Detección de anomalías multivariadas
Para obtener información general sobre la detección de anomalías multivariantes en inteligencia en tiempo real, consulta Detección de anomalías multivariantes en Microsoft Fabric: información general. En este tutorial, usará datos de muestra para entrenar un modelo de detección de anomalías multivariante usando el motor Spark en un cuaderno Python. Después, predecirá anomalías aplicando el modelo entrenado a nuevos datos mediante el motor de Eventhouse. Los primeros pasos configuran los entornos y los pasos siguientes entrenan el modelo y predicen anomalías.
Requisitos previos
- Un área de trabajo con una capacidad habilitada para Microsoft Fabric
- Rol de Administrador, Colaborador o Miembroen un área de trabajo. Este nivel de permiso es necesario para crear elementos como un entorno.
- Una instancia de Eventhouse en el área de trabajo con una base de datos.
- Descarga los datos de ejemplo del repositorio de GitHub
- Descarga el cuaderno del repositorio de GitHub
Parte 1: Habilitación de la disponibilidad de OneLake
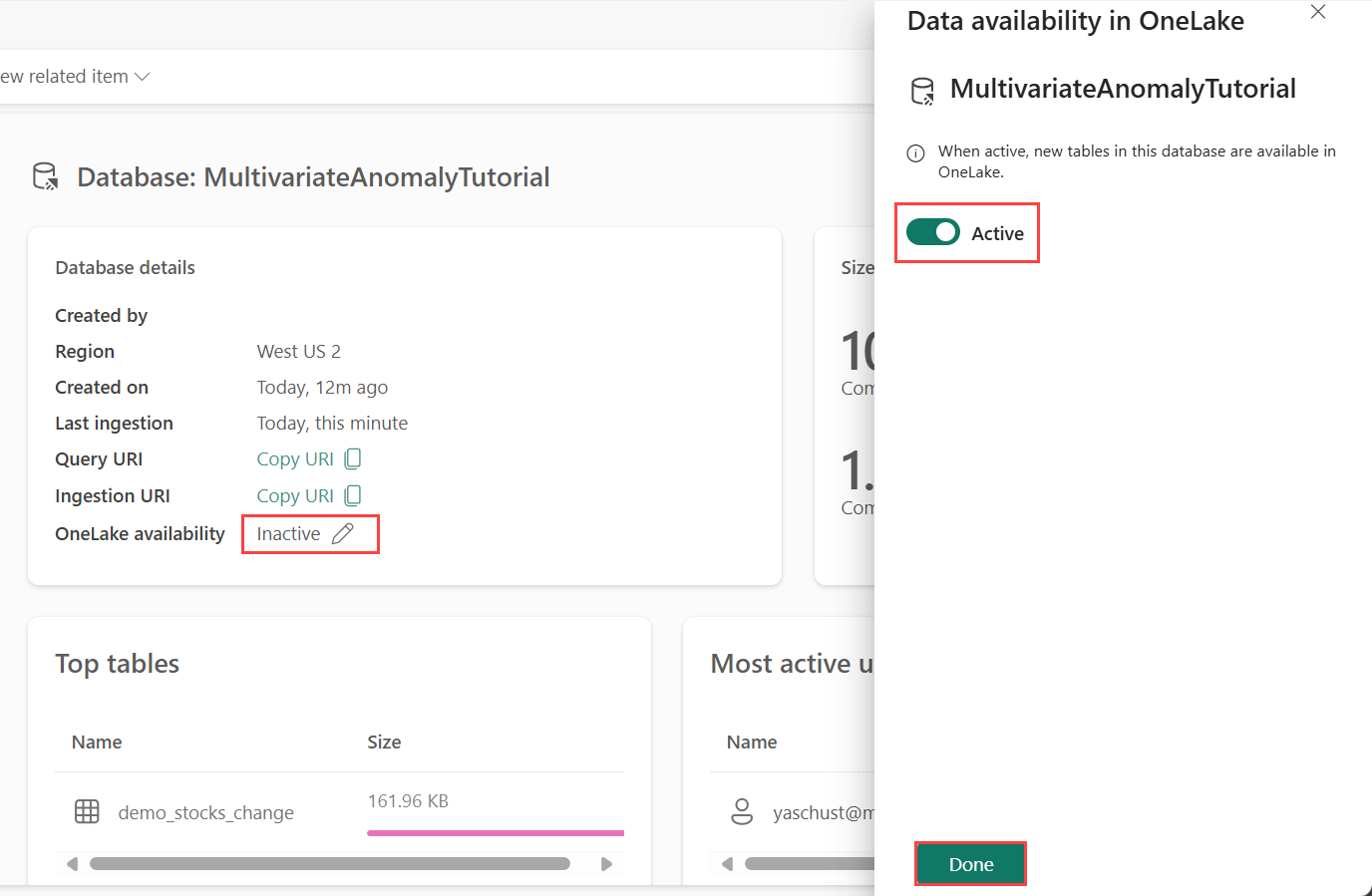
La disponibilidad de OneLake debe estar habilitada antes de obtener datos en Eventhouse. Este paso es importante, ya que permite que los datos que ingieres estén disponibles en OneLake. En un paso posterior, tendrás acceso a estos mismos datos desde Spark Notebook para entrenar el modelo.
Desde su área de trabajo, seleccione el Eventhouse que creó en los requisitos previos. Elige la base de datos en la que quieres almacenar los datos.
En el panel Detalles de la base de datos, cambie el botón de disponibilidad de OneLake a Activado.
Parte 2: Habilitación de la extensión de Python KQL
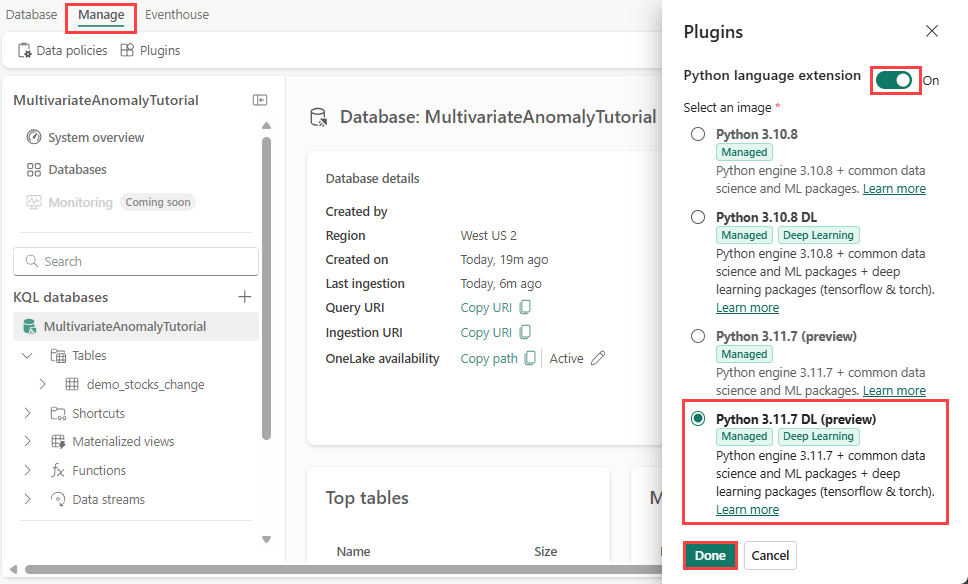
En este paso, habilitarás el complemento de Python en Eventhouse. Este paso es necesario para ejecutar el código de Python de predicción de anomalías en el conjunto de consultas KQL. Es importante elegir la imagen correcta que contiene el paquete time-series-anomaly-detector.
En la pantalla de Eventhouse, seleccione Eventhouse>Complementos en la barra de herramientas.
En el panel Extensiones, cambia la Extensión del lenguaje Python a Activado.
Selecciona Python 3.11.7 DL (versión preliminar).
Seleccione Listo.

Parte 3: Creación de un entorno de Spark
En este paso, crearás un entorno de Spark para ejecutar el cuaderno de Python que entrena el modelo de detección de anomalías multivariante mediante el motor de Spark. Para obtener más información sobre la creación de entornos, consulta Crear y administrar entornos.
En el área de trabajo, seleccione + Nuevo elemento y luego Entorno.
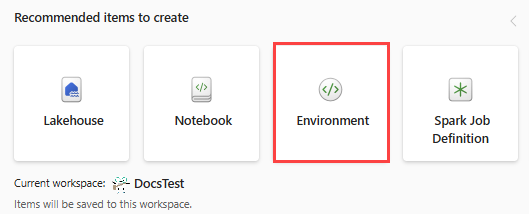
Escriba el nombre MVAD_ENV del entorno y seleccione Crear.
En la pestaña Inicio del entorno, seleccione Tiempo de ejecución>1.2 (Spark 3.4, Delta 2.4).
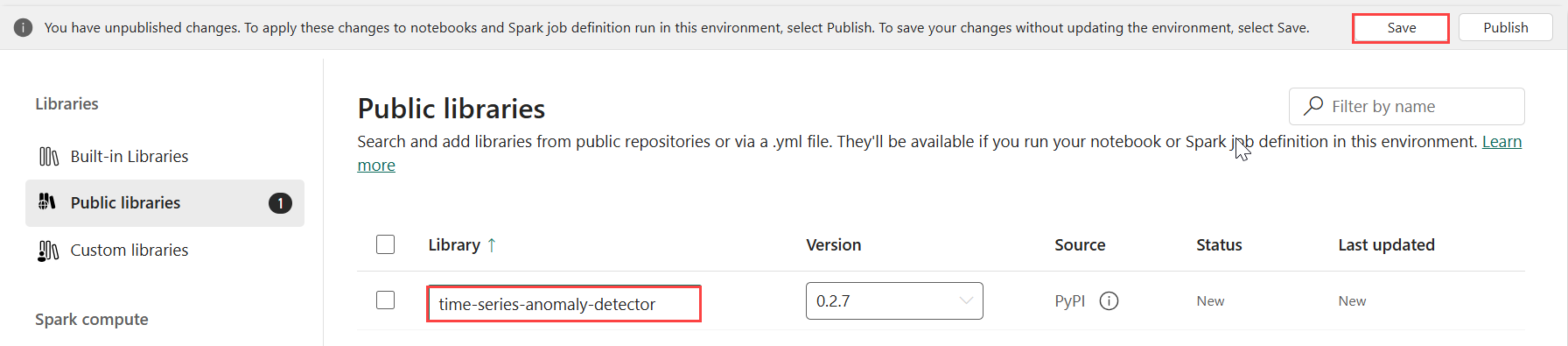
En Bibliotecas, selecciona Bibliotecas públicas.
Selecciona Agregar desde PyPI.
En el cuadro de búsqueda, escribe time-series-anomaly-detector. La versión se completa automáticamente con la versión más reciente. Este tutorial se creó con la versión 0.3.2.
Seleccione Guardar.
Selecciona la pestaña Inicios en el entorno.
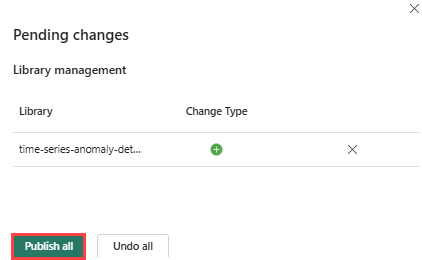
Selecciona el icono Publicar del desplegable.

Seleccione Publicar todo. Este paso puede tardar varios minutos en completarse.


Parte 4: Obtención de datos en Eventhouse
Mueve el puntero sobre la base de datos de KQL en la que quieres almacenar los datos. Selecciona el menú Más [...]>Obtener datos>Archivo local.
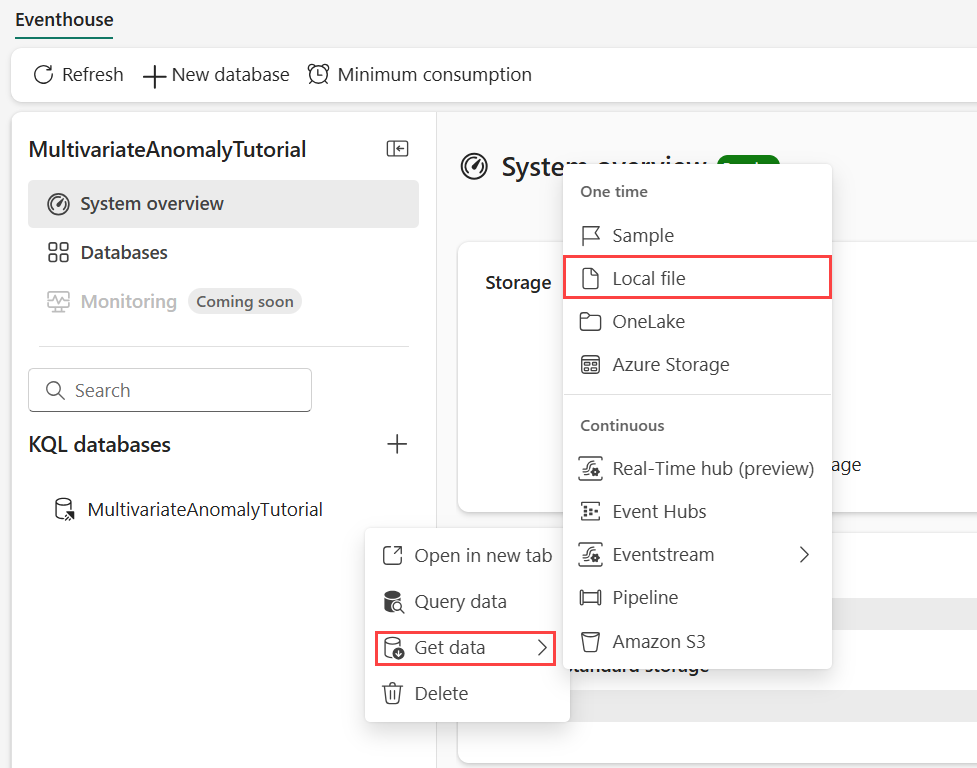
Selecciona + Nueva tabla y escribe demo_stocks_change como nombre de tabla.
En el cuadro de diálogo cargar datos, selecciona Buscar archivos y carga el archivo de datos de ejemplo que descargaste en los Requisitos previos
Seleccione Siguiente.
En la sección Inspeccionar los datos, cambia el botón de La primera fila es el encabezado de columna a Activado.
Seleccione Finalizar.
Una vez que los datos estén subidos, selecciona Cerrar.
Parte 5: Copia de la ruta de acceso OneLake a la tabla
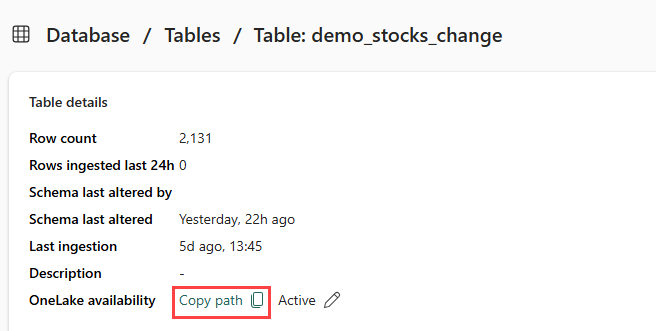
Asegúrate de seleccionar la tabla demo_stocks_change. En el panel Detalles de la tabla, seleccione Carpeta OneLake para copiar la ruta de acceso de OneLake en el Portapapeles. Guarda este texto copiado en un editor de texto en algún lugar para usarlo en un paso posterior.
Parte 6: Preparación del cuaderno
Seleccione su área de trabajo.
Seleccione Importar, cuaderno y luego Desde este equipo.
Selecciona Cargar y elige el cuaderno que descargaste en Requisitos previos.
Una vez cargado el cuaderno, puede encontrar y abrir el cuaderno desde el área de trabajo.
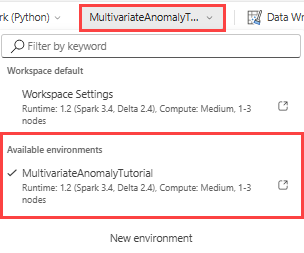
En el desplegable superior, selecciona el menú desplegable Área de trabajo predeterminada y selecciona el entorno que creaste en el paso anterior.
Parte 7: Ejecución del cuaderno
Importar paquetes estándar.
import numpy as np import pandas as pdSpark necesita un identificador URI de ABFSS para conectarse de forma segura a OneLake Storage, por lo que el siguiente paso define esta función para convertir el URI de OneLake en URI de ABFSS.
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uriReemplace el marcador de posición OneLakeTableURI por su URI de OneLake copiada de Parte 5: Copiar la ruta de OneLake a la tabla para cargar la tabla demo_stocks_change en un dataframe de pandas.
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]Ejecuta las celdas siguientes para preparar los dataframes de entrenamiento y predicción.
Nota:
Eventhouse ejecutará las predicciones reales en los datos en la Parte 9: Predicción de anomalías en el conjunto de consultas KQL. En un escenario de producción, si transmitieras datos al centro de eventos, las predicciones se realizarían en los nuevos datos de streaming. Para el tutorial, el conjunto de datos se ha dividido por fecha en dos secciones para el entrenamiento y la predicción. Esto es para simular datos históricos y nuevos datos de streaming.
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')Ejecuta las celdas para entrenar el modelo y guárdala en el registro de modelos de MLflow de Fabric.
import mlflow from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name="mvad_5_stocks_model", )Ejecute la celda siguiente para extraer la ruta de acceso del modelo registrado que se usará para la predicción mediante el entorno aislado de Kusto Python.
mi = mlflow.search_registered_models(filter_string="name='mvad_5_stocks_model'")[0] model_abfss = mi.latest_versions[0].source print(model_abfss)Copie el URI del modelo de la última salida de celda para su uso en un paso posterior.
Parte 8: Configuración del conjunto de consultas KQL
Para obtener información general, consulta Creación de un conjunto de consultas KQL.
- Desde su área de trabajo, seleccione +Nuevo elemento>Conjunto de consultas KQL.
- Introduzca el nombre MultivariateAnomalyDetectionTutorialy luego seleccione Crear.
- En la ventana del centro de datos de OneLake, selecciona la base de datos KQL donde almacenaste los datos.
- Seleccione Conectar.
Parte 9: Predicción de anomalías en el conjunto de consultas KQL
Ejecute la siguiente consulta ".create-or-alter function" para definir la función almacenada
predict_fabric_mvad_fl():.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }Ejecute la siguiente consulta de predicción y reemplace el URI del modelo de salida por el URI copiado al final de paso 7.
La consulta detecta anomalías multivariadas en los cinco valores, en función del modelo entrenado, y representa los resultados como
anomalychart. Los puntos anómalos se representan en la primera acción (AAPL), aunque representan anomalías multivariantes (es decir, anomalías de los cambios conjuntos de las cinco existencias en la fecha específica).let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
El gráfico de anomalías resultante debe tener un aspecto similar a la siguiente imagen:

Limpieza de recursos
Cuando termine el tutorial, puede eliminar los recursos que creó para evitar incurrir en otros costos. Para eliminar los recursos, siga estos pasos:
- Vaya a la página principal del área de trabajo.
- Elimina el entorno que hayas creado en este tutorial.
- Elimine el cuaderno que haya creado en este tutorial.
- Elimine el Eventhouse o la base de datos usados en este tutorial.
- Elimina el conjunto de consultas KQL que hayas creado en este tutorial.