Transformación de datos mediante la ejecución de una actividad de Azure Databricks
La actividad Azure Databricks en Data Factory para Microsoft Fabric le permite orquestar los siguientes trabajos de Azure Databricks:
- Notebook
- Jar
- Python
En este artículo se proporciona un tutorial paso a paso que describe cómo crear una actividad de Azure Databricks mediante la interfaz de Data Factory.
Requisitos previos
Para empezar, debe completar los siguientes requisitos previos:
- Una cuenta de inquilino con una suscripción activa. Cree una cuenta gratuita.
- Se crea un área de trabajo.
Configuración de una actividad de Azure Databricks
Para usar una actividad de Azure Databricks en una canalización, complete los pasos siguientes:
Configuración de la conexión
Cree una canalización en el área de trabajo.
Haga clic en agregar una actividad de canalización y busque Azure Databricks.
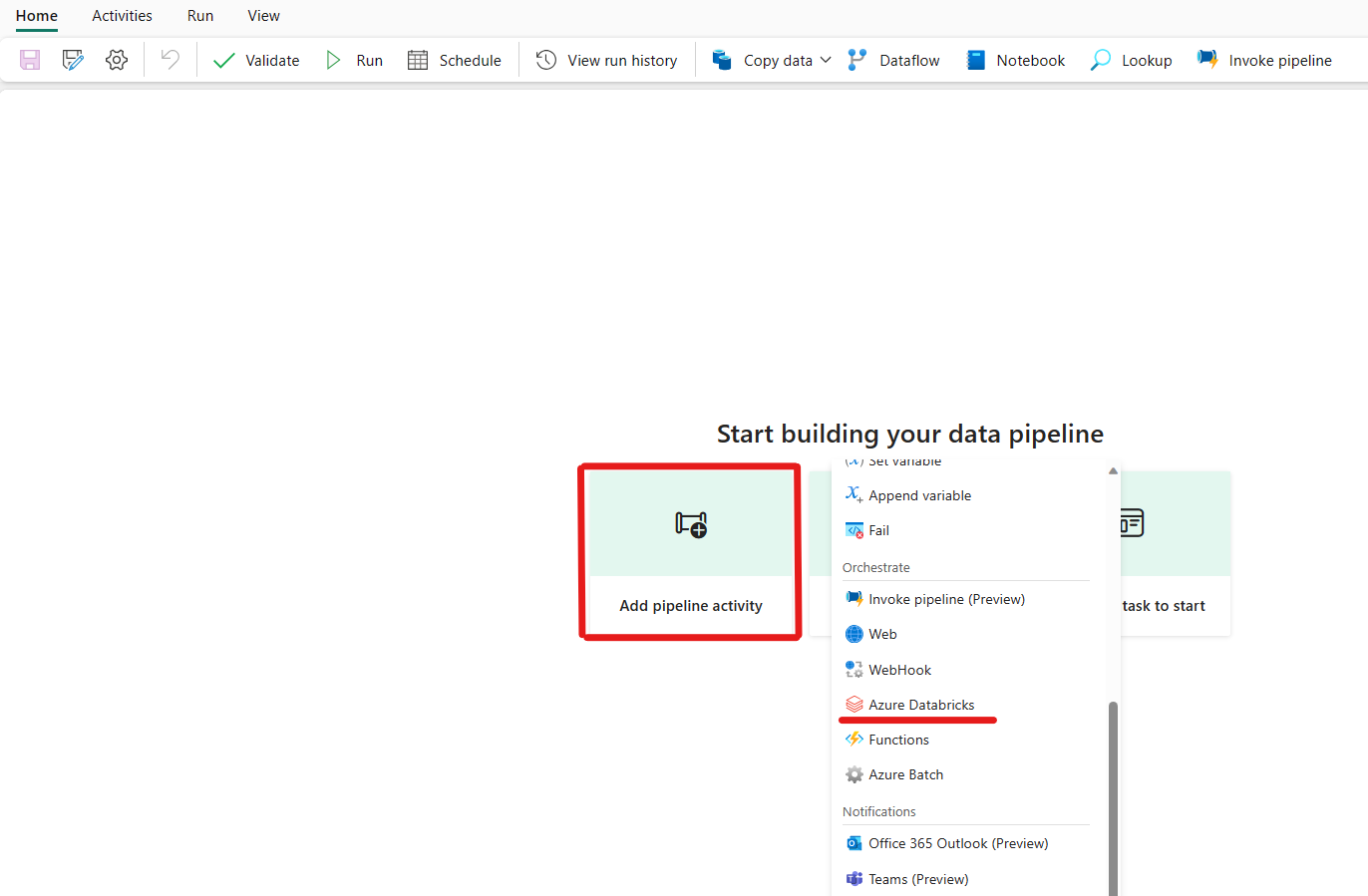
Alternativamente, puede buscar Azure Databricks en el panel Actividades de la canalización y seleccionarlo para añadirlo al lienzo de la canalización.
Seleccione la nueva actividad de Azure Databricks en el lienzo si aún no está seleccionada.
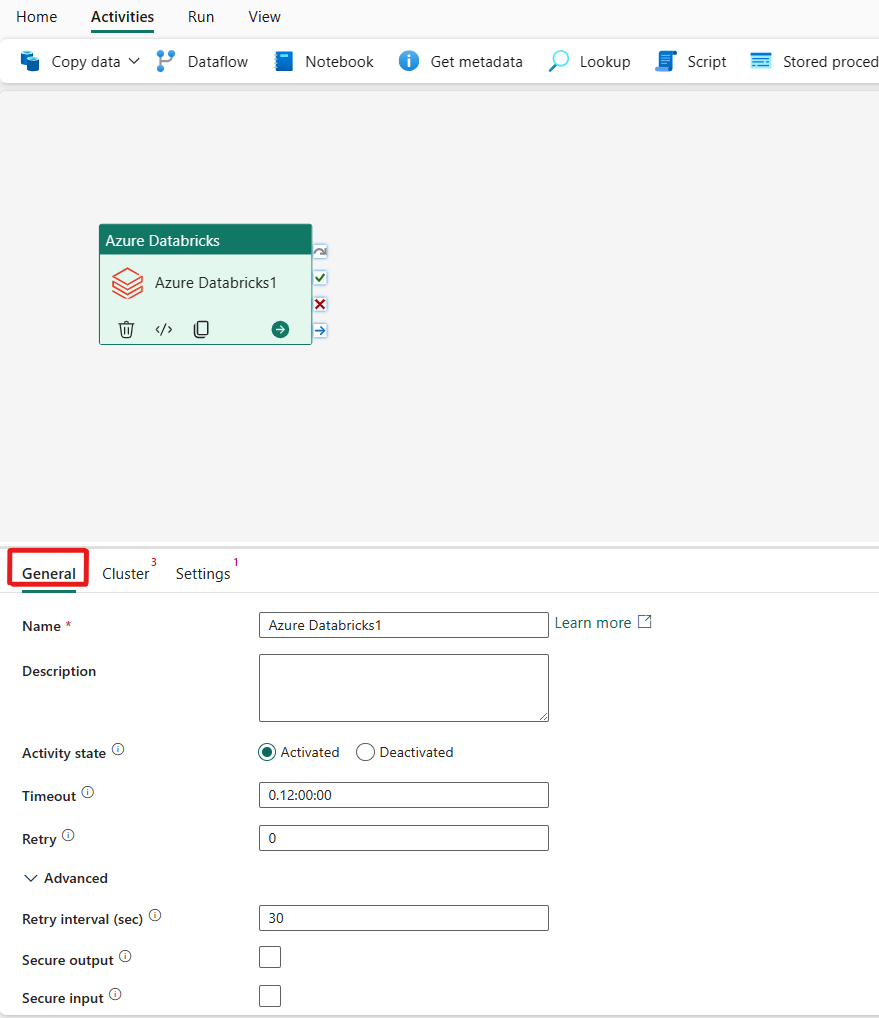
Consulte las instruccionesgenerales para configurar la pestaña de parámetros General.
Configuración de clústeres
Seleccione la pestañaClúster. A continuación, puede elegir una conexión Azure Databricks existente o crear una nuevay luego elegir un nuevo clúster de trabajounclúster interactivo existente, o ungrupo de instancias existente.
En función de lo que elija para el clúster, rellene los campos correspondientes como se muestra.
- En el nuevo clúster de trabajos y en el grupo de instancias existente, también tienes la capacidad de configurar el número de trabajadores y habilitar instancias de acceso puntual.
También puedes especificar opciones de clúster adicionales, como las directivas de clúster, la configuración de Spark, las variables de entorno de Spark, y las etiquetas personalizadas, según sea necesario para el clúster al que te conectes. scripts de inicialización de Databricks y ruta de acceso de destino del registro de clúster también se pueden agregar en la configuración adicional del clúster.
Nota:
Todas las propiedades avanzadas del clúster y las expresiones dinámicas admitidas en el servicio vinculado Azure Databricks de Azure Data Factory ahora también se admiten en la actividad de Azure Databricks en Microsoft Fabric, en la sección “Configuración de clúster adicional” de la interfaz de usuario. Dado que estas propiedades ahora se incluyen dentro de la interfaz de usuario de la actividad, se pueden usar fácilmente con una expresión (contenido dinámico) sin necesidad de la especificación JSON Avanzado en el servicio vinculado de Azure Databricks de Azure Data Factory.
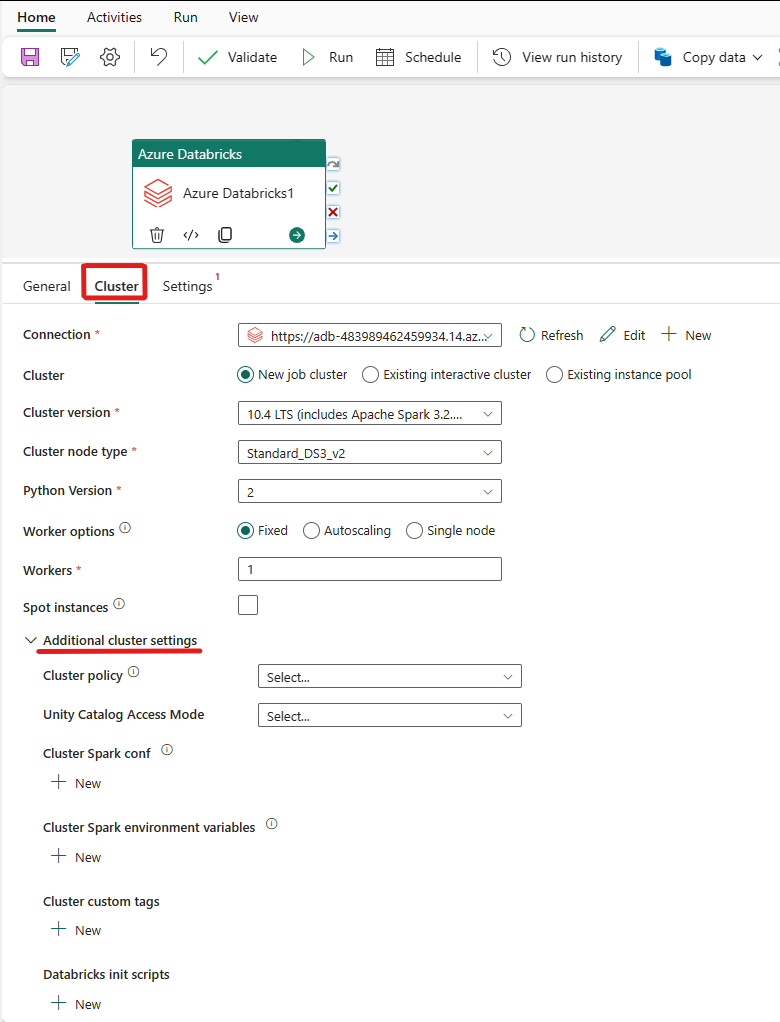
La actividad de Azure Databricks ahora también admite el soporte para la directiva de clústeres y Unity Catalog.
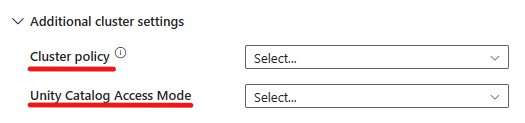
- En configuración avanzada, tiene la opción de elegir la directiva de clústeres para poder especificar qué configuraciones de clústeres se permiten.
- Además, en configuración avanzada, tiene la opción de configurar el modo de acceso a Unity Catalog para mayor seguridad. Los tipos de modo de acceso disponibles son:
- Modo de acceso de usuario único Este modo está diseñado para escenarios en los que un único usuario utiliza cada clúster. Garantiza que el acceso a los datos en el clúster está restringido solo a ese usuario. Este modo es útil para las tareas que requieren aislamiento y gestión de datos individuales.
- Modo de acceso compartido En este modo, varios usuarios pueden acceder al mismo clúster. Combina la gobernanza de datos de Unity Catalog con las listas de control de acceso (ACL) de tablas heredadas. Este modo permite el acceso de datos colaborativos, además de mantener los protocolos de gobernanza y seguridad. Sin embargo, tiene ciertas limitaciones, como no admitir Databricks Runtime ML, trabajos de envío de Spark y API de Spark específicas y UDF.
- Sin modo de acceso Este modo deshabilita la interacción con Unity Catalog, lo que significa que los clústeres no tienen acceso a los datos administrados por Unity Catalog. Este modo es útil para las cargas de trabajo que no requieren las características de gobernanza de Unity Catalog.
Configuración de opciones
Al seleccionar la pestaña Configuración, puede elegir entre 3 opciones que tipo de Azure Databricks desea orquestar.
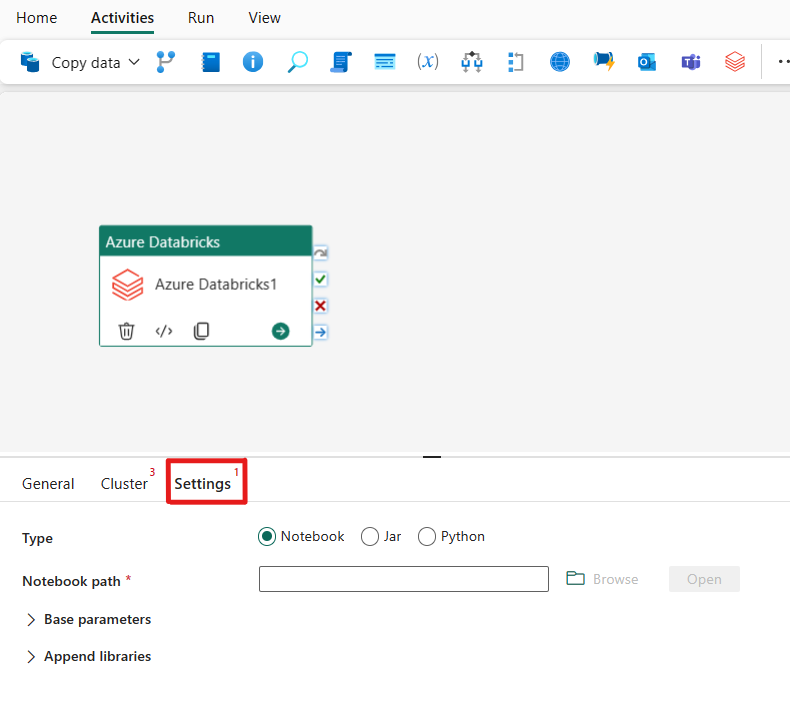
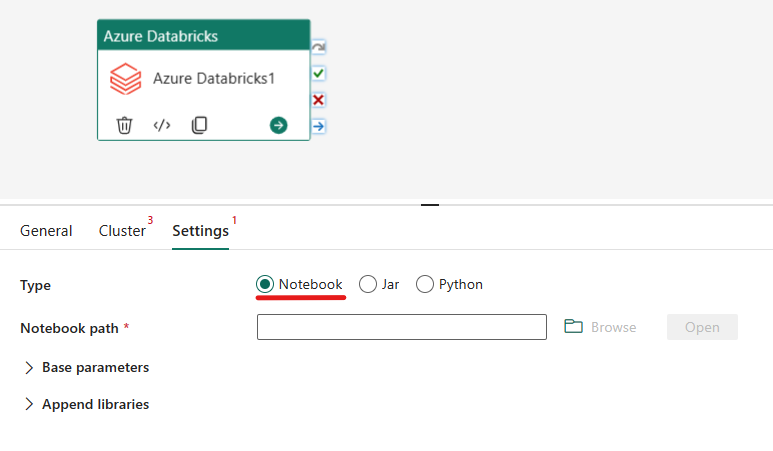
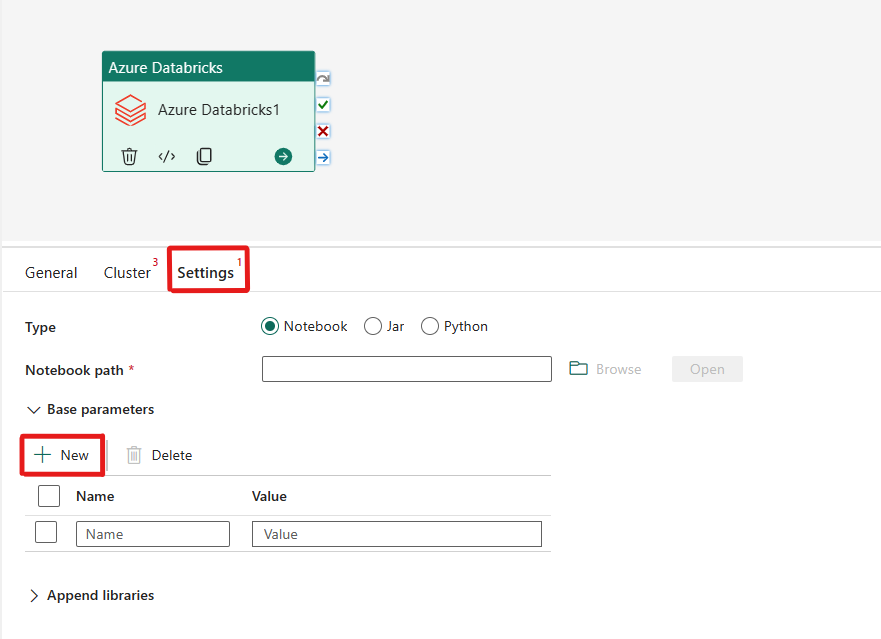
Orquestación del tipo de Notebook en la actividad de Azure Databricks:
En la pestaña Configuración, puede elegir el botón de radio Notebook para ejecutar un cuaderno. Deberá especificar la ruta del cuaderno que se ejecutará en Azure Databricks, los parámetros base opcionales que se pasarán al cuaderno, y cualquier biblioteca adicional que deba instalarse en el clúster para ejecutar el trabajo.
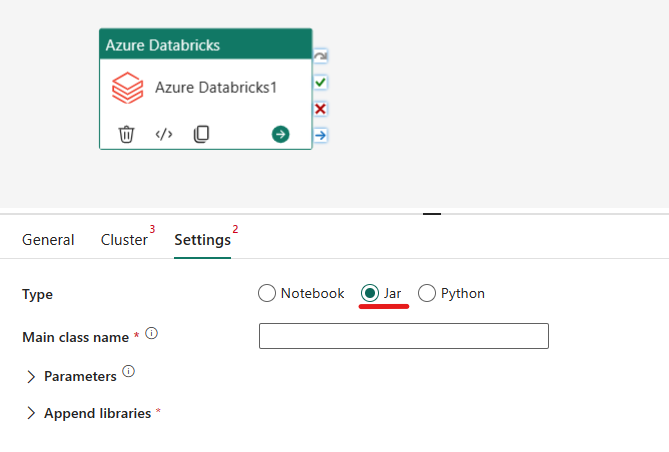
Orquestación del tipo Jar en la actividad de Azure Databricks:
En la pestaña Configuración, puede elegir el botón de radio Jar para ejecutar un archivo Jar. Deberá especificar el nombre de clase que se va a ejecutar en Azure Databricks, los parámetros base opcionales que se van a pasar al archivo Jar y las bibliotecas adicionales que se van a instalar en el clúster para ejecutar el trabajo.
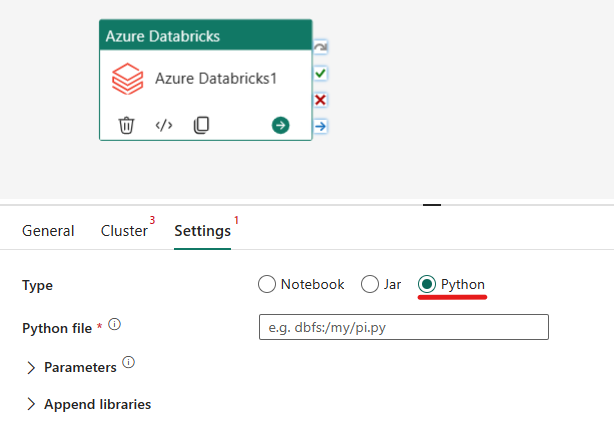
Orquestación del tipo de Python en la actividad de Azure Databricks:
En la pestaña Configuración, puede elegir el botón de radioPython para ejecutar un archivo de Python. Deberá especificar la ruta dentro de Azure Databricks a un archivo Python que se va a ejecutar, lolos parámetros base opcionales que se pasarán y cualquier biblioteca adicional que deba instalarse en el clúster para ejecutar el trabajo.
Bibliotecas admitidas para la actividad de Azure Databricks
En la definición de actividad de Databricks anterior, puede especificar estos tipos de biblioteca: jar, egg, whl, maven, pypi, cran.
Para más información, consulte la documentación de Databricks sobre los tipos de bibliotecas.
Paso de parámetros entre la actividad y las canalizaciones de Azure Databricks
Puede pasar parámetros a cuadernos mediante la propiedad baseParameters que se encuentra en la actividad de Databricks.
En ciertos casos, es posible que necesite devolver algunos valores del cuaderno al servicio, ya que se pueden usar en el flujo de control (esto es, para realizar comprobaciones condicionales) del servicio; también se pueden consumir mediante actividades de bajada (el límite de tamaño es de 2 MB).
En el cuaderno, por ejemplo, puede llamar a dbutils.notebook.exit("returnValue") y se devolverá "returnValue" correspondiente al servicio.
Puede usar la salida del servicio mediante una expresión como
@{activity('databricks activity name').output.runOutput}.
Guardar y ejecutar o programar la canalización
Después de configurar las demás actividades necesarias para la canalización, cambie a la pestaña Inicio en la parte superior del editor de canalizaciones y seleccione el botón Guardar para guardar la canalización. Seleccione Ejecutar para ejecutarlo directamente o Planificar para programarlo. También puede ver el historial de ejecución aquí o configurar otras opciones.
