Transformación de datos mediante la ejecución de una actividad de Azure HDInsight
La actividad Azure HDInsight en Data Factory para Microsoft Fabric le permite orquestar los siguientes tipos de trabajos de Azure HDInsight:
- Ejecutar consultas de Hive
- Invocar un programa MapReduce
- Ejecutar consultas Pig
- Ejecutar un programa spark
- Ejecutar un programa de Hadoop Stream
En este artículo se proporciona un tutorial paso a paso que describe cómo crear una actividad de Azure HDInsight mediante la interfaz de Data Factory.
Requisitos previos
Para empezar, debe completar los siguientes requisitos previos:
- Una cuenta de inquilino con una suscripción activa. Cree una cuenta gratuita.
- Se crea un área de trabajo.
Adición de una actividad de Azure HDInsight (HDI) a una canalización con la interfaz de usuario
Cree una canalización de datos en el área de trabajo.
Busque Azure HDInsight desde la tarjeta de la pantalla de inicio y selecciónelo o seleccione la actividad en la barra Actividades para agregarlo al lienzo de la canalización.
Creación de la actividad desde la tarjeta de la pantalla de inicio:

Creación de la actividad desde la barra Actividades:
Seleccione la nueva actividad de Azure HDInsight en el lienzo del editor de canalizaciones si aún no está seleccionada.
Consulte la guía de Configuración general para configurar las opciones que se encuentran en la pestaña Configuración general.

Configuración del clúster de HDI
Seleccione la pestaña Clúster de HDI. A continuación, puede elegir una conexión de HDInsight existente o crearla.
En Conexión de recursos, elija el Azure Blob Storage que haga referencia al clúster de Azure HDInsight. Puede elegir un almacén de blobs existente o crear una nueva.
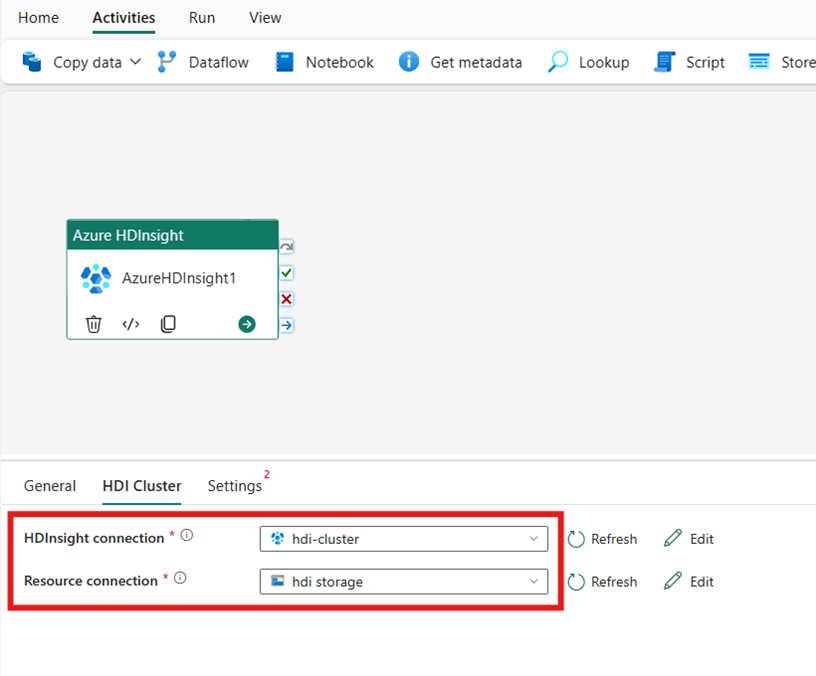
Definir configuración
Seleccione la pestaña Configuración para ver la configuración avanzada de la actividad.
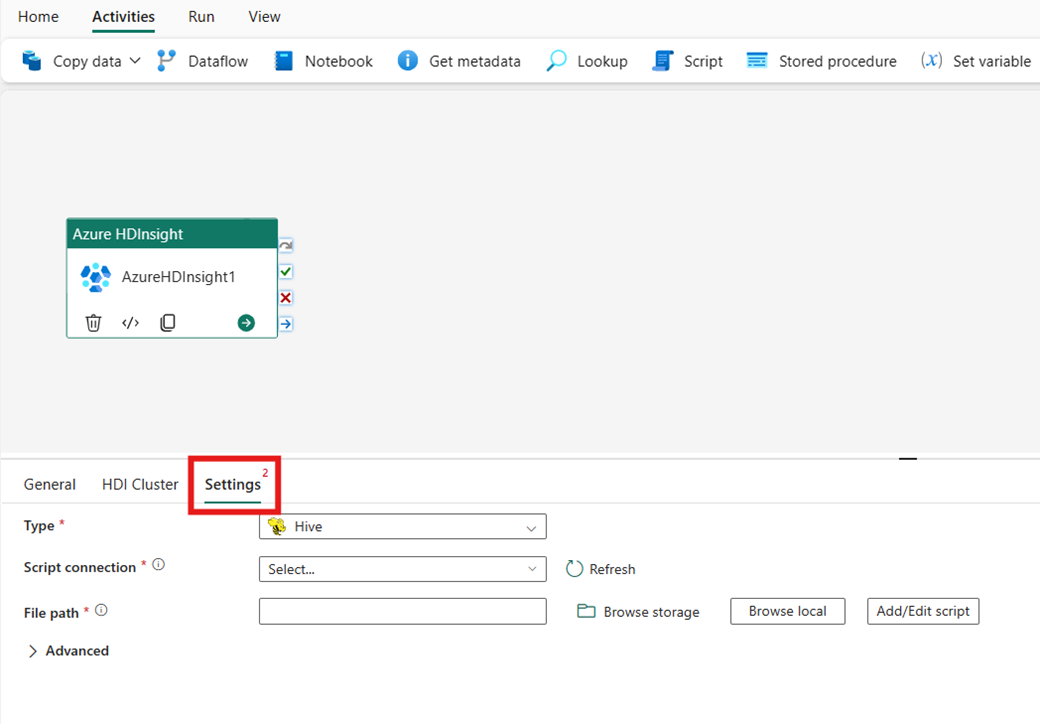
Todas las propiedades avanzadas del clúster y las expresiones dinámicas admitidas en el servicio vinculado hdInsight de Azure Data Factory y Synapse Analytics ahora también se admiten en la actividad de Azure HDInsight para Data Factory en Microsoft Fabric, en la sección Opciones avanzadas de la UI. Estas propiedades admiten expresiones parametrizadas personalizadas, fáciles de usar y con contenido dinámico.
Tipo de clúster
Para configurar las opciones del clúster de HDInsight, elija primero su Tipo en las opciones disponibles, como Hive, Map Reduce, Pig, Spark y Streaming.
Hive
Si elige Hive para Tipo, la actividad ejecuta una consulta de Hive. Opcionalmente, puede especificar la conexión de script que hace referencia a una cuenta de almacenamiento que contiene el tipo de Hive. De forma predeterminada, se usa la conexión de almacenamiento que especificó en la pestaña Clúster de HDI. Debe especificar la ruta de acceso de archivo que se va a ejecutar en Azure HDInsight. Opcionalmente, puede especificar más configuraciones en la sección Opciones avanzadas, Información de depuración, Tiempo de espera de consulta, Argumentos, Parámetros y Variables.

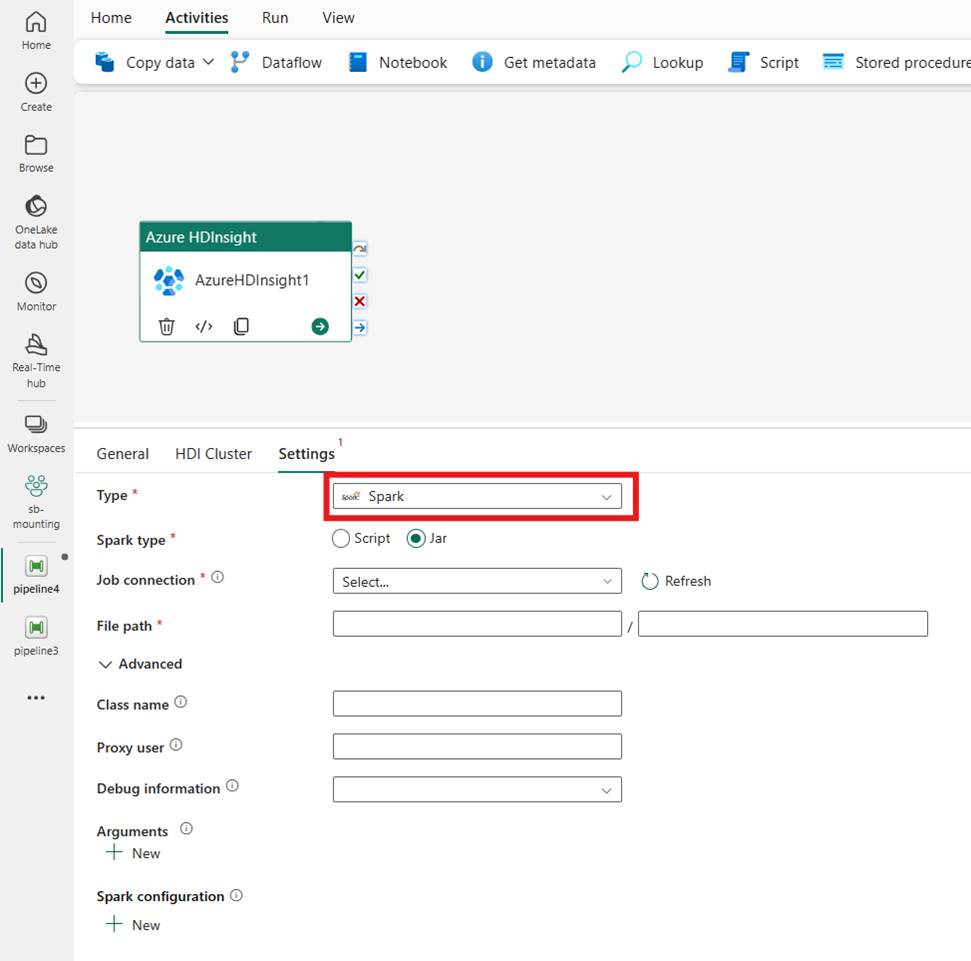
MapReduce
Si elige Map Reduce para Tipo, la actividad invoca un programa Map Reduce. Opcionalmente, puede especificar la conexión de Jar que hace referencia a una cuenta de almacenamiento que contiene el tipo de Map Reduce. De forma predeterminada, se utiliza la conexión de almacenamiento que especificó en la pestaña Clúster de HDI. Debe especificar el nombre de clase y la ruta de acceso de archivo que se va a ejecutar en Azure HDInsight. Opcionalmente, puede especificar más detalles de configuración, como importar bibliotecas Jar, información de depuración, argumentos y parámetros en la sección Opciones avanzadas.
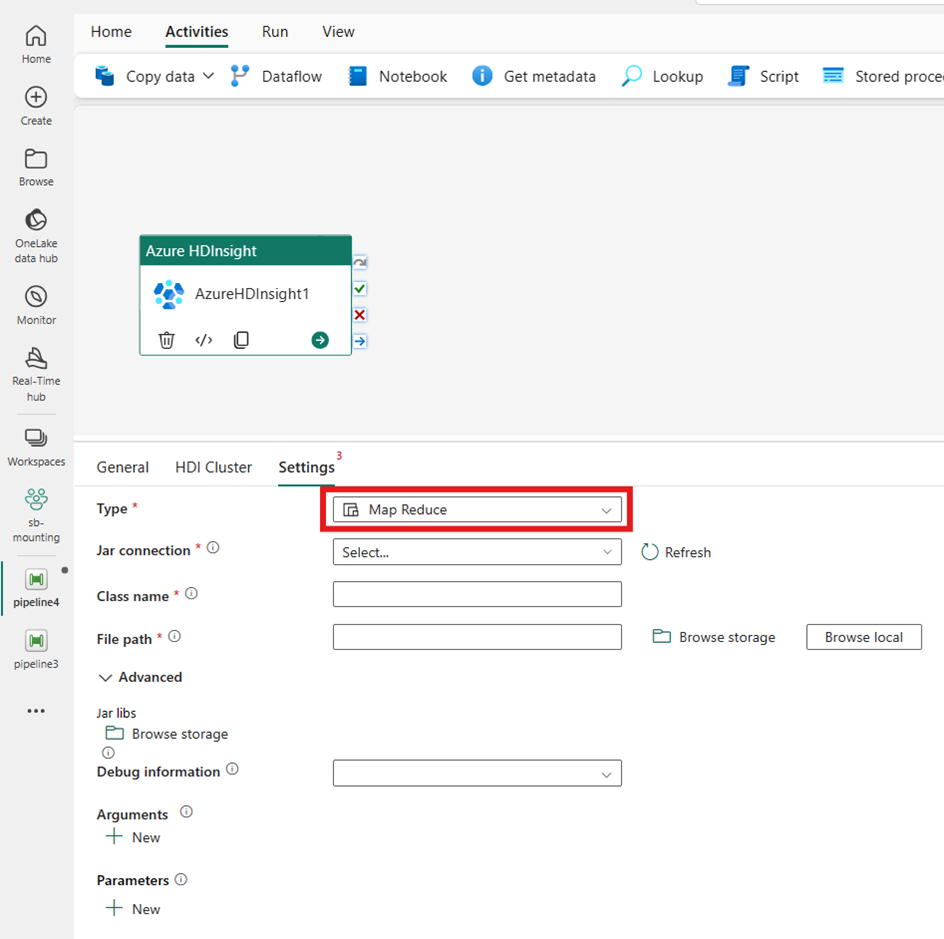
Pig
Si elige Pig para Tipo, la actividad invoca una consulta de Pig. Opcionalmente, puede especificar la configuración de conexión script que hace referencia a la cuenta de almacenamiento que contiene el tipo de Pig. De forma predeterminada, se utiliza la conexión de almacenamiento que especificó en la pestaña Clúster de HDI. Debe especificar la ruta de acceso de archivo que se va a ejecutar en Azure HDInsight. Opcionalmente, puede especificar más configuraciones como Información de depuración, Tiempo de espera de consulta, Argumentos, Parámetros y Variables en la sección Opciones avanzadas.
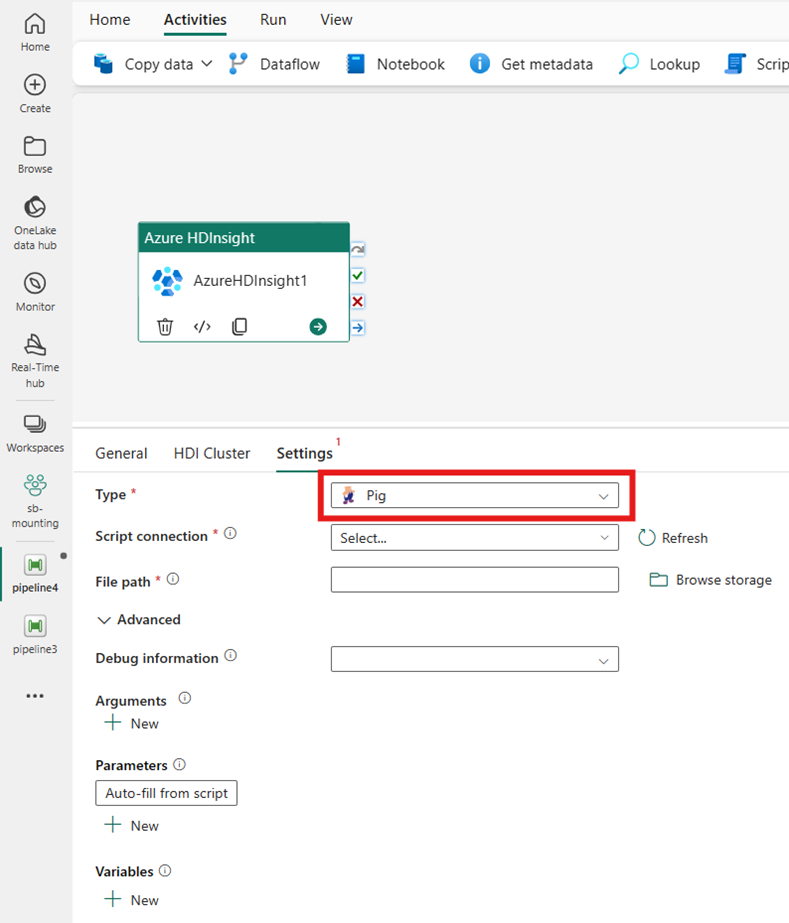
Spark
Si elige Spark para Tipo, la actividad invoca un programa Spark. Seleccione Script o Jar para el tipo de Spark. Opcionalmente, puede especificar la conexión de trabajo que hace referencia a la cuenta de almacenamiento que contiene el tipo de Spark. De forma predeterminada, se utiliza la conexión de almacenamiento que especificó en la pestaña Clúster de HDI. Debe especificar la ruta de acceso de archivo que se va a ejecutar en Azure HDInsight. Opcionalmente, puede especificar más configuraciones como Nombre de clase, Usuario de Proxy, Información de depuración, Tiempo de espera de consulta, Argumentos y Configuración de Spark en la sección Opciones avanzadas.
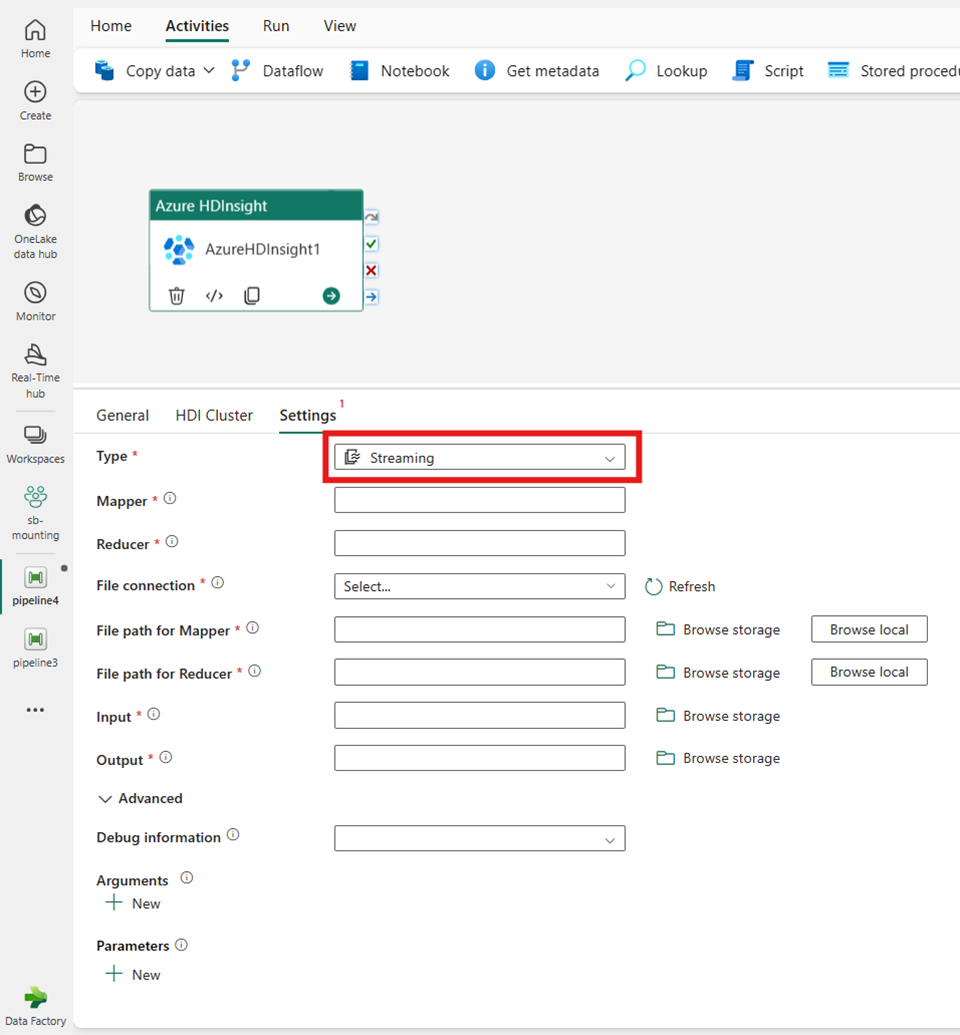
Streaming
Si elige Streaming para Tipo, la actividad invoca un programa streaming. Especifique los nombres del Asignador y del Reductor y, opcionalmente, puede especificar la conexión de archivo que hace referencia a la cuenta de almacenamiento que contiene el tipo de streaming. De forma predeterminada, se utiliza la conexión de almacenamiento que especificó en la pestaña Clúster de HDI. Debe especificar la ruta de acceso de archivo para el asignador y la ruta de acceso de archivo para el reductor para que se ejecuten en Azure HDInsight. Incluya las opciones entrada y salida, así como para la ruta de acceso WASB. Opcionalmente, puede especificar más configuraciones como Información de depuración, Tiempo de espera de consulta, Argumentos y Parámetros en la sección Opciones avanzadas.
Referencia de propiedades
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | En Hadoop Streaming Activity, el tipo de actividad es HDInsightStreaming | Sí |
| mapper | Especifica el nombre del archivo ejecutable del asignador | Sí |
| reducer | Especifica el nombre del archivo ejecutable del reductor | Sí |
| combiner | Especifica el nombre del archivo ejecutable del combinador | No |
| conexión de archivos | Referencia a un servicio vinculado de Azure Storage que se usa para almacenar los programas Asignador, Combinador y Reductor que se van a ejecutar. | No |
| En este caso solo se admiten conexiones a Azure Blob Storage y ADLS Gen2. Si no especifica esta conexión, se usa la conexión de almacenamiento definida en la conexión de HDInsight. | ||
| filePath | Proporcione una matriz de ruta de acceso a los programas Asignador, Combinador y Reductor almacenados en el almacenamiento de Azure Storage al que la conexión de archivos hace referencia. | Sí |
| input | Especifica la ruta de acceso de WASB al archivo de entrada para el asignador. | Sí |
| output | Especifica la ruta de acceso de WASB al archivo de salida para el reductor. | Sí |
| getDebugInfo | Especifica si se copian los archivos de registro en el almacenamiento de Azure Storage que usa el clúster de HDInsight o que está especificado por scriptLinkedService. | No |
| Valores permitidos: Ninguno, Siempre o Error. Valor predeterminado: Ninguno. | ||
| argumentos | Especifica una matriz de argumentos para un trabajo de Hadoop. Los argumentos se pasan a cada tarea como argumentos de la línea de comandos. | No |
| defines | Especifique parámetros como pares clave-valor para hacer referencia en el script de Hive. | No |
Guardar y ejecutar o programar la canalización
Después de configurar las demás actividades necesarias para la canalización, cambie a la pestaña Inicio en la parte superior del editor de canalizaciones y seleccione el botón Guardar para guardar la canalización. Seleccione Ejecutar para ejecutarlo directamente o Planificar para programarlo. También puede ver el historial de ejecución aquí o configurar otras opciones.
