Configuración de Azure Database for PostgreSQL en una actividad de copia
En este artículo se describe cómo usar la actividad de copia en la canalización de datos para copiar datos desde y hacia Azure Database for PostgreSQL.
Configuración admitida
Para la configuración de cada pestaña en la actividad de copia, vaya a las secciones siguientes respectivamente.
General
Consulte las instruccionesgenerales para configurar la pestaña de parámetros General.
Origen
Vaya a la pestaña Origen para configurar el origen de la actividad de copia. Consulte el siguiente contenido para obtener la configuración detallada.
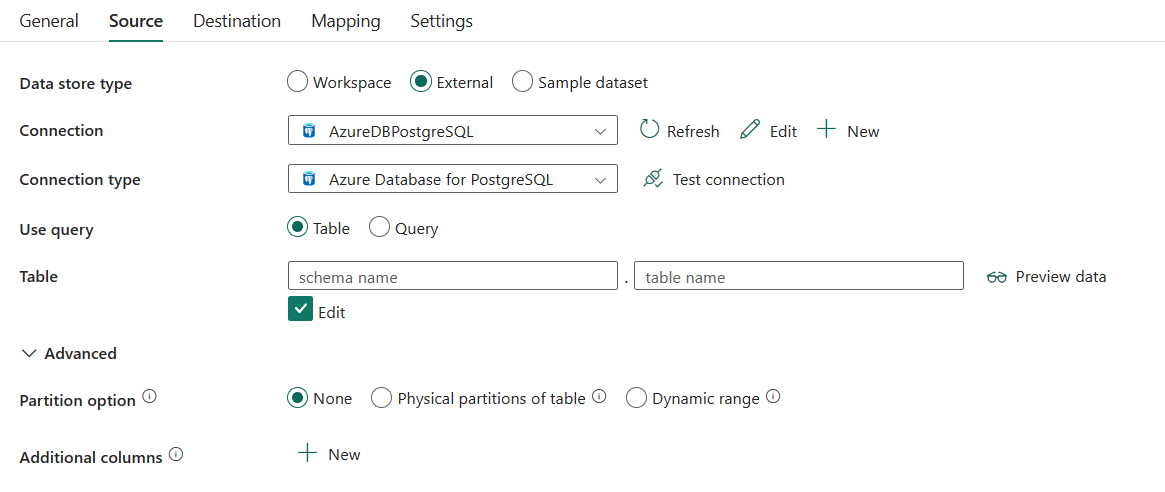
Se requieren las siguientes tres propiedades:
- Tipo de banco de datos : Seleccione Externo.
- Conexión: seleccione una conexión de Azure Database for PostgreSQL en la lista de conexiones. Si no existe ninguna conexión, cree una conexión de Azure Database for PostgreSQL seleccionando Nueva.
- Tipo de conexión: seleccione Azure Database for PostgreSQL.
- Usar consulta: seleccione Tabla para leer datos de la tabla especificada o seleccione Consulta para leer datos mediante consultas.
Si selecciona Tabla:
Tabla: seleccione la tabla en la lista desplegable o seleccione Editar para escribirla manualmente para leer datos.

Si selecciona Consulta:
Consulta: especifique la consulta SQL personalizada para leer los datos. Por ejemplo:
SELECT * FROM mytableoSELECT * FROM "MyTable".Nota:
Tenga en cuenta que en PostgreSQL el nombre de la entidad se trata sin distinción de mayúsculas y minúsculas si no está entre comillas.

En Avanzado, puede especificar los campos siguientes:
Opción de partición: especifica las opciones de creación de particiones de datos que se usan para cargar datos de Azure Database for PostgreSQL. Cuando se habilita una opción de partición (es decir, no Ninguno), el grado de paralelismo para cargar datos simultáneamente desde una instancia de Azure Database for PostgreSQL se controla mediante el Grado de paralelismo de copia en la pestaña de configuración de la actividad de copia.
Si selecciona Ninguno, decide no usar la partición.
Si selecciona Particiones físicas de la tabla:
Nombres de partición: especifique la lista de particiones físicas que se deben copiar.
Si usa una consulta para recuperar datos de origen, enlace
?AdfTabularPartitionNameen la cláusula WHERE. Para ver un ejemplo, consulte la sección Copia en paralelo desde Azure Database for PostgreSQL.
Si selecciona Rango dinámico:
Nombre de columna de partición: especifique el nombre de la columna de origen en tipo entero o fecha/datetime (
int,smallint,bigint,date,timestamp without time zone,timestamp with time zoneotime without time zone) que se usarán mediante la creación de particiones de intervalo para la copia en paralelo. Si no se especifica, se detectará automáticamente la clave principal de la tabla y se usará como columna de partición.Si usa una consulta para recuperar datos de origen, enlace
?AdfRangePartitionColumnNameen la cláusula WHERE. Para ver un ejemplo, consulte la sección Copia en paralelo desde Azure Database for PostgreSQL.Límite de partición superior: especifique el valor máximo de la columna de partición para copiar los datos.
Si usa una consulta para recuperar datos de origen, enlace
?AdfRangePartitionUpbounden la cláusula WHERE. Para ver un ejemplo, consulte la sección Copia en paralelo desde Azure Database for PostgreSQL. .Límite de partición superior: especifique el valor mínimo de la columna de partición para copiar los datos.
Si usa una consulta para recuperar datos de origen, enlace
?AdfRangePartitionLowbounden la cláusula WHERE. Para ver un ejemplo, consulte la sección Copia en paralelo desde Azure Database for PostgreSQL.
Columnas adicionales: añada columnas de datos adicionales para almacenar la ruta relativa o el valor estático de los archivos de origen. La expresión se admite para este último.
Destination
Vaya a la pestaña Destino para configurar el destino de la actividad de copia. Consulte el siguiente contenido para obtener la configuración detallada.
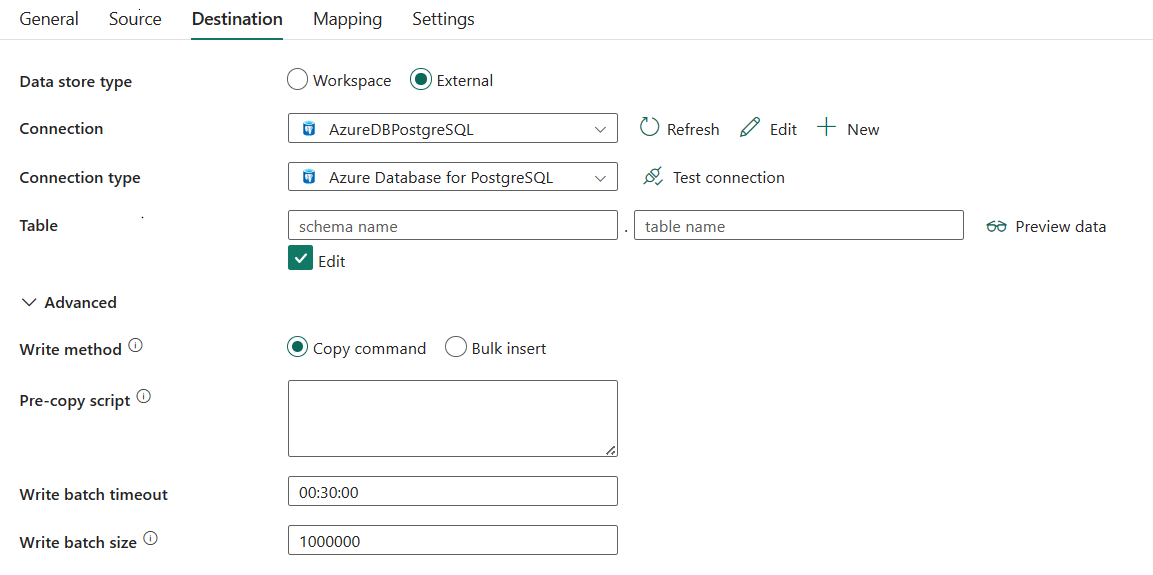
Se requieren las siguientes tres propiedades:
- Tipo de banco de datos : Seleccione Externo.
- Conexión: seleccione una conexión de Azure Database for PostgreSQL en la lista de conexiones. Si no existe ninguna conexión, cree una conexión de Azure Database for PostgreSQL seleccionando Nueva.
- Tipo de conexión: seleccione Azure Database for PostgreSQL.
- Tabla: seleccione la tabla de la lista desplegable o seleccione Editar para introducirla manualmente para escribir los datos.
En Avanzado, puede especificar los campos siguientes:
Método de escritura: seleccione el método usado para escribir datos en Azure Database for PostgreSQL. Seleccione el comando Copiar (valor predeterminado, que es más eficaz) e Inserción masiva.
Script de copia previa: especifique una consulta SQL para que se ejecute la actividad de copia antes de escribir datos en Azure Database for PostgreSQL en cada ejecución. Puede usar esta propiedad para limpiar los datos cargados previamente.
Tiempo de espera de escritura por lotes: especifique el tiempo que se concede a la operación de inserción por lotes para que finalice antes de que se agote el tiempo de espera. El valor permitido es timespan. El valor predeterminado es 00:30:00 (30 minutos).
Escribir tamaño de lote: especifique el número de filas cargadas en Azure Database for PostgreSQL por lote. El valor permitido es un entero que representa el número de filas. El valor predeterminado es 1 000 000.
Asignación
Para configurar la pestaña Asignación, consulte Configurar las asignaciones en la pestaña Asignación.
Configuración
Para la configuración de la pestañaConfiguración, vaya a Configurar los otros parámetros en la ficha Configuración .
Copia paralela de Azure Database for PostgreSQL
En la actividad de copia, el conector de Azure Database for PostgreSQL proporciona la opción de crear particiones de datos integradas para copiar los datos en paralelo. Puede encontrar las opciones de creación de particiones de datos en la pestaña Origen de la actividad de copia.
Al habilitar la copia con particiones, la actividad de copia ejecuta consultas en paralelo en el origen de Azure Database for PostgreSQL para cargar los datos por particiones. El grado paralelo se controla mediante el Grado de paralelismo de copia en la pestaña de configuración de la actividad de copia. Por ejemplo, si establece Grado de paralelismo de copia en cuatro, el servicio genera y ejecuta simultáneamente cuatro consultas basadas en la configuración y la opción de partición especificadas, y cada consulta recupera una parte de los datos de su instancia de Azure Database for PostgreSQL.
Se sugiere habilitar la copia en paralelo con la creación de particiones de datos, especialmente si se cargan grandes cantidades de datos de Azure Database for PostgreSQL. Estas son algunas configuraciones sugeridas para diferentes escenarios. Cuando se copian datos en un almacén de datos basado en archivos, se recomienda escribirlos en una carpeta como varios archivos (solo especifique el nombre de la carpeta), en cuyo caso el rendimiento es mejor que escribirlos en un único archivo.
| Escenario | Configuración sugerida |
|---|---|
| Carga completa de una tabla grande con particiones físicas. | Opción de partición: particiones físicas de la tabla. Durante la ejecución, el servicio detecta automáticamente las particiones físicas y copia los datos por particiones. |
| Carga completa de una tabla grande, sin particiones físicas, aunque con una columna de enteros para la creación de particiones de datos. | Opciones de partición: Intervalo dinámico. Columna de partición: especifique la columna usada para crear la partición de datos. Si no se especifica, se usa la columna de clave principal. |
| Cargue una gran cantidad de datos mediante una consulta personalizada con particiones físicas. | Opción de partición: particiones físicas de la tabla. Consulta: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.Nombre de la partición: especifique los nombres de las particiones desde las que se copiarán los datos. Si no se especifican, el servicio detecta automáticamente las particiones físicas en la tabla que ha especificado en el conjunto de datos de PostgreSQL. Durante la ejecución, el servicio reemplaza ?AdfTabularPartitionName por el nombre real de la partición y se lo envía a Azure Database for PostgreSQL. |
| Carga de grandes cantidades de datos mediante una consulta personalizada, sin particiones físicas, aunque cuenta con una columna de enteros para la creación de particiones de datos. | Opciones de partición: Intervalo dinámico. Consulta: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Columna de partición: especifique la columna usada para crear la partición de datos. Puede crear particiones en la columna con el tipo de datos entero o date/datetime. Límite superior de partición y Límite inferior de partición: especifique si desea filtrar por la columna de partición para recuperar datos solo entre el intervalo inferior y el superior. Durante la ejecución, el servicio reemplaza ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound, y ?AdfRangePartitionLowbound por el nombre real de la columna y los rangos de valor para cada partición y los envía a Azure Database for PostgreSQL. Por ejemplo, si establece la columna de partición "ID" con un límite inferior de 1 y un límite superior de 80, con la copia en paralelo establecida en 4, el servicio recupera los datos de 4 particiones. Los identificadores están comprendidos entre [1, 20], [21, 40], [41, 60] y [61, 80] respectivamente. |
Procedimientos recomendados para cargar datos con la opción de partición:
- Seleccione una columna distintiva como columna de partición (como clave principal o clave única) para evitar la asimetría de datos.
- Si la tabla tiene una partición integrada, use la opción de partición "Particiones físicas de tabla" para obtener un mejor rendimiento.
Resumen de tabla
La siguiente tabla contiene más información sobre la actividad de copia en Azure Database for PostgreSQL.
Información de origen
| Nombre | Descripción | Value | Obligatorio | Propiedad de script JSON |
|---|---|---|---|---|
| Tipo de almacén de datos | El tipo de almacén de datos. | Externo | Sí | / |
| Connection | La conexión al almacén de datos de origen. | < la conexión de Azure Database for PostgreSQL > | Sí | conexión |
| Tipo de conexión | El tipo de conexión de origen. | Azure Database para PostgreSQL | Sí | / |
| Usar consulta | La manera de leer datos. Aplique Tabla para leer datos de la tabla especificada o aplique Consulta para leer datos mediante consultas. | • Tabla • Consulta |
Sí | • typeProperties (en typeProperties ->source)- esquema - tabla • consulta |
| Nombres de partición | Lista de particiones físicas que deben copiarse. Si usa una consulta para recuperar datos de origen, enlace ?AdfTabularPartitionName en la cláusula WHERE. |
< los nombres de partición > | No | partitionNames |
| Nombre de columna de partición | Nombre de la columna de origen en tipo entero o fecha/datetime (int, smallint, bigint, date, timestamp without time zone, timestamp with time zone o time without time zone) que se usarán mediante la creación de particiones de intervalo para la copia en paralelo. Si no se especifica, se detectará automáticamente la clave principal de la tabla y se usará como columna de partición. |
< los nombres de columna de partición > | No | partitionColumnName |
| Límite superior de partición | El valor máximo de la columna de partición para copiar datos. Si usa una consulta para recuperar datos de origen, enlace ?AdfRangePartitionUpbound en la cláusula WHERE. |
< límite superior de partición > | No | partitionUpperBound |
| Límite inferior de partición | El valor mínimo de la columna de partición para copiar datos. Si usa una consulta para recuperar datos de origen, enlace ?AdfRangePartitionLowbound en la cláusula WHERE. |
< límite inferior de partición > | No | partitionLowerBound |
| Columnas adicionales | Agregue columnas de datos adicionales para almacenar la ruta de acceso relativa o el valor estático de los archivos de origen. La expresión se admite para este último. | • Name • Valor |
No | additionalColumns: • nombre • valor |
Información de destino
| Nombre | Descripción | Value | Obligatorio | Propiedad de script JSON |
|---|---|---|---|---|
| Tipo de almacén de datos | El tipo de almacén de datos. | Externo | Sí | / |
| Connection | La conexión al almacén de datos de destino. | < la conexión de Azure Database for PostgreSQL > | Sí | conexión |
| Tipo de conexión | Tipo de conexión de destino. | Azure Database para PostgreSQL | Sí | / |
| Tabla | Tabla de datos de destino para escribir datos. | < nombre de la tabla de destino> | Sí | typeProperties (en typeProperties :>sink):- esquema - tabla |
| Método de escritura | El método usado para escribir datos en Azure Database for PostgreSQL. | • Copiar comando (valor predeterminado) • Inserción masiva |
No | writeMethod: • CopyCommand • BulkInsert |
| Pre-copy script (Script anterior a la copia) | Una consulta SQL para que se ejecute la actividad de copia antes de escribir datos en Azure Database for PostgreSQL en cada ejecución. Puede usar esta propiedad para limpiar los datos cargados previamente. | < el script anterior a la copia > | No | preCopyScript |
| Tiempo de espera de escritura por lotes | Tiempo que se concede a la operación de inserción por lotes para que finalice antes de que se agote el tiempo de espera. | timespan (El valor predeterminado es 00:30:00 [30 minutos]). |
No | writeBatchTimeout |
| Tamaño del lote de escritura | Número de filas cargadas en Azure Database for PostgreSQL por lote. | integer (el valor predeterminado es 1 000 000) |
No | writeBatchSize |