Administración de bibliotecas de Apache Spark en Microsoft Fabric
Una biblioteca es una colección de código previamente escrito que los desarrolladores pueden importar para proporcionar funcionalidad. El uso de bibliotecas permite ahorrar tiempo y esfuerzo al no tener que escribir código desde cero para realizar tareas comunes. En su lugar, se importa la biblioteca y se utilizan sus funciones y clases para conseguir la funcionalidad deseada. Microsoft Fabric proporciona múltiples mecanismos para ayudarle a administrar y usar bibliotecas.
- Bibliotecas integradas: cada entorno de ejecución de Fabric Spark proporciona un amplio conjunto de bibliotecas preinstaladas populares. Encontrará la lista completa de bibliotecas integradas en Fabric Spark Runtime.
- Bibliotecas públicas: las bibliotecas públicas se obtienen de repositorios como PyPI o Conda, que se admiten actualmente.
- Bibliotecas personalizadas: las bibliotecas personalizadas se refieren al código que usted o su organización crean. Fabric admite los formatos .whl, .jar, and .tar.gz. Fabric solo admite archivos .tar.gz para el lenguaje R. Para las bibliotecas personalizadas de Python, use el formato .whl.
Resumen de los procedimientos recomendados de administración de bibliotecas
En los escenarios siguientes se describen los procedimientos recomendados al usar bibliotecas en Microsoft Fabric.
Escenario 1: el administrador establece bibliotecas predeterminadas para el área de trabajo
Para establecer bibliotecas predeterminadas, debe ser el administrador del área de trabajo. Como administrador, puede realizar estas tareas:
- Crear un nuevo entorno
- Instalar las bibliotecas necesarias en el entorno
- Adjuntar este entorno como área de trabajo predeterminada
Cuando los cuadernos y las definiciones de trabajo de Spark se adjuntan a la Configuración del área de trabajo, inician sesiones con las bibliotecas instaladas en el entorno predeterminado del área de trabajo.
Escenario 2: conservar especificaciones de biblioteca para uno o varios elementos de código
Si tiene bibliotecas comunes para distintos elementos de código y no requiere actualizaciones frecuentes, instalar las bibliotecas en un entorno y adjuntarlo a los elementos de código es una buena opción.
Se tardará algún tiempo en hacer que las bibliotecas en entornos sean eficaces al publicar. Normalmente tarda entre 5 y 15 minutos, en función de la complejidad de las bibliotecas. Durante este proceso, el sistema ayudará a resolver los posibles conflictos y descargar las dependencias necesarias.
Una ventaja de este enfoque es que se garantiza que las bibliotecas instaladas correctamente estén disponibles cuando se inicia la sesión de Spark con el entorno asociado. Ahorra esfuerzo para mantener bibliotecas comunes para los proyectos.
Se recomienda encarecidamente para escenarios de canalización con su estabilidad.
Escenario 3: instalación en línea en ejecución interactiva
Si usa los cuadernos para escribir código de forma interactiva, lo más recomendable es usar la instalación en línea para agregar nuevas librerías PyPI o conda o validar sus librerías personalizadas para un único uso. Los comandos en línea en Fabric le permiten hacer efectiva la biblioteca en la sesión Spark del cuaderno actual. Permite la instalación rápida, pero la biblioteca instalada no se conserva en distintas sesiones.
Dado que %pip install genera árboles de dependencias diferentes cada cierto tiempo, lo que puede provocar conflictos de biblioteca, los comandos insertados se desactivan de manera predeterminada en las ejecuciones de canalización y NO se recomienda usar en las canalizaciones.
Resumen de los tipos de biblioteca admitidos
| Tipo de biblioteca | Administración de bibliotecas de entorno | Instalación en línea |
|---|---|---|
| Python público (PyPI y Conda) | Compatible | Compatible |
| Python personalizado (.whl) | Compatible | Compatible |
| R público (CRAN) | No compatible | Compatible |
| R personalizado (.tar.gz) | Se admite como biblioteca personalizada | Compatible |
| Jar | Se admite como biblioteca personalizada | Compatible |
Instalación en línea
Los comandos insertados admiten la administración de bibliotecas en cada sesión de cuaderno.
Instalación en línea de Python
El sistema reinicia el intérprete de Python para aplicar el cambio de bibliotecas. Cualquier variable definida antes de ejecutar la celda de comandos se pierde. Se recomienda encarecidamente colocar todos los comandos para agregar, eliminar o actualizar paquetes de Python al principio del cuaderno.
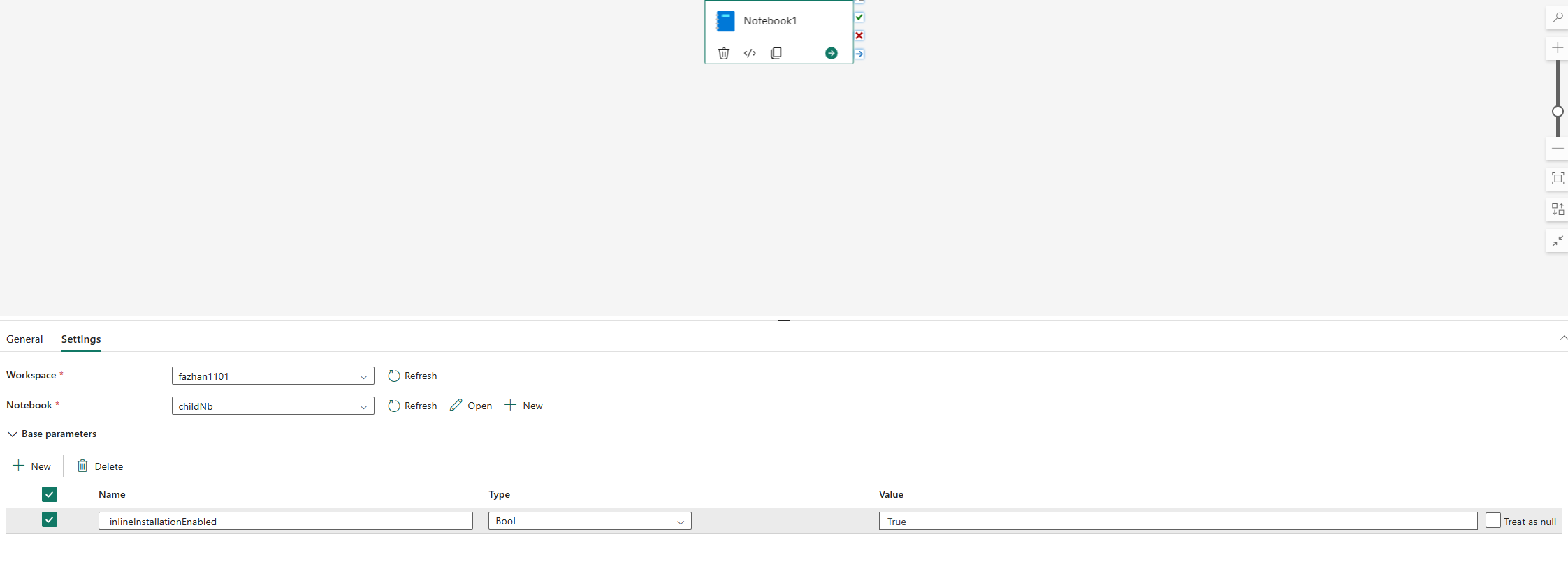
Los comandos insertados para administrar bibliotecas de Python están deshabilitados de forma predeterminada en la ejecución de canalización de cuadernos. Si deseas habilitar %pip install para la canalización, agrega «_inlineInstallationEnabled» como un parámetro booleano que equivale a True en los parámetros de actividad del cuaderno.
Nota:
%pip install puede dar lugar a resultados incoherentes de vez en cuando. Se recomienda instalar la biblioteca en un entorno y usarla en la canalización.
En las ejecuciones de referencia de cuadernos, no se admiten comandos insertados para administrar bibliotecas de Python. Para garantizar la corrección de la ejecución, se recomienda quitar estos comandos insertados del cuaderno al que se hace referencia.
Se recomienda %pip en lugar de !pip. !pip es un comando de shell integrado de IPython que tiene las siguientes limitaciones:
!pipsolo instala un paquete en el nodo controlador, no en los nodos ejecutores.- Los paquetes que se instalan a través de
!pipno afectan a los conflictos con paquetes incorporados o si los paquetes ya están importados en un cuaderno.
Sin embargo, %pip controla estos escenarios. Las bibliotecas instaladas a través de %pip están disponibles tanto en el nodo controlador como en el nodo ejecutor y siguen siendo efectivas incluso si la biblioteca ya está importada.
Sugerencia
El comando %conda install suele tardar más que el comando %pip install en instalar nuevas bibliotecas Python. Verifica todas las dependencias y resuelve los conflictos.
Puede que quiera usar %conda install para mayor fiabilidad y estabilidad. Puede usar %pip install si está seguro de que la biblioteca que desea instalar no entra en conflicto con las bibliotecas preinstaladas en el entorno de tiempo de ejecución.
Para todos los comandos en línea de Python disponibles y aclaraciones, consulte comandos %pip y comandos %conda.
Administración de bibliotecas públicas de Python mediante la instalación en línea
En este ejemplo, se muestra cómo usar comandos en línea para administrar bibliotecas. Supongamos que quiere usar altair, una biblioteca de visualización eficaz para Python, para una exploración de datos única. Supongamos que la biblioteca no está instalada en el área de trabajo. El siguiente ejemplo usa comandos conda para ilustrar los pasos.
Puede usar comandos en línea para habilitar altair en la sesión del cuaderno sin afectar a otras sesiones del cuaderno u otros elementos.
Ejecute los siguientes comandos en una celda de código del cuaderno. El primer comando instala la biblioteca altair. Además, instala vega_datasets, que contiene un modelo semántico que se puede usar para visualizar.
%conda install altair # install latest version through conda command %conda install vega_datasets # install latest version through conda commandLa salida de la celda indica el resultado de la instalación.
Importa el paquete y el modelo semántico ejecutando el siguiente código en otra celda del cuaderno.
import altair as alt from vega_datasets import dataAhora puede usar la biblioteca altair con ámbito de sesión.
# load a simple dataset as a pandas DataFrame cars = data.cars() alt.Chart(cars).mark_point().encode( x='Horsepower', y='Miles_per_Gallon', color='Origin', ).interactive()
Administración de bibliotecas personalizadas de Python mediante la instalación en línea
Puede cargar sus bibliotecas personalizadas de Python en la carpeta de recursos de su bloc de notas o en el entorno adjunto. Las carpetas de recursos son el sistema de archivos integrado proporcionado por cada cuaderno y entorno. Consulte Recursos de Notebook para obtener más detalles. Después de la carga, puede arrastrar y colocar la biblioteca personalizada en una celda de código, el comando insertado para instalar la biblioteca se genera automáticamente. O bien, puede usar el siguiente comando para instalar.
# install the .whl through pip command from the notebook built-in folder
%pip install "builtin/wheel_file_name.whl"
Instalación en línea de R
Para administrar bibliotecas R, Fabric admite los comandos install.packages(), remove.packages() y devtools::. Para todos los comandos R en línea disponibles y aclaraciones, consulte el comando install. packages y el comando remove.package.
Administración de bibliotecas públicas de R a través de la instalación en línea
Siga este ejemplo para recorrer los pasos de instalación de una biblioteca pública de R.
Para instalar una biblioteca de fuentes de R:
Cambie el lenguaje de trabajo a SparkR (R) en la cinta de opciones del cuaderno.
Instale la biblioteca caesar ejecutando el comando siguiente en una celda del cuaderno.
install.packages("caesar")Ahora puede experimentar con la biblioteca de caesar con ámbito de sesión con un trabajo de Spark.
library(SparkR) sparkR.session() hello <- function(x) { library(caesar) caesar(x) } spark.lapply(c("hello world", "good morning", "good evening"), hello)
Administración de bibliotecas Jar a través de la instalación en línea
Los archivos .jar son compatibles con las sesiones del cuaderno con el siguiente comando.
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<Lakehouse prefix>>.dfs.fabric.microsoft.com/<<path to JAR file>>/<<JAR file name>>.jar",
}
}
La celda de código usa el almacenamiento de Lakehouse como ejemplo. En el explorador de cuaderno, puede copiar el archivo completo ABFS ruta y reemplazar en el código.
