Migración de metadatos del metastore de Hive desde Azure Synapse Analytics a Fabric
El paso inicial de la migración del metastore de Hive (HMS) implica determinar las bases de datos, las tablas y las particiones que desea transferir. No es necesario migrar todo, puede seleccionar bases de datos específicas. Al identificar las bases de datos para la migración, asegúrese de comprobar si hay tablas de Spark administradas o externas.
Para conocer las consideraciones sobre HMS, consulte las diferencias entre Spark de Azure Synapse y Fabric.
Nota:
Como alternativa, si su instancia de ADLS Gen2 contiene tablas Delta, puede crear un acceso directo de OneLake a una tabla Delta en ADLS Gen2.
Requisitos previos
- Si aún no tiene una, cree una área de trabajo de Fabric en el inquilino.
- Si aún no tiene uno, cree un almacén de lago de Fabric en el área de trabajo.
Opción 1: Exportación e importación del HMS al metastore del almacén de lago
Siga estos pasos clave para la migración:
- Paso 1: Exportación de metadatos desde el HMS de origen
- Paso 2: Importación de los metadatos en el almacén de lago de Fabric
- Pasos posteriores a la migración: validación del contenido
Nota:
Los scripts solo copian los objetos del catálogo de Spark en el almacén de lago de Fabric. Se da por supuesto que los datos ya se han copiado (por ejemplo, desde la ubicación de almacenamiento a ADLS Gen2) o están disponibles para tablas administradas y externas (por ejemplo, mediante métodos abreviados o preferidos) en el almacén de lago de Fabric.
Paso 1: Exportación de metadatos desde el HMS de origen
El objetivo del paso 1 es exportar los metadatos del HMS de origen a la sección Archivos del almacén de lago de Fabric. El proceso es el siguiente:
1.1) Importe el cuaderno de exportación de metadatos del HMS en el área de trabajo de Azure Synapse. Este cuaderno consultas y exporta los metadatos del HMS de bases de datos, tablas y particiones a un directorio intermedio en OneLake (las funciones aún no están incluidas). La API interna del catálogo de Spark se usa en este script para leer los objetos del catálogo.
1.2) Configure los parámetros en el primer comando para exportar la información de metadatos a un almacenamiento intermedio (OneLake). El siguiente fragmento de código se usa para configurar los parámetros de origen y de destino. Asegúrese de reemplazarlos por sus propios valores.
// Azure Synapse workspace config var SynapseWorkspaceName = "<synapse_workspace_name>" var DatabaseNames = "<db1_name>;<db2_name>" var SkipExportTablesWithUnrecognizedType:Boolean = false // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/"1.3) Ejecute todos los comandos del cuaderno para exportar los objetos del catálogo a OneLake. Una vez completadas las celdas, se crea esta estructura de carpetas en el directorio de salida intermedio.
Paso 2: Importación de los metadatos en el almacén de lago de Fabric
En el paso 2, los metadatos reales se importan desde el almacenamiento intermedio al almacén de lago de Fabric. La salida de este paso es migrar todos los metadatos del HMS (bases de datos, tablas y particiones). El proceso es el siguiente:
2.1) Cree un acceso directo en la sección "Archivos" del almacén de lago. Este acceso directo debe apuntar al directorio de almacenamiento de Spark de origen y se usa más adelante para realizar el reemplazo de las tablas administradas de Spark. Consulte ejemplos de accesos directos que apuntan al directorio de almacenamiento de Spark:
- Ruta de acceso directo al directorio de almacenamiento de Spark de Azure Synapse:
abfss://<container>@<storage_name>.dfs.core.windows.net/synapse/workspaces/<workspace_name>/warehouse - Ruta de acceso directo al directorio de almacenamiento de Azure Databricks:
dbfs:/mnt/<warehouse_dir> - Ruta de acceso directo al directorio de almacenamiento de Spark de HDInsight:
abfss://<container>@<storage_name>.dfs.core.windows.net/apps/spark/warehouse
- Ruta de acceso directo al directorio de almacenamiento de Spark de Azure Synapse:
2.2) Importe el cuaderno de importación de metadatos del HMS en el área de trabajo de Fabric. Importe este cuaderno para importar los objetos de bases de datos, tablas y particiones desde el almacenamiento intermedio. La API interna del catálogo de Spark se usa en este script para crear los objetos del catálogo en Fabric.
2.3) Configure los parámetros en el primer comando. En Apache Spark, al crear una tabla administrada, los datos de esa tabla se almacenan en una ubicación administrada por el propio Spark, normalmente dentro del directorio de almacenamiento de Spark. Spark determina la ubicación exacta. Esto contrasta con las tablas externas, donde se especifica la ubicación y se administran los datos subyacentes. Al migrar los metadatos de una tabla administrada (sin mover los datos reales), los metadatos todavía contienen la información de la ubicación original, que apunta al directorio de almacenamiento de Spark anterior. Por lo tanto, para las tablas administradas, se usa
WarehouseMappingspara realizar el reemplazo mediante el acceso directo creado en el paso 2.1. Todas las tablas administradas de origen se convierten como tablas externas mediante este script.LakehouseIdhace referencia al almacén de lago creado en el paso 2.1 que contiene los accesos directos.// Azure Synapse workspace config var ContainerName = "<container_name>" var StorageName = "<storage_name>" var SynapseWorkspaceName = "<synapse_workspace_name>" // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var ShortcutName = "<warehouse_dir_shortcut_name>" var WarehouseMappings:Map[String, String] = Map( f"abfss://${ContainerName}@${StorageName}.dfs.core.windows.net/synapse/workspaces/${SynapseWorkspaceName}/warehouse"-> f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ShortcutName}" ) var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/" var DatabasePrefix = "" var TablePrefix = "" var IgnoreIfExists = true2.4) Ejecute todos los comandos del cuaderno para importar los objetos del catálogo desde la ruta de acceso intermedia.
Nota:
Al importar varias bases de datos, puede (i) crear un almacén de lago por cada base de datos (el enfoque que se usa aquí) o (ii) mover todas las tablas de bases de datos diferentes a un único almacén de lago. En este último caso, todas las tablas migradas podrían ser <lakehouse>.<db_name>_<table_name> y tendrá que ajustar el cuaderno de importación en consecuencia.
Paso 3: Validación del contenido
En el paso 3, se valida que los metadatos se hayan migrado correctamente. Consulte los diferentes ejemplos.
Puede ver las bases de datos importadas mediante la ejecución de:
%%sql
SHOW DATABASES
Puede comprobar todas las tablas de un almacén de lago (base de datos) mediante la ejecución de:
%%sql
SHOW TABLES IN <lakehouse_name>
Para ver los detalles de una tabla determinada, ejecute:
%%sql
DESCRIBE EXTENDED <lakehouse_name>.<table_name>
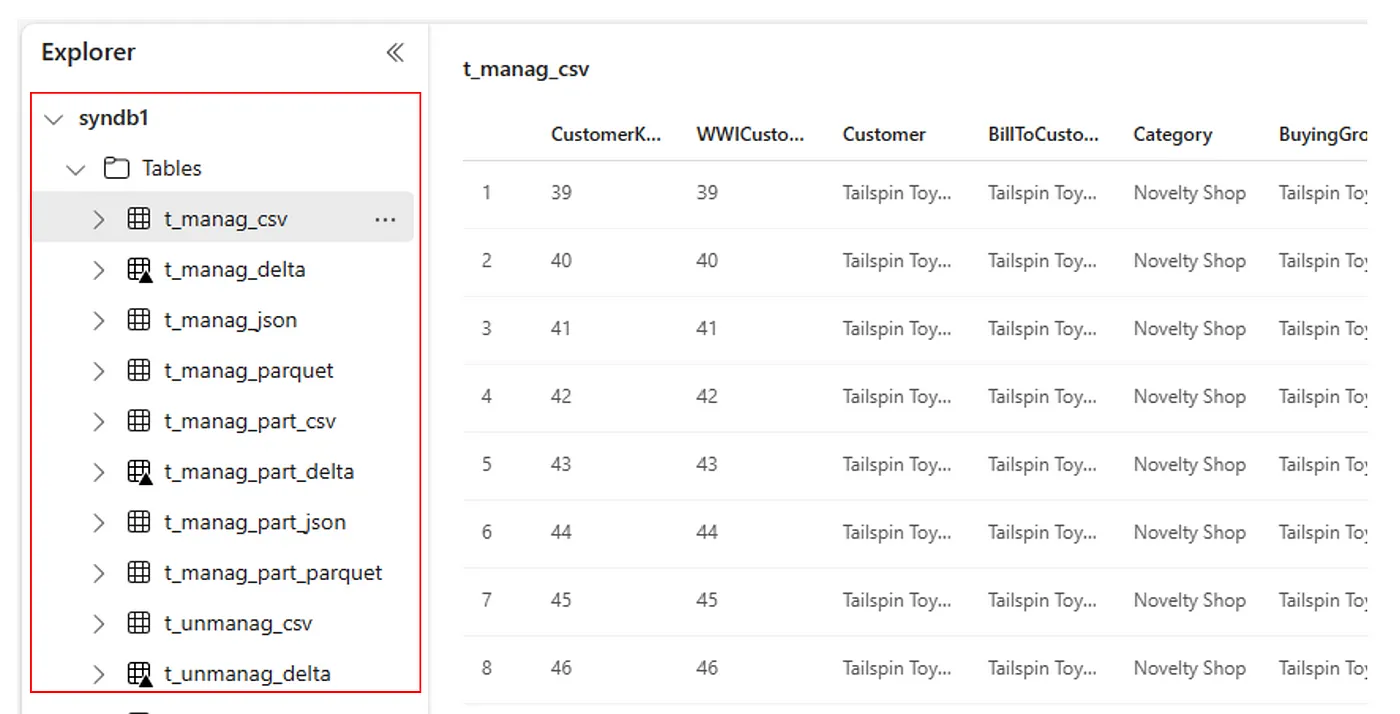
Como alternativa, todas las tablas importadas están visibles en la sección Tablas de la interfaz de usuario del Explorador del almacén de lago para cada almacén de lago.
Otras consideraciones
- Escalabilidad: la solución usa aquí la API interna del catálogo de Spark para realizar la importación y exportación, pero no se conecta directamente al HMS para obtener los objetos del catálogo, por lo que la solución no se puede escalar bien si el catálogo es grande. Tendría que cambiar la lógica de exportación mediante la base de datos del HMS.
- Precisión de los datos: no hay ninguna garantía de aislamiento, lo que significa que si el motor de proceso de Spark está realizando modificaciones simultáneas en el metastore mientras se ejecuta el cuaderno de migración, se pueden introducir datos incoherentes en el almacén de lago de Fabric.
Contenido relacionado
- Fabric frente a Spark de Azure Synapse
- Obtenga más información sobre las opciones de migración de los grupos de Spark, las configuraciones, las bibliotecas, los cuadernos y la definición de trabajos de Spark.