System.IO.Pipelines en .NET
System.IO.Pipelines es una biblioteca que se ha diseñado para facilitar la entrada y salida de alto rendimiento en .NET. Se trata de una biblioteca que tiene como destino .NET Standard y que funciona en todas las implementaciones de .NET.
La biblioteca está disponible en el paquete NuGet System.IO.Pipelines.
¿Qué problema resuelve System.IO.Pipelines?
Las aplicaciones que analizan datos de streaming se componen de código reutilizable que cuenta con muchos flujos de código especializados e inusuales. El código reutilizable y especial del caso es complejo y difícil de mantener.
System.IO.Pipelines se ha diseñado para lo siguiente:
- Disponer de un alto rendimiento al analizar datos de streaming.
- Reducir la complejidad del código.
El código siguiente es habitual para un servidor TCP que recibe mensajes delimitados por línea (delimitados por '\n') de un cliente:
async Task ProcessLinesAsync(NetworkStream stream)
{
var buffer = new byte[1024];
await stream.ReadAsync(buffer, 0, buffer.Length);
// Process a single line from the buffer
ProcessLine(buffer);
}
El código anterior tiene varios problemas:
- Es posible que el mensaje completo (final de la línea) no se reciba en una sola llamada a
ReadAsync. - Se omite el resultado de
stream.ReadAsync.stream.ReadAsyncdevuelve la cantidad de datos que se han leído. - No controla el caso en el que se leen varias líneas en una sola llamada a
ReadAsync. - Asigna una matriz
bytecon cada lectura.
Para solucionar los problemas anteriores, es necesario realizar los siguientes cambios:
Almacenar en búfer los datos entrantes hasta que se encuentre una línea nueva.
Analizar todas las líneas devueltas en el búfer.
Es posible que la línea tenga un tamaño superior a 1 KB (1024 bytes). El código debe cambiar el tamaño del búfer de entrada hasta que se encuentre el delimitador para ajustarse a la línea completa dentro del búfer.
- Si se cambia el tamaño del búfer, se realizan más copias de búfer a medida que aparecen líneas más largas en la entrada.
- Para reducir el espacio desaprovechado, compacte el búfer usado para las líneas de lectura.
Considere la posibilidad de usar la agrupación de búferes para evitar asignar memoria de forma repetida.
En el código siguiente se abordan algunos de estos problemas:
async Task ProcessLinesAsync(NetworkStream stream)
{
byte[] buffer = ArrayPool<byte>.Shared.Rent(1024);
var bytesBuffered = 0;
var bytesConsumed = 0;
while (true)
{
// Calculate the amount of bytes remaining in the buffer.
var bytesRemaining = buffer.Length - bytesBuffered;
if (bytesRemaining == 0)
{
// Double the buffer size and copy the previously buffered data into the new buffer.
var newBuffer = ArrayPool<byte>.Shared.Rent(buffer.Length * 2);
Buffer.BlockCopy(buffer, 0, newBuffer, 0, buffer.Length);
// Return the old buffer to the pool.
ArrayPool<byte>.Shared.Return(buffer);
buffer = newBuffer;
bytesRemaining = buffer.Length - bytesBuffered;
}
var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, bytesRemaining);
if (bytesRead == 0)
{
// EOF
break;
}
// Keep track of the amount of buffered bytes.
bytesBuffered += bytesRead;
var linePosition = -1;
do
{
// Look for a EOL in the buffered data.
linePosition = Array.IndexOf(buffer, (byte)'\n', bytesConsumed,
bytesBuffered - bytesConsumed);
if (linePosition >= 0)
{
// Calculate the length of the line based on the offset.
var lineLength = linePosition - bytesConsumed;
// Process the line.
ProcessLine(buffer, bytesConsumed, lineLength);
// Move the bytesConsumed to skip past the line consumed (including \n).
bytesConsumed += lineLength + 1;
}
}
while (linePosition >= 0);
}
}
El código anterior es complejo y no aborda todos los problemas identificados. Las redes de alto rendimiento normalmente implican la escritura de código complejo para maximizar el rendimiento. System.IO.Pipelines se ha diseñado para facilitar la escritura de este tipo de código.
Canalización (|).
La clase Pipe se puede usar para crear un par de PipeWriter/PipeReader. Todos los datos escritos en PipeWriter están disponibles en PipeReader:
var pipe = new Pipe();
PipeReader reader = pipe.Reader;
PipeWriter writer = pipe.Writer;
Uso básico de la canalización
async Task ProcessLinesAsync(Socket socket)
{
var pipe = new Pipe();
Task writing = FillPipeAsync(socket, pipe.Writer);
Task reading = ReadPipeAsync(pipe.Reader);
await Task.WhenAll(reading, writing);
}
async Task FillPipeAsync(Socket socket, PipeWriter writer)
{
const int minimumBufferSize = 512;
while (true)
{
// Allocate at least 512 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(minimumBufferSize);
try
{
int bytesRead = await socket.ReceiveAsync(memory, SocketFlags.None);
if (bytesRead == 0)
{
break;
}
// Tell the PipeWriter how much was read from the Socket.
writer.Advance(bytesRead);
}
catch (Exception ex)
{
LogError(ex);
break;
}
// Make the data available to the PipeReader.
FlushResult result = await writer.FlushAsync();
if (result.IsCompleted)
{
break;
}
}
// By completing PipeWriter, tell the PipeReader that there's no more data coming.
await writer.CompleteAsync();
}
async Task ReadPipeAsync(PipeReader reader)
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
while (TryReadLine(ref buffer, out ReadOnlySequence<byte> line))
{
// Process the line.
ProcessLine(line);
}
// Tell the PipeReader how much of the buffer has been consumed.
reader.AdvanceTo(buffer.Start, buffer.End);
// Stop reading if there's no more data coming.
if (result.IsCompleted)
{
break;
}
}
// Mark the PipeReader as complete.
await reader.CompleteAsync();
}
bool TryReadLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
// Look for a EOL in the buffer.
SequencePosition? position = buffer.PositionOf((byte)'\n');
if (position == null)
{
line = default;
return false;
}
// Skip the line + the \n.
line = buffer.Slice(0, position.Value);
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
return true;
}
Hay dos bucles:
FillPipeAsynclee deSockety escribe enPipeWriter.ReadPipeAsynclee dePipeReadery analiza las líneas de entrada.
No existe ningún búfer explícito asignado. Toda la administración del búfer se delega en las implementaciones de PipeReader y PipeWriter. La delegación de la administración del búfer facilita el consumo de código para centrarse únicamente en la lógica de negocios.
En el primer bucle:
- Se llama a PipeWriter.GetMemory(Int32) para obtener la memoria del escritor subyacente.
- Se llama a PipeWriter.Advance(Int32) para indicar a
PipeWriterla cantidad de datos que se han escrito en el búfer. - Se llama a PipeWriter.FlushAsync para hacer que los datos estén disponibles en
PipeReader.
En el segundo bucle, PipeReader consume los búferes que ha escrito PipeWriter. Los búferes proceden del socket. La llamada a PipeReader.ReadAsync:
Devuelve un elemento ReadResult que contiene dos fragmentos de información importantes:
- Los datos que se han leído en forma de
ReadOnlySequence<byte>. - Un valor booleano
IsCompletedque indica si se ha alcanzado el final de los datos (EOD).
- Los datos que se han leído en forma de
Después de buscar el delimitador de final de línea (EOL) y analizar la línea ocurre lo siguiente:
- La lógica procesa el búfer para omitir lo que ya se ha procesado.
- Se llama a
PipeReader.AdvanceTopara indicar aPipeReaderla cantidad de datos que se han consumido y examinado.
Los bucles de lectura y escritura finalizan con una llamada a Complete. Complete permite liberar la memoria que ha asignado la canalización subyacente.
Contrapresión y control de flujo
Idealmente, la lectura y el análisis funcionan juntos:
- El subproceso de lectura consume datos de la red y los coloca en los búferes.
- El subproceso de análisis se encarga de construir las estructuras de datos adecuadas.
Normalmente, el análisis tarda más tiempo en realizarse que simplemente copiar bloques de datos de la red:
- El subproceso de lectura se obtiene antes del subproceso de análisis.
- El subproceso de lectura tiene que ralentizar o asignar más memoria para almacenar los datos para el subproceso de análisis.
Para obtener un rendimiento óptimo, existe un equilibrio entre las pausas frecuentes y la asignación de más memoria.
Para resolver el problema anterior, Pipe tiene dos opciones de configuración para controlar el flujo de datos:
- PauseWriterThreshold: determina la cantidad de datos que se deben almacenar en búfer antes de que se pausen las llamadas a FlushAsync.
- ResumeWriterThreshold: determina la cantidad de datos que debe observar el lector antes de que se reanuden las llamadas a
PipeWriter.FlushAsync.
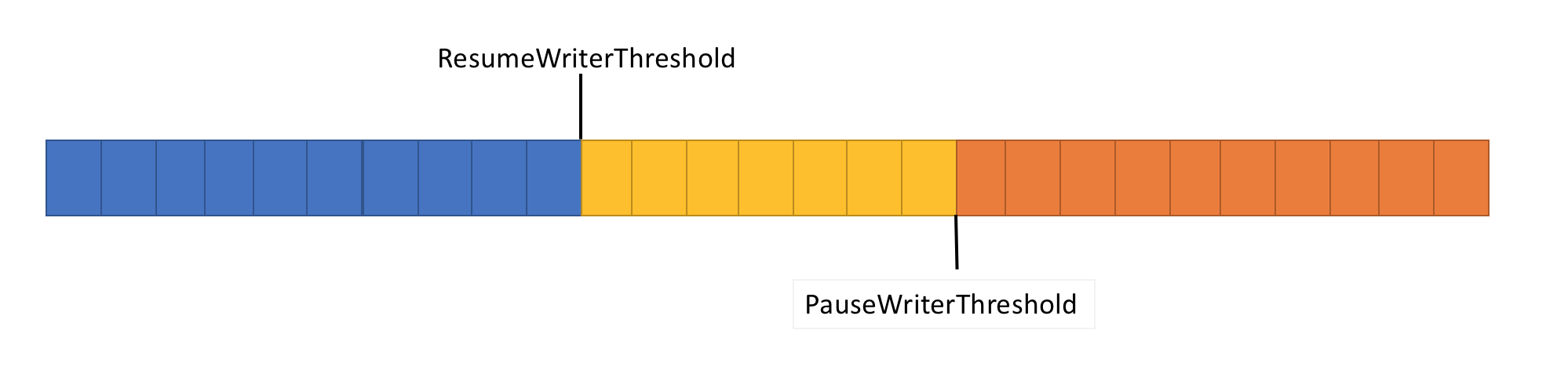
- Devuelve un
ValueTask<FlushResult>incompleto cuando la cantidad de datos dePipecruzaPauseWriterThreshold. - Completa
ValueTask<FlushResult>cuando se vuelve menor queResumeWriterThreshold.
Se usan dos valores para evitar ciclos rápidos, que pueden producirse si solo se usa un valor.
Ejemplos
// The Pipe will start returning incomplete tasks from FlushAsync until
// the reader examines at least 5 bytes.
var options = new PipeOptions(pauseWriterThreshold: 10, resumeWriterThreshold: 5);
var pipe = new Pipe(options);
PipeScheduler
Normalmente, cuando se usa async y await, el código asincrónico se reanuda en un elemento TaskScheduler o en el elemento SynchronizationContext actual.
Al realizar operaciones de E/S, es importante tener un control específico sobre dónde se realizan estas operaciones. Este control permite sacar provecho de las cachés de CPU de manera eficiente. Para las aplicaciones de alto rendimiento, como los servidores web, disponer de un almacenamiento en caché eficiente resulta fundamental. PipeScheduler proporciona control sobre dónde se ejecutan las devoluciones de llamada asincrónicas. De manera predeterminada:
- Se usa el elemento SynchronizationContext actual.
- Si no hay ningún elemento
SynchronizationContext, se usa el grupo de subprocesos para ejecutar las devoluciones de llamada.
public static void Main(string[] args)
{
var writeScheduler = new SingleThreadPipeScheduler();
var readScheduler = new SingleThreadPipeScheduler();
// Tell the Pipe what schedulers to use and disable the SynchronizationContext.
var options = new PipeOptions(readerScheduler: readScheduler,
writerScheduler: writeScheduler,
useSynchronizationContext: false);
var pipe = new Pipe(options);
}
// This is a sample scheduler that async callbacks on a single dedicated thread.
public class SingleThreadPipeScheduler : PipeScheduler
{
private readonly BlockingCollection<(Action<object> Action, object State)> _queue =
new BlockingCollection<(Action<object> Action, object State)>();
private readonly Thread _thread;
public SingleThreadPipeScheduler()
{
_thread = new Thread(DoWork);
_thread.Start();
}
private void DoWork()
{
foreach (var item in _queue.GetConsumingEnumerable())
{
item.Action(item.State);
}
}
public override void Schedule(Action<object?> action, object? state)
{
if (state is not null)
{
_queue.Add((action, state));
}
// else log the fact that _queue.Add was not called.
}
}
PipeScheduler.ThreadPool es la implementación de PipeScheduler que pone en cola las devoluciones de llamada en el grupo de subprocesos. PipeScheduler.ThreadPool es el valor predeterminado y, por lo general, la mejor opción. PipeScheduler.Inline puede producir consecuencias no intencionadas, como interbloqueos.
Restablecimiento de la canalización
A menudo, es eficiente la reutilización del objeto Pipe. Para restablecer la canalización, llame a PipeReader Reset cuando se hayan completado los elementos PipeReader y PipeWriter.
PipeReader
PipeReader administra la memoria en nombre del autor de la llamada. Llame a PipeReader.AdvanceTosiempre después de llamar a PipeReader.ReadAsync. Esto permite que PipeReader sepa cuándo ha acabado con la memoria el autor de la llamada, de tal modo que se le pueda realizar un seguimiento. El elemento ReadOnlySequence<byte> que devuelve PipeReader.ReadAsync solo es válido hasta que se llame a PipeReader.AdvanceTo. No es válido usar ReadOnlySequence<byte> después de llamar a PipeReader.AdvanceTo.
PipeReader.AdvanceTo toma dos argumentos SequencePosition:
- El primer argumento determina la cantidad de memoria consumida.
- El segundo argumento determina la cantidad de búfer observado.
Marcar los datos como consumidos significa que la canalización puede devolver la memoria al grupo de búferes subyacente. Cuando se marcan los datos como observados, estos controlan lo que hace la siguiente llamada a PipeReader.ReadAsync. Marcar todo como observado significa que la siguiente llamada a PipeReader.ReadAsync no se devolverá hasta que haya más datos escritos en la canalización. Cualquier otro valor hará que la siguiente llamada a PipeReader.ReadAsync se devuelva de inmediato con los datos observados y los no observados, pero no con los que ya se han consumido.
Escenarios de lectura de datos de streaming
Hay un par de patrones típicos que surgen al intentar leer datos de streaming:
- Dada una secuencia de datos, analizar un solo mensaje.
- Dada una secuencia de datos, analizar todos los mensajes disponibles.
En los ejemplos siguientes se usa el método TryParseLines para analizar los mensajes que proceden de un elemento ReadOnlySequence<byte>. TryParseLines analiza un solo mensaje y actualiza el búfer de entrada para recortar el mensaje analizado del búfer. TryParseLines no forma parte de .NET, es un método de usuario escrito que se usa en las secciones siguientes.
bool TryParseLines(ref ReadOnlySequence<byte> buffer, out Message message);
Lectura de un único mensaje
En el código siguiente se lee un único mensaje de un elemento PipeReader y se devuelve al autor de la llamada.
async ValueTask<Message?> ReadSingleMessageAsync(PipeReader reader,
CancellationToken cancellationToken = default)
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
// In the event that no message is parsed successfully, mark consumed
// as nothing and examined as the entire buffer.
SequencePosition consumed = buffer.Start;
SequencePosition examined = buffer.End;
try
{
if (TryParseLines(ref buffer, out Message message))
{
// A single message was successfully parsed so mark the start of the
// parsed buffer as consumed. TryParseLines trims the buffer to
// point to the data after the message was parsed.
consumed = buffer.Start;
// Examined is marked the same as consumed here, so the next call
// to ReadSingleMessageAsync will process the next message if there's
// one.
examined = consumed;
return message;
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(consumed, examined);
}
}
return null;
}
El código anterior:
- Analiza un único mensaje.
- Actualiza el elemento
SequencePositionconsumido y el elementoSequencePositionexaminado para que apunte al principio del búfer recortado de entrada.
Los dos argumentos SequencePosition se actualizan porque TryParseLines quita el mensaje analizado del búfer de entrada. Por lo general, al analizar un solo mensaje del búfer, la posición examinada debe ser una de las siguientes:
- El final del mensaje.
- El final del búfer recibido si no se ha encontrado ningún mensaje.
El caso de mensaje único tiene la probabilidad más alta de producir errores. Si se pasan valores incorrectos a examinados, se puede producir una excepción de memoria insuficiente o un bucle infinito. Para obtener más información, vea la sección Problemas comunes de PipeReader.
Lectura de varios mensajes
En el código siguiente se leen todos los mensajes de un elemento PipeReader y se llama a ProcessMessageAsync en cada uno de estos.
async Task ProcessMessagesAsync(PipeReader reader, CancellationToken cancellationToken = default)
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
Cancelación
PipeReader.ReadAsync:
- Admite pasar un elemento CancellationToken.
- Produce un elemento OperationCanceledException si se cancela
CancellationTokenmientras haya una lectura pendiente. - Admite una manera de cancelar la operación de lectura actual mediante PipeReader.CancelPendingRead, lo que evita que se produzca una excepción. La llamada a
PipeReader.CancelPendingReadprovoca que la llamada actual aPipeReader.ReadAsync, o la siguiente, devuelva un elemento ReadResult conIsCanceledestablecido entrue. Esto puede ser útil para detener el bucle de lectura existente de forma no destructiva y no excepcional.
private PipeReader reader;
public MyConnection(PipeReader reader)
{
this.reader = reader;
}
public void Abort()
{
// Cancel the pending read so the process loop ends without an exception.
reader.CancelPendingRead();
}
public async Task ProcessMessagesAsync()
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
if (result.IsCanceled)
{
// The read was canceled. You can quit without reading the existing data.
break;
}
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
Problemas comunes de PipeReader
Si se pasan valores incorrectos a
consumedoexamined, es posible que se lean datos ya leídos.Si se pasa
buffer.Endcomo examinado, es posible que se produzca lo siguiente:- Datos detenidos
- Es posible que se produzca una excepción de memoria insuficiente (OOM) si no se consumen los datos. Por ejemplo,
PipeReader.AdvanceTo(position, buffer.End)cuando se procesa un único mensaje a la vez desde el búfer.
Si se pasan valores incorrectos a
consumedoexamined, es posible que se produzca un bucle infinito. Por ejemplo,PipeReader.AdvanceTo(buffer.Start), sibuffer.Startno ha cambiado, hará que la siguiente llamada aPipeReader.ReadAsyncse devuelva inmediatamente antes de que lleguen datos nuevos.Si se pasan valores incorrectos a
consumedoexamined, es posible que se produzca un almacenamiento en búfer infinito (posible OOM).El uso de
ReadOnlySequence<byte>después de llamar aPipeReader.AdvanceTopuede producir daños en la memoria (se usa después de liberar).Si se produce un error al llamar a
PipeReader.Complete/CompleteAsync, puede dar como resultado una fuga de memoria.Al comprobar ReadResult.IsCompleted y salir de la lógica de lectura antes de procesar el búfer, se produce una pérdida de datos. La condición de salida del bucle debe basarse en
ReadResult.Buffer.IsEmptyyReadResult.IsCompleted. Si esto se hace incorrectamente, podría producirse un bucle infinito.
Código problemático
❌Pérdida de datos
ReadResult puede devolver el segmento final de los datos cuando IsCompleted está establecido en true. Si no se leen los datos antes de salir del bucle de lectura, se producirá una pérdida de datos.
Advertencia
NO utilice el código siguiente. El uso de este código de ejemplo producirá pérdidas de datos, bloqueos e incidencias de seguridad, y NO se debe copiar. El ejemplo siguiente se proporciona para explicar los Problemas comunes de PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> dataLossBuffer = result.Buffer;
if (result.IsCompleted)
break;
Process(ref dataLossBuffer, out Message message);
reader.AdvanceTo(dataLossBuffer.Start, dataLossBuffer.End);
}
Advertencia
NO utilice el código anterior. El uso de este código de ejemplo producirá pérdidas de datos, bloqueos e incidencias de seguridad, y NO se debe copiar. El ejemplo anterior se proporciona para explicar los Problemas comunes de PipeReader.
❌Bucle infinito
La lógica siguiente puede producir un bucle infinito si Result.IsCompleted es true, pero nunca hay un mensaje completo en el búfer.
Advertencia
NO utilice el código siguiente. El uso de este código de ejemplo producirá pérdidas de datos, bloqueos e incidencias de seguridad, y NO se debe copiar. El ejemplo siguiente se proporciona para explicar los Problemas comunes de PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (result.IsCompleted && infiniteLoopBuffer.IsEmpty)
break;
Process(ref infiniteLoopBuffer, out Message message);
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
Advertencia
NO utilice el código anterior. El uso de este código de ejemplo producirá pérdidas de datos, bloqueos e incidencias de seguridad, y NO se debe copiar. El ejemplo anterior se proporciona para explicar los Problemas comunes de PipeReader.
Este es otro fragmento de código con el mismo problema. Está comprobando si hay un búfer no vacío antes de comprobar ReadResult.IsCompleted. Dado que está en un elemento else if, se ejecutará en bucle para siempre si en el búfer no hay nunca un mensaje completo.
Advertencia
NO utilice el código siguiente. El uso de este código de ejemplo producirá pérdidas de datos, bloqueos e incidencias de seguridad, y NO se debe copiar. El ejemplo siguiente se proporciona para explicar los Problemas comunes de PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (!infiniteLoopBuffer.IsEmpty)
Process(ref infiniteLoopBuffer, out Message message);
else if (result.IsCompleted)
break;
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
Advertencia
NO utilice el código anterior. El uso de este código de ejemplo producirá pérdidas de datos, bloqueos e incidencias de seguridad, y NO se debe copiar. El ejemplo anterior se proporciona para explicar los Problemas comunes de PipeReader.
❌Aplicación sin respuesta
La llamada incondicional a PipeReader.AdvanceTo, con buffer.End en la posición examined, puede resultar en una aplicación sin respuesta al analizar un solo mensaje. La siguiente llamada a PipeReader.AdvanceTo no se devolverá hasta que:
- Haya más datos escritos en la canalización.
- Y los nuevos datos no se hayan examinado previamente.
Advertencia
NO utilice el código siguiente. El uso de este código de ejemplo producirá pérdidas de datos, bloqueos e incidencias de seguridad, y NO se debe copiar. El ejemplo siguiente se proporciona para explicar los Problemas comunes de PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> hangBuffer = result.Buffer;
Process(ref hangBuffer, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(hangBuffer.Start, hangBuffer.End);
if (message != null)
return message;
}
Advertencia
NO utilice el código anterior. El uso de este código de ejemplo producirá pérdidas de datos, bloqueos e incidencias de seguridad, y NO se debe copiar. El ejemplo anterior se proporciona para explicar los Problemas comunes de PipeReader.
❌Memoria insuficiente (OOM)
Con las condiciones siguientes, el código siguiente mantiene el almacenamiento en búfer hasta que se produce OutOfMemoryException:
- No hay tamaño máximo del mensaje.
- Los datos que devuelve
PipeReaderno representan un mensaje completo. Por ejemplo, no representa un mensaje completo porque el otro lado está escribiendo un mensaje de gran tamaño (por ejemplo, un mensaje de 4 GB).
Advertencia
NO utilice el código siguiente. El uso de este código de ejemplo producirá pérdidas de datos, bloqueos e incidencias de seguridad, y NO se debe copiar. El ejemplo siguiente se proporciona para explicar los Problemas comunes de PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> thisCouldOutOfMemory = result.Buffer;
Process(ref thisCouldOutOfMemory, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(thisCouldOutOfMemory.Start, thisCouldOutOfMemory.End);
if (message != null)
return message;
}
Advertencia
NO utilice el código anterior. El uso de este código de ejemplo producirá pérdidas de datos, bloqueos e incidencias de seguridad, y NO se debe copiar. El ejemplo anterior se proporciona para explicar los Problemas comunes de PipeReader.
❌Daño en la memoria
Al escribir asistentes que lean el búfer, se debe copiar cualquier carga devuelta antes de llamar a Advance. En el ejemplo siguiente se devolverá la memoria que ha descartado Pipe y se puede volver a usar para la siguiente operación (lectura/escritura).
Advertencia
NO utilice el código siguiente. El uso de este código de ejemplo producirá pérdidas de datos, bloqueos e incidencias de seguridad, y NO se debe copiar. El ejemplo siguiente se proporciona para explicar los Problemas comunes de PipeReader.
public class Message
{
public ReadOnlySequence<byte> CorruptedPayload { get; set; }
}
Environment.FailFast("This code is terrible, don't use it!");
Message message = null;
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
ReadHeader(ref buffer, out int length);
if (length <= buffer.Length)
{
message = new Message
{
// Slice the payload from the existing buffer
CorruptedPayload = buffer.Slice(0, length)
};
buffer = buffer.Slice(length);
}
if (result.IsCompleted)
break;
reader.AdvanceTo(buffer.Start, buffer.End);
if (message != null)
{
// This code is broken since reader.AdvanceTo() was called with a position *after* the buffer
// was captured.
break;
}
}
return message;
}
Advertencia
NO utilice el código anterior. El uso de este código de ejemplo producirá pérdidas de datos, bloqueos e incidencias de seguridad, y NO se debe copiar. El ejemplo anterior se proporciona para explicar los Problemas comunes de PipeReader.
PipeWriter
PipeWriter administra los búferes para escribir en nombre del autor de la llamada. PipeWriter implementa IBufferWriter<byte>. IBufferWriter<byte> permite obtener acceso a los búferes para realizar escrituras sin necesidad de tener copias de búfer adicionales.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
// Request at least 5 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(5);
// Write directly into the buffer.
int written = Encoding.ASCII.GetBytes("Hello".AsSpan(), memory.Span);
// Tell the writer how many bytes were written.
writer.Advance(written);
await writer.FlushAsync(cancellationToken);
}
El código anterior:
- Solicita un búfer de al menos 5 bytes de
PipeWritermediante GetMemory. - Escribe bytes para la cadena ASCII
"Hello"en el elemento devueltoMemory<byte>. - Llama a Advance para indicar el número de bytes que se han escrito en el búfer.
- Vacía
PipeWriter, que envía los bytes al dispositivo subyacente.
El método de escritura anterior utiliza los búferes que proporciona PipeWriter. También podría haber usado PipeWriter.WriteAsync, el cual:
- Copia el búfer existente en
PipeWriter. - Llama a
GetSpanoAdvance, según corresponda, y llama a FlushAsync.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer, there's no need to call Advance here
// (Write does that).
await writer.WriteAsync(helloBytes, cancellationToken);
}
Cancelación
FlushAsync admite pasar un elemento CancellationToken. Al pasar un elemento CancellationToken, se produce un elemento OperationCanceledException si el token se cancela mientras haya una operación de vaciado pendiente. PipeWriter.FlushAsync admite una manera de cancelar la operación de vaciado actual a través de PipeWriter.CancelPendingFlush sin que se produzca una excepción. La llamada a PipeWriter.CancelPendingFlush provoca que la llamada actual a PipeWriter.FlushAsync o a PipeWriter.WriteAsync, devuelva un elemento FlushResult con IsCanceled establecido en true. Esto puede ser útil para detener el vaciado de retención de forma no destructiva y no excepcional.
Problemas comunes de PipeWriter
- GetSpan y GetMemory devuelven un búfer con, al menos, la cantidad de memoria solicitada. No asume tamaños de búfer exactos.
- No existe ninguna garantía de que las llamadas sucesivas devuelvan el mismo búfer o el mismo tamaño del búfer.
- Se debe solicitar un nuevo búfer después de llamar a Advance para seguir escribiendo más datos. No se puede escribir en el búfer adquirido previamente.
- La llamada a
GetMemoryo aGetSpanno es segura mientras haya una llamada incompleta aFlushAsync. - La llamada a
Completeo aCompleteAsyncpuede provocar daños en la memoria mientras haya datos no vaciados.
Sugerencias para usar PipeReader y PipeWriter
Las siguientes sugerencias le ayudarán a usar correctamente las clases System.IO.Pipelines:
- Complete siempre PipeReader y PipeWriter, incluida una excepción cuando corresponda.
- Llame a PipeReader.AdvanceTosiempre después de llamar a PipeReader.ReadAsync.
- Periódicamente
awaitPipeWriter.FlushAsync mientras se escribe y siempre comprueba FlushResult.IsCompleted. Anule la escritura siIsCompletedestrue, ya que indica que el lector se ha completado y ya no le importa lo que se escribe. - Llame PipeWriter.FlushAsync después de escribir algo al que quiera que
PipeReadertenga acceso. - No llame a
FlushAsyncsi el lector no puede iniciarse hasta queFlushAsynctermine, ya que puede provocar un interbloqueo. - Asegúrese de que solo un contexto "posee"
PipeReaderoPipeWritero accede a ellos. Estos tipos no son seguros para subprocesos. - Nunca acceda a ReadResult.Buffer después de llamar a
AdvanceToo completarPipeReader.
IDuplexPipe
IDuplexPipe es un contrato para los tipos que admiten la lectura y la escritura. Por ejemplo, una conexión de red se representará mediante un elemento IDuplexPipe.
A diferencia de Pipe, que contiene un elemento PipeReader y otro elemento PipeWriter, IDuplexPipe representa un solo lado de una conexión de dúplex completo. Esto significa que lo que se escribe en PipeWriter no se leerá desde PipeReader.
Secuencias
Al leer o escribir datos de secuencia, normalmente se leen los datos mediante un deserializador y se escriben mediante un serializador. La mayoría de estas API de secuencias de lectura y escritura tienen un parámetro Stream. Para facilitar la integración con estas API existentes, PipeReader y PipeWriter exponen un método AsStream. AsStream devuelve una implementación de Stream en torno a PipeReader o PipeWriter.
Ejemplos de secuencias
Las instancias de PipeReader y PipeWriter se pueden crear mediante los métodos Create estáticos dado un objeto Stream y las opciones de creación correspondientes.
StreamPipeReaderOptions permite el control sobre la creación de la instancia de PipeReader con los parámetros siguientes:
- StreamPipeReaderOptions.BufferSize es el tamaño de búfer mínimo en bytes que se usa al alquilar memoria del grupo y su valor predeterminado es
4096. - La marca StreamPipeReaderOptions.LeaveOpen determina si el flujo subyacente se deja abierto una vez finalizada la instancia de
PipeReadery se establece de forma predeterminada enfalse. - StreamPipeReaderOptions.MinimumReadSize representa el umbral de bytes restantes en el búfer antes de que se asigne un nuevo búfer y su valor predeterminado es
1024. - StreamPipeReaderOptions.Pool es el elemento
MemoryPool<byte>que se usa al asignar memoria y el valor predeterminado esnull.
StreamPipeWriterOptions permite el control sobre la creación de la instancia de PipeWriter con los parámetros siguientes:
- La marca StreamPipeWriterOptions.LeaveOpen determina si el flujo subyacente se deja abierto una vez finalizada la instancia de
PipeWritery se establece de forma predeterminada enfalse. - StreamPipeWriterOptions.MinimumBufferSize representa el tamaño de búfer mínimo que se va a usar al alquilar memoria de Pool y su valor predeterminado es
4096. - StreamPipeWriterOptions.Pool es el elemento
MemoryPool<byte>que se usa al asignar memoria y el valor predeterminado esnull.
Importante
Al crear instancias de PipeReader y PipeWriter mediante los métodos Create, debe tener en cuenta la duración del objeto Stream. Si necesita tener acceso al flujo después de que el lector o el escritor hayan terminado con él, debe establecer la marca LeaveOpen en true en las opciones de creación. De lo contrario, el flujo se cerrará.
En el código siguiente se muestra la creación de instancias de PipeReader y PipeWriter mediante los métodos Create de un flujo.
using System.Buffers;
using System.IO.Pipelines;
using System.Text;
class Program
{
static async Task Main()
{
using var stream = File.OpenRead("lorem-ipsum.txt");
var reader = PipeReader.Create(stream);
var writer = PipeWriter.Create(
Console.OpenStandardOutput(),
new StreamPipeWriterOptions(leaveOpen: true));
WriteUserCancellationPrompt();
var processMessagesTask = ProcessMessagesAsync(reader, writer);
var userCanceled = false;
var cancelProcessingTask = Task.Run(() =>
{
while (char.ToUpperInvariant(Console.ReadKey().KeyChar) != 'C')
{
WriteUserCancellationPrompt();
}
userCanceled = true;
// No exceptions thrown
reader.CancelPendingRead();
writer.CancelPendingFlush();
});
await Task.WhenAny(cancelProcessingTask, processMessagesTask);
Console.WriteLine(
$"\n\nProcessing {(userCanceled ? "cancelled" : "completed")}.\n");
}
static void WriteUserCancellationPrompt() =>
Console.WriteLine("Press 'C' to cancel processing...\n");
static async Task ProcessMessagesAsync(
PipeReader reader,
PipeWriter writer)
{
try
{
while (true)
{
ReadResult readResult = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = readResult.Buffer;
try
{
if (readResult.IsCanceled)
{
break;
}
if (TryParseLines(ref buffer, out string message))
{
FlushResult flushResult =
await WriteMessagesAsync(writer, message);
if (flushResult.IsCanceled || flushResult.IsCompleted)
{
break;
}
}
if (readResult.IsCompleted)
{
if (!buffer.IsEmpty)
{
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
catch (Exception ex)
{
Console.Error.WriteLine(ex);
}
finally
{
await reader.CompleteAsync();
await writer.CompleteAsync();
}
}
static bool TryParseLines(
ref ReadOnlySequence<byte> buffer,
out string message)
{
SequencePosition? position;
StringBuilder outputMessage = new();
while(true)
{
position = buffer.PositionOf((byte)'\n');
if (!position.HasValue)
break;
outputMessage.Append(Encoding.ASCII.GetString(buffer.Slice(buffer.Start, position.Value)))
.AppendLine();
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
};
message = outputMessage.ToString();
return message.Length != 0;
}
static ValueTask<FlushResult> WriteMessagesAsync(
PipeWriter writer,
string message) =>
writer.WriteAsync(Encoding.ASCII.GetBytes(message));
}
La aplicación usa StreamReader para leer el archivo lorem-ipsum.txt como una secuencia y debe terminar con una línea en blanco. FileStream se pasa a PipeReader.Create, que crea una instancia de un objeto PipeReader. Después, la aplicación de consola pasa su flujo de salida estándar a PipeWriter.Create mediante Console.OpenStandardOutput(). El ejemplo admite la cancelación.