Sincronización de Microsoft Entra Connect: Descripción de la arquitectura
En este tema se describe la arquitectura básica de la sincronización de Microsoft Entra Connect. Si está familiarizado con las tecnologías de sincronización de identidades anteriores, el contenido de este tema también le resultará familiar. Si está comenzando con la sincronización, entonces este tema está a su nivel. De todos modos, no es requisito conocer los detalles de este tema para realizar personalizaciones correctas en la sincronización de Microsoft Entra Connect (llamado motor de sincronización en este tema).
Architecture
El motor de sincronización crea una vista integrada de objetos que están almacenados en varios orígenes de datos conectados y administra información de identidad en esos orígenes de datos. Esta vista integrada viene determinada por la información de identidad recuperada de orígenes de datos conectados y un conjunto de reglas que determinan cómo procesar esta información.
Orígenes de datos conectados y conectores
El motor de sincronización procesa la información de identidad procedente de diferentes repositorios de datos, como Active Directory o una base de datos de SQL Server. Todo repositorio de datos que organice los datos en un formato de base de datos y que proporcione métodos estándar de acceso a los datos es un origen de datos potencial para el motor de sincronización. Los repositorios de datos que se sincronizan mediante el motor de sincronización se denominan orígenes de datos conectados o directorios conectados (CD).
El motor de sincronización encapsula la interacción con un origen de datos conectado dentro de un módulo llamado conector. Cada tipo de origen de datos conectado posee un conector específico. El conector convierte una operación necesaria al formato que el origen de datos conectado comprende.
Los conectores hacen llamadas API para intercambiar información de identidad (tanto de lectura como de escritura) con un origen de datos conectado. También es posible agregar un conector personalizado mediante el marco de conectividad extensible. En la ilustración siguiente, se muestra cómo un conector conecta un origen de datos conectado al motor de sincronización.
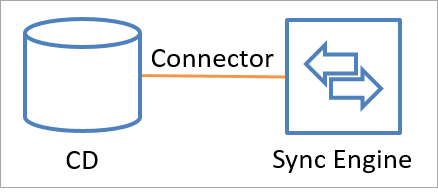
Los datos pueden fluir en ambas direcciones, pero no simultáneamente. Es decir, se puede configurar un conector para permitir que los datos fluyan desde el origen de datos conectado hacia el motor de sincronización o desde el motor de sincronización hacia el origen de datos conectado, pero solo se puede producir una de esas operaciones en un momento dado para un objeto y un atributo. La dirección puede ser diferente para distintos objetos y atributos.
Para configurar un conector, especifique los tipos de objeto que desea sincronizar. Al especificarse los tipos de objeto, se define el ámbito de los objetos que se incluyen en el proceso de sincronización. El siguiente paso consiste en seleccionar los atributos que se van a sincronizar, lo que se conoce como una lista de inclusión de atributos. Se puede cambiar esta configuración en cualquier momento como respuesta a los cambios en las reglas de negocio. Cuando usa el Asistente para instalación de Microsoft Entra Connect, estas opciones se configuran automáticamente.
Para exportar objetos a un origen de datos conectado, la lista de inclusión de atributos debe contener al menos los atributos mínimos necesarios para crear un tipo de objeto específico en un origen de datos conectado. Por ejemplo, el atributo sAMAccountName debe incorporarse a la lista de inclusión de atributos para exportar un objeto de usuario a Active Directory, ya que todos los objetos de usuario en Active Directory deben tener un atributo sAMAccountName definido. De nuevo, el asistente para la instalación realiza esta configuración.
Si el origen de datos conectado usa componentes estructurales, como particiones o contenedores para organizar objetos, puede limitar las áreas del origen de datos conectado que se usan para una solución dada.
Estructura interna del espacio de nombres del motor de sincronización
El espacio de nombres del motor de sincronización en total está formado por dos espacios de nombres que almacenan la información de identidad. Los dos espacios de nombres son:
- El espacio conector (CS)
- El metaverso (MV)
El espacio conector es un área de almacenamiento provisional que contiene representaciones de los objetos designados desde un origen de datos conectado y los atributos especificados en la lista de inclusión de atributos. El motor de sincronización usa el espacio conector para determinar qué ha cambiado en el origen de datos conectado y almacenar provisionalmente los cambios entrantes. Además, el motor de sincronización usa el espacio conector para almacenar de forma provisional los cambios salientes que se van a exportar al origen de datos conectado. El motor de sincronización mantiene un espacio conector distinto como área de almacenamiento provisional para cada conector.
Al usar un área de almacenamiento provisional, el motor de sincronización se mantiene independiente de los orígenes de datos conectados y no se ve afectado por la disponibilidad y la accesibilidad de estos. Como resultado, puede procesar la información de identidad en cualquier momento con los datos en el área de almacenamiento provisional. El motor de sincronización solo puede solicitar los cambios realizados dentro del origen de datos conectado desde que se cerró la última sesión de comunicación o solamente insertar los cambios de la información de identidad que el origen de datos conectado aún no haya recibido, lo que reduce el tráfico de red entre el motor de sincronización y el origen de datos conectado.
Además, el motor de sincronización almacena información de estado sobre todos los objetos que almacena provisionalmente en el espacio conector. Cuando se reciben nuevos datos, el motor de sincronización siempre evalúa si ya se han sincronizado.
El metaverso es un área de almacenamiento que contiene la información de identidad agregada de varios orígenes de datos conectados y proporciona una sola vista global integrada de todos los objetos combinados. Los objetos de metaverso se crean partiendo de la información de identidad que se recupera de los orígenes de datos conectados y un conjunto de reglas que le permiten personalizar el proceso de sincronización.
En la ilustración siguiente, se muestra el espacio de nombres del espacio conector y el del metaverso en el motor de sincronización.
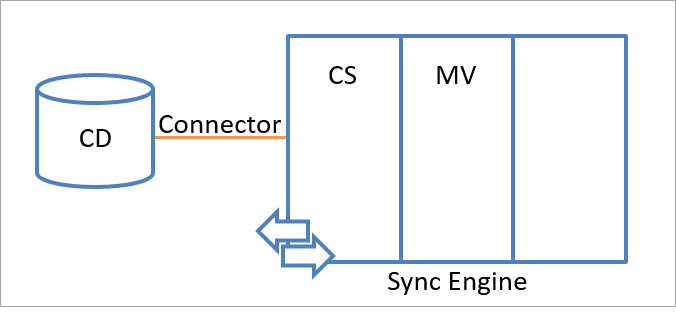
Objetos de identidad del motor de sincronización
Los objetos en el motor de sincronización son representaciones bien de objetos en el origen de datos conectado bien de la vista integrada que el motor de sincronización posee de dichos objetos. Cada objeto de motor de sincronización debe tener un identificador único global (GUID). Los GUID proporcionan integridad a los datos y expresan relaciones entre objetos.
Objetos del espacio conector
Cuando el motor de sincronización se comunica con un origen de datos conectado, lee la información de identidad en ese origen y la usa para crear una representación del objeto de identidad en el espacio conector. No se pueden crear ni eliminar estos objetos individualmente. Sin embargo, puede eliminar manualmente todos los objetos en un espacio conector.
Todos los objetos en el espacio conector poseen dos atributos:
- Un identificador único global (GUID)
- Un nombre distintivo (también conocido como DN)
Si el origen de datos conectado asigna un atributo único al objeto, los objetos en el espacio conector también pueden tener un atributo de delimitador. El atributo de delimitador identifica de forma única un objeto en el origen de datos conectado. El motor de sincronización usa el delimitador para localizar la representación correspondiente a este objeto en el origen de datos conectado. El motor de sincronización da por supuesto que el delimitador de un objeto no cambia nunca mientras dure el objeto.
Muchos de los conectores usan un identificador único conocido para generar un delimitador de forma automática para cada objeto cuando se importa. Por ejemplo, el conector de Active Directory usa el atributo objectGUID como delimitador. Para los orígenes de datos conectados que no proporcionan un identificador único claramente definido, puede especificar que se genere el delimitador como parte de la configuración del conector.
En ese caso, se genera el delimitador a partir de uno o más atributos únicos de un tipo de objeto, ninguno de los cuales cambia, y con eso identifica de forma única el objeto en el espacio conector (por ejemplo, un número de empleado o un identificador de usuario).
El objeto de espacio conector puede ser uno de los siguientes:
- Un objeto de almacenamiento provisional
- Un marcador de posición
Objetos de almacenamiento provisional
Un objeto de almacenamiento provisional representa una instancia de los tipos de objeto designados del origen de datos conectado. Además del GUID y el nombre distintivo, un objeto de almacenamiento provisional siempre posee un valor que indica el tipo de objeto.
Los objetos de almacenamiento provisional que se han importado siempre tienen un valor para el atributo de delimitador. Aquellos que el motor de sincronización acaba de aprovisionar y que se están creando en el origen de datos conectado no tienen ningún valor para el atributo de delimitador.
Los objetos de almacenamiento provisional también incluyen valores actuales para los atributos de negocios, así como información operativa necesaria para que el motor de sincronización realice el proceso de sincronización. Entre esta información operativa, se incluyen marcas que indican el tipo de actualizaciones que están almacenadas provisionalmente en el objeto de almacenamiento provisional. Si un objeto de almacenamiento provisional ha recibido nueva información de identidad desde el origen de datos conectado que todavía no se ha procesado, el objeto se marca como pendiente de importación. Si tiene nueva información de identidad que aún no se ha exportado al origen de datos conectado, se marca como pendiente de exportación.
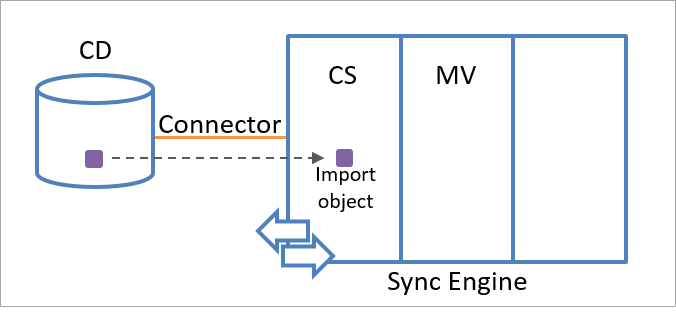
Un objeto de almacenamiento provisional puede ser un objeto de importación o de exportación. El motor de sincronización crea un objeto de importación utilizando la información del objeto recibida desde el origen de datos conectado. Cuando el motor de sincronización recibe información sobre la existencia de un nuevo objeto que coincide con uno de los tipos de objeto seleccionados en el conector, crea un objeto de importación en el espacio conector como representación del objeto en el origen de datos conectado.
En la ilustración siguiente, se muestra un objeto de importación que representa un objeto en el origen de datos conectado.
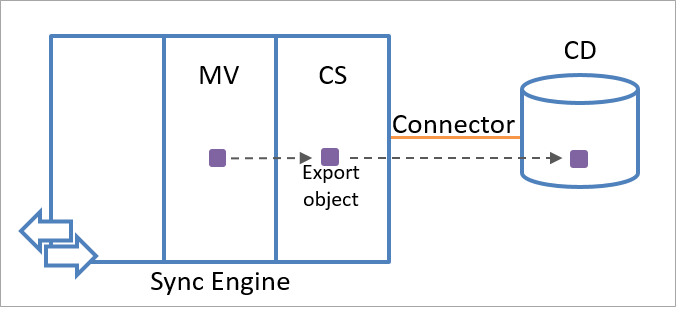
El motor de sincronización crea un objeto de exportación con la información del objeto en el metaverso. Los objetos de exportación se exportan al origen de datos conectado durante la siguiente sesión de comunicación. Desde la perspectiva del motor de sincronización, los objetos de exportación aún no existen en el origen de datos conectado. Por lo tanto, el atributo de delimitador para un objeto de exportación no está disponible. Después de recibir el objeto desde el motor de sincronización, el origen de datos conectado crea un valor único para el atributo de delimitador del objeto.
En la ilustración siguiente, se muestra cómo se crea un objeto de exportación usando la información de identidad en el metaverso.
El motor de sincronización confirma la exportación del objeto al volver a importarlo desde el origen de datos conectado. Los objetos de exportación se convierten en objetos de importación cuando el motor de sincronización los recibe durante la siguiente importación desde ese origen de datos conectado.
Marcadores de posición
El motor de sincronización usa un espacio de nombres plano para almacenar objetos. Sin embargo, algunos orígenes de datos conectados, como Active Directory, usan un espacio de nombres jerárquico. Para transformar la información de un espacio de nombres jerárquico en uno plano, el motor de sincronización usa marcadores de posición para conservar la jerarquía.
Cada marcador de posición representa un componente (por ejemplo, una unidad organizativa) del nombre jerárquico de un objeto que no se ha importado al motor de sincronización, pero que es necesario para construir el nombre jerárquico. Suplen las carencias creadas por las referencias en el origen de datos conectado a objetos que no son objetos de almacenamiento provisional en el espacio conector.
El motor de sincronización también usa marcadores de posición para almacenar objetos a los que se hace referencia y que aún no se han importado. Por ejemplo, si se configura la sincronización para que incluya el atributo de administrador para el objeto Abbie Spencer y el valor recibido es un objeto que aún no se ha importado, como CN=Lee Sperry,CN=Users,DC=fabrikam,DC=com, se almacena la información de administrador como marcadores de posición en el espacio conector. Si más adelante se importa el objeto de administrador, se sobrescribe el objeto de marcador de posición con el objeto de almacenamiento provisional que representa el administrador.
Objetos del metaverso
Un objeto de metaverso contiene la vista agregada que tiene ese motor de sincronización de los objetos de almacenamiento provisional en el espacio conector. El motor de sincronización crea los objetos de metaverso usando la información de los objetos de importación. Se pueden vincular varios objetos del espacio conector a un solo objeto de metaverso, pero no se puede vincular un objeto de espacio conector a más de un objeto de metaverso.
Los objetos de metaverso no se pueden crear ni eliminar manualmente. El motor de sincronización elimina automáticamente los objetos de metaverso que carecen de un vínculo a cualquier objeto de espacio conector en el espacio conector.
Para asignar objetos dentro de un origen de datos conectado a un tipo de objeto correspondiente en el metaverso, el motor de sincronización proporciona un esquema extensible con un conjunto predefinido de tipos de objeto y atributos asociados. Puede crear nuevos tipos de objeto y atributos para los objetos de metaverso. Los atributos pueden ser de un solo valor o de varios, mientras que los tipos de atributo pueden ser cadenas, referencias, números y valores booleanos.
Relaciones entre los objetos de almacenamiento provisional y los objetos de metaverso
Dentro del espacio de nombres del motor de sincronización, se hace posible el flujo de datos por la relación de vínculo entre los objetos de almacenamiento provisional y los objetos de metaverso. Un objeto de almacenamiento provisional que está vinculado a un objeto de metaverso se llama objeto unido (u objeto de conector). Un objeto de almacenamiento provisional que no está vinculado a un objeto de metaverso se llama objeto separado (u objeto de desconector). Se prefieren los términos "unido" y "separado" para no confundirlos con los conectores encargados de importar y exportar datos desde un directorio conectado.
Los marcadores de posición no se vinculan nunca a un objeto de metaverso
Un objeto unido consta de un objeto de almacenamiento provisional y su relación de vínculo con un solo objeto de metaverso. Los objetos unidos se usan para sincronizar los valores de atributo entre un objeto de espacio conector y un objeto de metaverso.
Cuando un objeto de almacenamiento provisional se convierte en objeto unido durante la sincronización, los atributos pueden fluir entre el objeto de almacenamiento provisional y el objeto de metaverso. El flujo de atributos es bidireccional y se configura mediante reglas de atributo de importación y de atributo de exportación.
Se puede vincular un solo objeto de espacio conector a un único objeto de metaverso. Sin embargo, cada objeto de metaverso se puede vincular a varios objetos de espacio conector en el mismo espacio conector o en otros diferentes, como se muestra en la siguiente ilustración.
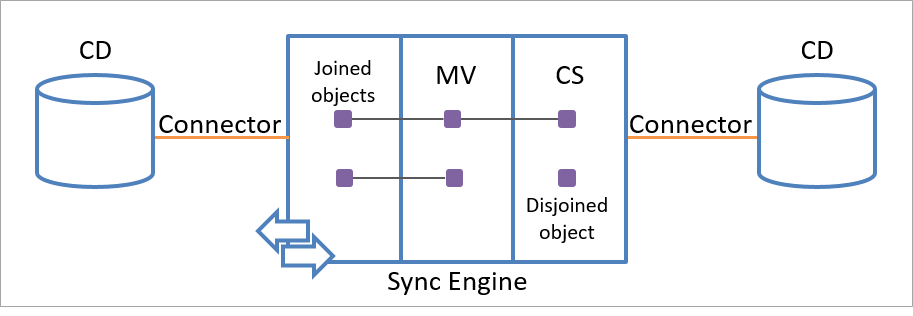
La relación de vínculo entre el objeto de almacenamiento provisional y un objeto de metaverso es persistente y solo se puede quitar con las reglas que especifique.
Un objeto separado es un objeto de almacenamiento provisional que no está vinculado a ningún objeto de metaverso. Los valores de atributo de un objeto separado no se procesan más en el metaverso. El motor de sincronización no actualiza los valores de atributo del objeto correspondiente en el origen de datos conectado.
Mediante el uso de objetos separados, puede almacenar información de identidad en el motor de sincronización y procesarla más adelante. Mantener un objeto de almacenamiento provisional como objeto separado en el espacio conector ofrece muchas ventajas. Dado que el sistema ya ha almacenado provisionalmente la información necesaria sobre este objeto, no es necesario volver a crear una representación de él durante la siguiente importación desde el origen de datos conectado. De este modo, el motor de sincronización siempre dispone de una instantánea completa del origen de datos conectado, incluso si no hay ninguna conexión actual establecida con el origen de datos conectado. Los objetos separados se pueden convertir en objetos unidos y viceversa, según las reglas que especifique.
Un objeto de importación se crea como objeto separado. A cambio, un objeto de exportación debe ser un objeto unido. La lógica del sistema aplica esta regla y elimina todos los objetos de exportación no sean objetos unidos.
Proceso de administración de identidad del motor de sincronización
El proceso de administración de identidad controla cómo se actualiza la información de identidad entre distintos orígenes de datos conectados. La administración de identidad se produce en tres procesos:
- Importar
- Synchronization
- Exportación
Durante el proceso de importación, el motor de sincronización evalúa la información de identidad entrante desde un origen de datos conectado. Cuando se detectan cambios, crea nuevos objetos de almacenamiento provisional o actualiza los existentes en el espacio conector para la sincronización.
Durante el proceso de sincronización, el motor de sincronización actualiza el metaverso para reflejar los cambios que se han producido en el espacio conector y actualiza el espacio conector con los cambios producidos en el metaverso.
Durante el proceso de exportación, el motor de sincronización inserta los cambios que están almacenados en objetos de almacenamiento provisional y que están marcados como pendientes de exportación.
En la siguiente ilustración, se muestra dónde sucede cada uno de los procesos según la información de identidad fluye de un origen de datos conectado a otro.

Proceso de importación
Durante el proceso de importación, el motor de sincronización evalúa las actualizaciones de la información de identidad. El motor de sincronización compara la información de identidad recibida del origen de datos conectado con la información de identidad sobre un objeto de almacenamiento provisional y determina si ese objeto debe actualizarse. Si es necesario actualizarlo con nuevos datos, se marca el objeto como pendiente de importación.
Al almacenar los objetos de forma provisional en el espacio conector antes de la sincronización, el motor de sincronización solo puede procesar la información de identidad que haya cambiado. Este proceso proporciona las siguientes ventajas:
- Sincronización eficiente. Se minimiza la cantidad de datos procesados durante la sincronización.
- Resincronización eficiente. Puede cambiar cómo el motor de sincronización procesa la información de identidad sin volver a conectarlo al origen de datos.
- Oportunidad de obtener una vista previa de la sincronización. Puede obtener una vista previa de la sincronización para comprobar que sus suposiciones sobre el proceso de administración de identidad sean correctas.
Para cada objeto que se especifica en el conector, en primer lugar el motor de sincronización intenta localizar una representación del objeto en el espacio conector del conector. El motor de sincronización examina todos los objetos de almacenamiento provisional en el espacio conector e intenta encontrar uno correspondiente que tenga un atributo de delimitador coincidente. Si no hay ningún objeto de almacenamiento provisional con un atributo de delimitador coincidente, el motor de sincronización intenta encontrar uno con el mismo nombre distintivo.
Cuando el motor de sincronización encuentra un objeto de almacenamiento provisional que coincide con el nombre distintivo pero no con el delimitador, se produce el siguiente comportamiento especial:
- Si el objeto que se encuentra en el espacio conector no tiene ningún delimitador, el motor de sincronización lo quita del espacio conector y marca el objeto de metaverso al que está vinculado para volver a intentar el aprovisionamiento en la siguiente sincronización. A continuación, crea el nuevo objeto de importación.
- Si el objeto que se encuentra en el espacio conector tiene delimitador, el motor de sincronización da por supuesto que este objeto se ha cambiado de nombre o eliminado en el directorio conectado. Asigna un nuevo nombre distintivo temporal al objeto de espacio conector para que pueda almacenar provisionalmente el objeto entrante. El objeto anterior se convierte en transitorioy espera a que el conector importe el cambio de nombre o la eliminación para resolver la situación.
Los objetos transitorios no siempre son un problema y es posible que los vea incluso en un entorno correcto. Con la API de punto de conexión de Microsoft Entra Connect Sync V2, los objetos transitorios deben resolverse automáticamente en ciclos de sincronización diferencial posteriores. Un ejemplo común en el que podría encontrar objetos transitorios generados se produce en servidores de Microsoft Entra Connect instalados en modo de almacenamiento provisional, cuando un administrador elimina permanentemente un objeto directamente en Microsoft Entra ID mediante PowerShell y, posteriormente, vuelve a sincronizarlo.
Si el motor de sincronización localiza un objeto de almacenamiento provisional que se corresponde con el objeto especificado en el conector, determina qué tipo de cambios se aplicarán. Por ejemplo, el motor de sincronización podría cambiar el nombre o eliminar el objeto en el origen de datos conectado o solamente actualizar los valores de atributo del objeto.
Los objetos de almacenamiento provisional con datos actualizados se marcan como pendientes de importación. Existen distintos tipos de importación pendiente. Según el resultado del proceso de importación, un objeto de almacenamiento provisional en el espacio conector tiene uno de los siguientes tipos de importación pendiente:
- No. No hay disponible ningún cambio en ninguno de los atributos del objeto de almacenamiento provisional. El motor de sincronización no marca este tipo como pendiente de importación.
- Agregar. El objeto de almacenamiento provisional es un nuevo objeto de importación en el espacio conector. El motor de sincronización marca este tipo como pendiente de importación para seguir procesándolo en el metaverso.
- Actualizar. El motor de sincronización encuentra un objeto de almacenamiento provisional correspondiente en el espacio conector y marca este tipo como pendiente de importación para que se puedan procesar las actualizaciones de los atributos en el metaverso. Entre las actualizaciones, se incluye el cambio de nombre del objeto.
- Eliminar. El motor de sincronización encuentra un objeto de almacenamiento provisional correspondiente en el espacio conector y marca este tipo como pendiente de importación para que se pueda eliminar el objeto unido.
- Eliminar o agregar. El motor de sincronización encuentra un objeto de almacenamiento provisional correspondiente en el espacio conector, pero los tipos de objeto no coinciden. En este caso, se almacena provisionalmente una modificación de tipo Eliminar o agregar. Este tipo de modificación indica al motor de sincronización que se debe producir una resincronización completa de este objeto porque se le aplicarán diferentes conjuntos de reglas cuando el tipo de objeto cambie.
Al establecer el estado de importación pendiente de un objeto de almacenamiento provisional, se puede reducir de forma notable la cantidad de datos que se procesan durante la sincronización, porque esto permite que el sistema solo procese los objetos que tengan datos actualizados.
Proceso de sincronización
La sincronización consta de dos procesos relacionados:
- Sincronización de entrada, cuando se actualiza el contenido del metaverso usando los datos en el espacio conector.
- Sincronización de salida, cuando se actualiza el contenido del espacio conector con datos en el metaverso.
Usando la información almacenada provisionalmente en el espacio conector, el proceso de sincronización de entrada crea una vista integrada de los datos en el metaverso que se almacena en los orígenes de datos conectados. Dependiendo de cómo se configuren las reglas, se agregarán todos los objetos de almacenamiento provisional o solo aquellos que tengan información pendiente de importación.
El proceso de sincronización de salida actualiza los objetos de exportación cuando cambian los objetos de metaverso.
La sincronización de entrada crea la vista integrada en el metaverso con la información de identidad que se recibe de los orígenes de datos conectados. El motor de sincronización puede procesar información de identidad en cualquier momento mediante la última información de identidad que ha recibido del origen de datos conectado.
Sincronización de entrada
La sincronización de entrada incluye los siguientes procesos:
- Aprovisionamiento (también denominado proyección si es importante distinguir este proceso del aprovisionamiento de la sincronización de salida). El motor de sincronización crea un nuevo objeto de metaverso basándose en un objeto de almacenamiento provisional y los vincula. El aprovisionamiento es una operación de nivel de objeto.
- Unión. El motor de sincronización vincula un objeto de almacenamiento provisional a un objeto de metaverso existente. La unión es una operación de nivel de objeto.
- Flujo de atributos de importación. El motor de sincronización actualiza los valores de atributo, lo que se denomina flujo de atributos, del objeto en el metaverso. El flujo de atributos de importación es una operación de nivel de atributo que requiere un vínculo entre un objeto de almacenamiento provisional y un objeto de metaverso.
El aprovisionamiento es el único proceso que crea objetos en el metaverso y afecta solamente a los objetos de importación que sean objetos separados. Durante el aprovisionamiento, el motor de sincronización crea un objeto de metaverso que corresponde al tipo del objeto de importación y establece un vínculo entre ambos objetos, lo que crea un objeto unido.
El proceso de unión también establece un vínculo entre los objetos de importación y un objeto de metaverso. La diferencia entre la unión y el aprovisionamiento es que el proceso de unión requiere que el objeto de importación se vincule a un objeto de metaverso existente, mientras que el proceso de aprovisionamiento crea un nuevo objeto de metaverso.
El motor de sincronización intenta unir un objeto de importación a un objeto de metaverso mediante criterios que se especifican en la configuración de la regla de sincronización.
Durante los procesos de aprovisionamiento y unión, el motor de sincronización vincula un objeto separado a un objeto de metaverso, lo que los convierte en unidos. Una vez completadas estas operaciones de nivel de objeto, el motor de sincronización puede actualizar los valores de atributo del objeto de metaverso asociado. Este proceso se denomina flujo de atributos de importación.
El flujo de atributos de importación se produce en todos los objetos de importación que transportan datos nuevos y están vinculados a un objeto de metaverso.
Sincronización de salida
La sincronización de salida actualiza los objetos de exportación cuando un objeto de metaverso cambia pero no se elimina. El objetivo de la sincronización de salida es evaluar si los cambios en objetos de metaverso requieren que se actualicen los objetos de almacenamiento provisional en los espacios conector. En algunos casos, los cambios pueden requerir que se actualicen los objetos de almacenamiento provisional en todos los espacios conector. Los objetos de almacenamiento provisional que se cambian se marcan como pendientes de exportación, lo que los convierte en objetos de exportación. Después, estos objetos de exportación se insertan en el origen de datos conectado durante el proceso de exportación.
La sincronización de salida consta de tres procesos:
- Aprovisionamiento
- Desaprovisionamiento
- Flujo de atributos de exportación
Tanto el aprovisionamiento como el desaprovisionamiento son operaciones de nivel de objeto. El desaprovisionamiento depende del aprovisionamiento porque solo lo puede iniciar este último. El desaprovisionamiento se desencadena cuando el aprovisionamiento quita el vínculo entre un objeto de metaverso y un objeto de exportación.
El aprovisionamiento se desencadena siempre cuando se aplican cambios a objetos en el metaverso. Cuando se realizan cambios en objetos de metaverso, el motor de sincronización puede llevar a cabo cualquiera de las siguientes tareas como parte del proceso de aprovisionamiento:
- Crear objetos unidos, donde un objeto de metaverso se vincula a un objeto de exportación recién creado.
- Cambiar el nombre de un objeto unido.
- Separar los vínculos entre un objeto de metaverso y objetos de almacenamiento provisional, lo que crea un objeto separado.
Si el aprovisionamiento requiere que el motor de sincronización cree un objeto de conector, el objeto de almacenamiento provisional al que está vinculado el objeto de metaverso siempre es un objeto de exportación porque el objeto aún no existirá en el origen de datos conectado.
Si el aprovisionamiento requiere que el motor de sincronización separe un objeto unido, lo que crea un objeto separado, se desencadena el desaprovisionamiento. El proceso de desaprovisionamiento eliminará el objeto.
Durante el desaprovisionamiento, la eliminación de un objeto de exportación no elimina físicamente el objeto. El objeto se marca como eliminado, lo que significa que la operación de eliminación se almacena provisionalmente en el objeto.
El flujo de atributos de exportación también se produce durante el proceso de sincronización de salida, de forma similar al flujo de atributos de importación que se produce durante la sincronización de entrada. El flujo de atributos de exportación se produce solamente entre los objetos de metaverso y de exportación que están unidos.
Proceso de exportación
Durante el proceso de exportación, el motor de sincronización examina todos los objetos de exportación que están marcados como pendientes de exportación en el espacio conector y después envía las actualizaciones al origen de datos conectado.
El motor de sincronización puede determinar si una exportación se ha realizado correctamente, pero no puede determinar con certeza que el proceso de administración de identidad se haya completado. Siempre es posible que otros procesos cambien los objetos en el origen de datos conectado. Dado que el motor de sincronización carece de conexión persistente al origen de datos conectado, no basta para hacer suposiciones acerca de las propiedades de un objeto en el origen de datos conectado basándose únicamente en una notificación de exportación correcta.
Por ejemplo, un proceso en el origen de datos conectado podría cambiar los atributos del objeto a sus valores originales (es decir, el origen de datos conectado podría sobrescribir los valores inmediatamente después de que el motor de sincronización los insertara y se aplicaran correctamente en el origen de datos conectado).
El motor de sincronización almacena información de estado de exportación y de importación sobre cada objeto de almacenamiento provisional. Si los valores de los atributos que se especifican en la lista de inclusión de atributos han cambiado desde la última exportación, el almacenamiento del estado de importación y de exportación permite que el motor de sincronización reaccione correctamente. El motor de sincronización usa el proceso de importación para confirmar los valores de atributo que se han exportado al origen de datos conectado. Una comparación entre la información importada y la exportada, tal como se muestra en la siguiente ilustración, permite al motor de sincronización determinar si la exportación fue correcta o si es necesario repetirla.
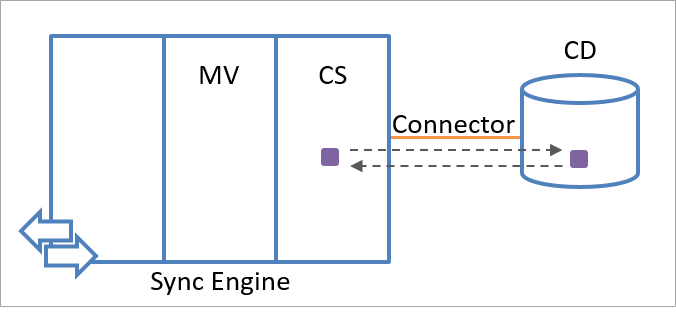
Por ejemplo, si el motor de sincronización exporta el atributo C, que tiene el valor 5, a un origen de datos conectado, almacena C=5 en la memoria del estado de exportación. Cada exportación adicional en este objeto da lugar a un intento de volver a exportar C=5 al origen de datos conectado porque el motor de sincronización da por supuesto que este valor no se ha aplicado de forma persistente al objeto (es decir, a menos que se importara recientemente un valor diferente desde el origen de datos conectado). La memoria de exportación se borra cuando se recibe C=5 durante una operación de importación en el objeto.
Pasos siguientes
Más información sobre la configuración de la sincronización de Microsoft Entra Connect.
Más información sobre la Integración de las identidades locales con Microsoft Entra ID.