Integración de Unity Catalog de Databricks con OneLake
En este escenario, se muestra cómo integrar tablas delta externas de Unity Catalog en OneLake mediante accesos directos. Después de completar este tutorial, podrá sincronizar automáticamente las tablas delta externas de Unity Catalog con un almacén de lago de Microsoft Fabric.
Requisitos previos
Antes de conectarse, debe tener:
- Un área de trabajo de Fabric.
- Un almacén de lago de Fabric en su área de trabajo.
- Tablas delta de Unity Catalog externas creadas en el área de trabajo de Azure Databricks.
Configuración de la conexión de almacenamiento en la nube
En primer lugar, examine qué ubicaciones de almacenamiento de Azure Data Lake Storage Gen2 (ADLS Gen2) usan las tablas de Unity Catalog. Los accesos directos de OneLake usan esta conexión de almacenamiento en la nube. Para crear una conexión en la nube a la ubicación de almacenamiento de Unity Catalog adecuada:
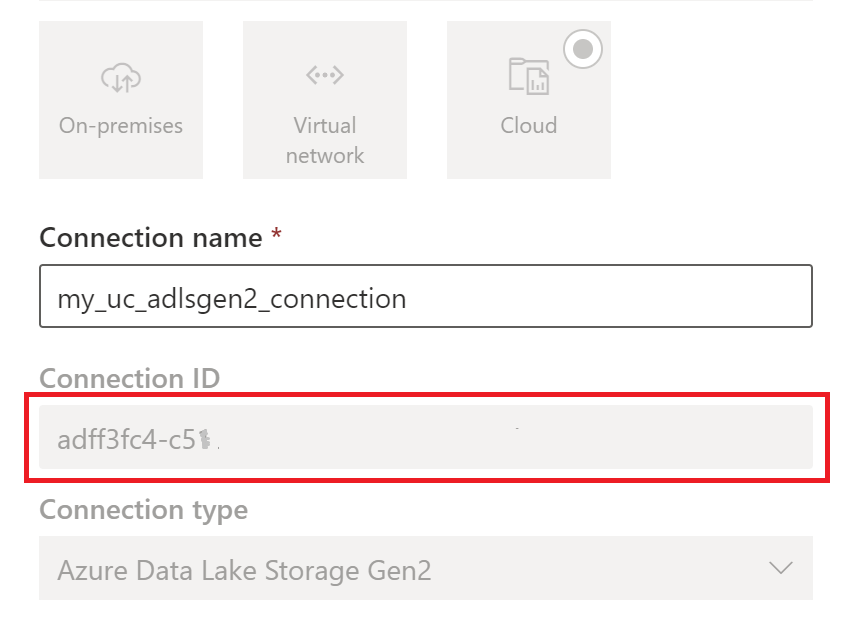
Cree una conexión de almacenamiento en la nube que usen las tablas de Unity Catalog. Consulte cómo configurar una conexión de ADLS Gen2.
Una vez creada la conexión, obtenga el ID de conexión seleccionando Configuración
 >Gestionar conexiones y puertas de enlace>Configuración> de conexiones.
>Gestionar conexiones y puertas de enlace>Configuración> de conexiones.
Nota:
La concesión a los usuarios de acceso de nivel de almacenamiento directo a un almacenamiento de ubicación externa en ADLS Gen2 no respeta los permisos concedidos ni las auditorías que mantiene Unity Catalog. El acceso directo omitirá la auditoría, el linaje y otras características de supervisión de seguridad de Unity Catalog, incluido el control de acceso y los permisos. Es responsable de administrar el acceso al almacenamiento directo a través de ADLS Gen2 y de asegurarse de que los usuarios tengan los permisos adecuados concedidos a través de Fabric. Evite todos los escenarios que conceden acceso de escritura de nivel de almacenamiento directo para depósitos que almacenan tablas administradas de Databricks. La modificación, eliminación o evolución de cualquier objeto directamente a través del almacenamiento administrado originalmente por Unity Catalog puede provocar daños en los datos.
Ejecución del cuaderno
Una vez obtenido el id. de conexión en la nube, integre las tablas de Unity Catalog en el almacén de lago de Fabric de la siguiente manera:
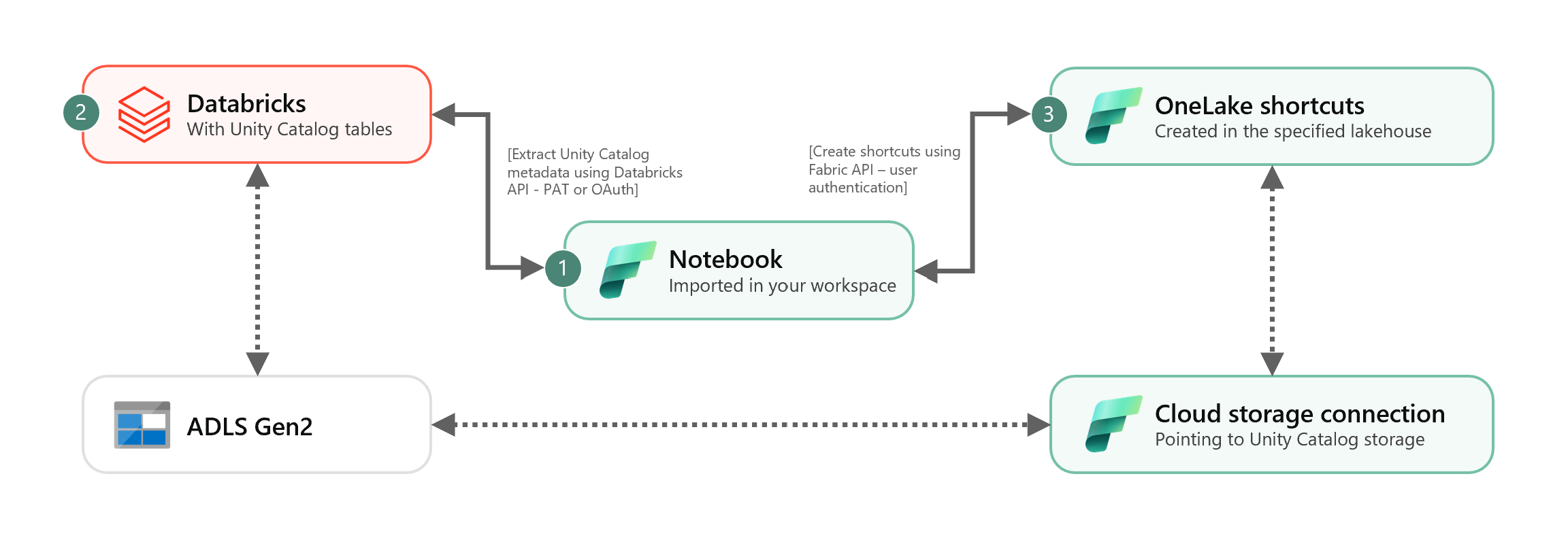
Importe el cuaderno de sincronización en el área de trabajo de Fabric. Este cuaderno exporta todos los metadatos de las tablas de Unity Catalog de un catálogo y esquemas determinados en el metastore.
Configure los parámetros en la primera celda del cuaderno para integrar tablas de Unity Catalog. La API de Databricks, que se autentica a través del token PAT, se usa para exportar tablas de Unity Catalog. El siguiente fragmento se usa para configurar los parámetros de origen (Unity Catalog) y de destino (OneLake). Asegúrese de reemplazarlos por sus propios valores.
# Databricks workspace dbx_workspace = "<databricks_workspace_url>" dbx_token = "<pat_token>" # Unity Catalog dbx_uc_catalog = "catalog1" dbx_uc_schemas = '["schema1", "schema2"]' # Fabric fab_workspace_id = "<workspace_id>" fab_lakehouse_id = "<lakehouse_id>" fab_shortcut_connection_id = "<connection_id>" # If True, UC table renames and deletes will be considered fab_consider_dbx_uc_table_changes = TrueEjecute todas las celdas del cuaderno para iniciar la sincronización de las tablas delta de Unity Catalog con OneLake mediante accesos directos. Una vez completado el cuaderno, los accesos directos a las tablas delta de Unity Catalog están disponibles en el almacén de lago, el punto de conexión de análisis de SQL y el modelo semántico.
Programación del cuaderno
Si desea ejecutar el cuaderno a intervalos regulares para integrar tablas delta de Unity Catalog en OneLake sin volver sincronizar o volver a ejecutar manualmente, puede programar el cuaderno o usar una actividad de cuaderno en una canalización de datos en Fabric Data Factory.
En el último escenario, si piensa pasar parámetros desde la canalización de datos, designe la primera celda del cuaderno como una celda de parámetro de alternancia y proporcione los parámetros adecuados en la canalización.

Otras consideraciones
- En escenarios de producción, se recomienda usar Databricks OAuth para la autenticación y Azure Key Vault para administrar los secretos. Por ejemplo, puede usar las utilidades de credenciales de MSSparkUtils para acceder a los secretos de Key Vault.
- El cuaderno funciona con tablas delta externas de Unity Catalog. Si usa varias ubicaciones de almacenamiento en la nube para las tablas de Unity Catalog, es decir, más de una instancia de ADLS Gen2, la recomendación es ejecutar el cuaderno por separado por cada conexión en la nube.
- No se admiten las tablas delta administradas por Unity Catalog, las vistas, las vistas materializadas, las tablas de streaming y las tablas que no son delta.
- Los cambios realizados en los esquemas de tablas de Unity Catalog, como agregar o eliminar columnas, se reflejan automáticamente en los accesos directos. Sin embargo, algunas actualizaciones, como el cambio de nombre y eliminación de la tabla de Unity Catalog, requieren volver a sincronizar o volver a ejecutar los cuadernos. Esto se considera según el parámetro
fab_consider_dbx_uc_table_changes. - En los escenarios de escritura, el uso de la misma capa de almacenamiento en distintos motores de proceso puede dar lugar a consecuencias no deseadas. Asegúrese de comprender las implicaciones al usar diferentes motores de proceso de Apache Spark y versiones en tiempo de ejecución.