Tutorial Parte 2: Exploración y visualización de datos mediante cuadernos de Microsoft Fabric
En este tutorial, aprenderá a realizar análisis exploratorios de datos (EDA) para examinar e investigar los datos al resumir sus características clave mediante el uso de técnicas de visualización de datos.
Usará seaborn, una biblioteca de visualización de datos de Python que proporciona una interfaz de alto nivel para crear objetos visuales en tramas de datos y matrices. Para obtener más información sobre seaborn, vea Seaborn: Estadísticas de visualización de datos.
También usará Data Wrangler, una herramienta basada en cuadernos que le proporciona una experiencia inmersiva para realizar análisis y limpieza exploratorios de datos.
Los pasos principales de este tutorial son:
- Lea los datos almacenados de una tabla delta en el almacén de lago de datos.
- Convierta un DataFrame de Spark en DataFrame de Pandas, que admiten las bibliotecas de visualización de Python.
- Utiliza Data Wrangler para realizar la limpieza y transformación iniciales de datos.
- Realice análisis de datos exploratorios mediante
seaborn.
Prerrequisitos
Obtenga una suscripción a Microsoft Fabric. También puede registrarse para obtener una evaluación gratuita de Microsoft Fabric.
Inicie sesión en Microsoft Fabric.
Use el conmutador de experiencia en la parte inferior izquierda de la página principal para cambiar a Fabric.

Esta es la parte 2 de 5 de la serie de tutoriales. Para completar este tutorial, primero complete:
Continuación en el cuaderno
2-explore-cleanse-data.ipynb es el cuaderno que acompaña a este tutorial.
A fin de abrir el cuaderno complementario para este tutorial, siga las instrucciones de Preparación del sistema para los tutoriales de ciencia de datos, para importar el cuaderno al área de trabajo.
Si prefiere copiar y pegar el código de esta página, puede crear un cuaderno nuevo.
Asegúrese de adjuntar un almacén de lago de datos al cuaderno antes de empezar a ejecutar código.
Importante
Adjunte la misma casa de lago que usó en la parte 1.
Lectura de datos sin procesar desde el almacén de lago de datos
Lea datos sin procesar de la sección Archivos del lago de datos. Subiste estos datos en el cuaderno anterior. Asegúrese de que ha adjuntado el mismo lago de datos que ha usado en la Parte 1 de este cuaderno antes de ejecutar este código.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Creación de un dataFrame de Pandas a partir del conjunto de datos
Convierta el DataFrame de Spark en dataFrame de Pandas para facilitar el procesamiento y la visualización.
df = df.toPandas()
Mostrar datos sin procesar
Explore los datos sin procesar con display, realice algunas estadísticas básicas y muestre las vistas del gráfico. Tenga en cuenta que primero debe importar las bibliotecas necesarias, como Numpy, Pnadas, Seaborny Matplotlib para el análisis y la visualización de datos.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Utilice Data Wrangler para realizar la limpieza inicial de datos
Para explorar y transformar cualquier dataframe de Pandas, inicie Limpieza y transformación de datos directamente desde el cuaderno.
Nota
Data Wrangler no se puede abrir mientras el kernel del notebook está ocupado. Se debe completar la ejecución de la celda antes de iniciar Limpieza y transformación de datos.
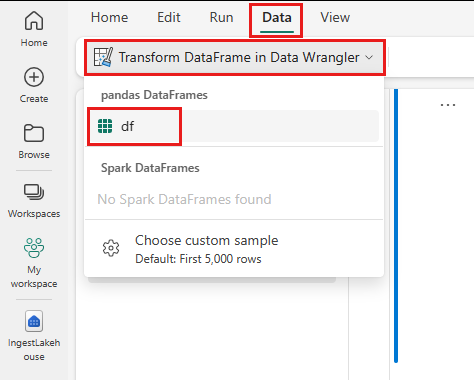
- En la pestaña Datos de la cinta del cuaderno, seleccione Iniciar Limpieza y transformación de datos. Verá una lista de dataframes de Pandas activados disponibles para su edición.
- Seleccione el DataFrame que desea abrir en Data Wrangler. Dado que este cuaderno solo contiene un dataframe,
df, seleccionedf.
Data Wrangler se inicia y genera una visión general descriptiva de tus datos. En la tabla central se muestra cada columna de datos. El panel resumen junto a la tabla muestra información sobre el dataframe. Al seleccionar una columna en la tabla, el resumen se actualiza con información sobre la columna seleccionada. En algunos casos, los datos mostrados y resumidos serán una vista truncada del dataframe. Cuando esto suceda, verá la imagen de advertencia en el panel de resumen. Mantenga el puntero sobre esta advertencia para ver el texto que explica la situación.

Cada operación que haga se puede aplicar en cuestión de clics, actualizando la visualización de datos en tiempo real y generando código que puede guardar de nuevo en el cuaderno como una función reutilizable.
El resto de esta sección le guía por los pasos para realizar la limpieza de datos con Data Wrangler.
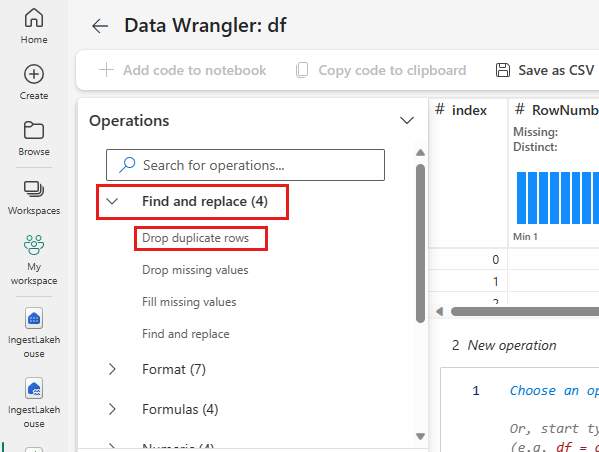
Quitar filas duplicadas
En el panel izquierdo se muestra una lista de operaciones (como Buscar y reemplazar, Format, Formulas, Numeric) que puede realizar en el conjunto de datos.
Expanda Buscar y reemplazar, y seleccione Quitar filas duplicadas.
Aparece un panel para seleccionar la lista de columnas que desea comparar para definir una fila duplicada. Seleccione RowNumber y CustomerId.
En el panel central se muestra una vista previa de los resultados de esta operación. En la vista previa se muestra el código para realizar la operación. En esta instancia, los datos parecen no modificarse. Pero como examina una vista truncada, es recomendable seguir aplicando la operación.
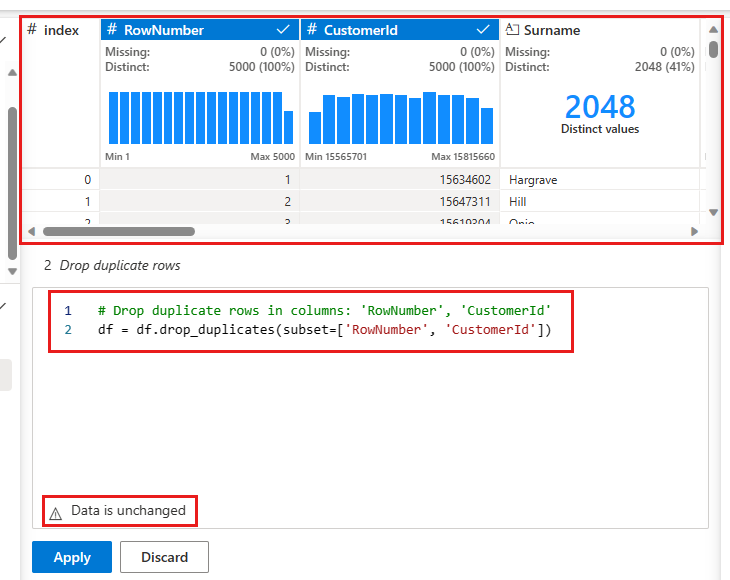
Seleccione Aplicar (ya sea en el lado o en la parte inferior) para ir al paso siguiente.

Quitar filas con datos que faltan
Utiliza Data Wrangler para eliminar filas con datos faltantes en cualquier columna.
Seleccione Eliminar valores faltantes de Buscar y reemplazar.
Elija Seleccionar todo en Columnas de destino.
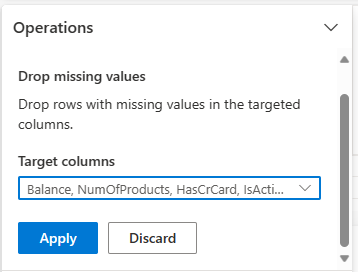
Seleccione Aplicar para ir al paso siguiente.

Eliminación de columnas
Utilice Data Wrangler para quitar columnas que no necesita.
Expanda Esquema y seleccione Quitar columnas.
Seleccione RowNumber, CustomerId y Surname. Estas columnas aparecen en rojo en la versión preliminar para mostrar que el código las cambia (en este caso, las elimina).
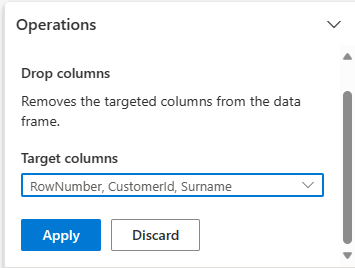
Seleccione Aplicar para ir al paso siguiente.

Adición de código al cuaderno
Cada vez que seleccione Aplicar, se crea un paso en el panel Pasos de limpieza la parte inferior izquierda. En la parte inferior del panel, seleccione Código de vista previa para todos los pasos a fin de ver una combinación de todos los pasos independientes.
Seleccione Agregar código al cuaderno en la parte superior izquierda para cerrar Data Wrangler y agregar el código automáticamente. En Agregar código al cuaderno se encapsula el código en una función, que después se llama.
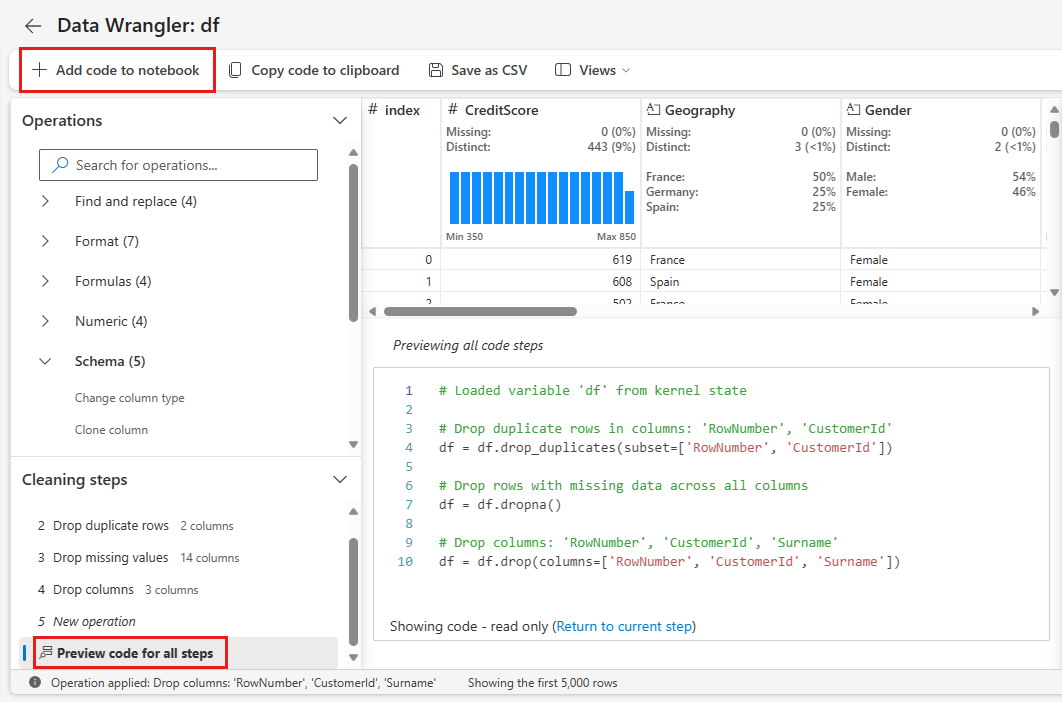
Sugerencia
El código generado por Data Wrangler no se aplicará hasta que ejecute manualmente la nueva celda.
Si no usó Data Wrangler, puede usar esta celda de código siguiente.
Este código es similar al código generado por Data Wrangler, pero agrega el argumento inplace=True a cada uno de los pasos generados. Al establecer inplace=True, pandas sobrescribirá el dataframe original en lugar de generar un nuevo dataframe como salida.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
Exploración de los datos
Muestra algunos resúmenes y visualizaciones de los datos limpios.
Determinar atributos categóricos, numéricos y de destino
Use este código para determinar atributos categóricos, numéricos y de destino.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
Resumen de los cinco números estadísticos
Muestre el resumen de cinco números (la puntuación mínima, el primer cuartil, la mediana, el tercer cuartil, la puntuación máxima) para los atributos numéricos, mediante trazados de cuadros.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
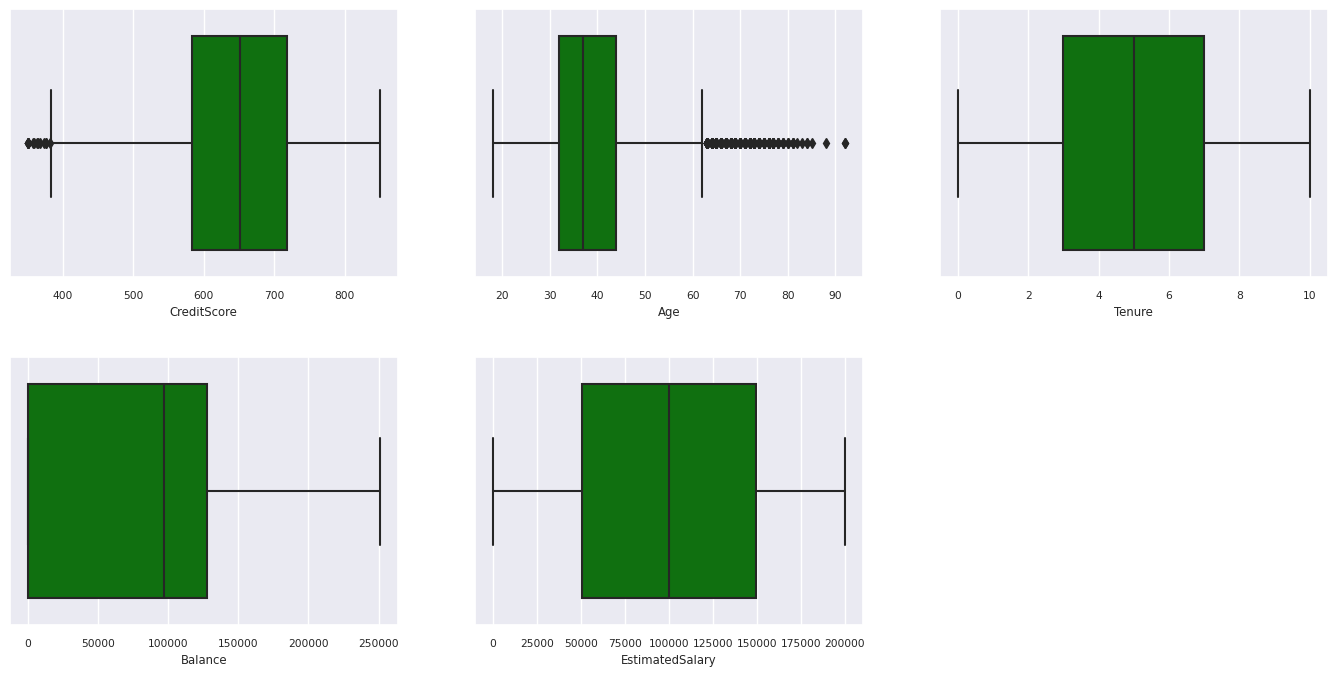
Distribución de clientes de salida y de no salida
Mostrar la distribución de clientes que se han dado de baja frente a los que no se han dado de baja en relación con los atributos categóricos.
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)

Distribución de atributos numéricos
Mostrar la distribución de frecuencia de los atributos numéricos mediante histograma.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

Ingeniería de características
Realice la ingeniería de características para generar nuevos atributos basados en los atributos actuales:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Uso de Limpieza y transformación de datos para realizar la codificación de un solo uso
Limpieza y transformación de datos también se puede usar para realizar la codificación de un solo uso. Para ello, vuelva a abrir Wrangler de datos. Esta vez, seleccione los datos df_clean.
- Expanda Fórmulas y seleccione Codificación de un solo uso.
- Aparecerá un panel para que seleccione la lista de columnas en las que desea realizar la codificación one-hot. Seleccione Geografía y Género.
Puede copiar el código generado, cerrar Data Wrangler para volver al cuaderno y, a continuación, pegarlo en una nueva celda. O bien, seleccione Agregar código al cuaderno en la parte superior izquierda para cerrar Data Wrangler y agregar el código automáticamente.
Si no usó Data Wrangler, puede usar esta celda de código siguiente:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
Resumen de las observaciones del análisis de datos exploratorios
- La mayoría de los clientes son de Francia en comparación con España y Alemania, mientras que España tiene la tasa de renovación más baja en comparación con Francia y Alemania.
- La mayoría de los clientes tienen tarjetas de crédito.
- Hay clientes cuya edad y puntuación de crédito están por encima de 60 y por debajo de 400, respectivamente, pero no se pueden considerar valores atípicos.
- Muy pocos clientes tienen más de dos de los productos del banco.
- Los clientes que no están activos tienen una tasa de renovación más alta.
- Los años de género y antigüedad no parecen tener un impacto en la decisión del cliente de cerrar la cuenta bancaria.
Creación de una tabla delta para los datos limpios
Usará estos datos en el siguiente cuaderno de esta serie.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
Paso siguiente
Entrenamiento y registro de modelos de Machine Learning con estos datos: