Análisis de datos de Microsoft Graph en el almacenamiento de datos
En este artículo se describe un patrón de integración común de Microsoft Graph para un escenario empresarial que requiere un análisis complejo de los datos de colaboración empresarial para mejorar los procesos empresariales y la productividad.
Este escenario se basa en una gran cantidad de datos extraídos de Microsoft 365 y tiene los siguientes requisitos:
- Un tipo de integración de datos.
- Un flujo de datos saliente desde los límites de Microsoft 365 a la aplicación.
- Un gran volumen de datos que abarca varios meses.
- Una latencia de datos relativamente alta; el extracto de datos inicial puede incluir mensajes que tienen hasta un año de antigüedad.
La mejor opción para este escenario es usar Microsoft Graph Data Connect. El cliente debe configurar el almacenamiento de datos de alta capacidad, como Azure Data Lake o Azure Synapse, habilitar una suscripción de Azure y configurar una canalización de Azure Data Factory o Azure Synapse.
En el diagrama siguiente se muestra la arquitectura de esta solución.
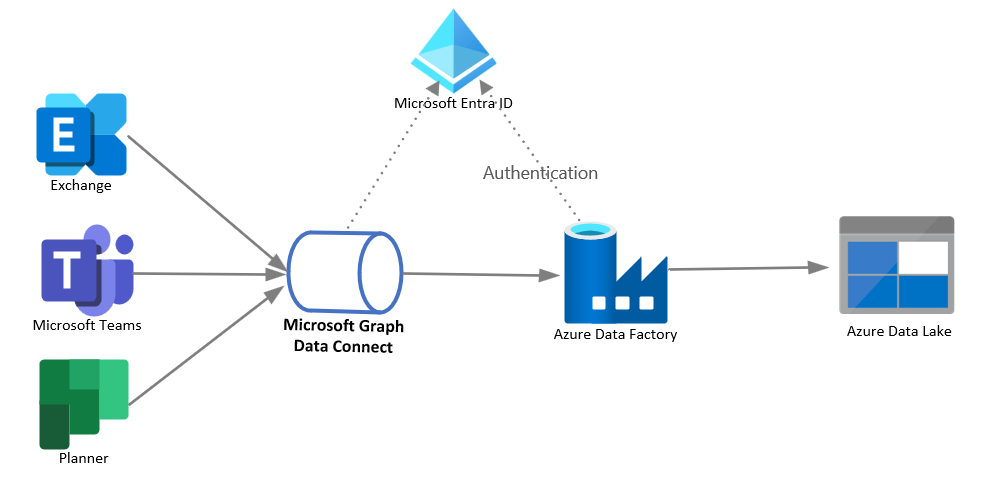
Componentes de la solución
La arquitectura de la solución incluye los siguientes componentes:
- Microsoft Graph Data Connect, que permite la extracción de datos de Microsoft 365 a escala con consentimiento de datos pormenorizada, y admite todas las funcionalidades de servicio nativas de Azure, como el cifrado, la barrera geográfica, la auditoría y la aplicación de directivas.
- Azure Data Factory (ADF), que permite una construcción sencilla de ETL (extracción, transformación y carga) y ELT (extracción, carga y transformación) procesa el código sin código en un entorno intuitivo o escribe el código.
- Azure Data Lake, que permite conservar grandes cantidades de datos estructurados y no estructurados en diferentes formatos.
- Microsoft Entra ID, que es necesario para administrar la autenticación para las API de Microsoft Graph y admite permisos delegados y de aplicación para habilitar el flujo de OAuth.
Consideraciones
Las siguientes consideraciones admiten el uso de este patrón de integración:
Disponibilidad: el cliente ADF puede extraer datos de forma masiva según su programación o de forma ad hoc.
Latencia: la latencia de datos en este escenario puede variar en función de la extracción de datos históricos o de la entrega de datos más recientes al almacenamiento de Microsoft Graph Data Connect mediante procesos asincrónicos realizados como tareas programadas. El rendimiento de la extracción de datos de gran tamaño de ADF es más rápido que las API HTTP granulares porque ADF usa el procesamiento por lotes y la transferencia de archivos.
Escalabilidad: esta arquitectura le permite desarrollar canalizaciones que maximizan el rendimiento del movimiento de datos para su entorno. Estas canalizaciones pueden usar completamente los siguientes recursos:
- Ancho de banda de red entre los almacenes de datos de origen y destino.
- Operaciones de entrada/salida por segundo (IOPS) y ancho de banda del almacén de datos de origen o destino.
Complejidad de la solución: esta solución de salida de datos es de baja complejidad desde una perspectiva de integración porque no requiere código personalizado, tiene pocos componentes y es tolerante a la latencia de datos.