Destinos de datos y configuración administrada de flujos de datos Gen2
Después de limpiar y preparar los datos con flujos de datos Gen2, quiere colocar sus datos en un destino. Puede hacerlo mediante las funcionalidades de destino de datos de flujos de datos Gen2. Con esta funcionalidad, puede elegir entre diferentes destinos, como Azure SQL, almacenes de lago de Fabric y muchos más. Luego, el flujo de datos Gen2 escribe los datos en el destino y, desde allí, puede utilizar los datos para realizar análisis e informes adicionales.
La lista siguiente contiene los destinos de datos admitidos.
- Bases de datos de Azure SQL
- Azure Data Explorer (Kusto)
- Fabric Lakehouse
- Fabric Warehouse
- Base de datos de KQL en Fabric
- Base de datos SQL en Fabric
Puntos de entrada
Cada consulta de datos del flujo de datos Gen2 puede tener un destino de datos. No se admiten funciones y listas; solo puede aplicarla a consultas tabulares. Puede especificar el destino de datos para cada consulta individualmente y puede utilizar varios destinos distintos dentro del flujo de datos.
Hay tres puntos de entrada principales para especificar el destino de los datos:
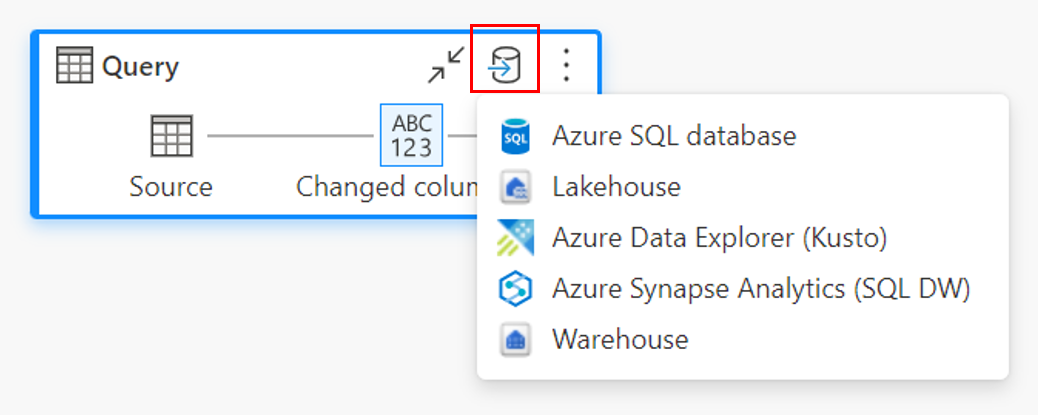
A través de la cinta de opciones superior.
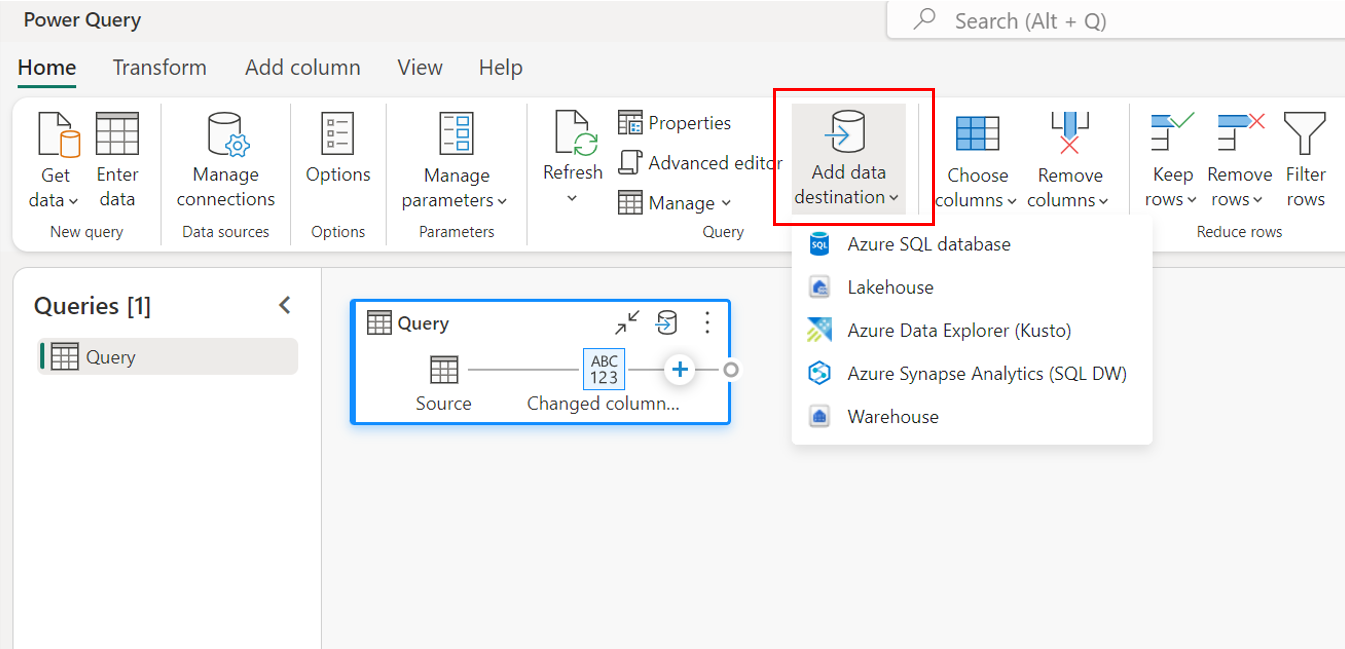
A través de la configuración de consulta.
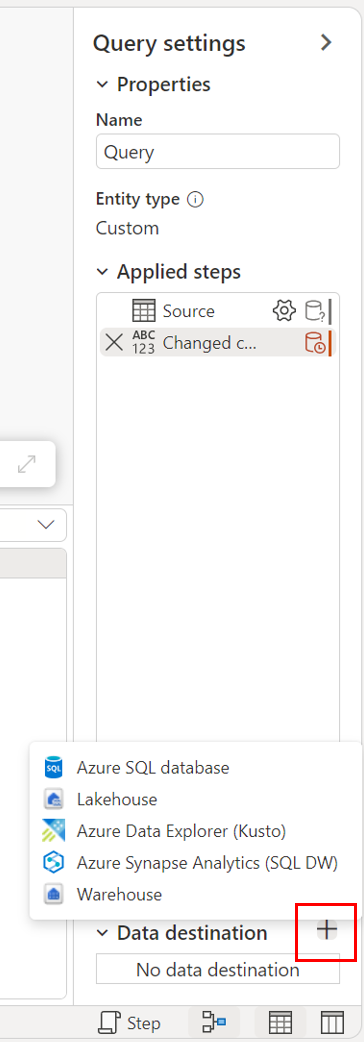
A través de la vista de diagrama.
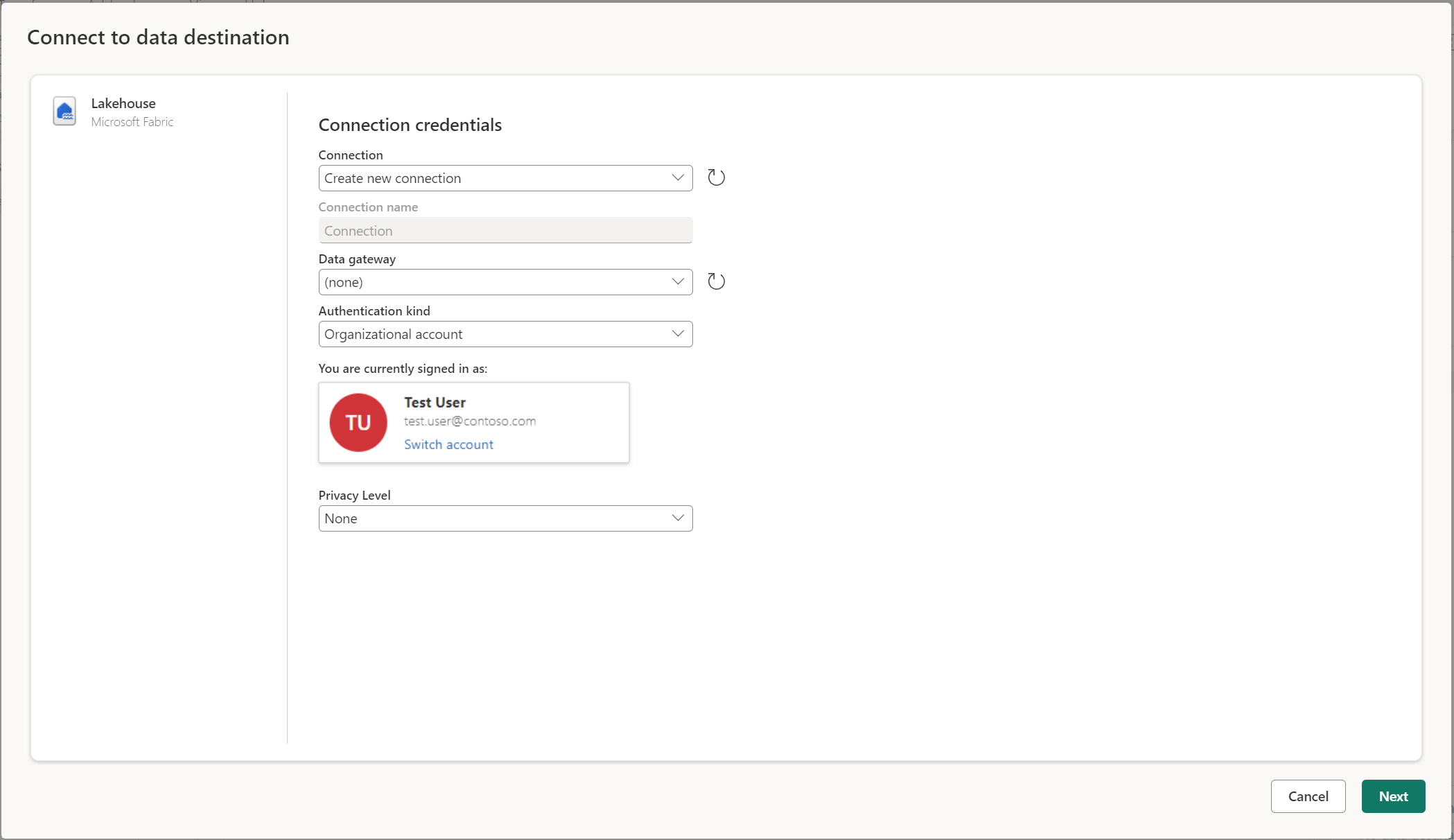
Conectarse al destino de datos
Conectarse al destino de datos es similar a la conexión a un origen de datos. Las conexiones se pueden utilizar para leer y escribir los datos, dado que tiene los permisos adecuados en el origen de datos. Tiene que crear una nueva conexión o elegir una conexión existente y, a continuación, seleccionar Siguiente.
Crear una tabla o elegir una tabla existente
Al cargar en el destino de datos, puede crear una nueva tabla o elegir una tabla existente.
Crear una nueva tabla
Al elegir crear una nueva tabla, durante la actualización del flujo de datos Gen2 se crea una nueva tabla en el destino de datos. Si más adelante se elimina la tabla manualmente desde el destino, el flujo de datos vuelve a crear la tabla durante la siguiente actualización del flujo de datos.
De manera predeterminada, el nombre de la tabla tiene el mismo nombre que el nombre de la consulta. Si el nombre de la tabla tiene caracteres no válidos que el destino no admite, el nombre de la tabla se ajusta automáticamente. Por ejemplo, muchos destinos no admiten espacios ni caracteres especiales.
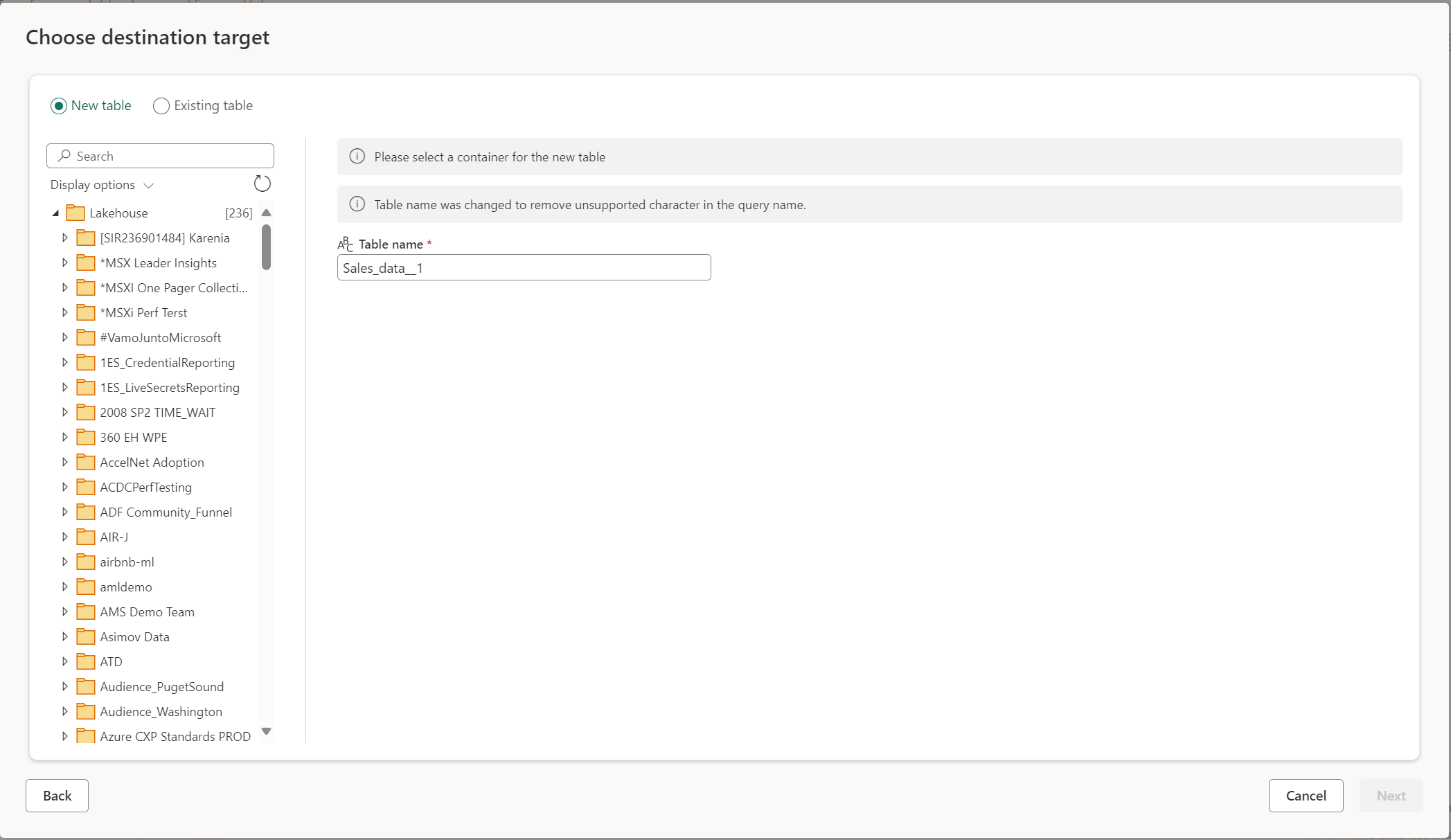
A continuación, debe seleccionar el contenedor de destino. Si eligió cualquiera de los destinos de datos de Fabric, puede usar el navegador para seleccionar el artefacto de Fabric en el que quiere cargar los datos. En el caso de los destinos de Azure, puede especificar la base de datos durante la creación de la conexión, o bien seleccionar la base de datos en la experiencia del navegador.
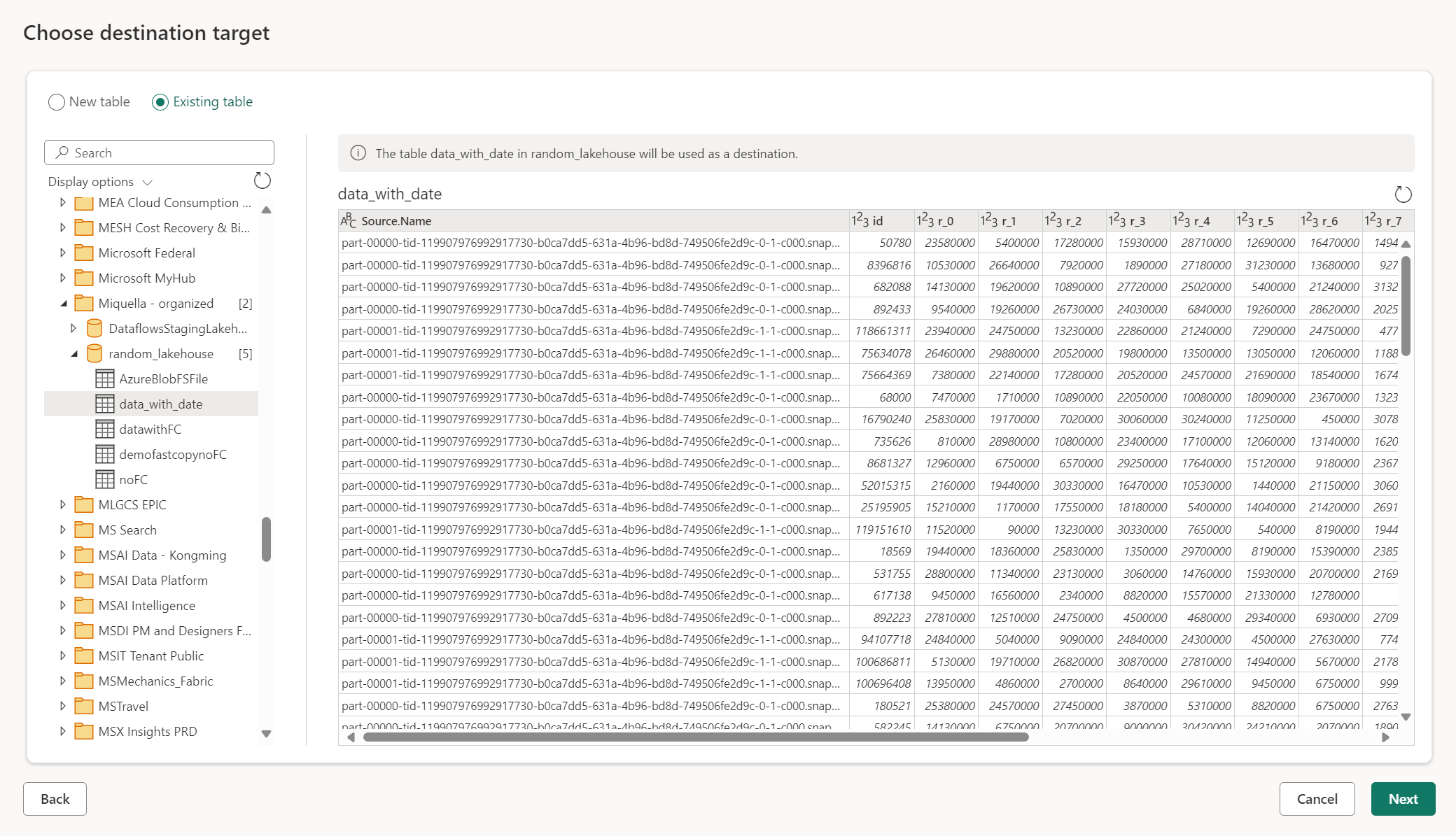
Usar una tabla existente
Para elegir una tabla existente, utilice el botón de alternancia en la parte superior del navegador. Al elegir una tabla existente, debe elegir tanto el artefacto o la base de datos de Fabric como la tabla mediante el navegador.
Cuando se usa una tabla existente, la tabla no se puede volver a crear en ningún escenario. Si elimina la tabla manualmente del destino de datos, el flujo de datos Gen2 no vuelve a crear la tabla en la siguiente actualización.
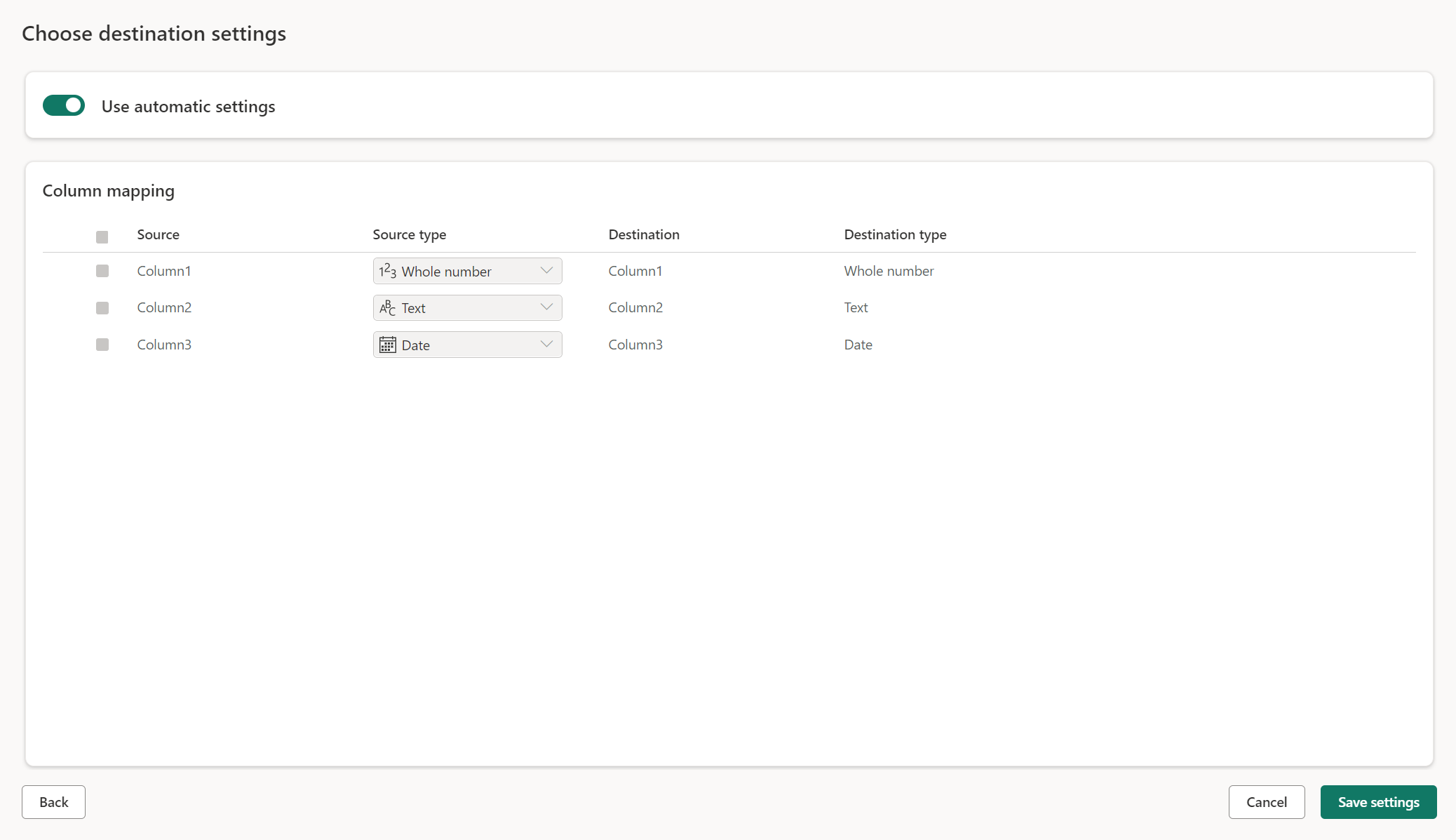
Configuración administrada para tablas nuevas
Cuando se carga en una nueva tabla, la configuración automática está activada de manera predeterminada. Si utiliza la configuración automática, el flujo de datos Gen2 administra la asignación por usted. La configuración automática proporciona el siguiente comportamiento:
Reemplazo del método de actualización: Los datos se reemplazan en cada actualización del flujo de datos. Se quitan los datos del destino. Los datos del destino se reemplazan por los datos de salida del flujo de datos.
Asignación administrada: La asignación se administra automáticamente. Cuando tenga que realizar cambios en los datos o consultas para agregar otra columna o cambiar un tipo de datos, la asignación se ajusta automáticamente para este cambio cuando vuelve a publicar el flujo de datos. No tiene que ir a la experiencia del destino de datos cada vez que realice cambios en el flujo de datos, lo que permite cambios de esquema sencillos cuando vuelve a publicar el flujo de datos.
Quitar la tabla y volver a crearla: Para permitir estos cambios de esquema, en cada actualización del flujo de datos se quita la tabla y se la vuelve a crear. La actualización del flujo de datos puede provocar la eliminación de relaciones o medidas que se agregaron anteriormente a la tabla.
Nota:
Actualmente, la configuración automática solo se admite para almacenes de lago y base de datos de Azure SQL como destino de datos.
Configuración manual
Al desactivar la opción Usar configuración automática, se obtiene control total sobre cómo cargar los datos en el destino de datos. Para realizar cualquier cambio en la asignación de columnas, puede cambiar el tipo de origen o excluir cualquier columna que no necesite en el destino de datos.
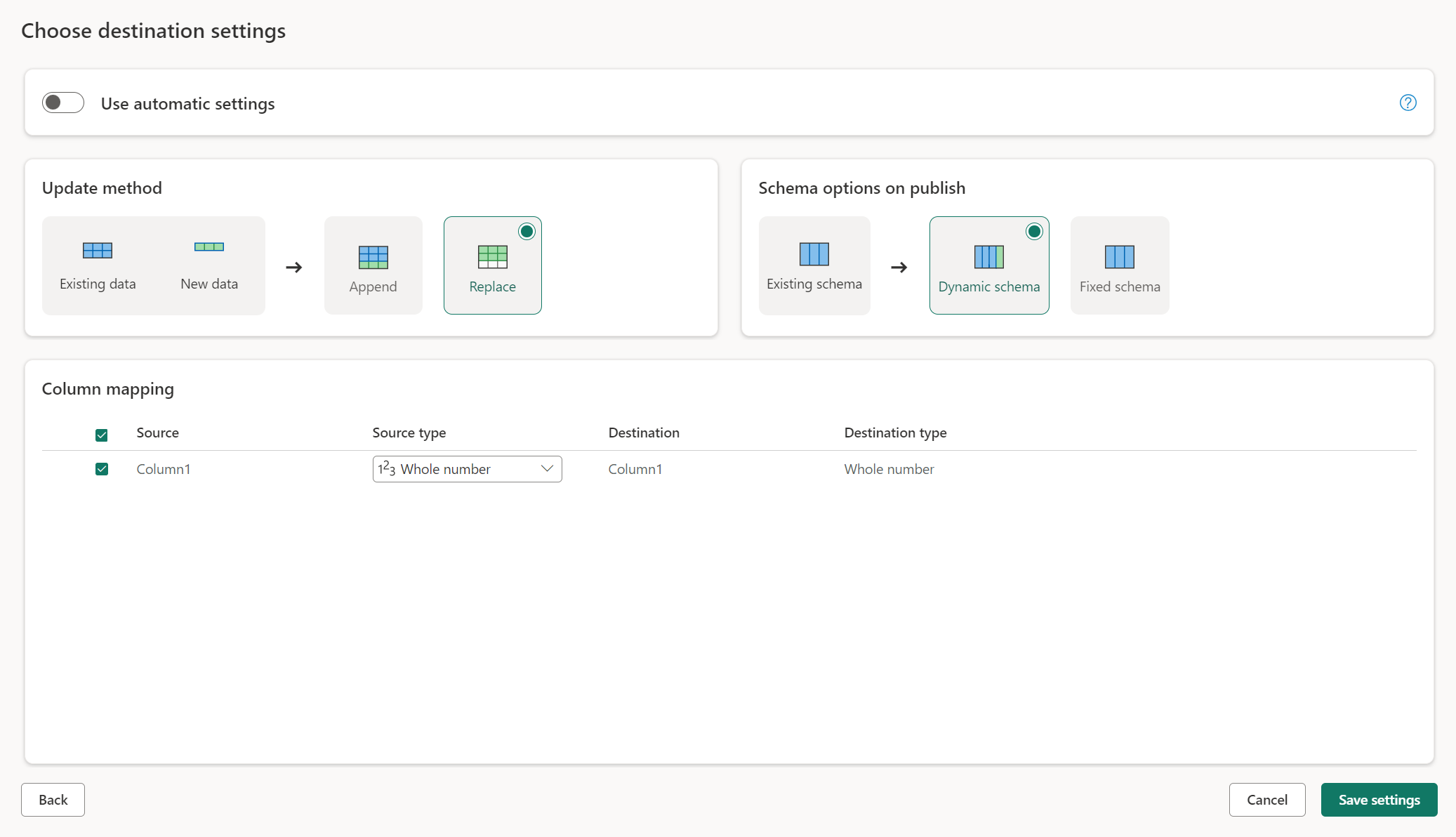
Métodos de actualización
La mayoría de los destinos admiten Anexar y Reemplazar como métodos de actualización. Sin embargo, las bases de datos de KQL en Fabric y Azure Data Explorer no admiten Reemplazar como método de actualización.
Reemplazar: En cada actualización del flujo de datos, los datos se quitan del destino y se reemplazan por los datos de salida del flujo de datos.
Anexar: En cada actualización del flujo de datos, los datos de salida del flujo de datos se anexan a los datos existentes en la tabla de destino de datos.
Opciones de esquema al publicar
Las opciones de esquema al publicar solo se aplican cuando el método de actualización es Reemplazar. Al anexar datos, no es posible realizar cambios en el esquema.
Esquema dinámico: Al elegir el esquema dinámico, se permiten cambios de esquema en el destino de datos al volver a publicar el flujo de datos. Dado que no está utilizando la asignación administrada, tiene que actualizar la asignación de columnas en el flujo de destino del flujo de datos al realizar cambios en la consulta. Cuando se actualiza el flujo de datos, se quita la tabla y se vuelve a crear. La actualización del flujo de datos puede provocar la eliminación de relaciones o medidas que se agregaron anteriormente a la tabla.
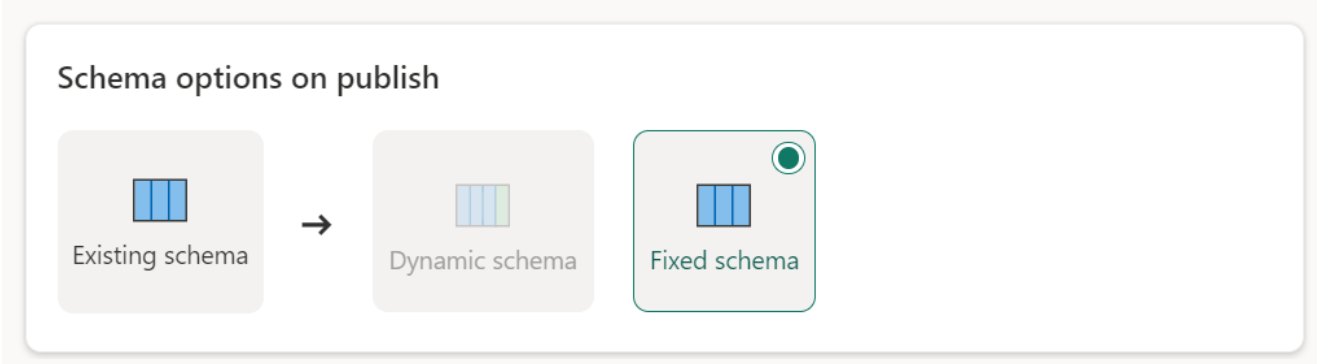
Esquema fijo: Cuando se elige el esquema fijo, no es posible realizar cambios en el esquema. Cuando se actualiza el flujo de datos, solo se quitan las filas de la tabla y reemplazan por los datos de salida del flujo de datos. Las relaciones o medidas de la tabla permanecen intactas. Si realiza algún cambio a la consulta en el flujo de datos, se produce un error en la publicación del flujo de datos si se detecta que el esquema de consulta no coincide con el esquema del destino de datos. Utilice esta opción cuando no tenga planes de cambiar el esquema y ni de agregar relaciones o medida a la tabla de destino.
Nota:
Al cargar datos en el almacén, solo se admite el esquema fijo.
Tipos de origen de datos admitidos por destino
| Tipos de datos admitidos por ubicación de almacenamiento | DataflowStagingLakehouse | Salida de Azure DB (SQL) | Salida de Azure Data Explorer | Salida de Fabric Lakehouse (LH) | Salida de Fabric Warehouse (WH) | Salida de Fabric SQL Database (SQL) |
|---|---|---|---|---|---|---|
| Action | No | N.º | N.º | N.º | N.º | No |
| Any | No | N.º | N.º | N.º | N.º | No |
| Binary | No | N.º | N.º | N.º | N.º | No |
| Moneda | Sí | Sí | Sí | Sí | No | Sí |
| Fecha, hora y zona horaria | Sí | Sí | Sí | No | No | Sí |
| Duration | No | No | Sí | No | N.º | No |
| Función | No | N.º | N.º | N.º | N.º | No |
| Ninguno | No | N.º | N.º | N.º | N.º | No |
| Null | No | N.º | N.º | N.º | N.º | No |
| Time | Sí | Sí | No | N.º | No | Sí |
| Tipo | No | N.º | N.º | N.º | N.º | No |
| Estructurado (Lista, Registro, Tabla) | No | N.º | N.º | N.º | N.º | No |
Temas avanzados
Uso del almacenamiento provisional antes de cargar en un destino
Para mejorar el rendimiento del procesamiento de consultas, se puede utilizar el almacenamiento provisional en los flujos de datos Gen2 para usar el proceso de Fabric para ejecutar las consultas.
Cuando el almacenamiento provisional está habilitado en las consultas (el comportamiento predeterminado), los datos se cargan en la ubicación de almacenamiento provisional, que es una instancia interna del almacén de lago a la que solo pueden acceder los flujos de datos.
El uso de ubicaciones de almacenamiento provisional puede mejorar el rendimiento en algunos casos en los que el envió de la consulta al punto de conexión de análisis de SQL es más rápido que en el procesamiento de memoria.
Cuando se cargan datos en Lakehouse u otros destinos que no son de almacenamiento, de manera predeterminada se deshabilita la característica de almacenamiento provisional para mejorar el rendimiento. Al cargar datos en el destino de datos, los datos se escriben directamente en el destino de datos sin usar el almacenamiento provisional. Si desea usar el almacenamiento provisional de la consulta, puede volver a habilitarla.
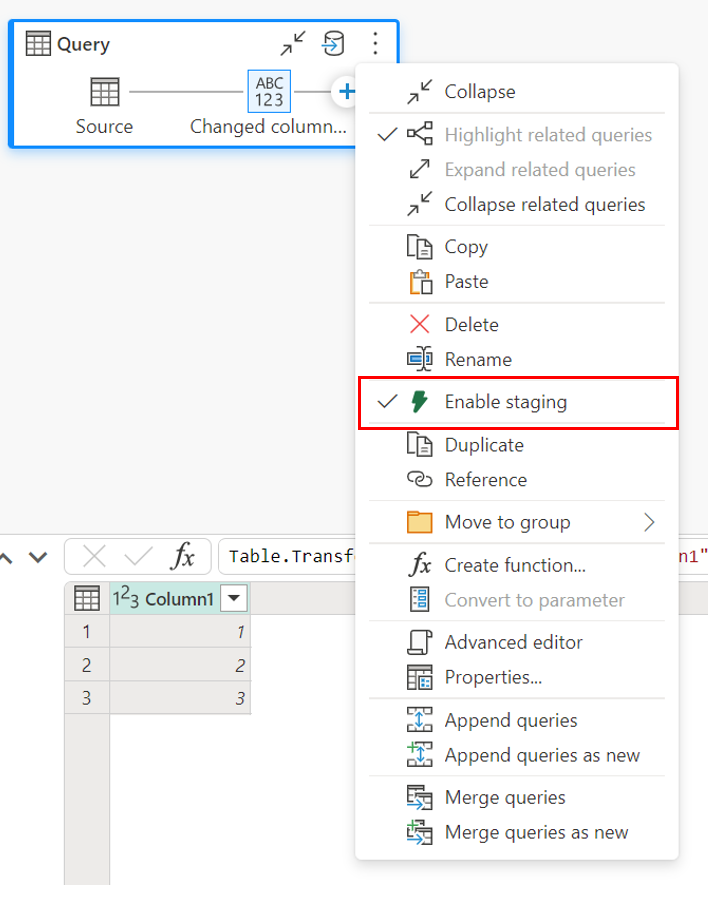
Para habilitar el almacenamiento provisional, haga clic con el botón derecho en la consulta y habilite el almacenamiento provisional mediante el botón Habilitar almacenamiento provisional. La consulta se vuelve azul.
Carga de datos en el almacén
Al cargar datos en el almacén, se requiere almacenamiento provisional antes de la operación de escritura en el destino de datos. Este requisito mejora el rendimiento. Actualmente, solo se admite la carga en la misma área de trabajo que el flujo de datos. Asegúrese de que el almacenamiento provisional esté habilitado para todas las consultas que se cargan en el almacén.
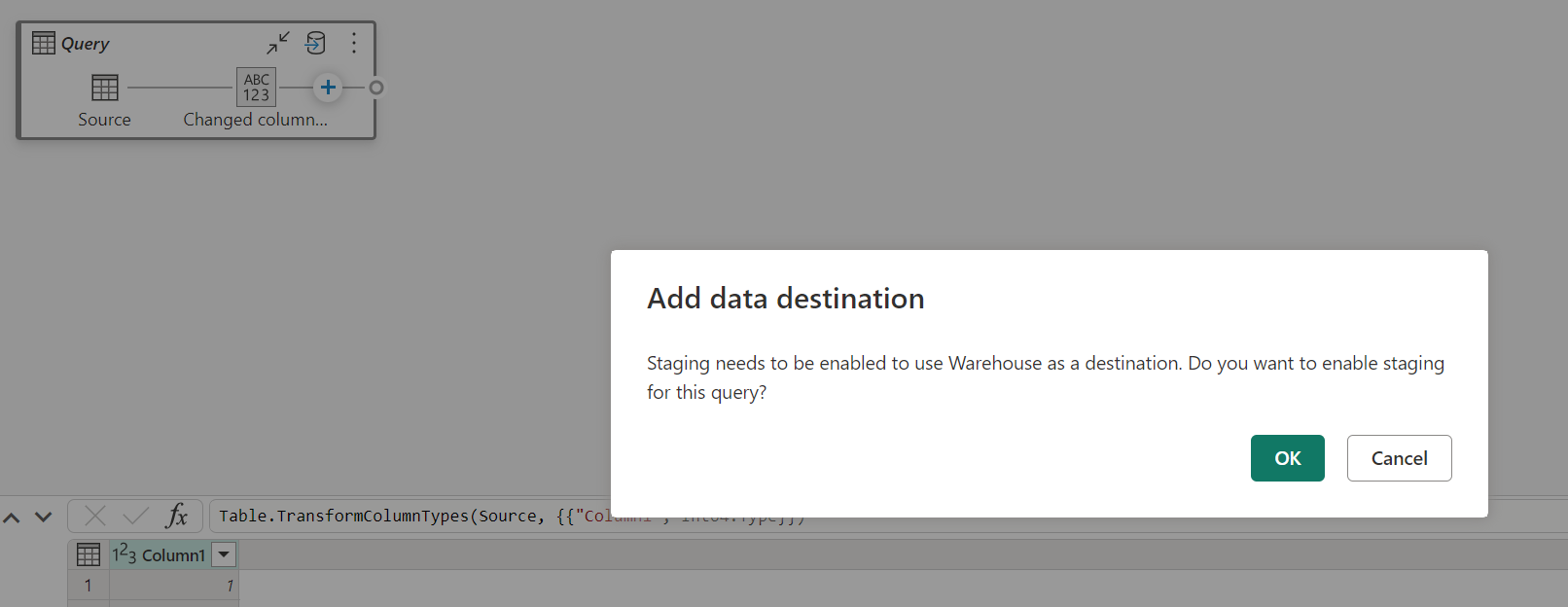
Cuando el almacenamiento provisional esté deshabilitado y elija Almacén como destino de salida, recibirá una advertencia para habilitar el almacenamiento provisional antes de poder configurar el destino de datos.
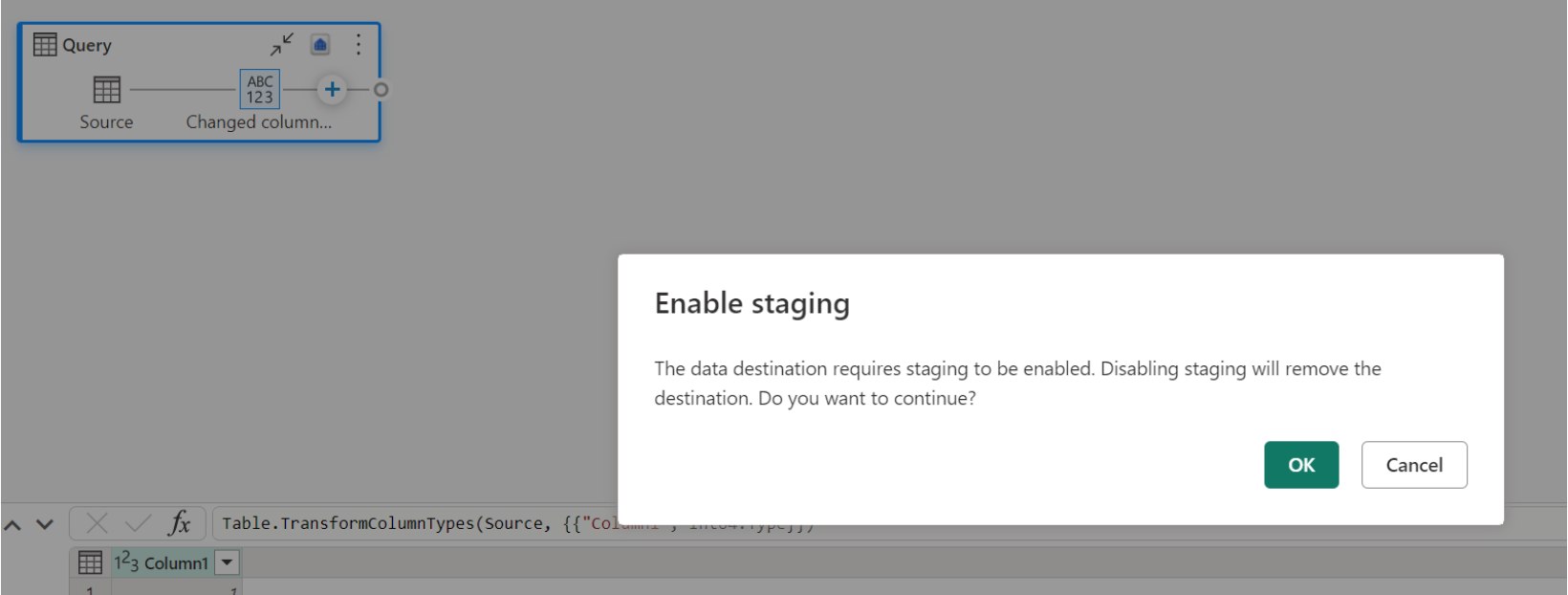
Si ya tiene un almacén como destino e intenta deshabilitar el almacenamiento provisional, aparece una advertencia. Puede quitar el almacén como destino o descartar la acción de almacenamiento provisional.
Vaciado del destino de datos de Lakehouse
Cuando se usa Lakehouse como destino para Dataflow Gen2 en Microsoft Fabric, es fundamental realizar un mantenimiento normal para garantizar un rendimiento óptimo y una administración de almacenamiento eficaz. Una tarea de mantenimiento esencial consiste en aspirar el destino de los datos. Este proceso ayuda a quitar los archivos antiguos a los que ya no hace referencia el registro de tabla delta, lo que optimiza los costes de almacenamiento y mantiene la integridad de los datos.
¿Por qué es importante el vaciado?
- Optimización del almacenamiento: con el tiempo, las tablas Delta acumulan archivos antiguos que ya no son necesarios. El vaciado ayuda a limpiar estos archivos, liberar espacio de almacenamiento y reducir los costes.
- Mejora del rendimiento: la eliminación de archivos innecesarios puede mejorar el rendimiento de las consultas reduciendo el número de archivos que deben examinarse durante las operaciones de lectura.
- Integridad de datos: asegurarse de que solo se conserven los archivos relevantes ayuda a mantener la integridad de sus datos, lo que evita posibles problemas con archivos no confirmados que podrían provocar fallos en el lector o corrupción de tablas.
Cómo vaciar el destino de los datos
Para vaciar las tablas delta en Lakehouse, siga estos pasos:
- Vaya a su Lakehouse: desde su cuenta de Microsoft Fabric, vaya a la instancia de Lakehouse deseada.
- Mantenimiento de tablas de Access: en el explorador de Lakehouse, haga clic con el botón derecho en la tabla que quiera mantener o use los puntos suspensivos para acceder al menú contextual.
- Seleccione las opciones de mantenimiento: elija la entrada de menú Mantenimiento y seleccione la opción Vaciado.
- Ejecute el comando de vacíado: establezca el umbral de retención (el valor predeterminado es de siete días) y ejecute el comando de vaciado seleccionando Ejecutar ahora.
procedimientos recomendados
- Período de retención: establezca un intervalo de retención de al menos siete días para asegurarse de que las instantáneas antiguas y los archivos no confirmados no se quiten prematuramente, lo que podría interrumpir los lectores y escritores simultáneos de tablas.
- Mantenimiento normal: programe el vaciado normal como parte de la rutina de mantenimiento de datos para mantener las tablas delta optimizadas y listas para el análisis.
Al incorporar el vaciado en la estrategia de mantenimiento de datos, puede asegurarse de que el destino de Lakehouse siga siendo eficaz, rentable y confiable para las operaciones de flujo de datos.
Para obtener información más detallada sobre el mantenimiento de tablas en Lakehouse, consulte la documentación de mantenimiento de tablas delta.
Admisión de valores NULL
En algunos casos, cuando tiene una columna que acepta valores NULL, Power Query la detecta como que no acepta valores NULL y, al escribir en el destino de datos, el tipo de columna no acepta valores NULL. Durante la actualización, se produce el siguiente error:
E104100 Couldn't refresh entity because of an issue with the mashup document MashupException.Error: DataFormat.Error: Error in replacing table's content with new data in a version: #{0}., InnerException: We can't insert null data into a non-nullable column., Underlying error: We can't insert null data into a non-nullable column. Details: Reason = DataFormat.Error;Message = We can't insert null data into a non-nullable column.; Message.Format = we can't insert null data into a non-nullable column.
Para forzar las columnas que aceptan valores NULL, puede probar los pasos siguientes:
Elimine la tabla del destino de datos.
Quite el destino de datos del flujo de datos.
Vaya al flujo de datos y actualice los tipos de datos mediante el siguiente código de Power Query:
Table.TransformColumnTypes( #"PREVIOUS STEP", { {"COLLUMNNAME1", type nullable text}, {"COLLUMNNAME2", type nullable Int64.Type} } )Agregue el destino de datos.
Conversión y escalado de tipos de datos
En algunos casos, el tipo de datos dentro del flujo de datos difiere de lo que se admite en el destino de datos. A continuación, se muestran algunas conversiones predeterminadas que hemos implementado para asegurarnos de que todavía puede obtener los datos en el destino de datos:
| Destino | Tipo de datos de flujo de datos | Tipo de datos de destino |
|---|---|---|
| Fabric Warehouse | Tipo Int8. | Tipo Int16. |