Creación de grupos de Spark personalizados en Microsoft Fabric
En este documento, se explica cómo crear grupos de Apache Spark personalizados en Microsoft Fabric para las cargas de trabajo de análisis. Los grupos de Apache Spark permiten a los usuarios crear entornos de proceso personalizados en función de sus requisitos específicos, lo que garantiza un rendimiento y un uso óptimo de los recursos.
Especifique los nodos mínimo y máximo para el escalado automático. En función de esos valores, el sistema adquiere y retira dinámicamente los nodos a medida que cambian los requisitos de proceso del trabajo, lo que da como resultado un escalado eficaz y un rendimiento mejorado. La asignación dinámica de ejecutores en grupos de Spark también reduce la necesidad de configuración manual del ejecutor. En su lugar, el sistema ajusta el número de ejecutores en función del volumen de datos y las necesidades de proceso de nivel de trabajo. Este proceso le permite centrarse en las cargas de trabajo sin preocuparse por la optimización del rendimiento y la administración de recursos.
Nota:
Para crear un grupo de Spark personalizado, necesita acceso de administrador al área de trabajo. El administrador de capacidad debe habilitar la opción Grupos de áreas de trabajo personalizadas en la sección Proceso de Spark de la configuración de Capacidad Administración. Para más información, vea Configuración de proceso de Spark para capacidades de Fabric.
Creación de grupos de Spark personalizados
Para crear o administrar el grupo de Spark asociado al área de trabajo:
Vaya al área de trabajo y seleccione Configuración del área de trabajo.
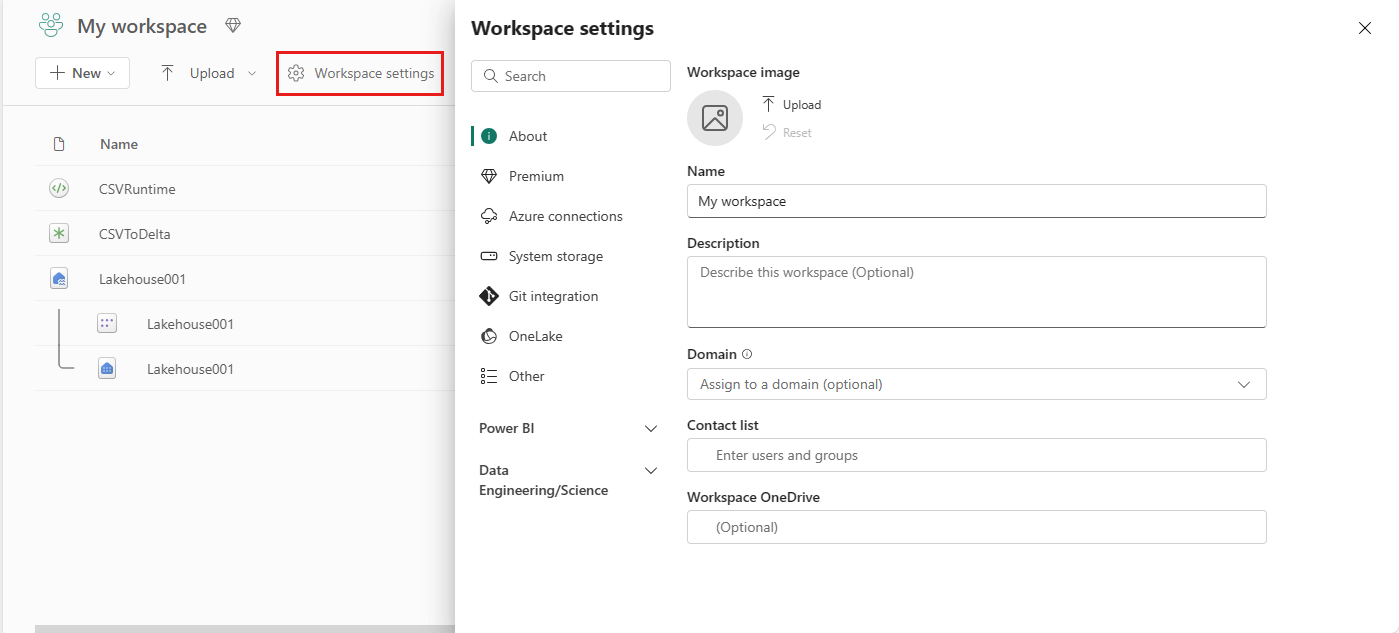
Seleccione la opción ingeniería/Ciencia de datos para expandir el menú y, luego, seleccione Spark Compute.

Seleccione la opción Nuevo grupo . En la pantalla Crear grupo, asigne un nombre al grupo de Spark. También elija la familia de nodos y seleccione un tamaño de nodo de entre los tamaños disponibles (Pequeño, Mediano, Grande, Más grande y Extra grande) en función de los requisitos de proceso de tus cargas de trabajo.
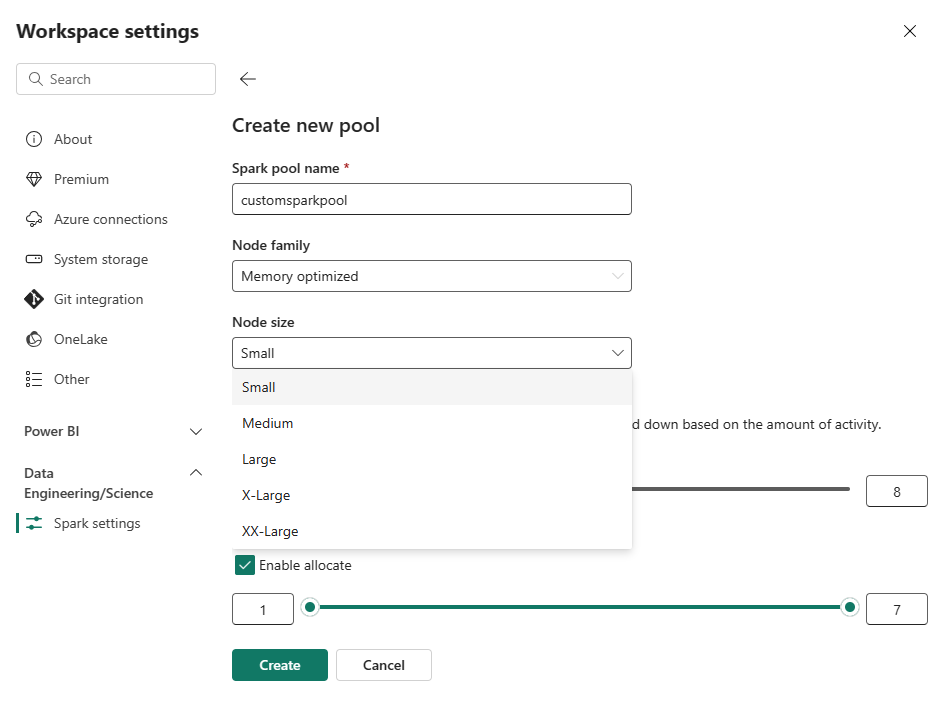
Puedes establecer la configuración mínima de nodo para los grupos personalizados en 1. Dado que Fabric Spark proporciona disponibilidad restaurable para clústeres con un solo nodo, no tiene que preocuparse por los errores de trabajo, la pérdida de sesión durante los errores o el pago por encima del proceso para trabajos de Spark más pequeños.
Puede habilitar o deshabilitar el escalado automático para los grupos de Spark personalizados. Cuando se habilita el escalado automático, el grupo adquirirá dinámicamente nuevos nodos hasta el límite máximo de nodos especificado por el usuario y, a continuación, los retirará después de la ejecución del trabajo. Esta característica garantiza un mejor rendimiento ajustando los recursos en función de los requisitos del trabajo. Puede ajustar el tamaño de los nodos, que se ajustan a las unidades de capacidad adquiridas como parte de la SKU de capacidad de Fabric.
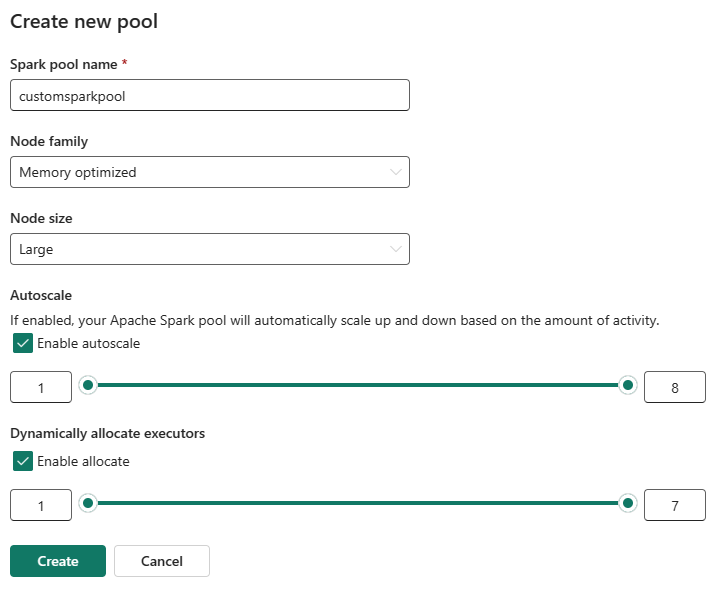
También puede optar por habilitar la asignación dinámica del ejecutor para el grupo de Spark, que determina automáticamente el número óptimo de ejecutores dentro del límite máximo especificado por el usuario. Esta característica ajusta el número de ejecutores en función del volumen de datos, lo que mejora el rendimiento y el uso de los recursos.

Estos grupos personalizados tienen una duración de pausa automática predeterminada de 2 minutos. Una vez alcanzada la duración de la pausa automática, la sesión expira y los clústeres no se asignan. Se le cobrará en función del número de nodos y la duración durante la que se usan los grupos de Spark personalizados.
Contenido relacionado
- Obtenga más información en la documentación pública de Apache Spark.
- Introducción a la configuración de administración del área de trabajo de Spark en Microsoft Fabric.