Consideraciones sobre la puerta de enlace de datos local para destinos de datos en Dataflow Gen2
En este artículo se intentan enumerar las limitaciones y consideraciones al usar puerta de enlace de datos con escenarios de destinos de datos en flujo de datos de Gen2.
Tiempos de espera de evaluación
Los flujos de datos que usan una puerta de enlace y la característica de destino de datos se limitan a una hora de evaluación o actualización.
Obtenga más información sobre esta limitación del artículo en Artículo sobre la solución de problemas de la puerta de enlace de datos local.
Problemas de red con el puerto 1433
Al usar Microsoft Fabric Dataflow Gen2 con una puerta de enlace de datos local, es posible que encuentre problemas con el proceso de actualización del flujo de datos. El problema subyacente se produce cuando la puerta de enlace no puede conectarse al lago de almacenamiento provisional del flujo de datos para leer los datos antes de copiarlos en el destino de datos deseado. Este problema puede producirse independientemente del tipo de destino de datos que se use.
Durante la actualización general del flujo de datos, la actualización de tablas puede mostrarse como "Correcto", pero la sección de actividades se muestra como "Error". Los detalles del error de la actividad WriteToDatabaseTableFrom_... indican el siguiente error:
Mashup Exception Error: Couldn't refresh the entity because of an issue with the mashup document MashupException.Error: Microsoft SQL: A network-related or instance-specific error occurred while establishing a connection to SQL Server. The server was not found or was not accessible. Verify that the instance name is correct and that SQL Server is configured to allow remote connections. (provider: TCP Provider, error: 0 - An attempt was made to access a socket in a way forbidden by its access permissions.) Details: DataSourceKind = Lakehouse;DataSourcePath = Lakehouse;Message = A network-related or instance-specific error occurred while establishing a connection to SQL Server. The server was not found or was not accessible. Verify that the instance name is correct and that SQL Server is configured to allow remote connections. (provider: TCP Provider, error: 0 - An attempt was made to access a socket in a way forbidden by its access permissions.);ErrorCode = -2146232060;Number = 10013
Nota:
Desde una perspectiva arquitectónica, el motor de flujo de datos usa un punto de conexión HTTPS de salida (puerto 443) para escribir datos en una instancia de Lakehouse. Sin embargo, la lectura de datos de Lakehouse requiere el uso del protocolo TDS (TCP a través del puerto 1433). Este protocolo se usa para copiar los datos del lago de almacenamiento provisional en el destino de los datos. Esto explica por qué el paso Carga de tablas se realiza correctamente mientras se produce un error en la actividad de destino de datos, incluso cuando ambos lakehouses están en la misma instancia de OneLake.
Solucionar problemas
Para solucionar el problema, siga estos pasos:
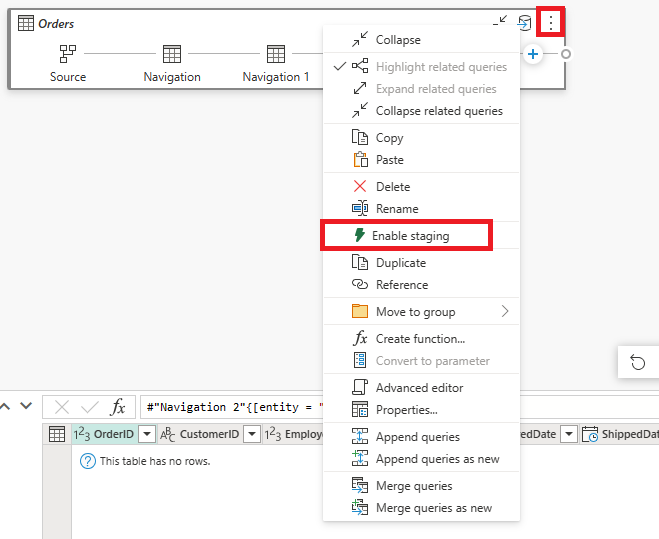
Confirme que el flujo de datos está configurado con un destino de datos.
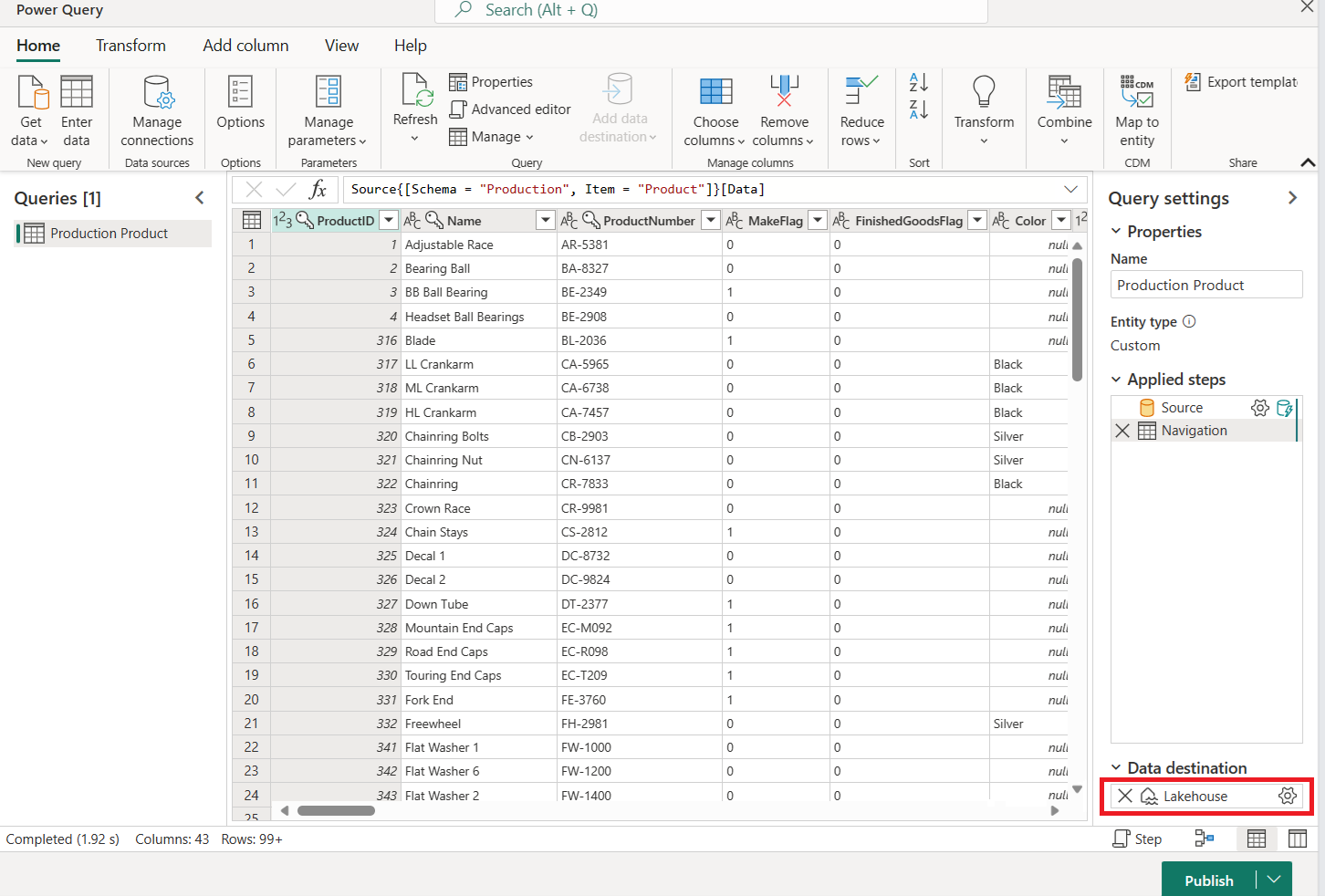
Compruebe que la actualización del flujo de datos ha fallado, mostrando la actualización de las tablas como " Correcto" y la de las actividades como "Error ".
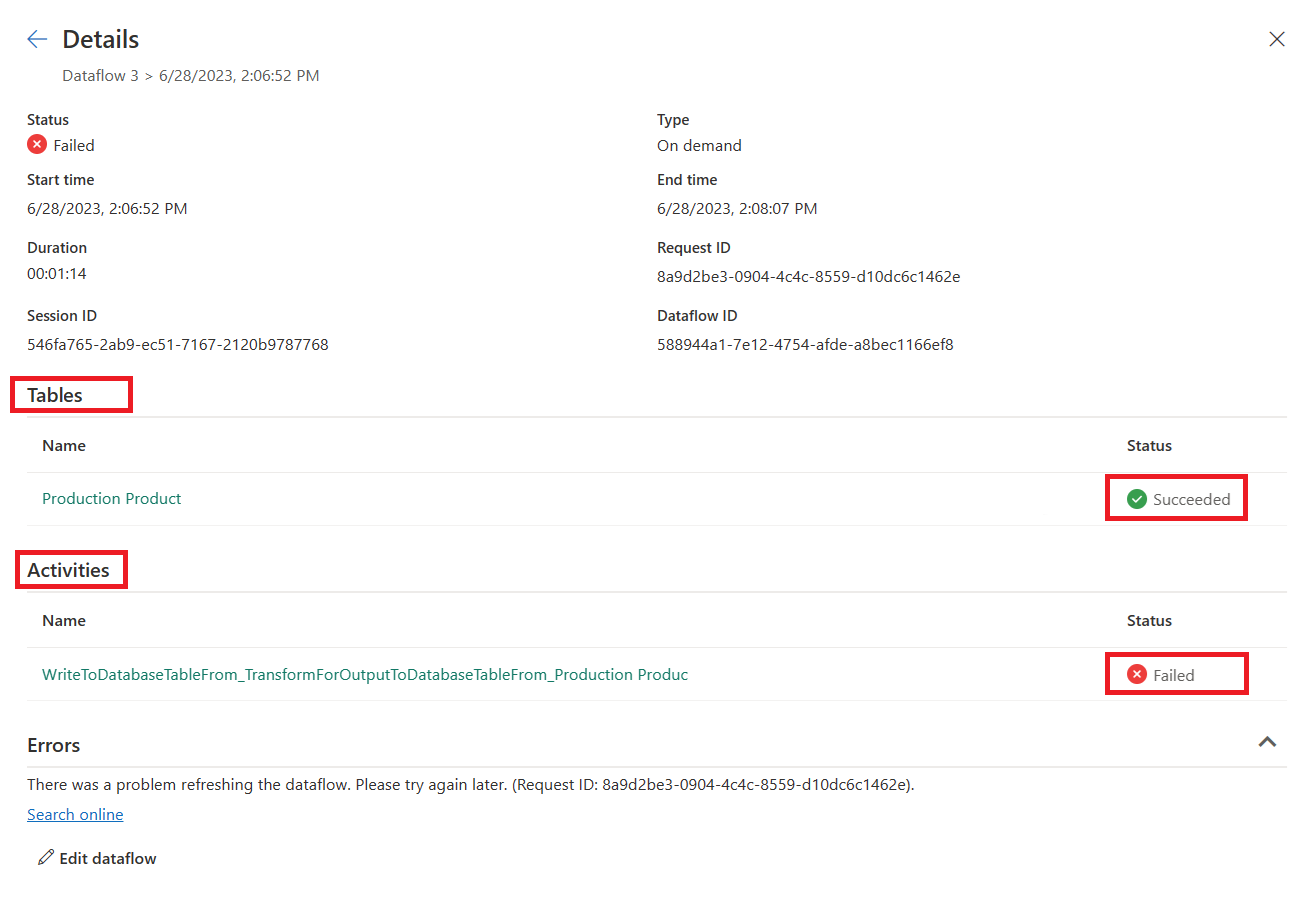
Revise los detalles del error de la actividad
WriteToDatabaseTableFrom_..., que proporciona información sobre el error encontrado.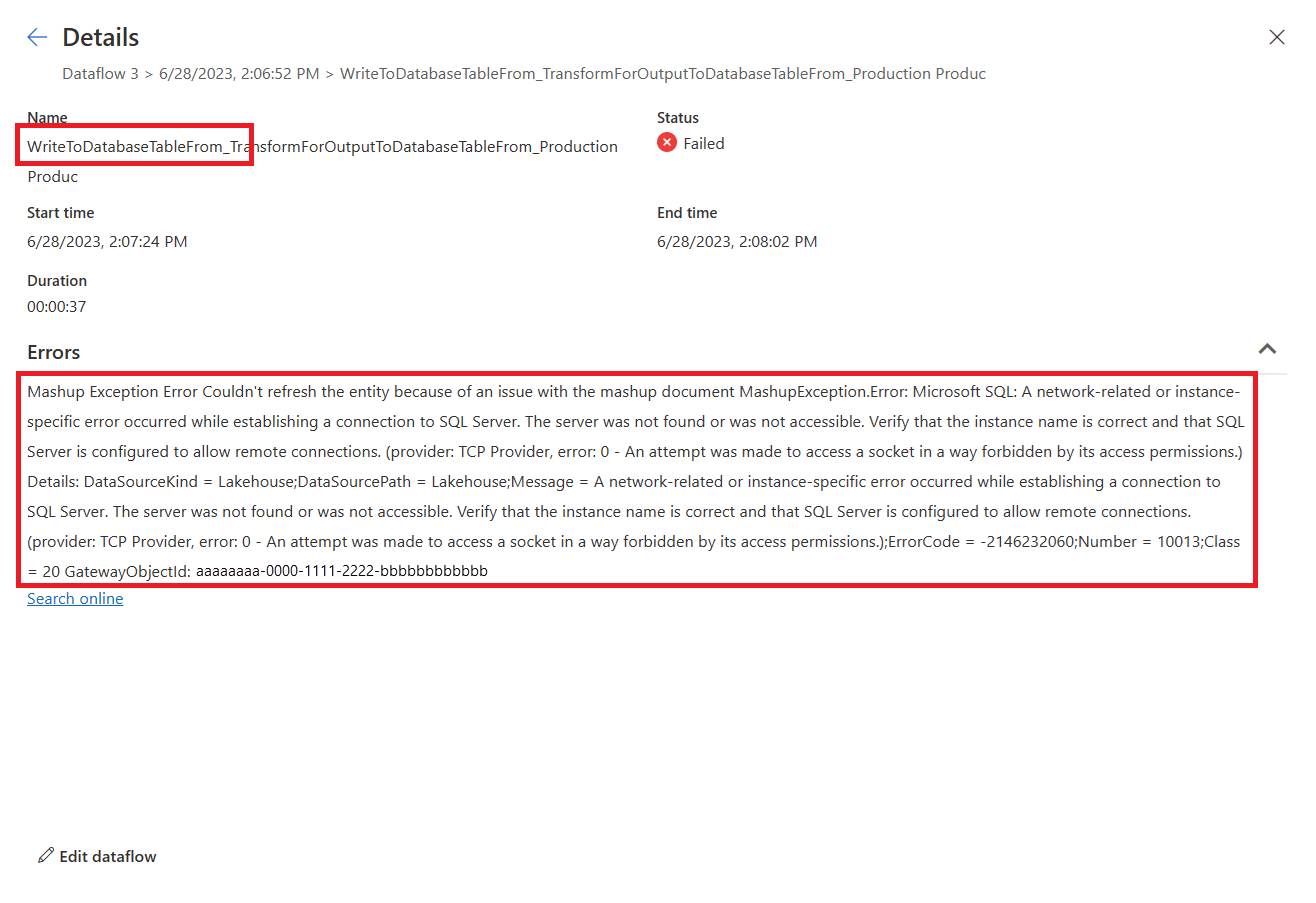



Solución: Establecimiento de nuevas reglas de firewall en el servidor que ejecuta la puerta de enlace
Es necesario actualizar las reglas de firewall en el servidor de la puerta de enlace y/o en los servidores proxy del cliente para permitir el tráfico saliente desde el servidor de puerta de enlace a los puntos de conexión indicados a continuación. Si el firewall no admite caracteres comodín, use las direcciones IP de intervalos IP de Azure y etiquetas de servicio. Deben mantenerse sincronizados cada mes.
- Protocolo: TCP
- Puntos de conexión: *.datawarehouse.pbidedicated.windows.net, *.datawarehouse.fabric.microsoft.com, *.dfs.fabric.microsoft.com
- Puerto:1433
Nota:
En determinados escenarios, especialmente cuando la capacidad se encuentra en una región que no es la más cercana a la puerta de enlace, podría ser necesario configurar el firewall para permitir el acceso a varios puntos de conexión (*cloudapp.azure.com). Este ajuste es necesario para dar cabida a las redirecciones que pueden producirse en estas condiciones. Si el tráfico destinado a *.cloudapp.azure.com no se intercepta mediante la regla, también puedes permitir las direcciones IP de la región de datos en el firewall.
Si quiere restringir el alcance del punto de conexión a la instancia real de OneLake en un área de trabajo (en lugar del comodín *.datawarehouse.pbidedicated.windows.net), esa URL se puede encontrar desplazándose al área de trabajo de Fabric, localizandoDataflowsStagingLakehouse, y seleccionando Ver detalles. A continuación, copie y pegue la cadena de conexión SQL.


El nombre completo del punto de conexión es similar al ejemplo siguiente:
x6eps4xrq2xudenlfv6naeo3i4-l27nd6wdk4oephe4gz4j7mdzka.datawarehouse.pbidedicated.windows.net
Solución alternativa: dividir el flujo de datos en un flujo de datos de ingesta y carga independientes
Si no puede actualizar las reglas de firewall, puede dividir el flujo de datos en dos flujos de datos independientes. El primer flujo de datos es responsable de ingerir los datos en el almacén de lago de almacenamiento provisional. El segundo flujo de datos es responsable de cargar los datos del almacén de lago de almacenamiento provisional en el destino de los datos. Esta solución alternativa no es ideal, ya que requiere el uso de dos flujos de datos independientes, pero se puede usar como solución temporal hasta que se puedan actualizar las reglas de firewall.
Para implementar esta solución alternativa, siga estos pasos:
Quitar el destino de datos del flujo de datos actual que ingiere datos a través de la puerta de enlace.
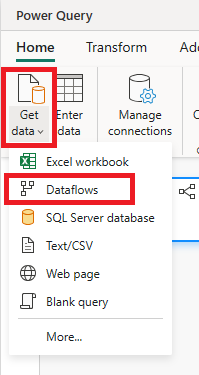
Cree un nuevo flujo de datos que use el conector de flujo de datos para conectarse al flujo de datos ingerido. Este flujo de datos es responsable de ingerir los datos de almacenamiento provisional en el destino de datos.
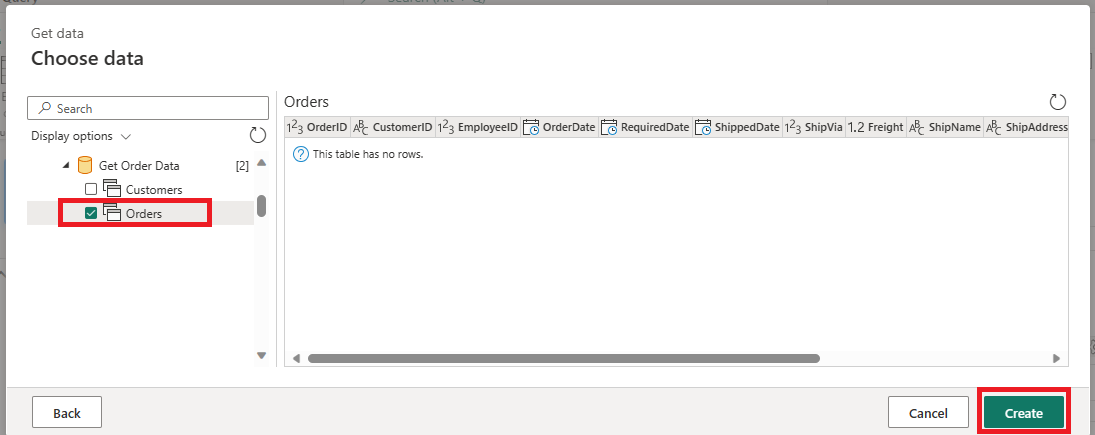
Establezca el destino de datos para que sea el destino de datos que prefiera para este nuevo flujo de datos.
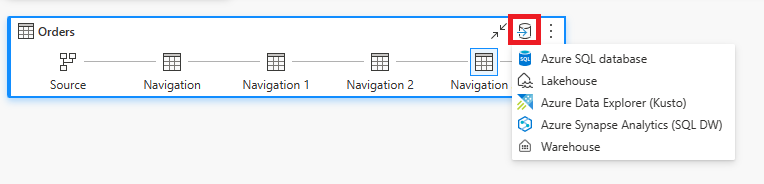
Opcionalmente, puede deshabilitar el almacenamiento provisional de este nuevo flujo de datos. Este cambio impide que los datos se copien de nuevo en el almacén de lago de almacenamiento provisional y, en su lugar, copia los datos directamente desde el flujo de datos ingerido al destino de datos.