Controlar errores parciales
Sugerencia
Este contenido es un extracto del libro electrónico, ".NET Microservices Architecture for Containerized .NET Applications" (Arquitectura de microservicios de .NET para aplicaciones de .NET contenedorizadas), disponible en Documentación de .NET o como un PDF descargable y gratuito que se puede leer sin conexión.

En sistemas distribuidos como las aplicaciones basadas en microservicios, hay un riesgo siempre presente de error parcial. Por ejemplo, se puede producir un error en un único contenedor o microservicio o este podría no estar disponible para responder durante un breve período, o se podría bloquear una única máquina virtual o un servidor. Puesto que los clientes y los servicios son procesos independientes, es posible que un servicio no pueda responder de forma oportuna a una solicitud del cliente. Es posible que el servicio esté sobrecargado y responda muy lentamente a las solicitudes, o bien que simplemente no sea accesible durante un breve período debido a problemas de red.
Por ejemplo, considere la página de detalles Order de la aplicación de ejemplo eShopOnContainers. Si el microservicio Ordering no responde cuando el usuario intenta enviar un pedido, una implementación incorrecta del proceso del cliente (la aplicación web MVC), por ejemplo, si el código de cliente usara RPC sincrónicas sin tiempo de espera, bloquearía los subprocesos indefinidamente en espera de una respuesta. Además de la mala experiencia del usuario, cada espera sin respuesta usa o bloquea un subproceso, y los subprocesos son muy valiosos en aplicaciones altamente escalables. Si hay muchos subprocesos bloqueados, al final el tiempo de ejecución de la aplicación puede quedarse sin subprocesos. En ese caso, la aplicación puede no responder globalmente en lugar de solo parcialmente, como se muestra en la figura 8-1.
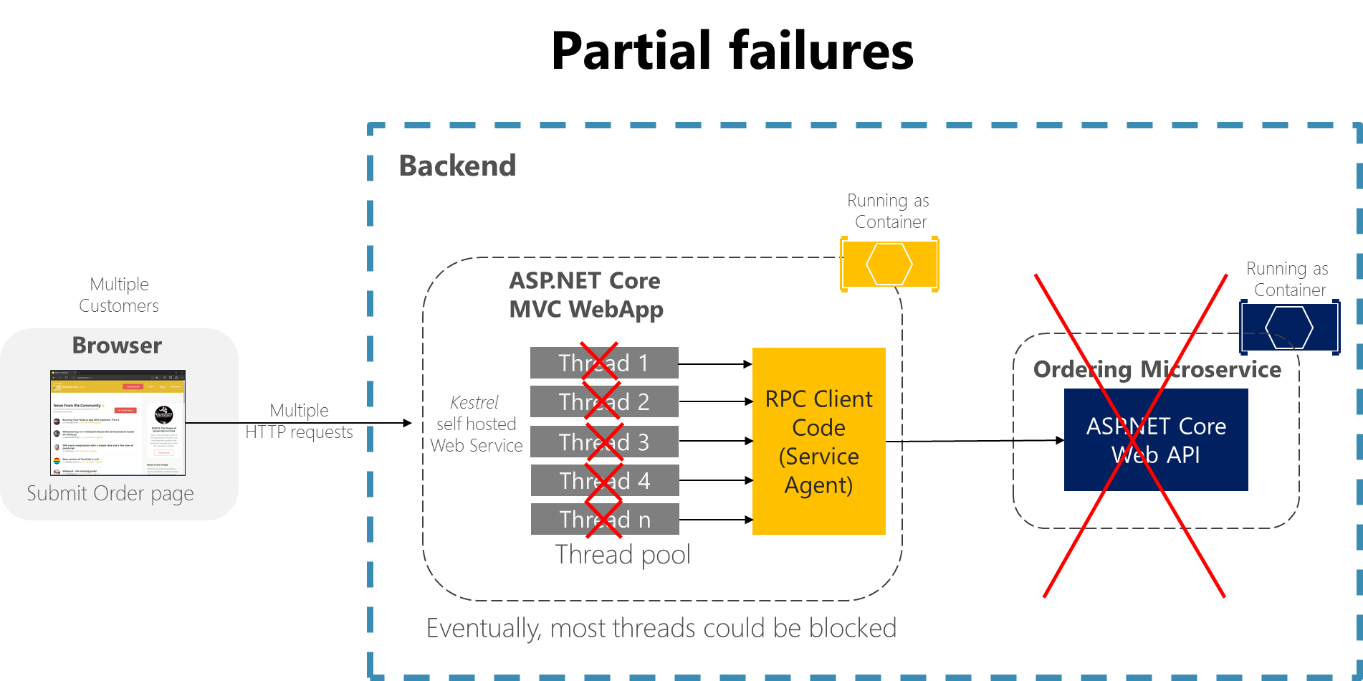
Figura 8-1. Errores parciales debido a dependencias que afectan a la disponibilidad del subproceso de servicio
En una aplicación basada en microservicios de gran tamaño, cualquier error parcial se puede amplificar, especialmente si la mayor parte de la interacción de los microservicios internos se basa en llamadas HTTP sincrónicas (lo que se considera un anti-patrón). Piense en un sistema que recibe millones de llamadas entrantes al día. Si el sistema tiene un diseño incorrecto basado en cadenas largas de llamadas HTTP sincrónicas, estas llamadas entrantes podrían dar lugar a muchos más millones de llamadas salientes (supongamos una proporción 1:4) a decenas de microservicios internos como dependencias sincrónicas. Esta situación se muestra en la figura 8-2, especialmente la dependencia 3, que inicia una cadena, que llama a la dependencia 4, que, a su vez, llama a la dependencia 5.
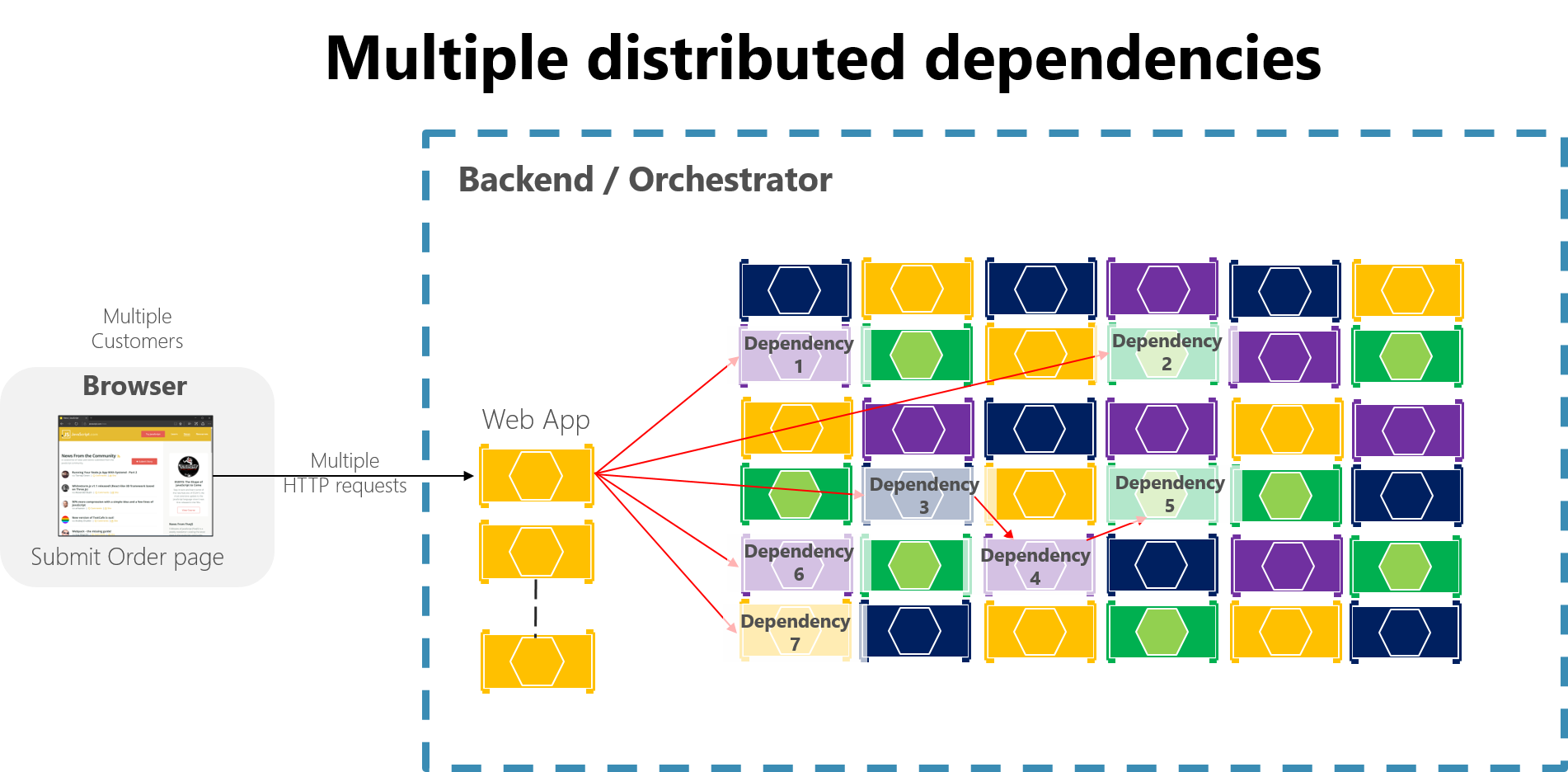
Figura 8-2. Impacto de tener un diseño incorrecto que incluye cadenas largas de solicitudes HTTP
Los errores intermitentes están garantizados en un sistema distribuido basado en la nube, aunque cada dependencia tenga una disponibilidad excelente. Es un hecho que se debe tener en cuenta.
Si no diseña ni implementa técnicas para asegurar la tolerancia a errores, incluso se pueden magnificar los pequeños tiempos de inactividad. Por ejemplo, 50 dependencias con un 99,99 % de disponibilidad cada una darían lugar a varias horas de tiempo de inactividad al mes debido a este efecto dominó. Cuando se produce un error en una dependencia de un microservicio al controlar un gran volumen de solicitudes, ese error puede saturar rápidamente todos los subprocesos de solicitudes disponibles en cada servicio y bloquear toda la aplicación.
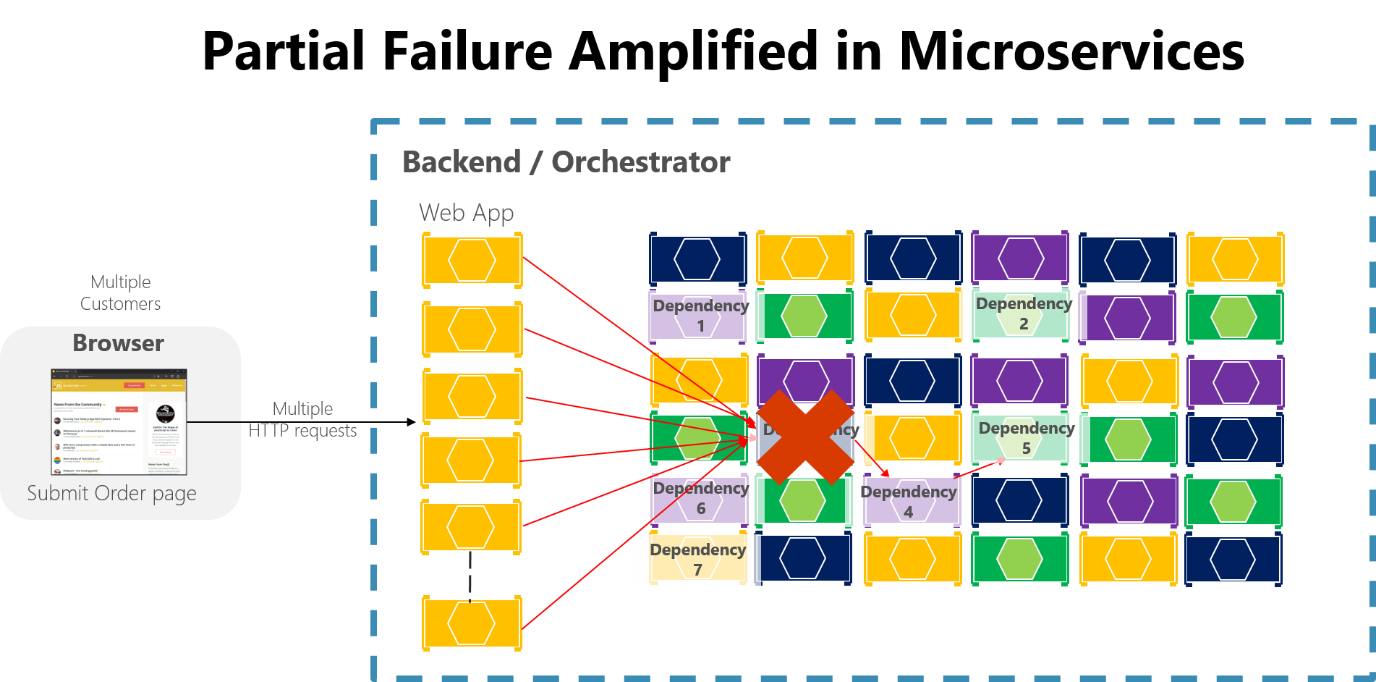
Figura 8-3. Error parcial amplificado por los microservicios con cadenas largas de llamadas HTTP sincrónicas
Para minimizar este problema, en la sección La integración asincrónica del microservicio obliga a su autonomía, esta guía recomienda usar la comunicación asincrónica entre los microservicios internos.
Además, es fundamental que diseñe las aplicaciones cliente y los microservicios para controlar los errores parciales, es decir, que compile microservicios y aplicaciones cliente resistentes.