Copia rápida en Dataflows Gen2
En este artículo se describe la característica de copia rápida de Dataflows Gen2 para Data Factory en Microsoft Fabric. Dataflows ayuda a ingerir y transformar datos. Con la introducción del escalado horizontal del flujo de datos con el proceso de SQL DW, puede transformar los datos a gran escala. Sin embargo, los datos deben ingerirse primero. Con la introducción de la copia rápida, puede ingerir terabytes de datos con la experiencia sencilla de flujos de datos, pero con el back-end escalable de la actividad de copia de canalización.
Después de habilitar esta funcionalidad, Dataflows cambia automáticamente el back-end cuando el tamaño de los datos supera un umbral determinado, sin necesidad de cambiar nada durante la creación de los flujos de datos. Después de actualizar un flujo de datos, puede consultar el historial de actualizaciones para ver si se usó la copia rápida durante la ejecución; para ello, consulte el tipo Motor que aparece.
Con la opción Requerir copia rápida habilitada, la actualización del flujo de datos se cancela si no se usa la copia rápida. Esto le ayuda a evitar esperar un tiempo de espera de actualización para continuar. Este comportamiento también puede ser útil en una sesión de depuración para probar el comportamiento del flujo de datos con los datos a la vez que se reduce el tiempo de espera. Con los indicadores de copia rápida en el panel de pasos de consulta, puede comprobar fácilmente si la consulta se puede ejecutar con una copia rápida.
Requisitos previos
- Debe tener una capacidad de Fabric.
- En el caso de los datos de archivos, los archivos están en formato .csv o parquet de al menos 100 MB y se almacenan en una cuenta de Azure Data Lake Storage (ADLS) Gen2 o de Blob Storage.
- En el caso de las bases de datos, incluida la de Azure SQL y PostgreSQL, 5 millones de filas de datos o más en el origen de datos.
Nota:
Puede omitir el umbral para forzar la copia rápida seleccionando la opción "Requerir copia rápida".
Compatibilidad con conectores
La copia rápida es compatible actualmente con los siguientes conectores de Dataflows Gen2:
- ADLS Gen2
- Blob Storage
- Azure SQL DB
- Lakehouse
- PostgreSQL
- Servidor SQL Server local
- Almacén de lago
- Oracle
- Snowflake
La actividad de copia solo admite algunas transformaciones al conectarse a un origen de archivos:
- Combinar archivos
- Seleccionar columnas
- Cambiar tipos de datos
- Cambio del nombre de una columna
- Quitar una columna
Puede seguir aplicando otras transformaciones si divide los pasos de ingesta y transformación en consultas independientes. La primera consulta recupera realmente los datos y la segunda consulta hace referencia a sus resultados para que se pueda usar el proceso DW. En el caso de los orígenes SQL, se admite cualquier transformación que forme parte de la consulta nativa.
Cuando se carga directamente la consulta en un destino de salida, solo se admiten actualmente los destinos de almacén de lago. Si desea usar otro destino de salida, puede almacenar provisionalmente la consulta en primer lugar y hacer referencia a ella más adelante.
Cómo usar la copia rápida
Vaya al punto de conexión de Fabric adecuado.
Vaya a un área de trabajo premium y cree un flujo de datos Gen2.
En la pestaña Inicio del nuevo flujo de datos, seleccione Opciones:
A continuación, seleccione la pestaña Escala en el cuadro de diálogo Opciones y seleccione la casilla Permitir el uso de conectores de copia rápida para activar la copia rápida. A continuación, cierre el cuadro de diálogo Opciones.

Seleccione Obtener datos y, a continuación, elija el origen de ADLS Gen2 y rellene los detalles del contenedor.
Use la funcionalidad Combinar archivo.

Para garantizar una copia rápida, aplique solo las transformaciones enumeradas en la sección Compatibilidad con conectores de este artículo. Si necesita aplicar más transformaciones, almacene provisionalmente primero los datos y haga referencia a la consulta más adelante. Realice otras transformaciones en la consulta a la que se hace referencia.
(Opcional) Para establecer la opción Requerir copia rápida para la consulta, haga clic con el botón derecho en ella para seleccionarla y habilitarla.
(Opcional) Actualmente, solo puede configurar un almacén de lago como destino de salida. Para cualquier otro destino, almacene provisionalmente la consulta y haga referencia a ella más adelante en otra consulta en la que pueda generar una salida a cualquier origen.
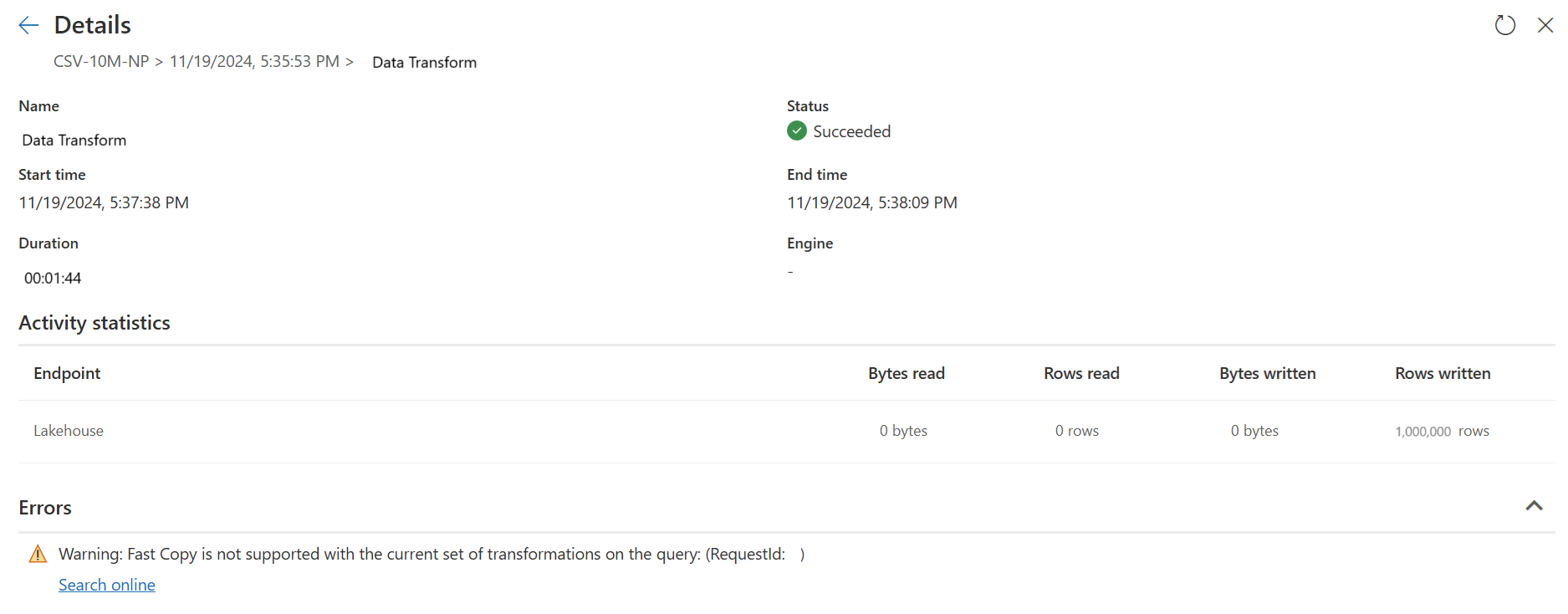
Compruebe los indicadores de copia rápida para ver si la consulta se puede ejecutar con una copia rápida. Si es así, el tipo Motor muestra CopyActivity.

Publicar el flujo de datos.
Compruebe después de que se haya completado la actualización para confirmar que se haya usado una copia rápida.

Cómo dividir la consulta para aprovechar la copia rápida
Para obtener un rendimiento óptimo al procesar grandes volúmenes de datos con Dataflow Gen2, use la característica Copia rápida para ingerir primero los datos en el almacenamiento provisional y, a continuación, transformarlos a gran escala con el proceso de SQL DW. Este enfoque mejora significativamente el rendimiento de un extremo a otro.
Para implementar esto, los indicadores de copia rápida pueden guiarle para dividir la consulta en dos partes: la ingesta de datos en el almacenamiento provisional y la transformación a gran escala con el proceso de SQL DW. Se recomienda que inserte lo máximo posible de las evaluaciones de una consulta en copia rápida que pueda usarse para ingerir los datos. Cuando los indicadores de copia rápida indican que la copia rápida no puede ejecutar los pasos restantes, puede dividir el resto de la consulta con almacenamiento provisional habilitado.
Indicadores de diagnóstico por etapas
| Indicador | Icono | Descripción |
|---|---|---|
| Este paso se va a evaluar con copia rápida | 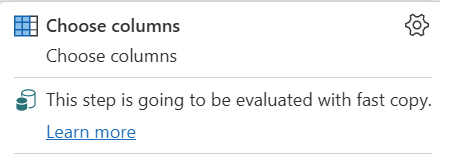
|
El indicador de copia rápida le indica que la consulta hasta este paso admite la copia rápida. |
| Este paso no es compatible con la copia rápida | 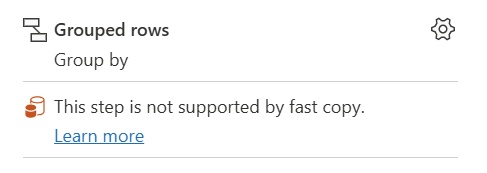
|
El indicador de copia rápida muestra que este paso no admite la copia rápida. |
| uno o varios pasos de la consulta no son compatibles con la consulta rápida | 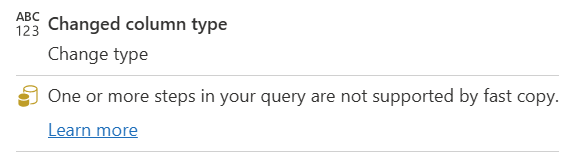
|
El indicador de copia rápida muestra que algunos pasos de esta consulta admiten la copia rápida, mientras que otros no. Para optimizar, divida la consulta: pasos amarillos (posiblemente compatibles con Fast Copy) y pasos rojos (no compatibles). |
Instrucciones paso a paso
Después de completar la lógica de transformación de datos en Dataflow Gen2, el indicador de copia rápida evalúa cada paso para determinar cuántos pasos pueden aprovechar Fast Copy para mejorar el rendimiento.
En el ejemplo siguiente, el último paso muestra rojo, lo que indica que el paso con Group By no es compatible con Fast Copy. Sin embargo, todos los pasos anteriores que muestran amarillo pueden ser posiblemente compatibles con Fast Copy.
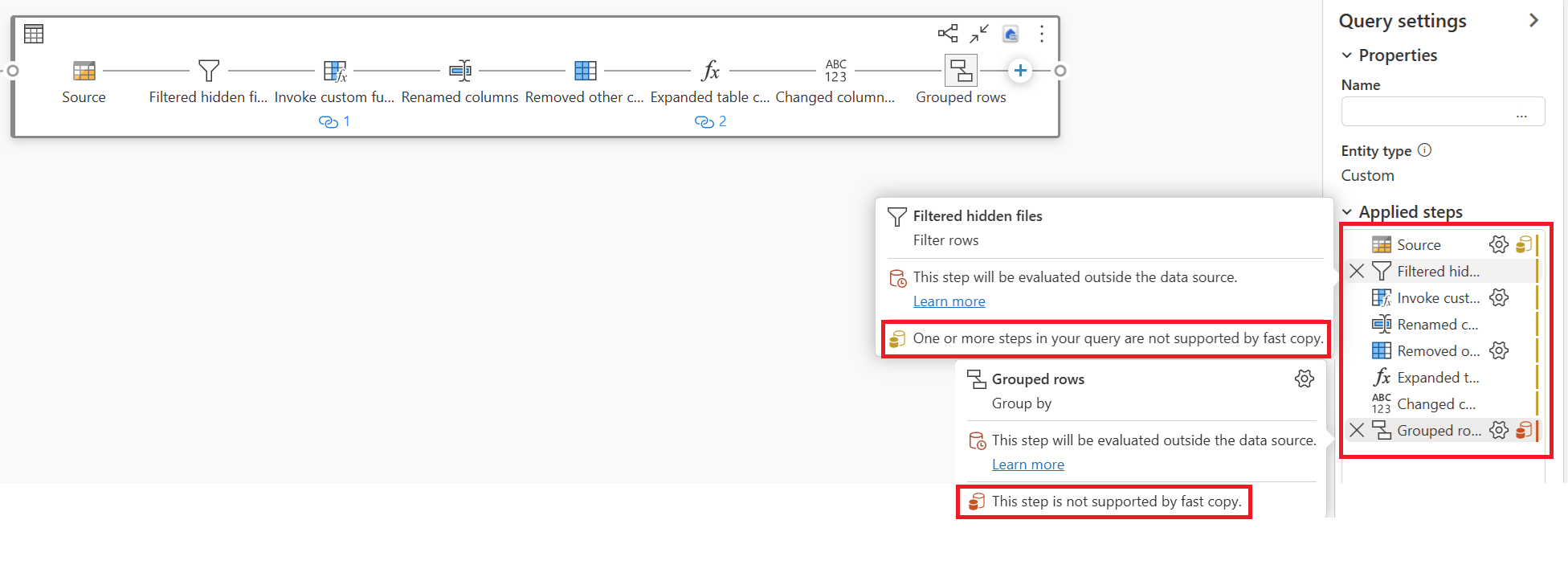
En este momento, si publica y ejecuta directamente Dataflow Gen2, no utilizará el motor de copia rápida para cargar sus datos como en la imagen a continuación.
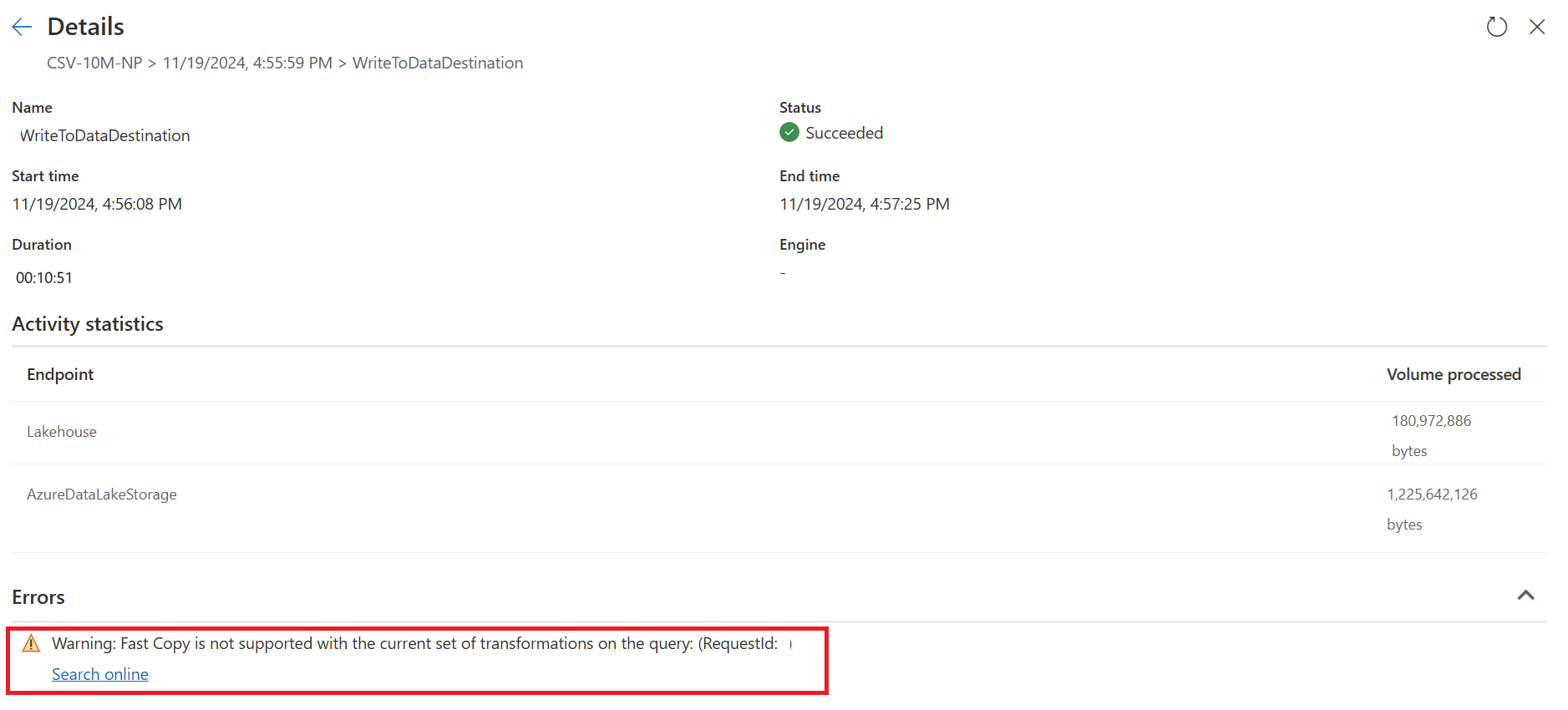
Para usar el motor de copia rápida y mejorar el rendimiento de su Dataflow Gen2, puede dividir la consulta en dos partes: la ingesta de datos en el almacenamiento provisional y la transformación a gran escala con la computación de SQL DW, de la siguiente manera:
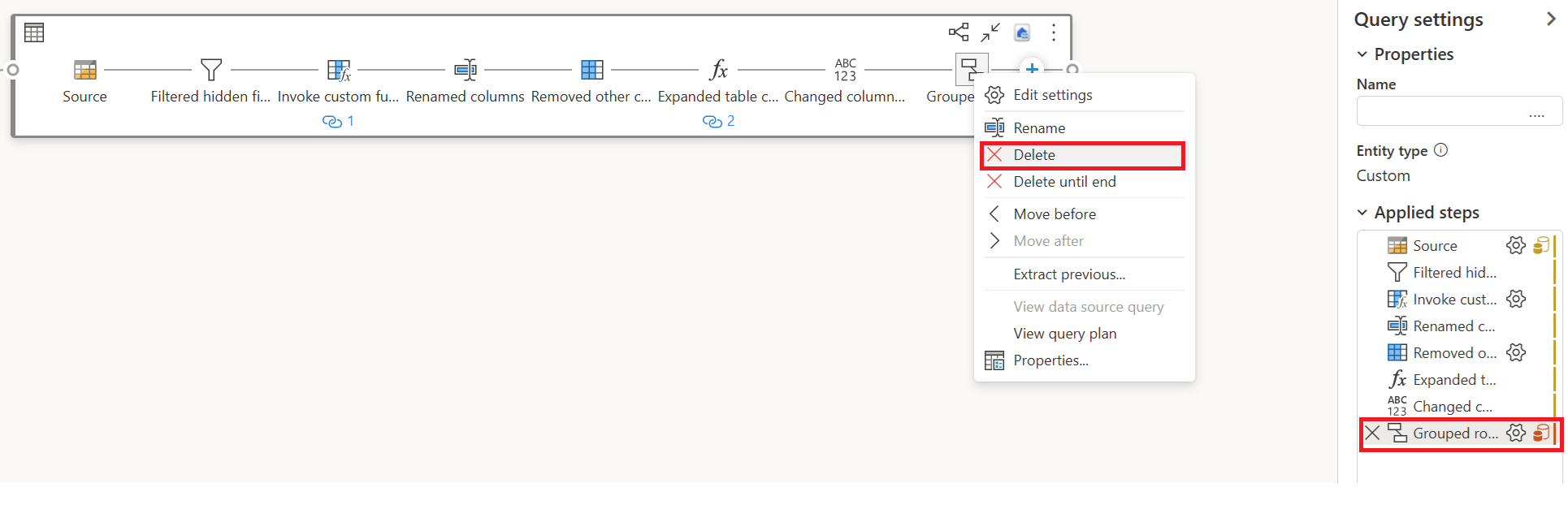
Quite las transformaciones (que muestran rojo) que no son compatibles con Fast Copy, junto con el destino (si se define).
El indicador de copia rápida ahora muestra verde para los pasos restantes, lo que significa que la primera consulta puede aprovechar Fast Copy para mejorar el rendimiento.
Seleccione Acción para la primera consulta y, a continuación, elija Habilitar almacenamiento provisional y referencia.
En una nueva consulta a la que se hace referencia, se lee la transformación "Agrupar por" y el destino (si procede).
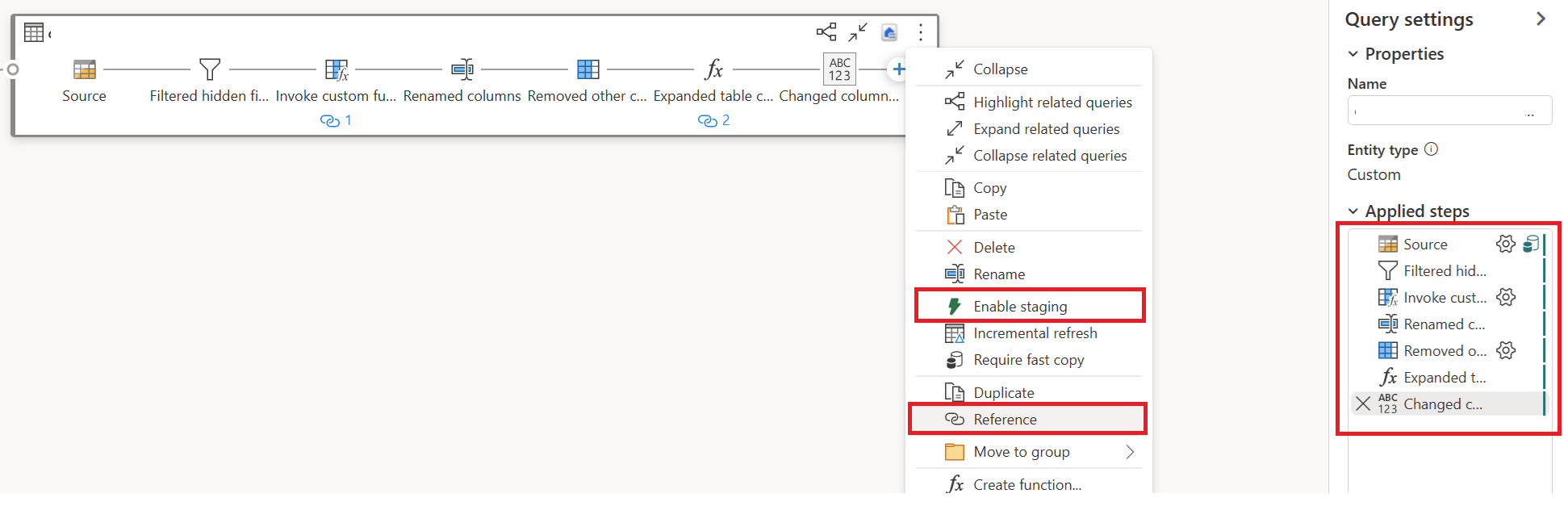
Publique y actualice el flujo de datos Gen2. Ahora verá dos consultas en el flujo de datos Gen2 y la duración general se reduce en gran medida.
La primera consulta ingiere datos en el almacenamiento provisional mediante copia rápida.
La segunda consulta realiza transformaciones a gran escala mediante el proceso de SQL DW.
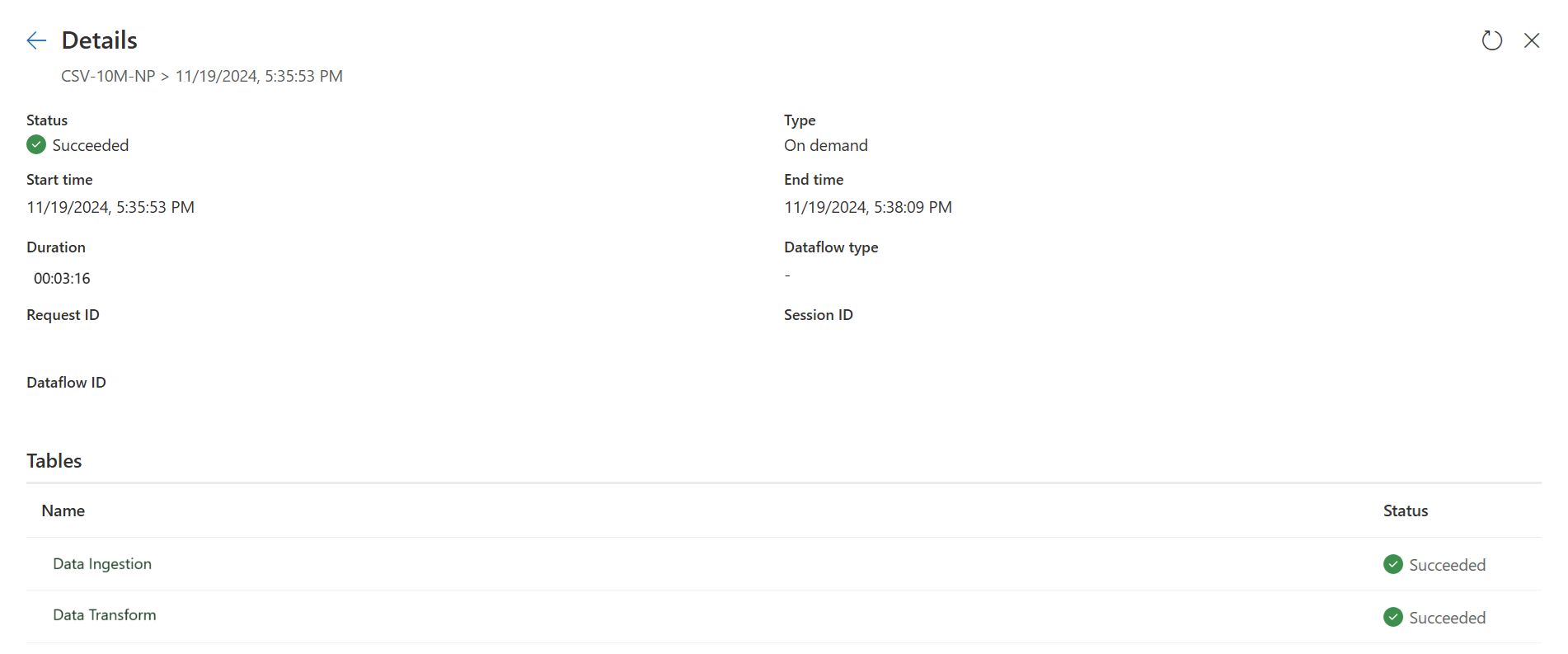
La primera consulta:
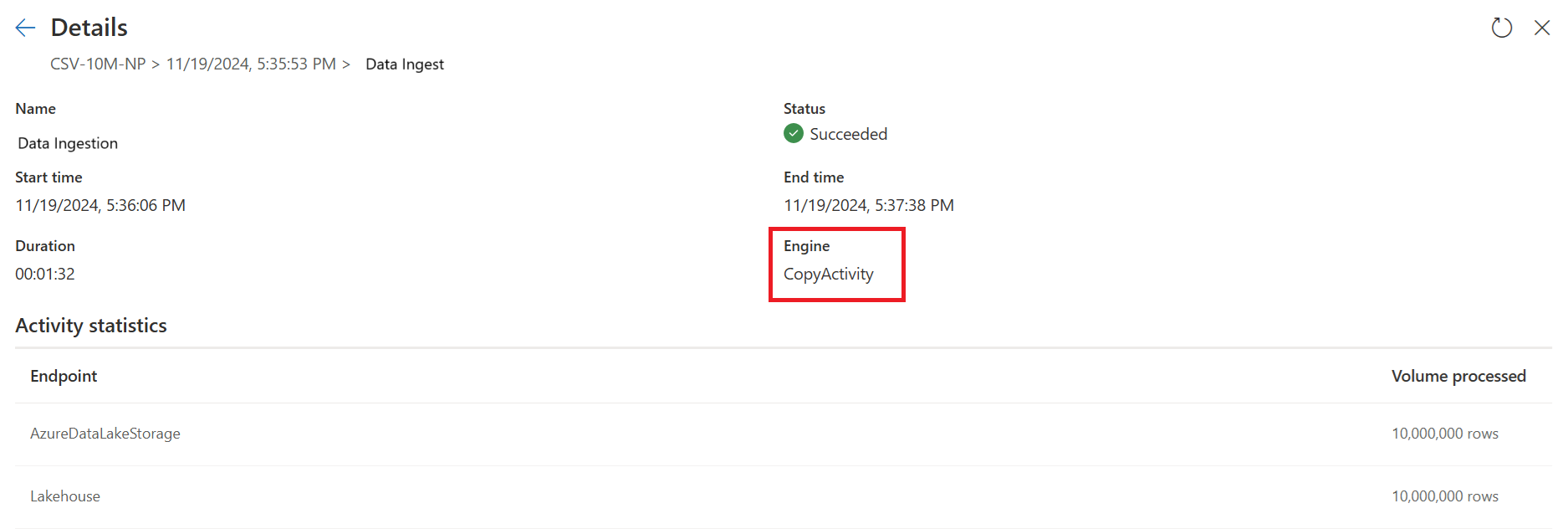
La segunda consulta:
Restricciones conocidas
- Se necesita una puerta de enlace de datos local versión 3000.214.2 o posterior para admitir la copia rápida.
- No se admite la puerta de enlace de red virtual.
- No se admite la escritura de datos en una tabla existente en Lakehouse.
- No se admite el esquema fijo.