Solucionar problemas de soluciones de datos de atención sanitaria en Microsoft Fabric
Este artículo proporciona información sobre algunos problemas o errores que puede ver al usar las soluciones de atención en Microsoft Fabric y cómo resolverlos. El artículo también incluye algunas orientaciones para la supervisión de aplicaciones.
Si el problema persiste después de seguir las instrucciones de este artículo, cree un vale de incidente para el equipo de soporte técnico.
Solucionar problemas de implementación
A veces, es posible que encuentre problemas intermitentes al implementar soluciones de datos de atención sanitaria en el área de trabajo de Fabric. Estos son algunos de los problemas comunes y las soluciones alternativas para solucionarlos:
La creación de la solución falla o tarda demasiado.
Error: La creación de la solución de atención sanitaria está en curso durante más de 5 minutos o falla.
Causa: Este error se produce si hay otra solución de atención médica que comparte el mismo nombre o que se eliminó recientemente.
Resolución: Si ha eliminado recientemente una solución, espere entre 30 y 60 minutos antes de intentar otra implementación.
La implementación de la capacidad falla.
Error: Las capacidades de las soluciones de datos de atención sanitaria no se implementan.
Resolución: Compruebe si la capacidad aparece en la sección Administrar capacidades implementadas.
- Si la capacidad no aparece en la tabla, intente implementarla de nuevo. Seleccione el icono de la capacidad y luego seleccione el botón Implementar en espacio de trabajo.
- Si la capacidad aparece en la tabla con el valor de estado Error en la implementación, vuelva a implementar la capacidad. Como alternativa, puede crear un nuevo entorno de soluciones de datos de atención sanitaria y volver a implementar la capacidad allí.
Solucionar problemas de tablas no identificadas
Cuando se crean tablas delta en el almacén de lago por primera vez, es posible que aparezcan temporalmente como "no identificadas" o vacías en la vista del Explorador de almacenes de lago. Sin embargo, deberían aparecer correctamente en la carpeta de tablas después de unos minutos.

Volver a ejecutar la canalización de datos
Para volver a ejecutar los datos de ejemplo de un extremo a otro, siga estos pasos:
Ejecute una instrucción SQL de Spark desde un cuaderno para eliminar todas las tablas de un almacén de lago. Mostramos ahora un ejemplo:
lakehouse_name = "<lakehouse_name>" tables = spark.sql(f"SHOW TABLES IN {lakehouse_name}") for row in tables.collect(): spark.sql(f"DROP TABLE {lakehouse_name}.{row[1]}")Use el explorador de archivos de OneLake para conectarse a OneLake en el Explorador de archivos de Windows.
Vaya a la carpeta de su área de trabajo en el Explorador de archivos de Windows. Bajo
<solution_name>.HealthDataManager\DMHCheckpoint, elimine todas las carpetas correspondientes en<lakehouse_id>/<table_name>. Como alternativa, también puede usar Microsoft Spark Utilities (MSSparkUtils) para Fabric para eliminar la carpeta.Vuelva a ejecutar las canalizaciones de datos, empezando por la ingesta de datos clínicos en el almacén de lago bronce.
Supervisar las aplicaciones de Apache Spark con Azure Log Analytics
Los registros de aplicación Apache Spark se envían a una instancia del área de trabajo de Log Analytics de Azure que puede consultar. Use esta consulta de Kusto de ejemplo para filtrar los registros específicos de las soluciones de datos de atención sanitaria:
AppTraces
| where Properties['LoggerName'] contains "Healthcaredatasolutions"
or Properties['LoggerName'] contains "DMF"
or Properties['LoggerName'] contains "RMT"
| limit 1000
Los registros de la consola del cuaderno también registran el RunId para cada ejecución. Puede usar este valor para recuperar los registros para una ejecución específica, como se muestra en la siguiente consulta de ejemplo:
AppTraces
| where Properties['RunId'] == "<RunId>"
Para obtener información general sobre la supervisión, consulte Uso el centro de supervisión de Fabric.
Usar el explorador de archivos de OneLake
La aplicación del explorador de archivos de OneLake integra a la perfección OneLake con el explorador de archivos de Windows. Puede usar el explorador de archivos de OneLake para ver cualquier carpeta o archivo implementado en el área de trabajo de Fabric. También puede ver los datos de ejemplo, los archivos y carpetas de OneLake, y los archivos de punto de control.
Usar el Explorador de Azure Storage
También puede usar el Explorador de Azure Storage para:
- Acceder a los archivos de OneLake en sus almacenes de lago de Fabric
- Conectarse a la ruta de archivo URL de OneLake
Restablecer la versión de runtime de Spark en el área de trabajo de Fabric
De forma predeterminada, todas las nuevas áreas de trabajo de Fabric usan la versión más reciente de runtime de Fabric, que actualmente es Runtime 1.3. Sin embargo, las soluciones de datos de atención sanitaria solo admiten Runtime 1.2.
Por lo tanto, después de implementar soluciones de datos de atención sanitaria en su área de trabajo, asegúrese de que la versión de runtime predeterminada de Fabric esté establecida en Runtime 1.2 (Apache Spark 3.4 y Delta Lake 2.4). De lo contrario, la canalización de datos y las ejecuciones del cuaderno pueden fallar. Para obtener más información, consulte Compatibilidad con varios runtime en Fabric.
Siga estos pasos para revisar o actualizar la versión de runtime de Fabric:
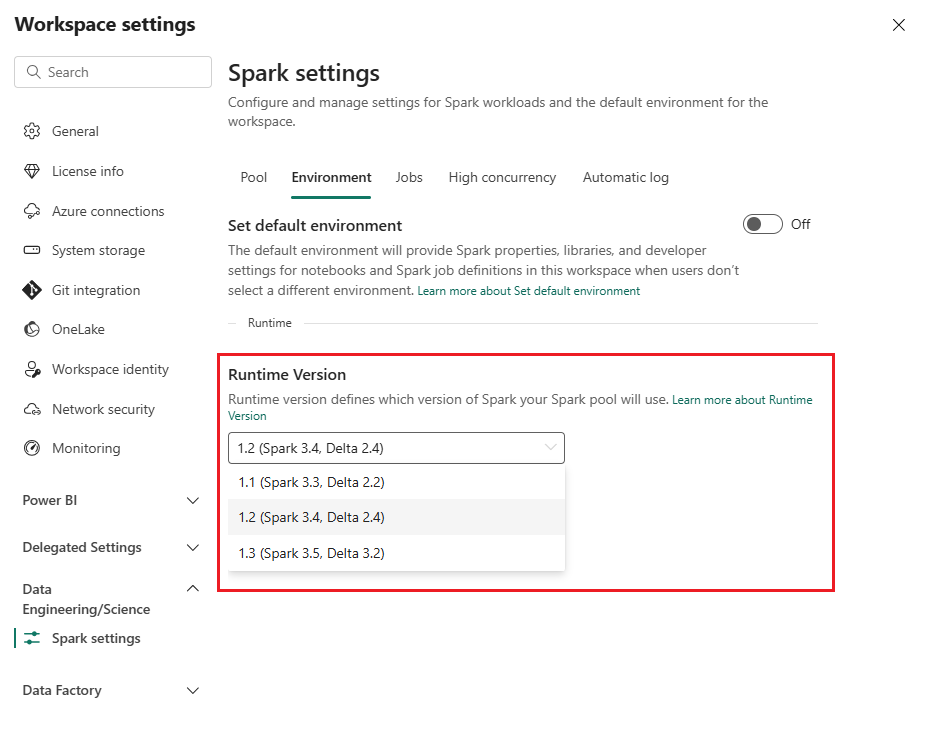
Vaya a su área de trabajo de soluciones de datos de atención sanitaria y seleccione Configuración del área de trabajo.
En la página de configuración del área de trabajo, expanda el cuadro desplegable Ingeniería de datos/Ciencia y seleccione Configuración de Spark.
En la pestaña Entorno, actualice el valor de Versión de runtime a 1.2 (Spark 3.4, Delta 2.4) y guarde los cambios.

Actualizar la interfaz de usuario de Fabric y el explorador de archivos de OneLake
A veces, es posible que observe que la interfaz de usuario de Fabric o el explorador de archivos de OneLake no siempre actualizan el contenido después de cada ejecución del cuaderno. Si no ve el resultado previsto en la interfaz de usuario después de ejecutar cualquier paso de ejecución (como crear una nueva carpeta o almacén de lago, o ingerir nuevos datos en una tabla), intente actualizar el artefacto (tabla, almacén de lago, carpeta). Esta actualización a menudo puede resolver discrepancias antes de explorar otras opciones o investigar más a fondo.