Uso del servidor de historial de Apache Spark extendido para depurar y diagnosticar aplicaciones Spark
En este artículo se proporcionan instrucciones sobre cómo usar el servidor de historial de Apache Spark para depurar y diagnosticar las aplicaciones Apache Spark en ejecución y completadas.
Acceso al servidor de historial de Apache Spark
El servidor de historial de Apache Spark es la interfaz de usuario web para aplicaciones Spark completadas y en ejecución. Puede abrir la interfaz de usuario web de Apache Spark (UI) desde el cuaderno del indicador de progreso o la página de detalles de la aplicación Apache Spark.
Abrir la interfaz de usuario web de Spark desde el cuaderno indicador de progreso
Cuando se activa un trabajo de Apache Spark, el botón para abrir Spark web UI se encuentra dentro de la opción Más acciones del indicador de progreso. Seleccione Spark web UI y espere unos segundos, entonces aparecerá la página Spark UI.

Abrir la interfaz web de Spark desde la página de detalles de la aplicación Apache Spark
La interfaz web de Spark también puede abrirse a través de la página de detalles de la aplicación Apache Spark. Seleccione Centro de supervisión en la parte izquierda de la página y, a continuación, seleccione una aplicación Apache Spark. Aparecerá la página de detalles de la aplicación.

Para una aplicación Apache Spark cuyo estado es en ejecución, el botón muestra Interfaz de usuario de Spark. Seleccione Interfaz de usuario de Spark y aparecerá la página Interfaz de usuario de Spark.

Para una aplicación Apache Spark cuyo estado es finalizado, el estado finalizado puede ser Detenido, Erróneo, Cancelado, o Completado. El botón muestra Servidor de historial de Spark. Seleccione Servidor de historial de Spark y aparecerá la página de Interfaz de usuario de Spark.

Pestaña Gráfico en el servidor de historial de Apache Spark
Seleccione el id. del trabajo que quiere ver. Después, seleccione Gráfico en el menú de herramientas para obtener la vista de gráfico del trabajo.
Información general
Puede ver la información general del trabajo en el gráfico generado. De forma predeterminada, el gráfico muestra todos los trabajos. Puede filtrar esta vista por Id. de trabajo.

Pantalla
De forma predeterminada, está seleccionada la opción para mostrar Progreso. Puede comprobar el flujo de datos; para ello, seleccione Read (Leído) o Written (Escrito) en la lista desplegable Mostrar.

El nodo de gráfico muestra los colores descritos en la leyenda del mapa térmico.

Reproducción
Para reproducir el trabajo, seleccione Reproducir. Puede seleccionar Detener en cualquier momento para detener el proceso. Los colores de las tareas muestran distintos estados durante la reproducción:
| Color | Significado |
|---|---|
| Verde | Correcto: el trabajo se ha completado correctamente. |
| Naranja | Reintentadas: Instancias de tareas que no funcionaron pero que no afectan al resultado final del trabajo. Estas tareas tenían instancias duplicadas o de reintentos que pueden realizarse correctamente más tarde. |
| Azul | En ejecución: la tarea se está ejecutando. |
| Blanco | En espera u omitido: la tarea está esperando para ejecutarse o la fase se ha omitido. |
| Rojo | Con errores: error en la tarea. |
La siguiente imagen muestra los colores de estado verde, naranja y azul.

La siguiente imagen muestra los colores de estado verde y blanco.

La siguiente imagen muestra los colores de estado rojo y verde.

Nota:
El servidor de historial de Apache Spark permite la reproducción de cada trabajo completado (pero no permite la reproducción de trabajos incompletos).
Zoom
Use la rueda del mouse para acercar y alejar el gráfico del trabajo o seleccione Ajustar al tamaño para ajustarlo a la pantalla.

Información sobre herramientas
Mantenga el mouse sobre el nodo del gráfico para ver la información sobre herramientas cuando haya tareas con errores y seleccione una fase para abrir su página.

En la pestaña del gráfico de trabajo, las fases tienen información sobre herramientas y se muestra un icono pequeño si tienen tareas que cumplen las siguientes condiciones:
| Condición | Descripción |
|---|---|
| Asimetría de datos | Tamaño de lectura de datos > tamaño medio de lectura de datos de todas las tareas dentro de esta etapa * 2 y tamaño de lectura de datos > 10 MB. |
| Desfase horario | Tiempo de ejecución > tiempo medio de ejecución de todas las tareas de esta fase * 2 y tiempo de ejecución > 2 minutos. |
![]()
Descripción del nodo de gráfico
El nodo de gráfico de trabajo muestra la siguiente información de cada fase:
- ID
- Nombre o descripción
- Número total de tareas
- Datos leídos: suma del tamaño de entrada y el tamaño de lectura aleatorio
- Escritura de datos: la suma del tamaño de salida y el tamaño de las escrituras aleatorias
- Tiempo de ejecución: tiempo entre la hora de inicio del primer intento y la hora de finalización del último intento
- Recuento de filas: la suma de registros de entrada, registros de salida, registros de lectura aleatoria y registros de escritura aleatoria.
- Progreso
Nota:
De forma predeterminada, el nodo del gráfico del trabajo muestra la información del último intento de cada fase (excepto en el tiempo de ejecución de la fase). Sin embargo, durante la reproducción, el nodo del gráfico muestra la información de cada intento.
El tamaño de los datos de lectura y escritura es 1MB = 1000 KB = 1000 * 1000 bytes.
Envío de comentarios
Seleccione Proporcione sus comentarios para enviar comentarios sobre incidencias.

Límite de números de fase
Por motivos de rendimiento, de forma predeterminada, el gráfico solo está disponible cuando la aplicación Spark tiene menos de 500 fases. Si hay demasiadas fases, se producirá un error similar al siguiente:
The number of stages in this application exceeds limit (500), graph page is disabled in this case.
Como solución alternativa, antes de iniciar una aplicación Spark, aplique esta configuración de Spark para aumentar el límite:
spark.ui.enhancement.maxGraphStages 1000
Sin embargo, tenga en cuenta que esto puede provocar un rendimiento deficiente de la página y la API, ya que el contenido puede ser demasiado grande para que el explorador pueda capturar y representar.
Examen de la pestaña Diagnóstico en el servidor de historial de Apache Spark
Para acceder a la pestaña Diagnóstico, seleccione un Id. de trabajo. Después, seleccione Diagnóstico en el menú de herramientas para obtener la vista Diagnóstico del trabajo. La pestaña de diagnóstico incluye Asimetría de datos, Desfase horario y Análisis de uso del ejecutor.
Para comprobar la Asimetría de datos, el Desfase horario y el Análisis de uso del ejecutor, seleccione las pestañas respectivamente.

Asimetría de datos
Cuando seleccione la pestaña Asimetría de datos, se mostrarán las tareas con sesgos según los parámetros especificados.
Especificar parámetros: la primera sección muestra los parámetros que se usan para detectar la Asimetría de datos. La regla predeterminada es: los datos de tarea leídos son más de tres veces la media de los datos de tarea leídos, y los datos de tarea leídos son más de 10 MB. Si desea definir su propia regla para las tareas sesgadas, puede elegir los parámetros. Las secciones Skewed Stage (Fase sesgada) y Skew Chart (Gráfico de sesgo) se actualizarán en consecuencia.
Fase sesgada: la segunda sección muestra las etapas que tienen tareas sesgadas que cumplen los criterios especificados anteriormente. Si hay más de una tarea sesgada en una etapa, la tabla de etapas sesgadas sólo muestra la tarea más sesgada (por ejemplo, los datos más grandes para el sesgo de datos).
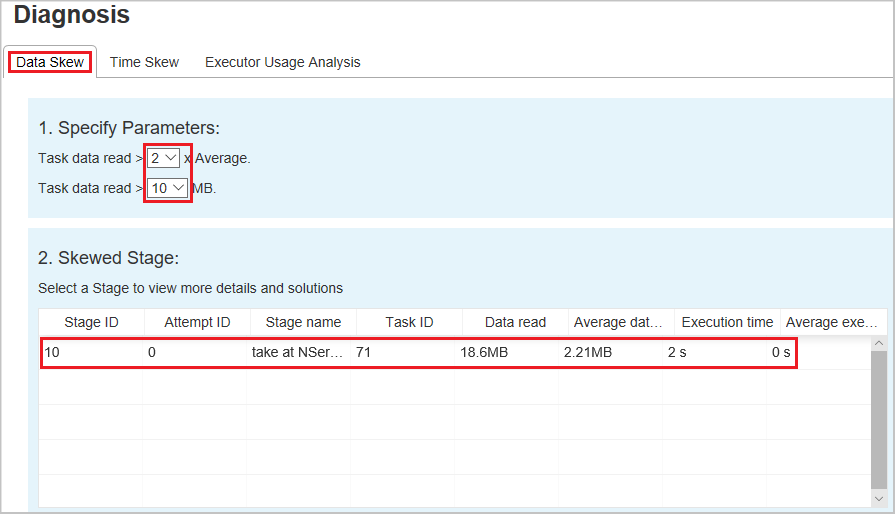
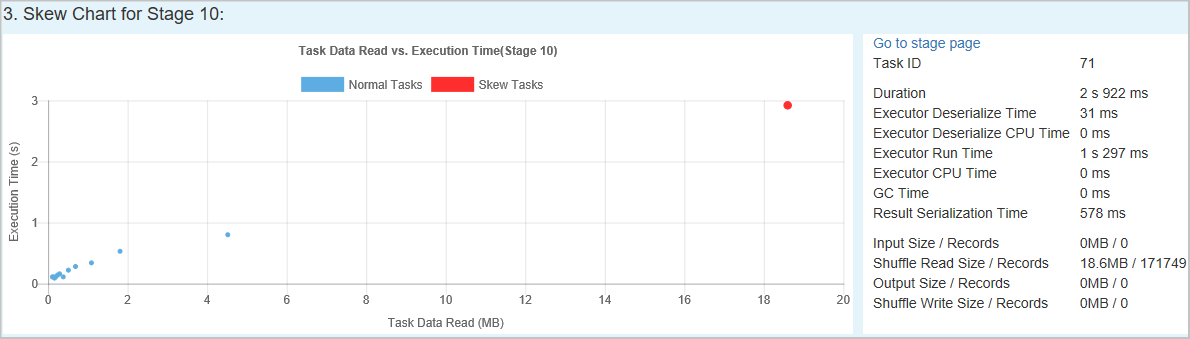
Gráfico de sesgo: cuando se selecciona una fila de la tabla de etapas de sesgo, el gráfico de sesgo muestra más detalles de la distribución de tareas en función de los datos leídos y el tiempo de ejecución. Las tareas sesgadas se marcan en rojo y las tareas normales se marcan en azul. El gráfico muestra hasta 100 tareas de ejemplo y los detalles de la tarea se muestran en el panel inferior derecho.


Desfase horario
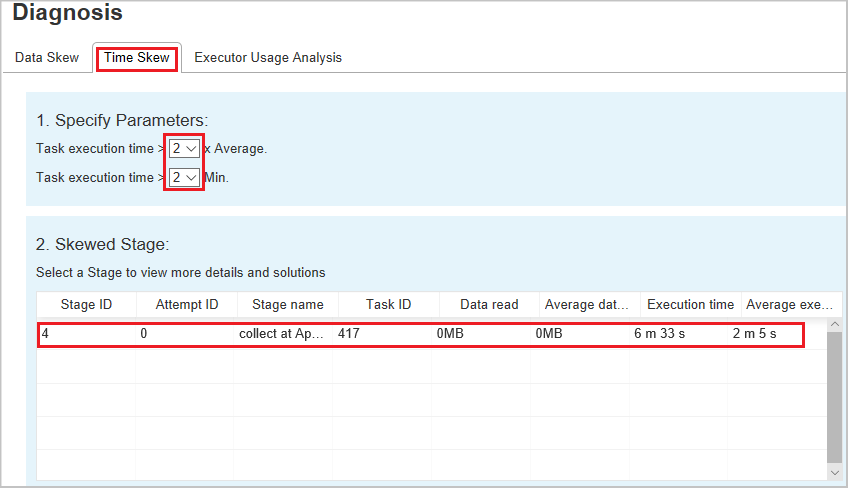
En la pestaña Desfase horario se muestran las tareas sesgadas en función del tiempo de ejecución de la tarea.
Especificar parámetros: la primera sección muestra los parámetros que se utilizan para detectar la inclinación del tiempo. Los criterios predeterminados para detectar el desfase horario son: el tiempo de ejecución de la tarea es mayor que tres veces el tiempo de ejecución promedio y el tiempo de ejecución de la tarea es superior a 30 segundos. Puede cambiar los parámetros en función de sus necesidades. Las secciones Fase sesgada y Gráfico sesgado muestran la información de las fases y tareas correspondientes, al igual que la pestaña Datos sesgados descrita anteriormente.
Seleccione Desfase horario y, después, se muestran los resultados filtrados en la sección Fase sesgada según los parámetros establecidos en la sección Especificar parámetros. Seleccione un elemento en la sección Fase sesgada, entonces el gráfico correspondiente se dibuja en la sección 3, y los detalles de la tarea se muestran en el panel inferior derecho.

Análisis de uso del ejecutor
Esta característica ha quedado en desuso en Fabric. Si todavía quiere usar esto como solución alternativa, acceda a la página agregando explícitamente "/executorusage" al final de la ruta de acceso "/diagnostic" en la dirección URL, de la siguiente manera:
