Planeamiento de la migración desde Azure Data Factory
Microsoft Fabric es el producto SaaS de análisis de datos de Microsoft que reúne todos los productos de análisis líderes en el mercado de Microsoft en una sola experiencia de usuario. Fabric Data Factory proporciona orquestación de flujo de trabajo, movimiento de datos, replicación de datos y transformación de datos a escala con funcionalidades similares que se encuentran en Azure Data Factory (ADF). Si tiene inversiones existentes en ADF que desea modernizar a Fabric Data Factory, este documento es útil para ayudarle a comprender las consideraciones de migración, las estrategias y los enfoques.
La migración desde los servicios de ETL/DI de PaaS de Azure y las canalizaciones y flujos de datos de ADF y Synapse puede proporcionar varias ventajas importantes:
- Las nuevas características de canalización integradas, incluidas las actividades de correo electrónico y de Teams, permiten el enrutamiento sencillo de mensajes durante la ejecución del pipeline.
- Las características integradas de integración y entrega continua (CI/CD) (canalizaciones de implementación) no requieren integración externa con repositorios de Git.
- La integración del área de trabajo con el lago de datos de OneLake permite la administración centralizada y sencilla de los análisis.
- La actualización de los modelos de datos semánticos es fácil en Fabric con una actividad de canalización totalmente integrada.
Microsoft Fabric es una plataforma integrada para datos empresariales de autoservicio y gestionados por TI. Con un crecimiento exponencial en volúmenes de datos y complejidad, los clientes de Fabric exigen soluciones empresariales que se escalan, son seguras, fáciles de administrar y accesibles para todos los usuarios de la mayor parte de las organizaciones.
En los últimos años, Microsoft invertía importantes esfuerzos para ofrecer funcionalidades de nube escalables a Premium. Para ello, Data Factory en Fabric permite al instante un gran ecosistema de desarrolladores de integración de datos y soluciones de integración de datos que se crearon durante décadas para aplicar el conjunto completo de características y funcionalidades que van mucho más allá de la funcionalidad comparable disponible en generaciones anteriores.
Naturalmente, los clientes preguntan si hay una oportunidad para consolidar hospedando sus soluciones de integración de datos en Fabric. Entre las preguntas comunes se incluyen:
- ¿Funciona toda la funcionalidad de la que dependemos en las canalizaciones de Fabric?
- ¿Qué funcionalidades solo están disponibles en las canalizaciones de Fabric?
- ¿Cómo se migran las canalizaciones existentes a canalizaciones de Fabric?
- ¿Cuál es la hoja de ruta de Microsoft para la ingesta de datos empresariales?
Diferencias de plataforma
Al migrar una instancia completa de ADF, hay muchas diferencias importantes que se deben tener en cuenta entre ADF y Data Factory en Fabric, lo que es importante a medida que se migra a Fabric. Exploramos varias de esas diferencias importantes en esta sección.
Para obtener una comprensión más detallada del mapeo funcional de las diferencias entre las características de Azure Data Factory y Fabric Data Factory, consulte Comparación de Data Factory en Fabric y Azure Data Factory.
Integration Runtime
En ADF, los entornos de ejecución de integración (IRs) son objetos de configuración que representan la capacidad de cómputo que utiliza ADF para completar el procesamiento de datos. Estas propiedades de configuración incluyen la región de Azure para el cálculo en la nube y los tamaños de computación de Spark para procesos de flujo de datos. Otros tipos de IR incluyen los IR autohospedados (SHIR) para la conectividad de datos local, los IR de SSIS para ejecutar paquetes de SQL Server Integration Services y los IR en la nube habilitados para redes virtuales.
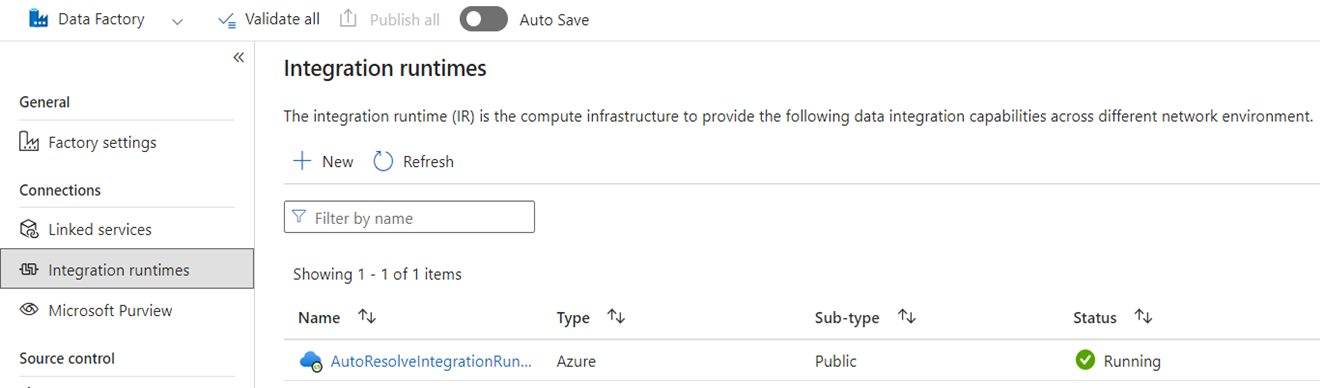
Microsoft Fabric es un producto de software como servicio (SaaS), mientras que ADF es un producto de plataforma como servicio (PaaS). Lo que significa esta distinción en términos de entornos de ejecución de integración es que no es necesario configurar nada para usar canalizaciones o flujos de datos en Fabric, ya que el valor predeterminado es usar el proceso basado en la nube en la región donde se encuentran las capacidades de Fabric. Las instancias de ejecución de SSIS no existen en Fabric, y para la conectividad de datos local se utiliza un componente específico de Fabric conocido como la puerta de enlace de datos local (OPDG). Además, para la conectividad basada en redes virtuales a redes protegidas, use la puerta de enlace de datos de red virtual en Fabric.
Al migrar de ADF a Fabric, no es necesario migrar las direcciones IP de Azure (nube) de red pública. Debe recrear los SHIR como OPDG y las IR de Azure habilitadas para la red virtual como puertas de enlace de datos de red virtual.
Tuberías
Las canalizaciones son el componente fundamental de ADF, que se usa para el flujo de trabajo principal y la orquestación de los procesos de ADF para el movimiento de datos, la transformación de datos y la orquestación de procesos. Las canalizaciones de Fabric Data Factory son casi idénticas a ADF, pero con componentes adicionales que se ajustan al modelo SaaS basado en power BI. Esta similitud incluye actividades nativas para correos electrónicos, Teams y actualizaciones del modelo semántico.
La definición JSON de las canalizaciones de Fabric Data Factory difiere ligeramente de ADF debido a las diferencias en el modelo de aplicación entre los dos productos. Debido a esta diferencia, no es posible copiar o pegar JSON de canalización, importar/exportar canalizaciones, o apuntar a un repositorio de Git de ADF.
Al volver a generar las canalizaciones de ADF como canalizaciones de Fabric, se utilizan esencialmente los mismos modelos y aptitudes de flujo de trabajo que usó en ADF. La consideración principal tiene que ver con los servicios vinculados y los conjuntos de datos, que son conceptos de ADF que no existen en Fabric.
Servicios vinculados
En ADF, los servicios vinculados definen las propiedades de conectividad necesarias para conectarse a los almacenes de datos para las actividades de movimiento de datos, transformación de datos y procesamiento de datos. En Fabric, debe volver a crear estas definiciones como Conexiones que son propiedades para sus actividades como Copiar y Flujos de datos.
Conjuntos de datos
Los conjuntos de datos definen la forma, la ubicación y el contenido de los datos en ADF, pero no existen como entidades en Fabric. Para definir propiedades de datos como tipos de datos, columnas, carpetas, tablas, etc. en canalizaciones de Fabric Data Factory, defina estas características insertadas dentro de las actividades de canalización y dentro del objeto Connection al que se hace referencia anteriormente en la sección Servicio vinculado.
Flujos de datos
En Data Factory for Fabric, el término flujos de datos hace referencia a las actividades de transformación de datos sin código, mientras que en ADF, la misma característica se conoce como flujos de datos. Los flujos de datos de Fabric Data Factory tienen una interfaz de usuario basada en Power Query, que se usa en la actividad de Power Query de ADF. El cómputo utilizado para procesar flujos de datos en Fabric es un motor de ejecución nativo que puede escalar horizontalmente para la transformación de datos a gran escala mediante el nuevo motor de cómputo de Fabric Data Warehouse.
En ADF, los flujos de datos se basan en la infraestructura de Spark de Synapse y se definen mediante una interfaz de usuario de construcción que usa un lenguaje específico del dominio subyacente (DSL) conocido como script de flujo de datos. Este lenguaje de definición difiere considerablemente de los flujos de datos basados en Power Query en Fabric que usan un lenguaje de definición conocido como M para definir su comportamiento. Debido a estas diferencias en las interfaces de usuario, los lenguajes y los motores de ejecución, los flujos de datos de Fabric y los flujos de datos de ASF no son compatible y necesita volver a crear los flujos de datos de ADF como flujos de datos de Fabric al actualizar las soluciones a Fabric.
Desencadenantes
Los desencadenadores activan ADF para ejecutar una canalización basada en una programación en base a tiempo real, ventanas de tiempo de tamaño constante, eventos basados en archivos o eventos personalizados. Estas características son similares en Fabric, aunque la implementación subyacente es diferente.
En Fabric, los desencadenadores solo existen como un concepto de tubería. El marco más amplio que utilizan los desencadenadores de canalización en Fabric es conocido como Activador de datos, que es un subsistema de eventos y alertas de las características de Inteligencia en tiempo real de Fabric.
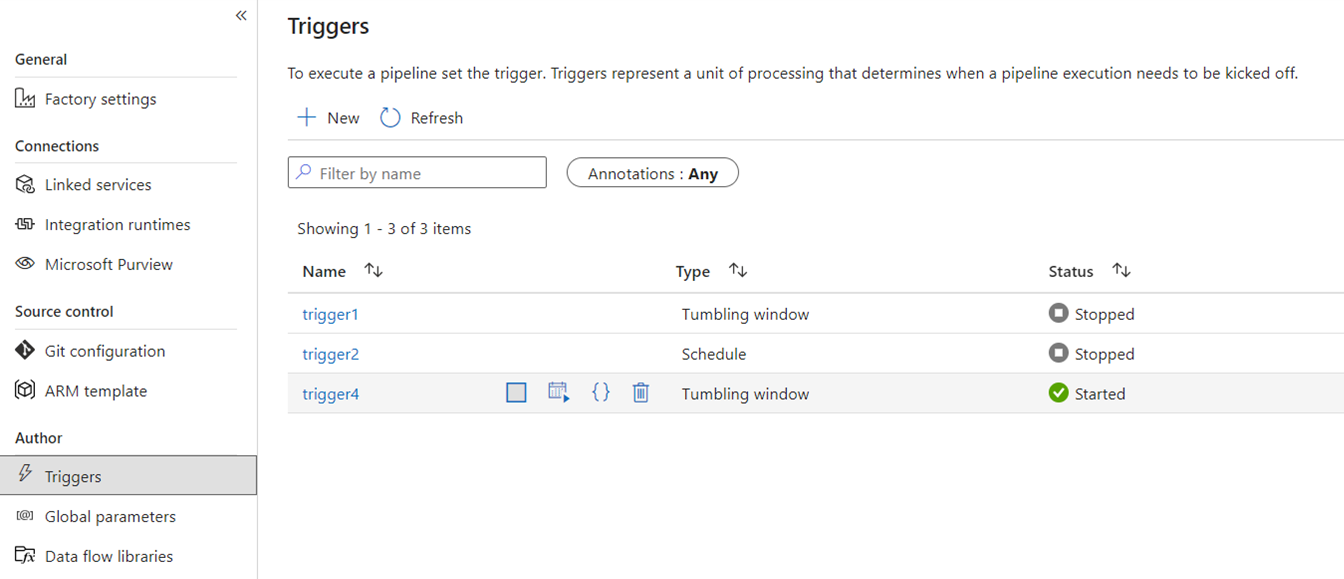
Fabric Data Activator tiene alertas que se pueden usar para crear desencadenadores de eventos de archivo y eventos personalizados. Aunque los desencadenadores de programación son una entidad independiente en Fabric conocida como programaciones. Estas programaciones se encuentran en un nivel de plataforma en Fabric y no son específicas de las canalizaciones. Tampoco se conocen como desencadenadores en Fabric.
Para migrar los desencadenadores de ADF a Fabric, piense en volver a generar los desencadenadores de programación simplemente como programaciones que son propiedades de las canalizaciones de Fabric. Y para todos los demás tipos de desencadenadores, use el botón Desencadenadores dentro de la canalización de Fabric o use Data Activator de forma nativa en Fabric.
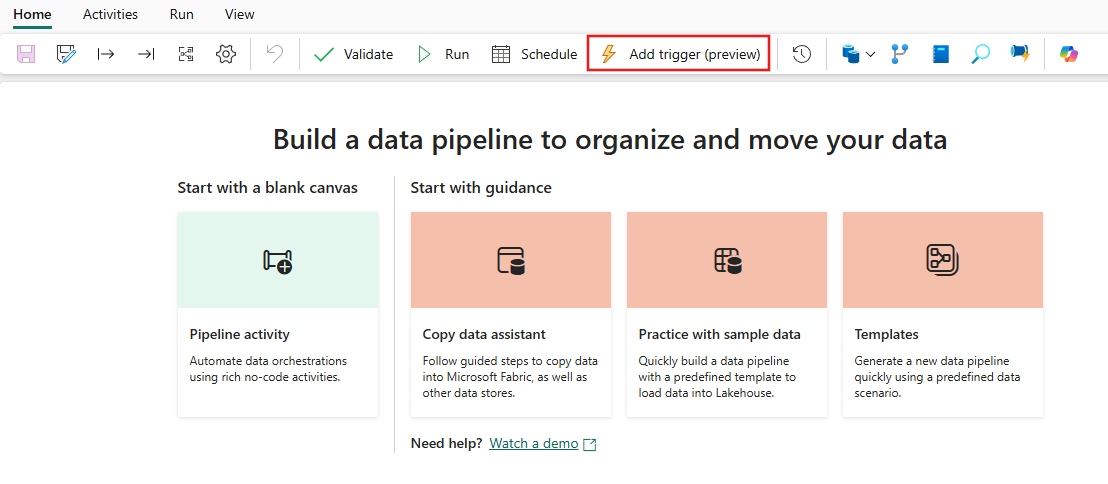
Depuración
Depurar canalizaciones es más sencillo en Fabric que en ADF. Esta simplicidad se debe a que las canalizaciones de Fabric Data Factory no tienen un concepto separado de modo de depuración que se encuentra en las canalizaciones y flujos de datos de ADF. En su lugar, al construir tu canalización, siempre estás en modo interactivo. Para probar y depurar las canalizaciones, solo tiene que seleccionar el botón Reproducir de la barra de herramientas del editor de canalizaciones cuando esté listo en el ciclo de desarrollo. Las canalizaciones de Fabric no incluyen el patrón de depuración interactiva depuración hasta de paso a paso. En su lugar, en Fabric, se usa el estado de la actividad y se establecen solo las actividades que desea probar como activas al establecer todas las demás actividades inactivas para lograr los mismos patrones de prueba y depuración. Consulte el siguiente video que explica cómo lograr esta experiencia de depuración en Fabric.
Captura de datos modificados
La captura de datos modificados (CDC) en ADF es una característica en versión preliminar que facilita el traslado de datos rápidamente de forma incremental mediante la aplicación de características CDC del lado de origen de los almacenes de datos. Para migrar los artefactos de CDC a Fabric Data Factory, recrea estos artefactos como elementos de Trabajos de copia en el área de trabajo de Fabric. Esta característica proporciona capacidades similares de movimiento de datos incremental con una interfaz fácil de usar sin requerir una canalización, como en CDC de ADF. Para obtener más información, consulte el Trabajo de copia para Data Factory en Fabric.
Azure Synapse Link
Aunque no está disponible en ADF, los usuarios de Synapse pipeline utilizan con frecuencia Azure Synapse Link para replicar datos de bases de datos SQL en su lago de datos con un enfoque llave en mano. En Fabric, se recrean los artefactos de Azure Synapse Link como elementos de duplicación en su área de trabajo. Para obtener más información, consulte en Fabric Creación de reflejo de la base de datos.
SQL Server Integration Services (SSIS)
SSIS es la integración de datos local y la herramienta ETL que Microsoft envía con SQL Server. En ADF, puede migrar sus paquetes SSIS a la nube utilizando el método "lift-and-shift" y el entorno de ejecución integrado de SSIS en ADF. En Fabric, no tenemos el concepto de IRs, por lo que esta funcionalidad no es posible hoy en día. Sin embargo, estamos trabajando para habilitar la ejecución de paquetes SSIS de forma nativa desde Fabric, que esperamos traer al producto pronto. Mientras tanto, la mejor manera de ejecutar paquetes SSIS en la nube con Fabric Data Factory es iniciar una instancia de SSIS IR en la factoría de ADF y, a continuación, invocar una canalización de ADF para llamar a los paquetes SSIS. Puede llamar de forma remota a una canalización de ADF desde las canalizaciones de Fabric mediante la actividad de canalización invocada que se describe en la sección siguiente.
Actividad de invocación de la canalización
Una actividad común que se usa en las canalizaciones de ADF es la actividad Ejecutar canalización que permite llamar a otra canalización en la factoría. En Fabric, hemos mejorado esta actividad como la actividad de invocación de canalización. Consulte la documentación de la actividad de invocación de canalización.
Esta actividad es útil para escenarios de migración en los que tienes muchas canalizaciones de ADF que usan características específicas de ADF, como los flujos de datos de mapeo o SSIS. Puede mantener esas canalizaciones tal como están en ADF o incluso en canalizaciones de Synapse y, a continuación, llamar a esa canalización en línea desde la nueva canalización de Fabric Data Factory mediante la actividad Invocar canalización y apuntar a la canalización de factoría remota.
Escenarios de migración de ejemplo
Los escenarios siguientes son escenarios comunes de migración que se pueden encontrar al migrar de ADF a Fabric Data Factory.
Escenario 1: canalizaciones y flujos de datos de ADF
Los casos de uso principales para las migraciones de fábrica se basan en la modernización del entorno ETL desde el modelo PaaS de fábrica de ADF al nuevo modelo SaaS de Fabric. Los elementos de fábrica principales que se van a migrar son canalizaciones y flujos de datos. Hay varios elementos de fábrica fundamentales que debe planear para la migración fuera de esos dos elementos de nivel superior: servicios vinculados, entornos de ejecución de integración, conjuntos de datos y desencadenadores.
- Los servicios vinculados deben volver a crearse en Fabric como conexiones en las actividades de canalización.
- Los conjuntos de datos no existen en Factory. Las propiedades de los conjuntos de datos se representan como propiedades dentro de actividades de canalización, como Copiar o Buscar, mientras que las conexiones contienen otras propiedades del conjunto de datos.
- Los entornos de ejecución de integración no existen en Fabric. Sin embargo, las IR autohospedadas se pueden volver a crear mediante puertas de enlace de datos locales (OPDG) en IR de tejido y red virtual de Azure como puertas de enlace de red virtual administradas en Fabric.
- Estas actividades de canalización de ADF no se incluyen en Fabric Data Factory:
- Data Lake Analytics (U-SQL): esta característica es un servicio de Azure en desuso.
- Actividad de validación: la actividad de validación en ADF es una actividad auxiliar que puede volver a generar en las canalizaciones de Fabric fácilmente mediante una actividad Obtener metadatos, un bucle de canalización y una actividad If.
- Power Query: en Fabric, todos los flujos de datos se compilan mediante la interfaz de usuario de Power Query, por lo que puede copiar y pegar el código M de las actividades de ADF Power Query y compilarlos como flujos de datos en Fabric.
- Si usa cualquiera de las funcionalidades de canalización de ADF que no se encuentran en Fabric Data Factory, use la actividad Invocar canalización en Fabric para llamar a las canalizaciones existentes en ADF.
- Las siguientes actividades de canalización de ADF se combinan en una actividad de un solo propósito:
- Actividades de Azure Databricks (Notebook, Jar, Python)
- Azure HDInsight (Hive, Pig, MapReduce, Spark, Streaming)
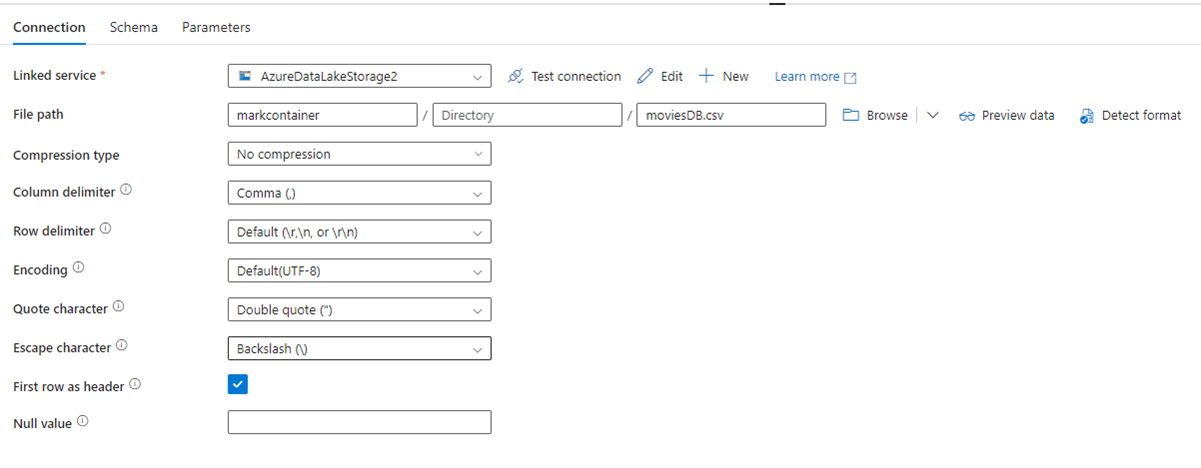
En la imagen siguiente se muestra la página de configuración del conjunto de datos de ADF, con su ruta de acceso de archivo y la configuración de compresión:
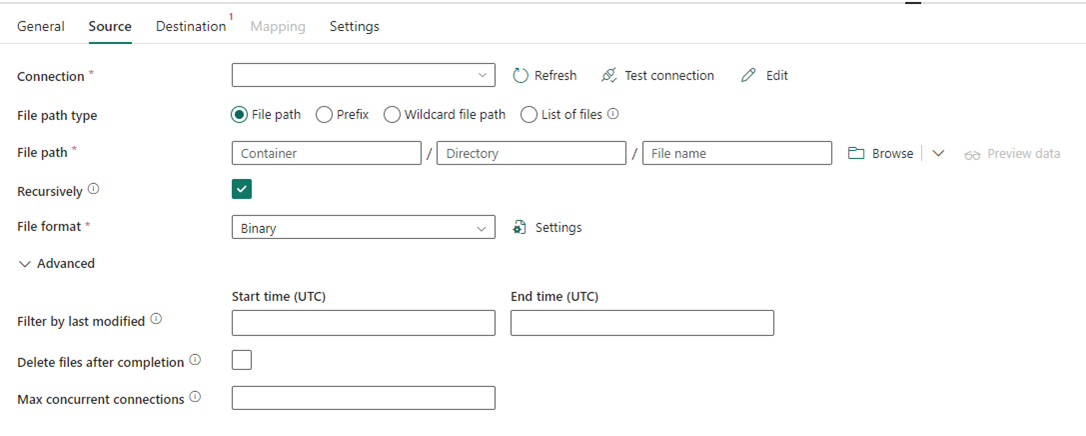
En la imagen siguiente se muestra la configuración de la actividad de copia para Data Factory en Fabric, donde la compresión y la ruta de acceso del archivo están incluidas en la actividad.
Escenario 2: ADF con CDC, SSIS y Airflow
CDC & Airflow en ADF son funciones de vista previa, mientras que SSIS en ADF es una característica que ha estado disponible con carácter general durante muchos años. Cada una de estas características atiende diferentes necesidades de integración de datos, pero requiere especial atención al migrar de ADF a Fabric. La captura de datos modificados (CDC) es un concepto de ADF de nivel superior, pero en Fabric, esta capacidad se presenta como un Trabajo de copia.
Airflow es la característica Apache Airflow administrada por la nube de ADF y también está disponible en Fabric Data Factory. Debería poder usar el mismo repositorio de origen de Airflow o tomar los DAG y copiar o pegar el código en la oferta de Fabric Airflow con poco o ningún cambio necesario.
Escenario 3: migración de Data Factory habilitada para Git a Fabric
Aunque no es necesario, es habitual que las factorías y áreas de trabajo de ADF o Synapse estén conectadas a su propio proveedor de Git externo en ADO o GitHub. En este escenario, debe migrar los elementos de fábrica y área de trabajo a un área de trabajo de Fabric y, a continuación, configurar la integración de Git en el área de trabajo de Fabric.
Fabric proporciona dos maneras principales de habilitar CI/CD, ambas a nivel de área de trabajo: integración de Git, donde conecta su propio repositorio de Git en ADO a Fabric, y canalizaciones de implementación integradas, donde puede promover código a ambientes de niveles superiores sin necesidad de traer su propio Git.
En ambos casos, el repositorio de Git existente de ADF no funciona con Fabric. En su lugar, debe apuntar a un nuevo repositorio o iniciar una nueva canalización de implementación en Fabric y recompilar los artefactos de canalización en Fabric.
Monte sus instancias existentes de ADF directamente en un área de trabajo de Fabric
Anteriormente, hablamos sobre el uso de la actividad de invocación de pipeline de Fabric Data Factory como un mecanismo para mantener las inversiones existentes en pipelines de ADF y ejecutarlas directamente desde Fabric. Dentro de Fabric, puedes llevar ese concepto un paso más allá y montar la fábrica entera dentro de tu área de trabajo de Fabric como un elemento nativo de Fabric.
Para obtener más información sobre el montaje de escenarios de uso, consulte Escenarios de colaboración y entrega de contenido.
El montaje de Azure Data Factory dentro del área de trabajo de Fabric ofrece muchas ventajas que se deben tener en cuenta. Si no está familiarizado con Fabric y desea mantener sus fábricas en paralelo dentro del mismo panel de vidrio, puede montarlas en Fabric para que pueda administrar ambas dentro de Fabric. La interfaz de usuario completa de ADF ya está disponible desde la fábrica montada, donde puede supervisar, administrar y editar los elementos de fábrica de ADF completamente desde el área de trabajo de Fabric. Esta característica facilita mucho la migración de estos elementos a Fabric como artefactos nativos de Fabric. Esta característica es principalmente para facilitar el uso y facilita la visualización de las factorías de ADF en el área de trabajo de Fabric. Sin embargo, la ejecución real de las canalizaciones, las actividades, los entornos de ejecución de integración, etc., todavía se produce dentro de los recursos de Azure.
Contenido relacionado
Consideraciones de migración de ADF a Data Factory en Fabric