Actualización incremental en Dataflow Gen2 (versión preliminar)
En este artículo, presentamos la actualización incremental de datos en Dataflow Gen2 para Data Factory de Microsoft Fabric. Cuando se usan flujos de datos para la ingesta y transformación de datos, hay escenarios en los que, en concreto, es necesario actualizar solo los datos—nuevos o actualizados, especialmente a medida que los datos siguen creciendo. La característica de actualización incremental aborda esta necesidad al permitirle reducir los tiempos de actualización, mejorar la confiabilidad evitando las operaciones de larga duración y minimizando el uso de recursos.
Requisitos previos
Para usar la actualización incremental en Dataflow Gen2, debe cumplir los siguientes requisitos previos:
- Debe tener una capacidad de Fabric.
- El origen de datos admite plegado (recomendado) y debe contener una columna Date/DateTime que se pueda usar para filtrar los datos.
- Debe tener un destino de datos que admita la actualización incremental. Para obtener más información, vaya a Compatibilidad con destino.
- Antes de empezar, asegúrese de revisar las limitaciones de la actualización incremental. Para más información, consulte las Limitaciones.
Compatibilidad con destino
Se admiten los siguientes destinos de datos para la actualización incremental:
- Fabric Warehouse
- Azure SQL Database
- Azure Synapse Analytics
Otros destinos como el Almacén de lago de datos se pueden usar en combinación con la actualización incremental mediante una segunda consulta que hace referencia a los datos almacenados provisionalmente para actualizar el destino de los datos. De este modo, puede seguir usando la actualización incremental para reducir la cantidad de datos que se deben procesar y recuperar del sistema de origen. Pero debe realizar una actualización completa de los datos almacenados provisionalmente en el destino de los datos.
Uso de la actualización incremental
Cree una nueva instancia de Dataflow Gen2 o abra una instancia existente de Dataflow Gen2.
En el editor de flujo de datos, cree una nueva consulta que recupere los datos que desea actualizar incrementalmente.
Compruebe la vista previa de datos para asegurarse de que la consulta devuelve datos que contienen una columna DateTime, Date o DateTimeZone que puede usar para filtrar los datos.
Asegúrese de que la consulta se pliega por completo, lo que significa que la consulta se inserta completamente en el sistema de origen. Si la consulta no se pliega por completo, debe modificar la consulta para que se doble por completo. Puede asegurarse de que la consulta se pliega por completo comprobando los pasos de consulta en el editor de consultas.
Haga clic con el botón derecho en la consulta y seleccione Actualización incremental.
Proporcione la configuración necesaria para la actualización incremental.
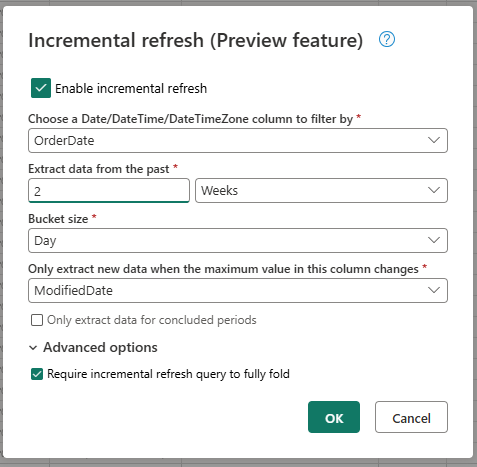
- Elija una columna de DateTime por la que filtrar.
- Extraiga datos del pasado.
- Tamaño del cubo.
- Solo extraiga nuevos datos cuando cambie el valor máximo de esta columna.
Configure las opciones avanzadas si es necesario.
- Requerir una consulta de actualización incremental para plegar por completo.
Seleccione Aceptar para guardar la configuración.
Si lo desea, ahora puede configurar un destino de datos para la consulta. Asegúrese de realizar esta configuración antes de la primera actualización incremental, ya que, de lo contrario, el destino de los datos solo contiene los datos modificados incrementalmente desde la última actualización.
Publique el flujo de datos Dataflow Gen2.
Después de configurar la actualización incremental, el flujo de datos actualiza automáticamente los datos de forma incremental en función de la configuración proporcionada. El flujo de datos solo recupera los datos que han cambiado desde la última actualización. Por lo tanto, el flujo de datos se ejecuta más rápido y consume menos recursos.
Funcionamiento de la actualización incremental en segundo plano
La actualización incremental funciona dividiendo los datos en cubos en función de la columna DateTime. Cada cubo contiene los datos que cambiaron desde la última actualización. El flujo de datos sabe qué ha cambiado comprobando el valor máximo en la columna especificada. Si se cambia el valor máximo para ese cubo, el flujo de datos recupera todo el cubo y reemplaza los datos en el destino. Si no se cambia el valor máximo, el flujo de datos no recupera ningún dato. Las secciones siguientes contienen información general de alto nivel sobre cómo funciona la actualización incremental paso a paso.
Primer paso: Evaluar los cambios
Cuando se ejecuta el flujo de datos, primero evalúa los cambios en el origen de datos. Realiza esta evaluación comparando el valor máximo de la columna DateTime con el valor máximo de la actualización anterior. Si el valor máximo ha cambiado o si es la primera actualización, el flujo de datos marca el cubo como cambiado y lo enumera para su procesamiento. Si el valor máximo no ha cambiado, el flujo de datos omite el cubo y no lo procesa.
Segundo paso: Recuperar los datos
Ahora el flujo de datos está listo para recuperar los datos. Recupera los datos de cada cubo que cambió. El flujo de datos realiza esta recuperación en paralelo para mejorar el rendimiento. El flujo de datos recupera los datos del sistema de origen y los carga en el área de ensayo. El flujo de datos solo recupera los datos que están dentro del intervalo de cubos. Es decir, el flujo de datos solo recupera los datos que han cambiado desde la última actualización.
Último paso: Reemplazar los datos en el destino de datos
El flujo de datos reemplaza los datos del destino por los nuevos datos. El flujo de datos usa el método replace para reemplazar los datos del destino. Es decir, el flujo de datos elimina primero los datos del destino de ese cubo y, a continuación, inserta los nuevos datos. El flujo de datos no afecta a los datos que están fuera del intervalo de cubos. Por lo tanto, si tiene datos en el destino que es anterior al primer cubo, la actualización incremental no afecta a estos datos de ninguna manera.
Configuración de actualización incremental explicada
Para configurar la actualización incremental, debe especificar las siguientes opciones.
Configuración general
Las opciones generales son necesarias y especifican la configuración básica para la actualización incremental.
Elija una columna de DateTime por la que filtrar
Esta configuración es necesaria y especifica la columna que usan los flujos de datos para filtrar los datos. Esta columna debe ser una columna DateTime, Date o DateTimeZone. El flujo de datos usa esta columna para filtrar los datos y solo recupera los datos que han cambiado desde la última actualización.
Extraiga datos del pasado.
Esta configuración es necesaria y especifica el retroceso en el tiempo que el flujo de datos debe extraer datos. Esta configuración se usa para recuperar la carga de datos inicial. El flujo de datos recupera todos los datos del sistema de origen que se encuentran dentro del intervalo de tiempo especificado. Los valores posibles son:
- x días
- x semanas
- x meses
- x trimestres
- x años
Por ejemplo, si especifica 1 mes, el flujo de datos recupera todos los datos nuevos del sistema de origen que se encuentra en el último mes.
Tamaño del cubo
Esta configuración es necesaria y especifica el tamaño de los cubos que usa el flujo de datos para filtrar los datos. El flujo de datos divide los datos en cubos en función de la columna DateTime. Cada cubo contiene los datos que cambiaron desde la última actualización. El tamaño del cubo determina la cantidad de datos que se procesan en cada iteración. Un tamaño de cubo más pequeño significa que el flujo de datos procesa menos datos en cada iteración, pero también significa que se requieren más iteraciones para procesar todos los datos. Un tamaño de cubo mayor significa que el flujo de datos procesa más datos en cada iteración, pero también significa que se requieren menos iteraciones para procesar todos los datos.
Solo extraiga nuevos datos cuando cambie el valor máximo de esta columna
Esta configuración es necesaria y especifica la columna que usa el flujo de datos para determinar si los datos han cambiado. El flujo de datos compara el valor máximo de esta columna con el valor máximo de la actualización anterior. Si se cambia el valor máximo, el flujo de datos recupera los datos que han cambiado desde la última actualización. Si no se cambia el valor máximo, el flujo de datos no recupera ningún dato.
Extraer solo datos para períodos de conclusión
Esta configuración es opcional y especifica si el flujo de datos solo debe extraer datos durante períodos de conclusión. Si esta configuración está habilitada, el flujo de datos solo extrae datos durante períodos que concluyeron. Por lo tanto, el flujo de datos solo extrae los datos de los períodos completados y no contienen ningún dato futuro. Si esta configuración está deshabilitada, el flujo de datos extrae los datos de todos los períodos, incluidos los períodos que no se completan y contienen datos futuros.
Por ejemplo, si tiene una columna DateTime que contiene la fecha de la transacción y solo desea actualizar meses completos, puede habilitar esta configuración en combinaciones con el tamaño del cubo de month. Por lo tanto, el flujo de datos solo extrae datos durante meses completos y no extrae datos durante meses incompletos.
Configuración avanzada
Algunas opciones de configuración se consideran avanzadas y no son necesarias para la mayoría de los escenarios.
Requerir una consulta de actualización incremental para plegar por completo
Esta configuración es opcional y especifica si la consulta utilizada para la actualización incremental debe plegarse por completo. Si esta configuración está habilitada, la consulta que se usa para la actualización incremental debe plegarse por completo. Es decir, la consulta debe insertarse completamente en el sistema de origen. Si esta configuración está deshabilitada, la consulta que se usa para la actualización incremental no necesita plegarse por completo. En este caso, la consulta se puede insertar parcialmente en el sistema de origen. Recomendamosencarecidamente activar esta opción para mejorar el rendimiento y evitar recuperar datos innecesarios y sin filtrar.
Limitaciones
Solo se admiten destinos de datos basados en SQL
Actualmente, solo se admiten destinos de datos basados en SQL para la actualización incremental. Por lo tanto, solo puede usar Fabric Warehouse, Azure SQL Database o Azure Synapse Analytics como destino de datos para la actualización incremental. El motivo de esta limitación es que estos destinos de datos admiten las operaciones basadas en SQL necesarias para la actualización incremental. Usamos las operaciones Eliminar e Insertar para reemplazar los datos del destino de datos, que no se pueden realizar en paralelo en otros destinos de datos.
El destino de datos debe establecerse en un esquema fijo.
El destino de datos debe establecerse en un esquema fijo, lo que significa que el esquema de la tabla en el destino de datos debe ser fijo y no puede cambiar. Si el esquema de la tabla en el destino de datos está establecido en esquema dinámico, debe cambiarlo a esquema fijo antes de configurar la actualización incremental.
El único método de actualización admitido en el destino de datos es replace
El único método de actualización admitido en el destino de datos es replace, lo que significa que el flujo de datos reemplaza los datos de cada cubo del destino de datos por los nuevos datos. Sin embargo, los datos que están fuera del intervalo de cubos no se ven afectados. Por lo tanto, si tiene datos en el destino de datos anterior al primer cubo, la actualización incremental no afecta a estos datos de ninguna manera.
El número máximo de cubos es 50 para una sola consulta y 150 para todo el flujo de datos
El número máximo de cubos por consulta que admite el flujo de datos es 50. Si tiene más de 50 cubos, debe aumentar el tamaño del cubo o reducir el intervalo de cubos para reducir el número de cubos. Para todo el flujo de datos, el número máximo de cubos es 150. Si tiene más de 150 cubos en el flujo de datos, debe reducir el número de consultas de actualización incremental o aumentar el tamaño del cubo para reducir el número de cubos.
Diferencias entre la actualización incremental en Dataflow Gen1 y Dataflow Gen2
Entre Dataflow Gen1 y Dataflow Gen2, hay algunas diferencias en el funcionamiento de la actualización incremental. En la lista siguiente se explican las principales diferencias entre la actualización incremental en Dataflow Gen1 y Dataflow Gen2.
- La actualización incremental ahora es una característica de primera clase en Dataflow Gen2. En Dataflow Gen1, tenía que configurar la actualización incremental después de publicar el flujo de datos. En Dataflow Gen2, la actualización incremental es ahora una característica de primera clase que puede configurar directamente en el editor de flujos de datos. Esta característica facilita la configuración de la actualización incremental y reduce el riesgo de errores.
- En Dataflow Gen1, tenía que especificar el intervalo de datos histórico al configurar la actualización incremental. En Dataflow Gen2, no es necesario especificar el intervalo de datos histórico. El flujo de datos no quita ningún dato del destino que esté fuera del intervalo de cubos. Por lo tanto, si tiene datos en el destino que es anterior al primer cubo, la actualización incremental no afecta a estos datos de ninguna manera.
- En Dataflow Gen1, tenía que especificar los parámetros para la actualización incremental al configurar la actualización incremental. En Dataflow Gen2, no es necesario especificar los parámetros de la actualización incremental. El flujo de datos agrega automáticamente los filtros y parámetros como último paso de la consulta. Por lo tanto, no es necesario especificar los parámetros de la actualización incremental manualmente.
Preguntas más frecuentes
He recibido una advertencia que he usado la misma columna para detectar cambios y filtrar. ¿Qué significa esto?
Si recibe una advertencia de que usó la misma columna para detectar cambios y filtrar, significa que la columna especificada para detectar cambios también se usa para filtrar los datos. No se recomienda este uso, ya que puede provocar resultados inesperados. En su lugar, se recomienda usar una columna diferente para detectar cambios y filtrar los datos. Si los datos cambian entre cubos, es posible que el flujo de datos no pueda detectar los cambios correctamente y podría crear datos duplicados en el destino. Puede resolver esta advertencia mediante una columna diferente para detectar cambios y filtrar los datos. O bien, puede omitir la advertencia si está seguro de que los datos no cambian entre las actualizaciones de la columna especificada.
Quiero usar la actualización incremental con un destino de datos que no se admite. ¿Qué se puede hacer?
Si desea usar la actualización incremental con un destino de datos que no se admite, puede habilitar la actualización incremental en la consulta y usar una segunda consulta que haga referencia a los datos almacenados provisionalmente para actualizar el destino de datos. De este modo, puede seguir usando la actualización incremental para reducir la cantidad de datos que se deben procesar y recuperar del sistema de origen, pero debe realizar una actualización completa de los datos almacenados provisionalmente en el destino de datos. Asegúrese de configurar correctamente la ventana y el tamaño del cubo, ya que no garantizamos que los datos del almacenamiento provisional se conserven fuera del intervalo de cubos.
¿Cómo sé si mi consulta tiene habilitada la actualización incremental?
Puede ver si la consulta tiene habilitada la actualización incremental comprobando el icono situado junto a la consulta en el editor de flujos de datos. Si el icono contiene un triángulo azul, se habilita la actualización incremental. Si el icono no contiene un triángulo azul, la actualización incremental no está habilitada.
Mi origen obtiene demasiadas solicitudes cuando uso la actualización incremental. ¿Qué se puede hacer?
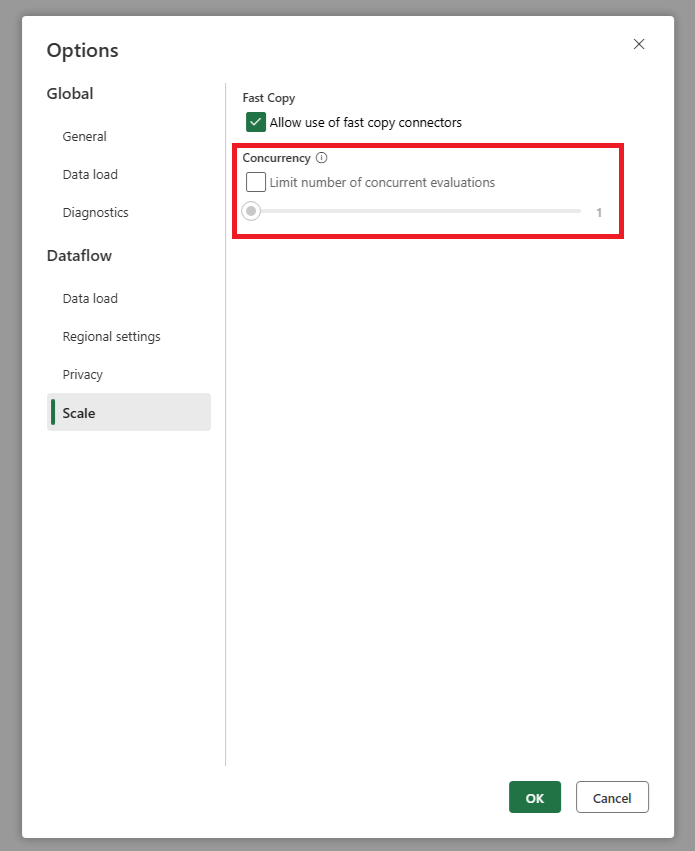
Se ha agregado una configuración que permite establecer el número máximo de evaluaciones de consultas paralelas. Esta configuración se puede encontrar en la configuración global del flujo de datos. Al establecer este valor en un número inferior, puede reducir el número de solicitudes enviadas al sistema de origen. Esta configuración puede ayudar a reducir el número de solicitudes simultáneas y mejorar el rendimiento del sistema de origen. Para establecer el número máximo de ejecuciones de consultas paralelas, vaya a la configuración global del flujo de datos, navegue hasta la pestaña Escalar y establezca el número máximo de evaluaciones de consultas paralelas. Se recomienda no habilitar este límite a menos que experimente problemas con el sistema de origen.
Quiero usar la actualización incremental, pero veo que, después de la habilitación, el flujo de datos tarda más tiempo en actualizarse. ¿Qué se puede hacer?
La actualización incremental, como se describe en este artículo, está diseñada para reducir la cantidad de datos que se deben procesar y recuperar del sistema de origen. Sin embargo, si el flujo de datos tarda más tiempo en actualizarse después de habilitar la actualización incremental, puede deberse a la sobrecarga adicional de comprobar si los datos han cambiado y el procesamiento de los cubos es mayor que el tiempo ahorrado mediante el procesamiento de menos datos. En este caso, se recomienda revisar la configuración de la actualización incremental y ajustarlas para que se ajusten mejor a su escenario. Por ejemplo, puede aumentar el tamaño del cubo para reducir el número de cubos y la sobrecarga de procesarlos. O bien, puede reducir el número de cubos aumentando el tamaño del cubo. Si sigue experimentando un bajo rendimiento después de ajustar la configuración, puede deshabilitar la actualización incremental y usar una actualización completa en su lugar, ya que podría ser más eficaz en su escenario.