Administración y arquitectura de datos en soluciones de datos de atención sanitaria en Microsoft Fabric
El marco de soluciones de datos de atención sanitaria utiliza una arquitectura de medallón especializada para optimizar la organización y el procesamiento de datos. Este diseño garantiza una mejora continua en la calidad y la estructura de los datos, lo que le permite administrar los datos de atención sanitaria de manera más efectiva. Este artículo explora las características y ventajas clave de esta arquitectura, proporcionando una visión general completa de cómo se gestionan los datos dentro de este marco.
Diseño del almacén de lago de medallón
Como se explica en la arquitectura de la solución, las soluciones de datos de atención sanitaria utilizan la arquitectura de almacén de datos de medallón para organizar y procesar datos en varias capas. A medida que los datos se mueven por cada capa, su estructura y calidad mejoran continuamente. En esencia, el diseño de la casa del almacén de lago de medallón en las soluciones de datos de atención sanitaria consta de los siguientes almacenes de lago clave:
Almacén de lago bronce: también denominado zona sin procesar, el almacén de lago bronce es la primera capa que organiza los datos de origen en su formato de archivo original. Ingiere archivos de origen en OneLake y/o crea accesos directos a partir de orígenes de almacenamiento nativas. También almacena datos estructurados y semiestructurados del origen en tablas delta, también conocidas como tablas de almacenamiento provisional. Estas tablas están comprimidas e indexadas en columnas para permitir transformaciones y procesamiento de datos eficientes. Los datos de esta capa suelen ser de solo anexión e inmutables.
Los archivos en el almacén de lago bronce (ya sean persistentes o accesos directos) sirven como fuente de verdad. Sientan las bases para el linaje de datos en todo el patrimonio de datos en soluciones de datos de atención sanitaria. Las tablas de almacenamiento provisional de la capa bronce suelen constar de unas pocas columnas y están diseñadas para contener cada modalidad y formato de datos en una sola tabla (por ejemplo, tablas ClinicalFhir e ImagingDicom). No debe ampliar, personalizar ni crear dependencias en estas tablas de almacenamiento provisional en el almacén de lago bronce por los siguientes motivos:
- Implementación interna: las tablas de almacenamiento provisional se implementan internamente específicamente para soluciones de datos de atención sanitaria en Microsoft Fabric. Su esquema está diseñado específicamente para soluciones de datos de asistencia sanitaria y no sigue ningún estándar de datos de la industria o la comunidad.
- Almacén transitorio: después de procesar y transformar los datos de las tablas de almacenamiento provisional del almacén de lago de bronce a las tablas delta aplanadas y normalizadas del almacén de lago de plata, los datos de la tabla de almacenamiento provisional de bronce se consideran listos para ser purgados. Este modelo garantiza la eficiencia de costes y almacenamiento, y reduce la redundancia de datos entre los archivos de origen y las tablas de almacenamiento provisional en el almacén de lago de bronce.
Almacén de lago plata: también denominada zona zona , el almacén de lago de plata refina los datos del almacén de lago de bronce. Incluye comprobaciones de validación y técnicas de enriquecimiento para mejorar la precisión de los datos para el análisis posterior. A diferencia de la capa bronce, los datos de almacén de lago utilizan reglas basadas en identificadores deterministas y marcas de tiempo de modificación para administrar las inserciones y actualizaciones de registros.
Almacén de lago oro: también denominado zona curada, el almacén de lago oro refina aún más los datos del almacén de plata para cumplir con los requisitos comerciales y analíticos específicos. Esta capa sirve como origen principal de conjuntos de datos agregados de alta calidad, listos para un análisis exhaustivo y la extracción de información. Si bien las soluciones de datos de atención sanitaria implementan un almacén de lago bronce y uno plata por implementación, puede tener varios almacenes de lago oro para atender a varias unidades de negocio y personas.
Almacén de lago de datos de administración: el administrador contiene archivos para la gobernanza de datos y la trazabilidad en todas las capas del almacén de lago, incluidos los errores de configuración y validación globales almacenados en la tabla BusinessEvent. Para obtener más información, consulte Almacén de lago de datos de administración.
Estructura de carpetas unificada
Los clientes del sector sanitario y de ciencias biológicas gestionan grandes cantidades de datos de diversos sistemas de origen, en varias modalidades de datos y formatos de archivo, incluidos los siguientes formatos de archivo:
- Modalidad clínica: archivos NDJSON FHIR, paquetes FHIR y HL7.
- Modalidad de imágenes: DICOM, NIFTI y NDPI.
- Modalidad genómica: BAM, BCL, FASTQ y VCF.
- Reclamaciones: CCLF y CSV.
Donde:
- FHIR: Recursos Rápidos de Interoperabilidad en Salud
- HL7: Health Level Seven International
- DICOM: Digital Imaging and Communications in Medicine
- NIFTI: Neuroimaging Informatics Technology Initiative
- NDPI: Nano-dimensional Pathology Imaging
- BAM: Binary Alignment Map
- BCL: Base Call
- FASTQ: Un formato basado en texto para almacenar una secuencia biológica y sus correspondientes puntuaciones de calidad
- VCF: Variant Call Format
- CCLF: Claim and Claim Line Feed
- CSV: Valores separados por comas
OneLake en Microsoft Fabric ofrece un lago de datos lógico para su organización. Las soluciones de datos de atención sanitaria en Microsoft Fabric proporcionan una estructura de carpetas unificada que ayuda a organizar los datos en varias modalidades y formatos. Esta estructura agiliza la ingesta y el procesamiento de datos, a la vez que mantiene el linaje de datos en los niveles de archivo de origen y sistema de origen en el almacén de lago bronce.
Las seis carpetas de nivel superior incluyen:
- Externos
- Con errores
- Ingerir
- Proceso
- ReferenceData
- SampleData
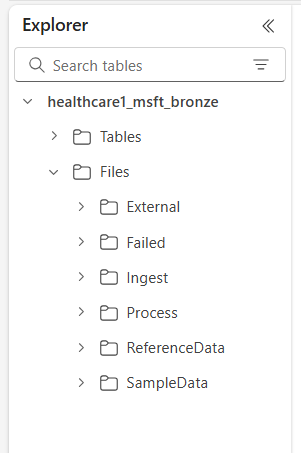
Las subcarpetas se organizan de la siguiente manera:
Files\Ingest\[DataModality]\[DataFormat]\[Namespace]Files\External\[DataModality]\[DataFormat]\[Namespace]\[BYOSShortcutname]\Files\SampleData\[DataModality]\[DataFormat]\[Namespace]\Files\ReferenceData\[DataModality]\[DataFormat]\[Namespace]\Files\Failed\[DataModality]\[DataFormat]\[Namespace]\YYYY\MM\DDFiles\Process\[DataModality]\[DataFormat]\[Namespace]\YYYY\MM\DD
Descripciones de carpeta
Espacio de nombres (obligatorio): identifica el sistema de origen para los archivos recibidos, lo que es crucial para garantizar la unicidad del id. por sistema de origen.
Carpeta de ingesta: funciona como una carpeta de entrega o cola. Esta carpeta le permite colocar los archivos que se van a ingerir en las subcarpetas de modalidad y formato adecuadas. Una vez que comienza la ingesta, los archivos se transfieren a la carpeta Proceso o la carpeta Con error para errores.
Carpeta Proceso: el destino final de todos los archivos procesados correctamente dentro de cada modalidad y combinación de formato. Esta carpeta sigue el patrón
YYYY/MM/DDen función de la fecha de procesamiento. La creación de particiones de carpetas se adhiere a los Procedimientos recomendados para usar Azure Data Lake Storage para una organización mejorada, las búsquedas filtradas, la automatización y el posible procesamiento paralelo.Carpeta externa: sirve como carpeta principal para las carpetas de acceso directo de Bring Your Own Storage (BYOS). La implementación predeterminada proporciona una sugerente estructura de carpetas para las modalidades de notificaciones, clínicas, genómicas e imágenes. Las modalidades clínicas y de imágenes tienen formatos predeterminados y espacios de nombres configurados para admitir los servicios DICOM y FHIR en Azure Health Data Services. Este formato solo se aplica si tiene la intención de acceder directamente a los datos en OneLake. Las soluciones de datos de atención sanitaria e Microsoft Fabric tienen acceso de solo lectura a los archivos de estas carpetas de accesos directos.
Carpeta con errores: si se produce un error al mover o procesar archivos en las carpetas Ingerir o Procesar, los archivos afectados se mueven a la carpeta Con error correspondiente a su combinación de formato y modalidad. Se registra un error en la tabla BusinessEvent del almacén de lago de administración. Esta carpeta usa el patrón
YYYY/MM/DDen función de la fecha de procesamiento/error. Los archivos de esta carpeta no se purgan y permanecen aquí hasta que los corrija y los vuelva a ingerir con el mismo patrón de ingesta inicial.Carpeta de datos de ejemplo: incluye conjuntos de datos sintéticos, referenciales y/o públicos. La implementación predeterminada proporciona datos de ejemplo para varias combinaciones de modalidades y formatos a fin de facilitar la ejecución inmediata de cuadernos y canalizaciones después de la implementación. Esta carpeta no crea ninguna subcarpeta
YYYY/MM/DD.Carpeta de datos de referencia: contiene conjuntos de datos referenciales y primarios de fuentes públicas o específicas de usuario. Esta carpeta no crea ninguna subcarpeta
YYYY/MM/DD. La implementación predeterminada proporciona una estructura de carpetas sugerida para vocabularios OMOP (Observational Medical Outcomes Partnership).
Patrones de ingesta de datos
En función de la estructura de carpetas unificada descrita anteriormente, las soluciones de datos de atención sanitaria en Microsoft Fabric admiten dos patrones de ingesta distintos. En ambos casos, las soluciones utilizan la transmisión estructurada en Spark para procesar los archivos entrantes en las carpetas respectivas.
Patrón de ingesta
Este patrón es un enfoque sencillo en el que los archivos que se van a ingerir se colocan en la carpeta Ingerir con la modalidad, el formato y el espacio de nombres adecuados. Las canalizaciones de ingesta supervisan esta carpeta en busca de archivos recién colocados y los mueven a la carpeta Procesar correspondiente para su procesamiento. Si la ingesta de datos de archivo en la tabla de almacenamiento provisional de almacén de lago bronce se realiza correctamente, el archivo se comprime y se guarda con un prefijo de marca de tiempo en la carpeta Proceso, siguiendo el patrón YYYY/MM/DD basado en el momento en que se produce el procesamiento. Este prefijo garantiza nombres de archivo únicos. Puede configurar o deshabilitar la compresión según sea necesario.
Si se produce un error en el procesamiento de archivos, los archivos con errores se mueven de la carpeta Ingesta a la carpeta Con error para cada combinación de formato y modalidad, y se registra un error en la tabla BusinessEvent del almacén de lago de administración.
Este patrón de ingesta es ideal para ingestas incrementales diarias o cuando se mueven datos físicamente a Azure Data Lake Storage o OneLake.
Patrón Bring Your Own Database (BYOD)
Es posible que a veces tenga datos y archivos ya presentes en Azure u otros servicios de almacenamiento en la nube, con implementaciones posteriores existentes y dependencias en esos archivos. En el sector de la atención médica y las ciencias biológicas, los volúmenes de datos pueden alcanzar varios terabytes o incluso petabytes, especialmente para imágenes médicas y genómica. Por estos motivos, es posible que el patrón de ingesta directa no sea factible.
Recomendamos utilizar el patrón BYOS para la ingesta de datos históricos cuando ya tenga volúmenes de datos sustanciales disponibles en Azure u otro almacenamiento local y en la nube que admita el protocolo S3. Este patrón usa los accesos directos de OneLake en Fabric y la carpeta Externo en el almacén de lago bronce para habilitar el procesamiento local de archivos de origen. Elimina la necesidad de mover o copiar archivos, y evita incurrir en cargos de salida y duplicación de datos.
A pesar de las eficiencias que ofrece el patrón de ingesta de BYOS, debe tener en cuenta las siguientes consideraciones:
- Las actualizaciones de archivos in situ (actualizaciones de contenido dentro del archivo) no se supervisan. Se espera que cree un nuevo archivo (con un nombre diferente) para las actualizaciones, ya que la canalización de ingesta solo supervisa los archivos nuevos. Esta limitación está asociada al streaming estructurado en Spark.
- No se aplican compresiones de datos.
- El patrón BYOS no crea ninguna estructura de carpetas optimizada basada en el patrón
YYYY/MM/DD. - Si se produce un error en el procesamiento de archivos, los archivos con errores no se mueven a la carpeta Con error. Sin embargo, se registra un error en la tabla BusinessEvent del almacén de lago de administración.
- Se supone que los datos de origen son de solo lectura.
- No hay control sobre el linaje o la disponibilidad de los datos de origen después de la ingesta.
Compresión de datos
Las soluciones de datos sanitarios en Microsoft Fabric admiten la compresión por diseño en todo el diseño del almacén de lago del medallón. Los datos ingeridos en las tablas delta del almacén de lago de medallón se almacenan en un formato comprimido y de columnas mediante archivos Parquet. En el patrón de ingesta, cuando los archivos se mueven de la carpeta Ingesta a la carpeta Proceso , se comprimen de forma predeterminada después de un procesamiento correcto. Puede configurar o deshabilitar la compresión según sea necesario. Para las capacidades de imágenes y notificaciones, las canalizaciones de ingesta también pueden procesar archivos sin procesar en un formato comprimido ZIP.
Modelo de datos de atención sanitaria
Como se describe en el diseño de almacén de lago de medallón, las tablas de almacenamiento provisional de almacén de lago de bronce implementan internamente tablas diseñadas específicamente para soluciones de datos sanitarios y no siguen ningún estándar de datos de la industria o la comunidad.
El modelo de datos sanitarios del almacén de lago plata se basa en el estándar FHIR R4. Proporciona un lenguaje de datos común para que los analistas de datos, los científicos de datos y los desarrolladores colaboren y creen soluciones basadas en datos que mejoren los resultados de los pacientes y el rendimiento empresarial. Admite datos en diferentes dominios de atención sanitaria, como clínico, administrativo, financiero y social. El modelo de datos de atención sanitaria captura los datos definidos por el estándar FHIR y organiza los recursos de FHIR mediante tablas y columnas dentro del almacén de lago.
Al aplanar los datos de FHIR en tablas de Parquet delta, puede usar herramientas conocidas, como T-SQL y Spark SQL para la exploración y el análisis de datos. Para los datos no clínicos fuera del alcance de FHIR, utilizamos esquemas de las plantillas de la base de datos de Azure Synapse. Esta implementación permite la integración de información no clínica, como los datos de participación del paciente, en el perfil del paciente.
El modelo de datos de atención sanitaria del almacén de lago plata está diseñado para representar una vista empresarial integral de los datos de atención sanitaria en todas las unidades de negocio y dominios de investigación.

Linaje de datos y trazabilidad
Para garantizar el linaje y la trazabilidad en el nivel de registros y archivos, las tablas del modelo de datos de atención sanitaria incluyen las siguientes columnas:
| Columna | Descripción |
|---|---|
msftCreatedDatetime |
Marca de tiempo en la que se creó el registro por primera vez en el almacén de lago plata. |
msftModifiedDatetime |
Marca de tiempo de la última modificación del registro |
msftFilePath |
Ruta completa al archivo de origen en el almacén de lago bronce, incluidos los accesos directos. |
msftSourceSystem |
El sistema de origen del registro, correspondiente al Namespace especificado en la estructura de carpetas unificada. |
Si un campo se normaliza, acopla o modifica, el valor original se conserva en una columna {columnName}Orig. Por ejemplo, en la tabla Paciente del almacén de lago plata, puede encontrar las siguientes columnas:
| Columna | Descripción |
|---|---|
meta_lastUpdatedOrig |
Conserva el valor original en su formato sin procesar (cadena o fecha) y lo almacena como fecha y hora. |
idOrig y identifierOrig |
Id. e identificadores armonizados en el almacén de lago plata |
birthdateOrig y deceasedDateTimeOrig |
Conserva los valores de fecha originales con un formato de marca de tiempo diferente. |
Si una columna se aplana (por ejemplo, meta_lastUpdated) o se convierte en una cadena (por ejemplo, meta_string), la indicamos usando un sufijo que comienza con un guion bajo (_).
Gestión de actualizaciones
Cuando se ingieren nuevos datos del almacén de lago bronce al almacén de lago plata, una operación de actualización compara los registros entrantes con las tablas de destino del almacén de lago plata para cada recurso y tipo de tabla. En el caso de las tablas FHIR del almacén de lago platea, esta comparación compara tanto el valor {FHIRResource}.id como el valor {FHIRResource}.meta_lastUpdated con las columnas id y lastUpdated de la tabla de almacenamiento provisional del almacén de lago bronce de ClinicalFhir.
- Si se identifica una coincidencia y el registro entrante es nuevo, se actualiza el registro plata.
- Si el registro entrante es antiguo, se omite el registro plata.
- Si no se encuentra ninguna coincidencia, el nuevo registro se inserta en el almacén de lago plata.
Almacén de lago de administración
El almacén de lago de administración administra la configuración entre lagos, la configuración global, los informes de estado y el seguimiento de las soluciones de datos sanitarios en Microsoft Fabric.
Configuración global
La carpeta system-configurations del almacén de lago de administración centraliza los parámetros de configuración global. Los tres archivos de configuración contienen valores preconfigurados para la implementación predeterminada de todas las capacidades de las soluciones de datos sanitarios. No es necesario volver a configurar ninguno de estos valores para ejecutar los datos de ejemplo o las canalizaciones de datos para ninguna capacidad.

El archivo deploymentParametersConfiguration.json contiene parámetros globales en activitiesGlobalParameters y parámetros específicos de la actividad para cuadernos y canalizaciones en activities. La guía de capacidades correspondiente cubre detalles de configuración específicos para cada capacidad. Los parámetros de archivo validation_config.json se explican en Validación de datos.
En la siguiente tabla se muestran todos los parámetros de configuración global.
| Sección | Parámetros de configuración |
|---|---|
activitiesGlobalParameters |
•administration_lakehouse_id: Identificador de almacén de lago de administración.• bronze_lakehouse_id: Identificador de almacén de lago bronce.• silver_lakehouse_id: Identificador de almacén de lago plata.• keyvault_name: Valor de Azure Key Vault cuando se implementa con la oferta de Azure Marketplace.• enable_hds_logs: Habilita el registro; el valor predeterminado se establece en true.• movement_config_path: Ruta al archivo file_orchestration_config.• bronze_imaging_delta_table_path: Ruta de Fabric para la tabla de modalidad de imágenes (si se implementa).• bronze_imaging_table_schema_path: Ruta de Fabric para el esquema de modalidad de imágenes (si se implementa).• omop_lakehouse_id: Identificador de almacén de lago oro (si se implementa). |
| Actividades para healthcare#_msft_fhir_ndjson_bronze_ingestion | •source_path_pattern: Ruta de acceso a OneLake a la carpeta Proceso.• move_failed_files_enabled: Indicador para determinar si un archivo con errores debe pasar de la carpeta Ingesta a la carpeta Con errores.• compression_enabled: Indicador para determinar si los archivos NDJSON sin procesar se comprimirán después del procesamiento.• target_table_name: Nombre de la tabla de ingesta clínica en el almacén de lago bronce.• target_tables_path: Ruta de acceso a OneLake para todas las tablas delta en el almacén de lago bronce.• max_files_per_trigger: Número de archivos procesados con cada ejecución.• max_structured_streaming_queries: Número de consultas de procesamiento que se pueden ejecutar en paralelo.• checkpoint_path: Ruta de OneLake para la carpeta del punto de control.• schema_dir_path: Ruta de OneLake para la carpeta del esquema bronce.• validation_config_key: Configuración de validación de nivel primario. Para obtener más información, consulte Validación de datos.• file_extension: Extensión del archivo sin procesar ingerido. |
| Actividades para healthcare#_msft_bronze_silver_flatten | •source_table_name: Nombre de la tabla de ingesta clínica en el almacén de lago bronce.• config_path: Ruta de OneLake para el archivo de configuración aplanado.• source_tables_path: Ruta de acceso a OneLake para las tablas delta de origen en el almacén de lago bronce.• target_tables_path: Ruta de acceso a OneLake para las tablas delta de destino en el almacén de lago plata.• checkpoint_path: Ruta de OneLake para la carpeta del punto de control.• schema_dir_path: Ruta de OneLake para la carpeta del esquema bronce.• max_files_per_trigger: Número de archivos procesados dentro de cada ejecución.• max_bytes_per_trigger: Número de bytes procesados dentro de cada ejecución.• max_structured_streaming_queries: Número de consultas de procesamiento que se pueden ejecutar en paralelo. |
| Actividades para healthcare#_msft_imaging_dicom_extract_bronze_ingestion | •byos_enabled: Indicador que determina si la ingesta del conjunto de datos de imágenes DICOM en el almacén de lago bronce procede de una ubicación de almacenamiento externa a través de accesos directos de OneLake. En este caso, los archivos no se mueven a la carpeta Proceso como lo harían de otra manera.• external_source_path: Ruta de OneLake para la carpeta Externa de acceso directo en el almacén de lago bronce.• process_source_path: Ruta de OneLake para la carpeta Proceso en el almacén de lago bronce.• checkpoint_path: Ruta de OneLake para la carpeta del punto de control.• move_failed_files: Indicador que determina si un archivo con errores se mueve de la carpeta Ingesta a Con error.• compression_enabled: Indicador que determina si los archivos NDJSON sin procesar se comprimen después del procesamiento.• max_files_per_trigger: Número de archivos procesados dentro de cada ejecución.• num_retries: Número de reintentos por cada procesamiento de archivo antes de un error. |
| Actividades para healthcare#_msft_imaging_dicom_fhir_conversion | •fhir_ndjson_files_root_path: Ruta de acceso a OneLake a la carpeta Proceso.• avro_schema_path: Ruta de OneLake para la carpeta del esquema plata.• dicom_to_fhir_config_path: Ruta de OneLake para asignar la configuración de las metaetiquetas DICOM al recurso ImagingStudy de FHIR.• checkpoint_path: Ruta de OneLake para la carpeta del punto de control.• max_records_per_ndjson: Número de registros procesados en un único archivo NDJSON en cada ejecución.• subject_id_type_code: Código de valor del número médico del paciente en los metadatos DICOM. El valor predeterminado se establece en MR, que se corresponde a Medical Record Number en FHIR.• subject_id_type_code_system: El sistema de código del número médico del paciente en los metadatos DICOM.• subject_id_system: El id. de objeto para el sistema de código del número médico del paciente en los metadatos DICOM. |
| Actividades para healthcare#_msft_omop_silver_gold_transformation | •vocab_path: Ruta de OneLake a la carpeta de datos de referencia en el almacén de lago bronce donde se almacenan los conjuntos de datos de vocabulario de OMOP.• vocab_checkpoint_path: Ruta de OneLake para la carpeta del punto de control.• omop_config_path: Ruta de OneLake para asignar la configuración desde el almacén de lago plata hasta el almacén de lago OMOP oro. |
Tabla BusinessEvents
La tabla delta BusinessEvents captura todos los errores de validación, advertencias y otras notificaciones o excepciones que se pueden producir durante los procesos de ingesta y transformación. Use esta tabla para supervisar el progreso de la ejecución de la ingesta tanto en el nivel de usuario como en el funcional, en lugar de solo en el nivel de registro del sistema. Por ejemplo, identifica qué archivos sin procesar introdujeron errores de validación o advertencias durante la ingesta. Para los registros en el nivel de sistema y para supervisar las actividades de Apache Spark en todos los almacenes de lago, puede usar el centro de supervisión de Fabric, con la opción para integrar Azure Log Analytics.
En la tabla siguiente se enumeran las columnas de la tabla BusinessEvent:
| Columna | Descripción |
|---|---|
id |
Identificador único (GUID) para cada fila de la tabla. |
activityName |
Nombre de la actividad o cuaderno que generó el error y/o la advertencia o error de validación. |
targetTableName |
Tabla de destino para la actividad de datos que generó el evento. |
targetFilePath |
Ruta para el archivo de destino para la actividad de datos que generó el evento. |
sourceTableName |
Tabla de origen para la actividad de datos que generó el evento. |
sourceLakehouseName |
Almacén de lago de origen para la actividad de datos que generó el evento. |
targetLakehouseName |
Almacén de lago de destino para la actividad de datos que generó el evento. |
sourceFilePath |
Ruta para el archivo de origen para la actividad de datos que generó el evento. |
runId |
Id. de ejecución para la actividad de datos que generó el evento. |
severity |
Nivel de gravedad del evento, que puede tener uno de los dos valores siguientes: Error o Warning. Error significa que debe resolver este evento antes de continuar con la actividad de datos. Warning sirve como notificación pasiva, que no suele requerir ninguna acción inmediata. |
eventType |
Distingue entre los eventos generados por el motor de validación y los eventos genéricos generados por los usuarios o las excepciones no controladas o del sistema que los usuarios desean que aparezcan en la tabla BusinessEvent. |
recordIdentifier |
Identificador del registro de origen. Esta columna difiere de la columna id en que representa un identificador único y nuevo para cada evento de la tabla BusinessEvents. |
recordIdentifierSource |
Sistema de origen para el identificador del registro de origen. Por ejemplo, si el sistema de origen es el EMR, el nombre o la URL del EMR sirve como origen. |
active |
Marca que indica si el evento (error o advertencia) se ha resuelto. |
message |
Mensaje descriptivo del evento, error o advertencia. |
exception |
Mensaje de excepción del sistema o no controlado. |
customDimensions |
Aplicable cuando los datos de origen de la validación o excepción no son una columna discreta de una tabla. Por ejemplo, cuando los datos de origen son un atributo dentro de un objeto JSON guardado como cadena dentro de una sola columna, el objeto JSON completo se proporciona como dimensión personalizada. |
eventDateTime |
Marca de tiempo en la que se genera el evento o la excepción. |
Validación de datos
El motor de validación de datos dentro de las soluciones de datos sanitarios en Microsoft Fabric garantiza que los datos sin procesar cumplan con los criterios predefinidos antes de su ingesta en el almacén de lago bronce. Puede configurar las reglas de validación en los niveles de tabla y columna dentro del almacén de lago bronce. Actualmente, estas reglas se implementan exclusivamente durante el proceso de ingesta, desde archivos sin procesar hasta tablas delta en el almacén de lago bronce.
Cuando se procesa un archivo sin procesar, las reglas de validación se aplican en el nivel de ingesta. Hay dos niveles de gravedad para la validación: Error y Warning. Si se establece una regla de validación en Error, la canalización se detiene cuando se infringe la regla y el archivo defectuoso se mueve a la carpeta Error. Si la gravedad se establece en Warning, la canalización continúa procesándose y el archivo se mueve a la carpeta Proceso. En ambos casos, las entradas que reflejan los errores o advertencias se crean en la tabla BusinessEvents dentro del almacén de lago de administración.
La tabla BusinessEvents captura registros y eventos de nivel empresarial en todos los almacenes de lago para cualquier actividad, cuaderno o canalización de datos dentro de las soluciones de datos de atención sanitaria. Sin embargo, la configuración actual solo aplica reglas de validación durante la ingesta, lo que puede dar lugar a que algunas columnas de la tabla BusinessEvents permanezcan sin rellenar para errores y advertencias de validación.
Puede configurar las reglas de validación de datos en el archivo validation_config.json en el almacén de lago de administración. De forma predeterminada, las columnas meta.lastUpdated y id de la tabla ClinicalFhir del almacén de lago bronce se establecen según sea necesario. Estas columnas son fundamentales para determinar cómo se administran las actualizaciones y las inserciones en el almacén de lago plata, como se explica en Gestión de actualizaciones.
La tabla siguiente muestra los parámetros de configuración para la validación de datos.
| Tipo de configuración | Parámetros |
|---|---|
| Nivel del almacén de lago | bronze: El ámbito de las validaciones y los nodos de identificación de registros. En este caso, el valor se establece en el almacén de lago bronce. |
| Validaciones | •validationType: El tipo de validación exists comprueba si se proporciona un valor para el atributo configurado en el archivo sin procesar (datos de origen).• attributeName: Nombre del atributo que se valida.• validationMessage: Mensaje que describe el error o advertencia de validación.• severity: Indica el nivel del problema, que puede ser Error o Warning.• tableName: Nombre de la tabla que se valida. Un asterisco (*) indica que esta regla se aplica a todas las tablas dentro del ámbito de ese almacén de lago. |
recordIdentifier |
•attributeName: identificador de registro del archivo de origen/sin procesar colocado en la columna recordIdentifier de la tabla BusinessEvent.• jsonPath: valor opcional que representa la ruta JSON de una columna o atributo para el valor que se colocará en la columna recordIdentifier de la tabla BusinessEvent. Este valor se aplica cuando los datos de origen de la validación no son una columna discreta de una tabla. Por ejemplo, si los datos de origen son un atributo dentro de un objeto JSON almacenado como cadena dentro de una sola columna, la ruta JSON dirige al atributo específico que sirve como identificador de registro. |