Stream mensajes de bot
Nota:
- El streaming de mensajes de bot solo está disponible para chats uno a uno y en versión preliminar para desarrolladores públicos.
- El streaming de mensajes de bot no está disponible con las llamadas a funciones y el modelo OpenAI
o1. - Los mensajes de bot de streaming se admiten en web, escritorio y dispositivos móviles (Android). No se admite en iOS.
Puede transmitir mensajes de bot para entregar las respuestas de un bot al usuario como pequeñas actualizaciones mientras se genera la respuesta completa para mejorar la experiencia del usuario. A menudo, los bots tardan mucho tiempo en generar respuestas sin actualizar la interfaz de usuario, lo que da lugar a una experiencia menos atractiva.
Cuando los usuarios observan el bot procesando su solicitud en tiempo real, puede aumentar su satisfacción y confianza. Esta capacidad de respuesta y transparencia percibidas mejora la interacción del usuario y reduce el abandono de la conversación con el bot.
Los mensajes de bot de streaming tienen dos tipos de actualizaciones:
Actualizaciones informativas: las actualizaciones informativas aparecen como una barra de progreso azul en la parte inferior del chat. Informa al usuario sobre las acciones en curso del bot mientras se genera una respuesta.

Streaming de respuesta: el streaming de respuesta se muestra como un indicador de escritura. Revela la respuesta del bot al usuario como pequeñas actualizaciones mientras se genera la respuesta completa.

Puede implementar mensajes de bot de streaming en la aplicación de una de las siguientes maneras:
Stream mensaje a través de la biblioteca de inteligencia artificial de Teams
La biblioteca de inteligencia artificial de Teams proporciona la capacidad de transmitir mensajes para bots con tecnología de inteligencia artificial. El streaming de mensajes de bot ayuda a facilitar el retraso en el tiempo de respuesta mientras el modelo de lenguaje grande (LLM) genera la respuesta completa. Los factores principales que contribuyen a un tiempo de respuesta lento incluyen varios pasos de preprocesamiento, como Retrieval-Augmented generación (RAG) o llamadas de función, y el tiempo necesario para generar una respuesta completa por parte del LLM.
Nota:
El streaming de mensajes del bot no está disponible con llamadas a funciones.
A través del streaming, el bot con tecnología de inteligencia artificial puede ofrecer una experiencia atractiva y con capacidad de respuesta para el usuario. Configure las siguientes características para transmitir mensajes para la aplicación con tecnología de inteligencia artificial:
Habilite el streaming para un bot con tecnología de inteligencia artificial:
Los mensajes de bot se pueden transmitir a través del SDK de IA. El bot con tecnología de inteligencia artificial envía fragmentos al usuario a medida que el modelo genera la respuesta. Los mensajes de streaming admiten texto. Sin embargo, los datos adjuntos, la etiqueta de IA, el bucle de comentarios y las etiquetas de confidencialidad solo están disponibles para el mensaje de streaming final.
Establecer mensaje informativo:
Puede definir un mensaje informativo para el bot con tecnología de inteligencia artificial. Este mensaje aparece para el usuario cada vez que el bot envía una actualización. Estos son algunos ejemplos de mensajes informativos que puede establecer en la aplicación:
- Examen de documentos
- Resumen del contenido
- Búsqueda de elementos de trabajo relevantes
En el ejemplo siguiente se muestran las actualizaciones de información de un bot con tecnología de inteligencia artificial:
Dar formato al mensaje transmitido final:
Con el SDK de IA, los mensajes de texto y markdown simple se pueden dar formato mientras se transmiten. Sin embargo, para tarjetas adaptables, imágenes o HTML enriquecido, el formato se puede aplicar una vez completado el mensaje final. El bot solo puede enviar datos adjuntos en el fragmento final transmitido.
En el ejemplo siguiente se muestra la respuesta de streaming en un bot con tecnología de inteligencia artificial:

En el ejemplo siguiente se muestra el bot con tecnología de inteligencia artificial que aplica formato a la respuesta en secuencia:

En el ejemplo siguiente se muestra la respuesta final en secuencias en un bot con tecnología de inteligencia artificial una vez completado el formato:

Habilite las características con tecnología de inteligencia artificial para el mensaje final:
Puede habilitar las siguientes características con tecnología de inteligencia artificial para el mensaje final enviado por el bot:
- Citas: la biblioteca de inteligencia artificial de Teams incluye automáticamente citas en las respuestas del bot. Proporciona referencias para los orígenes que el bot usó para generar la respuesta. Permite a los usuarios hacer referencia al origen a través de citas y referencias en texto.
- Etiqueta de confidencialidad: use la etiqueta de confidencialidad para ayudar a los usuarios a comprender la confidencialidad de un mensaje.
- Bucle de comentarios: esto permite a los usuarios proporcionar comentarios positivos o negativos sobre los mensajes del bot.
- Generado por IA: la biblioteca de inteligencia artificial de Teams incluye automáticamente una etiqueta Generated by AI en las respuestas del bot. Esta etiqueta ayuda a los usuarios a identificar que se generó un mensaje mediante IA.
Para obtener más información sobre cómo dar formato a los mensajes de bot con tecnología de inteligencia artificial, consulte Mensajes de bot con contenido generado por IA.
Configuración de mensajes de bot de streaming
Siga estos pasos para configurar mensajes de bot de streaming:
Habilite el streaming para un bot con tecnología de inteligencia artificial:
a. Use la
DefaultAugmentationclase en elconfig.jsonarchivo y en una de las siguientes clases de aplicación principales de la aplicación de bot:- Para una aplicación de bot de C#: actualice
Program.cs. - Para una aplicación de JavaScript: actualice
index.ts. - Para una aplicación de Python: actualice
bot.py.
b. Establezca
streamen true en laOpenAIModeldeclaración.- Para una aplicación de bot de C#: actualice
Establecer mensaje informativo: especifique el mensaje informativo en la
ActionPlannerdeclaración mediante laStartStreamingMessageconfiguración.Dar formato al mensaje transmitido final:
- Establezca el botón de alternancia del bucle de comentarios en el
AIOptionsobjeto dentro de la declaración de la aplicación y especifique un controlador.- Para una aplicación de bot compilada con Python, establezca el botón de alternancia del bucle de comentarios en el
ActionPlannerOptionsobjeto además delAIOptionsobjeto .
- Para una aplicación de bot compilada con Python, establezca el botón de alternancia del bucle de comentarios en el
- Establezca los datos adjuntos en el fragmento final mediante dentro de
EndStreamHandlerlaActionPlannerdeclaración.
- Establezca el botón de alternancia del bucle de comentarios en el
El siguiente fragmento de código muestra un ejemplo de mensajes de bot de streaming:
// Create OpenAI Model
builder.Services.AddSingleton<OpenAIModel > (sp => new(
new OpenAIModelOptions(config.OpenAI.ApiKey, "gpt-4o")
{
LogRequests = true,
Stream = true, // Set stream toggle
},
sp.GetService<ILoggerFactory>()
));
ResponseReceivedHandler endStreamHandler = new((object sender, ResponseReceivedEventArgs args) =>
{
StreamingResponse? streamer = args.Streamer;
if (streamer == null)
{
return;
}
AdaptiveCard adaptiveCard = new("1.6")
{
Body = [new AdaptiveTextBlock(streamer.Message) { Wrap = true }]
};
var adaptiveCardAttachment = new Attachment()
{
ContentType = "application/vnd.microsoft.card.adaptive",
Content = adaptiveCard,
};
streamer.Attachments = [adaptiveCardAttachment]; // Set attachments
});
// Create ActionPlanner
ActionPlanner<TurnState> planner = new(
options: new(
model: sp.GetService<OpenAIModel>()!,
prompts: prompts,
defaultPrompt: async (context, state, planner) =>
{
PromptTemplate template = prompts.GetPrompt("Chat");
return await Task.FromResult(template);
}
)
{
LogRepairs = true,
StartStreamingMessage = "Loading stream results...", // Set informative message
EndStreamHandler = endStreamHandler // Set final chunk handler
},
loggerFactory: loggerFactory
);
Desarrollo de modelos y Planner personalizados
La StreamingResponse clase es la clase auxiliar para las respuestas de streaming al cliente. Permite enviar una serie de actualizaciones en una única respuesta, lo que facilita la interacción. Si usa su propio modelo personalizado, puede usar fácilmente esta clase para transmitir respuestas sin problemas. Es una excelente manera de mantener al usuario comprometido.
Los mensajes del bot de streaming deben usar la siguiente secuencia:
queueInformativeUpdate()queueTextChunk()endStream()
Una vez que el modelo llama a endStream(), la secuencia finaliza y el bot no puede enviar más actualizaciones.
Esta es una lista de otros métodos que puede usar para personalizar la experiencia de la aplicación:
setAttachmentssetSensitivityLabelsetFeedbackLoopsetGeneratedByAILabel
Limitaciones de Azure OpenAI o OpenAI
- Cuando el bot llama a la API de streaming demasiado rápido, puede causar problemas e interrumpir la experiencia de streaming. Para evitar esto, transmita un mensaje a la vez a un ritmo coherente. Si no lo hace, es posible que se limite la solicitud. Almacene en búfer los tokens del modelo durante 1,5 a 2 segundos para garantizar el streaming sin problemas.
- Las características con tecnología de inteligencia artificial, como citas, etiquetas de confidencialidad, bucle de comentarios y etiquetas generadas por IA , solo se admiten en el fragmento final. Las citas se establecen por cada fragmento de texto en cola.
- Solo se puede transmitir texto enriquecido.
- Solo puede establecer un mensaje informativo. El bot reutiliza este mensaje para cada actualización. Algunos ejemplos son:
- Examen de documentos
- Resumen del contenido
- Búsqueda de elementos de trabajo relevantes
- El modelo representa el mensaje informativo solo al principio de cada mensaje devuelto por el LLM.
- Los datos adjuntos solo se pueden enviar en el fragmento final.
- El streaming aún no está disponible con las llamadas a funciones del SDK de IA y el modelo de AOAI o OAI
o1. - Estos son los requisitos que se deben usar
streamSequencepara el SDK de IA:- La secuencia debe comenzar con el número '1'.
- Los números posteriores (excepto final) deben ser un entero de aumento monotónico (por ejemplo, 1-2-3>>).
- Para el mensaje final,
streamSequenceno se debe establecer.
Stream mensaje a través de la API REST
Los mensajes de bot se pueden transmitir a través de la API REST. Los mensajes de streaming admiten texto enriquecido y cita. Los datos adjuntos, la etiqueta de IA, el botón de comentarios y las etiquetas de confidencialidad solo están disponibles para el mensaje de streaming final. Para obtener más información, consulte datos adjuntos y mensajes de bot con contenido generado por IA.
Cuando el bot invoque el streaming a través de la API REST, asegúrese de llamar a la siguiente API de streaming solo después de recibir una respuesta correcta de la llamada de API inicial. Si el bot usa el SDK, compruebe que recibe un objeto de respuesta NULL del método de actividad de envío para confirmar que la llamada anterior se transmitió correctamente.
Cuando el bot llama a streaming API demasiado rápido, es posible que se produzcan problemas y se pueda interrumpir la experiencia de streaming. Se recomienda que el bot transmita un mensaje a la vez para asegurarse de que llama a la API de streaming a un ritmo coherente. Si no es así, es posible que se limite la solicitud. Almacene en búfer los tokens del modelo durante 1,5 a dos segundos para garantizar un proceso de streaming sin problemas.
A continuación se muestran las propiedades para transmitir mensajes de bot:
| Propiedad | Obligatorio | Descripción |
|---|---|---|
type |
✔️ | Los valores admitidos son typing o message.
• : typingse usa al transmitir el mensaje.
• : messageuse para el mensaje final transmitido. |
text |
✔️ | Contenido del mensaje que se va a transmitir. |
entities.type |
✔️ | Debe ser streamInfo |
entities.streamId |
✔️ |
streamId desde la solicitud de streaming inicial, inicie el streaming. |
entities.streamType |
Tipo de actualizaciones de streaming. Los valores admitidos son informative, streamingo final. El valor predeterminado es streaming.
final solo se usa en el mensaje final. |
|
entities.streamSequence |
✔️ | Entero incremental para cada solicitud. |
Nota:
Estos son los requisitos para usar streamSequence para las API REST:
- El primero debe ser el número '1'.
- Los números posteriores (excepto final) deben ser un entero de aumento monotónico (por ejemplo, 1-2-3>>).
- Para el mensaje final,
streamSequenceno se debe establecer.
Para habilitar el streaming en bots, siga estos pasos:
Iniciar streaming
El bot puede enviar un mensaje informativo o de streaming como su comunicación inicial. La respuesta incluye , streamIdque es importante para ejecutar llamadas posteriores.
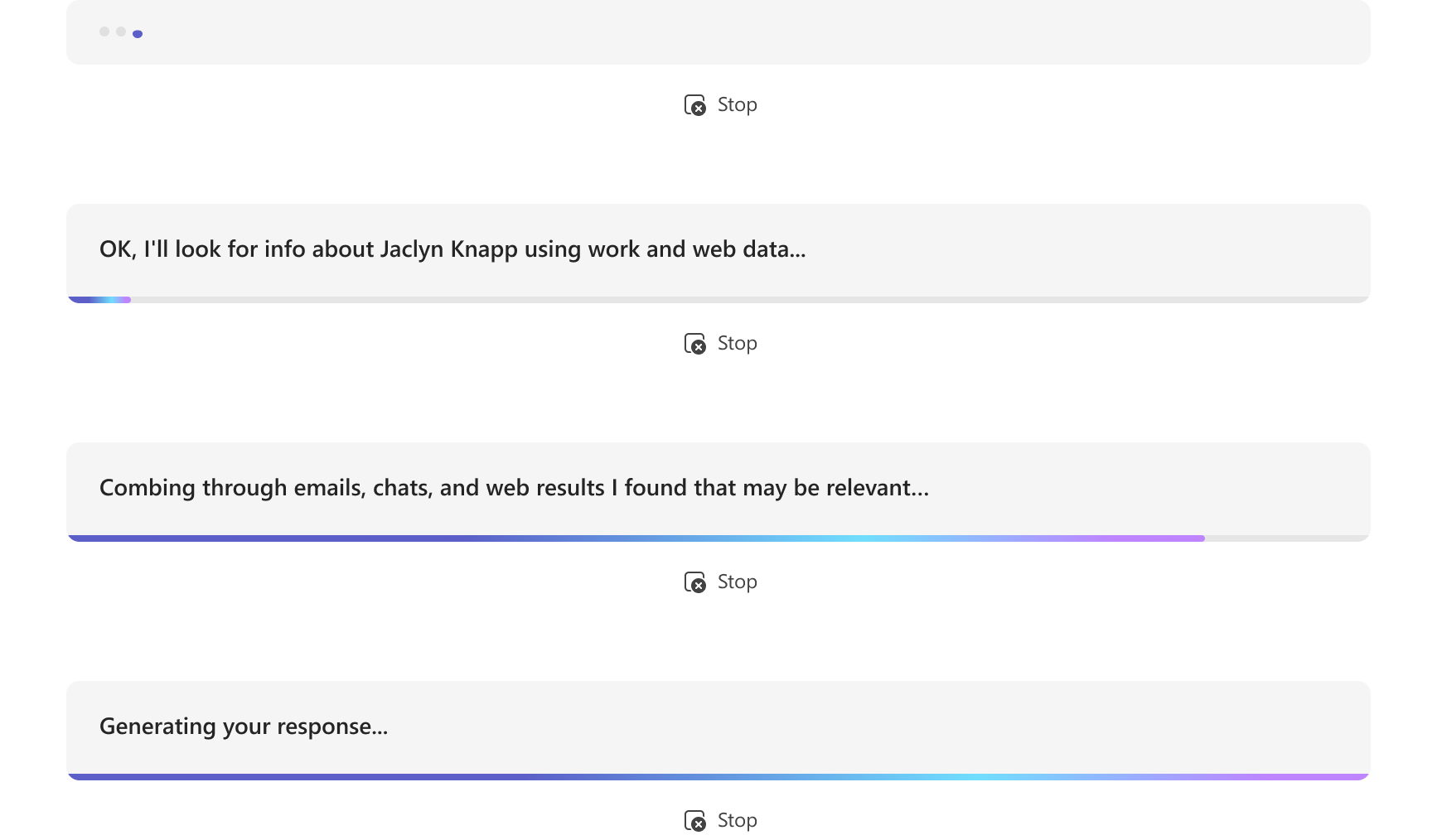
El bot puede enviar varias actualizaciones informativas mientras procesa la solicitud del usuario, como el examen de documentos, el resumen de contenido y los elementos de trabajo pertinentes encontrados. Puede enviar estas actualizaciones antes de que el bot genere su respuesta final al usuario.
//Ex: A bot sends the first request with content & the content is informative loading message.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "typing",
"serviceurl": "https://smba.trafficmanager.net/amer/",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id": "<conversationId>"
},
"recipient": {
"id": "<recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en-US",
"text": "Searching through documents...", //(required) first informative loading message.
"entities":[
{
"type": "streaminfo",
"streamType": "informative", // informative or streaming; default= streaming.
"streamSequence": 1 // (required) incremental integer; must be present for start and continue streaming request, but must not be set for final streaming request.
}
],
}
201 created { "id": "a-0000l" } // return stream id
La siguiente imagen es un ejemplo de inicio de streaming:

Continuar streaming
Use el streamId que ha recibido de la solicitud inicial para enviar mensajes informativos o de streaming. Puede empezar con actualizaciones informativas y, posteriormente , cambiar a streaming de respuesta cuando la respuesta final esté lista.
Empezar con actualizaciones informativas
A medida que el bot genera una respuesta, envíe actualizaciones informativas al usuario, como el examen de documentos, el resumen de contenido y los elementos de trabajo pertinentes encontrados. Asegúrese de realizar llamadas posteriores solo después de que el bot reciba una respuesta correcta de las llamadas anteriores.
// Ex: A bot sends the second request with content & the content is informative loading message.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "typing",
" serviceurl": "https://smba.trafficmanager.net/amer/",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id" : "<conversationId>"
},
"recipient": {
"id": "<recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en -US",
"text ": "Searching through emails...", // (required) second informative loading message.
"entities":[
{
"type": "streaminfo",
"streamId": "a-0000l", // // (required) must be present for any subsequent request after the first chunk.
"streamType": "informative", // informative or streaming; default= streaming.
"streamSequence": 2 // (required) incremental integer; must be present for start and continue streaming request, but must not be set for final streaming request.
}
],
}
202 0K { }
La siguiente imagen es un ejemplo de un bot que proporciona actualizaciones informativas:

Cambiar a streaming de respuesta
Una vez que el bot esté listo para generar su mensaje final para el usuario, cambie de proporcionar actualizaciones informativas a streaming de respuesta. Para cada actualización de streaming de respuesta, el contenido del mensaje debe ser la versión más reciente del mensaje final. Esto significa que el bot debe incorporar los nuevos tokens generados por los modelos de lenguaje grande (LLM). Anexe estos tokens a la versión del mensaje anterior y, a continuación, envíelos al usuario.
Cuando el bot envía una solicitud de streaming, asegúrese de que el bot envía la solicitud a una velocidad mínima de una solicitud por segundo.
// Ex: A bot sends the third request with content & the content is actual streaming content.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "typing",
" serviceurl" : "https://smba.trafficmanager.net/amer/ ",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id" : "<conversationId>"
},
"recipient": {
"id" : "<recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en-US" ,
"text ": "A brown fox", // (required) first streaming content.
"entities":[
{
"type": "streaminfo",
"streamId": "a-0000l", // // (required) must be present for any subsequent request after the first chunk.
"streamType": "streaming", // informative or streaming; default= streaming.
"streamSequence": 3 // (required) incremental integer; must be present for start and continue streaming request, but must not be set for final streaming request.
}
],
}
202 0K{ }
// Ex: A bot sends the fourth request with content & the content is actual streaming content.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "typing",
" serviceurl" : "https://smba.trafficmanager.net/amer/ ",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id" : "<conversationId>"
},
"recipient": {
"id" : "<recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en-US" ,
"text ": "A brown fox jumped over the fence", // (required) first streaming content.
"entities":[
{
"type": "streaminfo",
"streamId": "a-0000l", // // (required) must be present for any subsequent request after the first chunk.
"streamType": "streaming", // informative or streaming; default= streaming.
"streamSequence": 4 // (required) incremental integer; must be present for start and continue streaming request, but must not be set for final streaming request.
}
],
}
202 0K{ }
La imagen siguiente es un ejemplo de un bot que proporciona actualizaciones en fragmentos:

Final Streaming
Una vez que el bot haya terminado de generar su mensaje, envíe la señal de streaming final junto con el mensaje final. Para el mensaje final, el de la type actividad es message. Aquí, el bot establece los campos que se permiten para la actividad de mensaje normal, pero final es el único valor permitido para streamType.
// Ex: A bot sends the second request with content && the content is informative loading message.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "message",
" serviceurl" : "https://smba.trafficmanager.net/amer/ ",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id" : "<conversationId>"
},
"recipient": {
"id" : "recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en-US",
"text ": "A brown fox jumped over the fence.", // (required) first streaming content.
"entities":[
{
"type": "streaminfo",
"streamId": "a-0000l", // // (required) must be present for any subsequent request after the first chunk.
"streamType": "final", // (required) final is only allowed for the last message of the streaming.
}
],
}
202 0K{ }
La siguiente imagen es un ejemplo de la respuesta final del bot:

Códigos de respuesta
A continuación se muestran los códigos de error y correcto:
Códigos correctos
| Código de estado HTTP | Valor devuelto | Descripción |
|---|---|---|
201 |
streamId, es igual que, por activityId ejemplo, {"id":"1728640934763"} |
El bot devuelve este valor después de enviar la solicitud de streaming inicial.
Para las solicitudes de streaming posteriores, streamId se requiere . |
202 |
{} |
Código correcto para las solicitudes de streaming posteriores. |
Códigos de error
| Código de estado HTTP | Código de error | Mensaje de error | Descripción |
|---|---|---|---|
202 |
ContentStreamSequenceOrderPreConditionFailed |
PreCondition failed exception when processing streaming activity. |
Es posible que algunas solicitudes de streaming lleguen fuera de secuencia y se quiten. La solicitud de streaming más reciente, determinada por streamSequence, se usa cuando las solicitudes se reciben de forma desordenada. Asegúrese de enviar cada solicitud de forma secuencial. |
400 |
BadRequest |
En función del escenario, es posible que encuentre varios mensajes de error, como Start streaming activities should include text |
La carga entrante no cumple ni contiene los valores necesarios. |
403 |
ContentStreamNotAllowed |
Content stream is not allowed |
No se permite la característica de API de streaming para el usuario o bot. |
403 |
ContentStreamNotAllowed |
Content stream is not allowed on an already completed streamed message |
Un bot no puede transmitirse continuamente en un mensaje que ya se ha transmitido y completado. |
403 |
ContentStreamNotAllowed |
Content stream finished due to exceeded streaming time. |
El bot no pudo completar el proceso de streaming dentro del límite de tiempo estricto de dos minutos. |
403 |
ContentStreamNotAllowed |
Message size too large |
El bot envió un mensaje que supera la restricción de tamaño del mensaje actual. |
429 |
ND | API calls quota exceeded |
El número de mensajes transmitidos por el bot ha superado la cuota. |
Ejemplo de código
| Ejemplo de nombre | Descripción | Node.js | C# | Python |
|---|---|---|---|---|
| Ejemplo de bot de streaming de Teams | En este ejemplo de código se muestra cómo crear un bot conectado a un LLM y enviar mensajes a través de Teams. | ND | View | ND |
| Bot de streaming conversacional | Se trata de un bot de streaming conversacional con la biblioteca de inteligencia artificial de Teams. | View | View | Ver |