Uso de tablas de Iceberg con OneLake
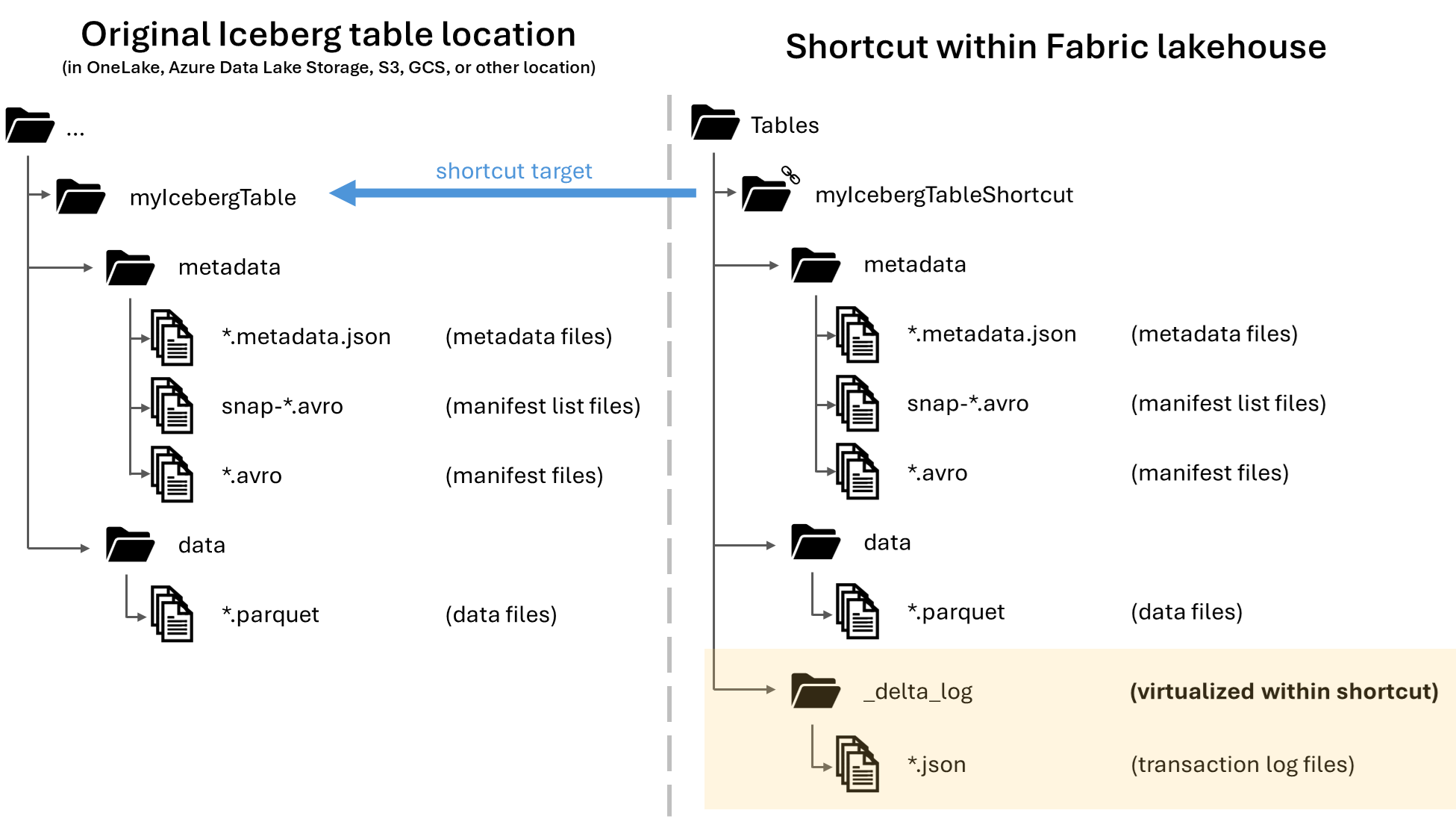
En Microsoft OneLake, es posible crear accesos directos a las tablas de Apache Iceberg, lo que permite su uso en todas las cargas de trabajo de Fabric. Esta funcionalidad se hace posible a través de una característica denominada virtualización de metadatos, permitiendo que las tablas de Iceberg se interpreten como tablas de Delta Lake desde la perspectiva del acceso directo. Cuando se crea un acceso directo a una carpeta de tabla de Iceberg, OneLake genera automáticamente los metadatos correspondientes de Delta Lake (el registro Delta) para esa tabla, haciendo que los metadatos de Delta Lake sean accesibles a través del acceso directo.
Importante
Esta característica se encuentra en versión preliminar.
Aunque en este artículo se incluyen instrucciones para escribir tablas de Iceberg desde Snowflake a OneLake, esta característica está pensada para trabajar con cualquier tabla de Iceberg con archivos de datos de Parquet.
Crear un acceso directo de tabla a una tabla de Iceberg
En el caso de que ya disponga de una tabla de Iceberg en una ubicación de almacenamiento compatible con los accesos directos de OneLake, siga estos pasos para crear un acceso directo y hacer que la tabla de Iceberg aparezca con el formato de Delta Lake.
Búsqueda de la tabla de Iceberg. Busque dónde se almacena la tabla de Iceberg, que podría estar en Azure Data Lake Storage, OneLake, Amazon S3, Google Cloud Storage o en un servicio de almacenamiento compatible con S3.
Nota:
En el caso de que use Snowflake y no esté seguro de dónde se almacena la tabla de Iceberg, ejecute la siguiente instrucción para ver la ubicación de almacenamiento de la misma.
SELECT SYSTEM$GET_ICEBERG_TABLE_INFORMATION('<table_name>');Al ejecutar esta instrucción, se devuelve una ruta de acceso al archivo de metadatos de la tabla de Iceberg. Esta ruta de acceso indica qué cuenta de almacenamiento contiene la tabla de Iceberg. Por ejemplo, esta es la información pertinente para encontrar la ruta de acceso de una tabla de Iceberg almacenada en Azure Data Lake Storage:
{"metadataLocation":"azure://<storage_account_path>/<path_within_storage>/<table_name>/metadata/00001-389700a2-977f-47a2-9f5f-7fd80a0d41b2.metadata.json","status":"success"}La carpeta de la tabla de Iceberg debe contener una carpeta
metadata, que contiene al menos un archivo que termina en.metadata.json.En el almacén de lago de Fabric, cree un nuevo acceso directo en el área Tablas de un almacén de lago no habilitado para esquemas.
Nota:
Si se vieran esquemas como
dboen la carpeta Tablas del almacén de lago, este último estará habilitado para esquemas y aún no será compatible con esta característica.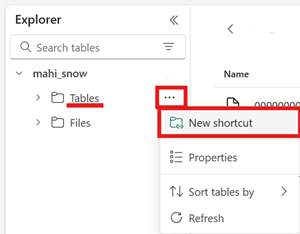
Para la ruta de acceso de destino del acceso directo, seleccione la carpeta de la tabla de Iceberg. La carpeta de la tabla de Iceberg contiene las carpetas
metadataydata.Al crear el acceso directo, se debería ver automáticamente esta tabla reflejada como tabla de Delta Lake en el almacén de lago, lista para su uso en Fabric.
En caso de que el nuevo acceso directo a la tabla de Iceberg no aparezca como una tabla utilizable, compruebe la sección Solución de problemas.
Escritura de tablas de Iceberg en OneLake mediante Snowflake
Al usar Snowflake en Azure, es posible escribir tablas de Iceberg en OneLake siguiendo estos pasos:
Asegúrese de que la capacidad de Fabric esté en la misma ubicación de Azure que la instancia de Snowflake.
Identifique la ubicación de la capacidad de Fabric asociada al almacén de lago de Fabric. Abra la configuración del área de trabajo de Fabric que contenga el almacén de lago.
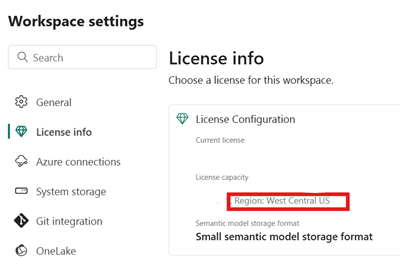
En la esquina inferior izquierda de la interfaz de la cuenta de Snowflake en Azure, compruebe la región de Azure de la cuenta de Snowflake.
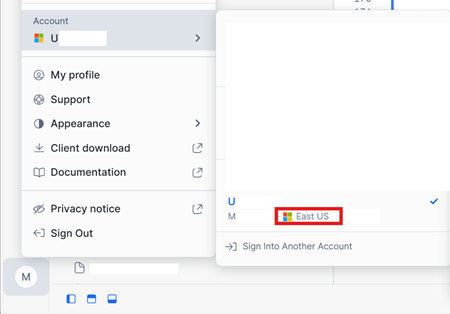
En caso de que estas regiones sean diferentes, use una capacidad de Fabric diferente en la misma región que la cuenta de Snowflake.
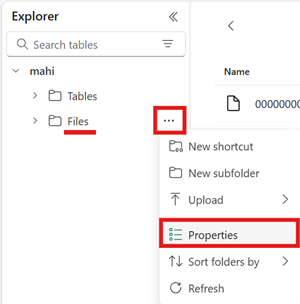
Abra el menú del área Archivos del almacén de lago, seleccione Propiedades y copie la dirección URL (la ruta de acceso HTTPS) de esa carpeta.
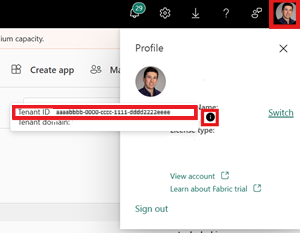
Identifique el Id. de inquilino de Fabric. Seleccione el perfil de usuario en la esquina superior derecha de la interfaz de usuario de Fabric y mantenga el puntero sobre la burbuja de información situada junto a su Nombre de inquilino. Copie el Id. de inquilino.
En Snowflake, configure el
EXTERNAL VOLUMEcon la ruta de acceso a la carpeta Archivos del almacén de lago. Encontrará más información sobre cómo configurar volúmenes externos de Snowflake aquí.Nota:
Snowflake requiere que el esquema de dirección URL sea
azure://, así que asegúrese de cambiarhttps://porazure://.CREATE OR REPLACE EXTERNAL VOLUME onelake_exvol STORAGE_LOCATIONS = ( ( NAME = 'onelake_exvol' STORAGE_PROVIDER = 'AZURE' STORAGE_BASE_URL = 'azure://<path_to_Files>/icebergtables' AZURE_TENANT_ID = '<Tenant_ID>' ) );En este ejemplo, cualquier tabla que se cree con este volumen externo se almacenará en el almacén de lago de Fabric, dentro de la carpeta
Files/icebergtables.Una vez creado el volumen externo, ejecute el siguiente comando para recuperar la dirección URL de consentimiento y el nombre de la aplicación que Snowflake usa para escribir en OneLake. Cualquier otro volumen externo de la cuenta de Snowflake usa esta aplicación.
DESC EXTERNAL VOLUME onelake_exvol;La salida de este comando devuelve las propiedades
AZURE_CONSENT_URLyAZURE_MULTI_TENANT_APP_NAME. Tome nota de ambos valores. El nombre de aplicación multiinquilino de Azure es similar a<name>_<number>, pero solo es necesario capturar la parte<name>.Abra la dirección URL de consentimiento del paso anterior en una nueva pestaña del explorador. Si desea continuar, otorgue su consentimiento a los permisos de aplicación necesarios, si se le solicita.
De nuevo en Fabric, abra el área de trabajo y seleccione Administrar acceso y, a continuación, Agregar contactos o grupos. Conceda a la aplicación que use el volumen externo de Snowflake los permisos necesarios para escribir datos en almacenes de lago en el área de trabajo. Se recomienda conceder el rol de Colaborador.
De vuelta en Snowflake, use el nuevo volumen externo para crear una tabla de Iceberg.
CREATE OR REPLACE ICEBERG TABLE MYDATABASE.PUBLIC.Inventory ( InventoryId int, ItemName STRING ) EXTERNAL_VOLUME = 'onelake_exvol' CATALOG = 'SNOWFLAKE' BASE_LOCATION = 'Inventory/';Con esta instrucción, se crea una nueva carpeta de tabla de Iceberg denominada Inventario dentro de la ruta de acceso de carpeta definida en el volumen externo.
Agregue algunos datos en la tabla de Iceberg.
INSERT INTO MYDATABASE.PUBLIC.Inventory VALUES (123456,'Amatriciana');Por último, en el área Tablas del mismo almacén de lago, cree un acceso directo de OneLake a la tabla de Iceberg. A través de ese acceso directo, la tabla de Iceberg aparecerá como una tabla de Delta Lake para su consumo en cargas de trabajo de Fabric.
Solución de problemas
Las siguientes recomendaciones pueden ayudarle a asegurarse de que las tablas de Iceberg sean compatibles con esta característica:
Compruebe la estructura de carpetas de la tabla de Iceberg
Abra la carpeta de Iceberg en la herramienta de explorador de almacenamiento que prefiera y compruebe la lista de directorios de la carpeta de Iceberg en su ubicación original. Debería ver una estructura de carpetas como la del ejemplo siguiente.
../
|-- MyIcebergTable123/
|-- data/
|-- snow_A5WYPKGO_2o_APgwTeNOAxg_0_1_002.parquet
|-- snow_A5WYPKGO_2o_AAIBON_h9Rc_0_1_003.parquet
|-- metadata/
|-- 00000-1bdf7d4c-dc90-488e-9dd9-2e44de30a465.metadata.json
|-- 00001-08bf3227-b5d2-40e2-a8c7-2934ea97e6da.metadata.json
|-- 00002-0f6303de-382e-4ebc-b9ed-6195bd0fb0e7.metadata.json
|-- 1730313479898000000-Kws8nlgCX2QxoDHYHm4uMQ.avro
|-- 1730313479898000000-OdsKRrRogW_PVK9njHIqAA.avro
|-- snap-1730313479898000000-9029d7a2-b3cc-46af-96c1-ac92356e93e9.avro
|-- snap-1730313479898000000-913546ba-bb04-4c8e-81be-342b0cbc5b50.avro
En caso de no ver la carpeta de metadatos o archivos con las extensiones que se muestran en este ejemplo, es posible que no tenga una tabla de Iceberg generada correctamente.
Comprobación del registro de conversión
Cuando una tabla de Iceberg se virtualiza como tabla de Delta Lake, se puede encontrar una carpeta denominada _delta_log/ dentro de la carpeta de acceso directo. Esta carpeta contendrá los metadatos del formato de Delta Lake (el registro Delta) después de una conversión correcta.
Esta carpeta también incluye el archivo latest_conversion_log.txt, que contiene los detalles de éxito o error de la conversión más reciente.
Para ver el contenido de este archivo después de la creación del acceso directo, abra el menú para el acceso directo de la tabla de Iceberg en el área Tablas del almacén de lago y seleccione Ver archivos.
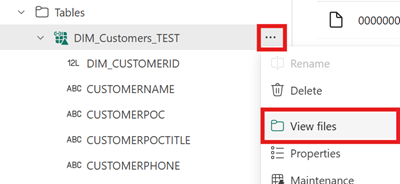
Debería mostrarse una estructura como la del ejemplo siguiente:
Tables/
|-- MyIcebergTable123/
|-- data/
|-- <data files>
|-- metadata/
|-- <metadata files>
|-- _delta_log/ <-- Virtual folder. This folder doesn't exist in the original location.
|-- 00000000000000000000.json
|-- latest_conversion_log.txt <-- Conversion log with latest success/failure details.
Abra el archivo de registro de conversión para ver la hora de conversión más reciente o los detalles del error. Si no se mostrase un archivo de registro de conversión, esta última no se intentó.
Si no se intentó la conversión
Si no se mostrase un archivo de registro de conversión, entonces esta última no se intentó. Aquí se muestran dos razones comunes por las que podría no intentarse realizar la conversión:
El acceso directo no se creó en el lugar correcto.
Para que un acceso directo a una tabla de Iceberg se convierta al formato de Delta Lake, el acceso directo deberá colocarse directamente en la carpeta Tablas de un almacén de lago no habilitado para esquemas. El acceso directo no debería colocarse en la sección Archivos o en otra carpeta en caso de querer que la tabla se virtualice automáticamente como tabla de Delta Lake.
La ruta de acceso de destino del acceso directo no es la ruta de acceso de la carpeta de Iceberg.
Al crear el acceso directo, la ruta de acceso a la carpeta que se seleccione en la ubicación de almacenamiento de destino solo deberá ser la carpeta de la tabla de Iceberg. Esta carpeta contiene las carpetas
metadataydata.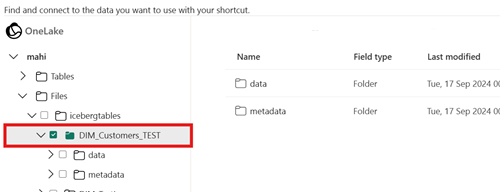
Limitaciones y consideraciones
Tenga en cuenta las siguientes limitaciones temporales al usar esta característica:
Supported data types (Tipos de datos admitidos)
Los siguientes tipos de datos de columna de Iceberg se asignan a sus tipos de Delta Lake correspondientes mediante esta característica.
Tipo de columna de Iceberg Tipo de columna de Delta Lake Comentarios intintegerlonglongConsulte Problema de ancho de tipo. floatfloatdoubledoubleConsulte Problema de ancho de tipo. decimal(P, S)decimal(P, S)Consulte Problema de ancho de tipo. booleanbooleandatedatetimestamptimestamp_ntzEl tipo de datos de Iceberg timestampno contiene información sobre zona horaria. El tipo de Delta Laketimestamp_ntzno es totalmente compatible con las cargas de trabajo de Fabric. Se recomienda el uso de marcas de tiempo con zonas horarias incluidas.timestamptztimestampPara usar este tipo en Snowflake, especifique timestamp_ltzcomo tipo de columna durante la creación de la tabla de Iceberg. Aquí encontrará más información sobre los tipos de datos de Iceberg admitidos en Snowflake.stringstringbinarybinaryProblema de ancho de tipo
En caso de usar Snowflake para escribir la tabla de Iceberg y esta contuviera tipos de columna
INT64,doubleoDecimalcon precisión >= 10, es posible que todos los motores de Fabric no consuman la tabla virtual de Delta Lake resultante. Es posible que vea errores como los siguientes:Parquet column cannot be converted in file ... Column: [ColumnA], Expected: decimal(18,4), Found: INT32.Estamos trabajando para solucionar el problema.
Solución alternativa: en caso de usar la interfaz de usuario de vista previa de la tabla del almacén de lago y ver este problema, se resolverá este error al cambiar a la vista de punto de conexión de SQL (en la esquina superior derecha, seleccione la vista de almacén de lago y cambie a Punto de conexión de SQL) y se obtendrá una vista previa de la tabla desde allí. Al volver a la vista de almacén de lago, la vista previa de la tabla debería mostrarse correctamente.
En caso de ejecutar un cuaderno o un trabajo de Spark y encontrarse este problema, se resolverá este error estableciendo la configuración de Spark de
spark.sql.parquet.enableVectorizedReaderenfalse. Este es un comando de PySpark de ejemplo para su ejecución en un cuaderno de Spark:spark.conf.set("spark.sql.parquet.enableVectorizedReader","false")El almacenamiento de metadatos de tabla de Iceberg no es portátil
Los archivos de metadatos de una tabla de Iceberg se hacen referencia entre sí mediante referencias de ruta de acceso absoluta. Al copiar o mover el contenido de la carpeta de una tabla de Iceberg a otra ubicación sin reescribir los archivos de metadatos de Iceberg, la tabla se volverá ilegible para los lectores de Iceberg, incluyendo esta característica de OneLake.
Solución alternativa:
En caso de necesitar mover la tabla de Iceberg a otra ubicación para usar esta característica, use la herramienta que originalmente escribió la tabla de Iceberg para escribir nuevas tablas de Iceberg en la ubicación deseada.
Las tablas de Iceberg deben tener una profundidad mayor que el nivel raíz
La carpeta de la tabla de Iceberg del almacenamiento debe encontrarse en un directorio más profundo que el nivel de depósito o contenedor. Es posible que las tablas de Iceberg almacenadas directamente en el directorio raíz de un depósito o contenedor no estén virtualizadas con el formato de Delta Lake.
Se está trabajando en una mejora para quitar este requisito.
Solución alternativa:
Asegúrese de que todas las tablas de Iceberg se almacenen en un directorio más profundo que el directorio raíz de un depósito o contenedor.
Las carpetas de tablas de Iceberg solo deben contener un conjunto de archivos de metadatos
Al quitar y volver a crear tablas de Iceberg en Snowflake, los archivos de metadatos no se limpiarán. Este comportamiento es compatible con la característica
UNDROPde Snowflake. Sin embargo, como el acceso directo apunta directamente a una carpeta y esa carpeta ya tiene varios conjuntos de archivos de metadatos dentro de ella, no es posible convertir la tabla hasta que se quiten los archivos de metadatos de la tabla anterior.Actualmente, la conversión se intenta en este escenario, lo que podría dar lugar a que el contenido de la tabla y la información de esquema antiguos se muestren en la tabla de Delta Lake virtualizada.
Se está trabajando en una corrección en la que se produzca un error en la conversión en caso de encontrarse más de un conjunto de archivos de metadatos en la carpeta de metadatos de la tabla de Iceberg.
Solución alternativa:
Para asegurarse de que la tabla convertida refleje la versión correcta de la tabla:
- Asegúrese de que no se esté almacenando más de una tabla de Iceberg en la misma carpeta.
- Limpie cualquier contenido de una carpeta de tabla de Iceberg después de quitarla antes de volver a crear la tabla.
Los cambios de metadatos no se reflejan inmediatamente
En caso de realizar cambios en los metadatos en la tabla de Iceberg, como agregar una columna, eliminar una columna, cambiar el nombre de una columna o cambiar un tipo de columna, es posible que la tabla no se vuelva a convertir hasta que se realice un cambio de datos, como agregar una fila de datos.
Se está trabajando en una corrección que recoja el archivo de metadatos correcto más reciente que incluya el cambio de metadatos más reciente.
Solución alternativa:
Después de realizar el cambio de esquema en la tabla de Iceberg, agregue una fila de datos o realice cualquier otro cambio en los datos. Después de ese cambio, debería poder actualizar y ver la vista más reciente de la tabla en Fabric.
Las áreas de trabajo habilitadas para esquemas aún no se admiten
Al crear un acceso directo de Iceberg en almacenes de lago habilitados para esquemas, la conversión no se producirá para ese acceso directo.
Se está trabajando en una mejora para quitar esta limitación.
Solución alternativa:
Use un almacén de lago no habilitado para esquemas con esta característica. Establezca esta configuración durante la creación del almacén de lago.
Limitación de disponibilidad de regiones
La característica aún no está disponible en las siguientes regiones:
- Centro de Catar
- Oeste de Noruega
Solución alternativa:
Las áreas de trabajo adjuntas a las capacidades de Fabric en otras regiones pueden usar esta característica. Consulte la lista completa de regiones en las que Microsoft Fabric está disponible.
Los vínculos privados no son compatibles
Esta característica no se admite actualmente para inquilinos o áreas de trabajo que tengan habilitados vínculos privados.
Se está trabajando en una mejora para quitar esta limitación.
Limitación de tamaño de tabla
Existe una limitación temporal sobre el tamaño de las tablas de Iceberg compatibles con esta característica. El número máximo admitido de archivos de datos de Parquet es de unos 5000 archivos de datos, o bien de aproximadamente mil millones de filas, cualquiera que sea el límite que se alcance primero.
Se está trabajando en una mejora para quitar esta limitación.
Los accesos directos de OneLake deben ser de la misma región
Existe una limitación temporal sobre el uso de esta característica con accesos directos que apunten a ubicaciones de OneLake: la ubicación de destino del acceso directo debe estar en la misma región que el propio acceso directo.
Se está trabajando en una mejora para quitar este requisito.
Solución alternativa:
En caso de tener un acceso directo de OneLake a una tabla de Iceberg en otro almacén de lago, asegúrese de que el otro almacén de lago esté asociado a una capacidad de la misma región.
Contenido relacionado
- Más información sobre la seguridad de Fabric y OneLake.
- Obtenga más información sobre los accesos directos de OneLake.