Administración de estado y datos en aplicaciones de Docker
Sugerencia
Este contenido es un extracto del libro electrónico, ".NET Microservices Architecture for Containerized .NET Applications" (Arquitectura de microservicios de .NET para aplicaciones de .NET contenedorizadas), disponible en Documentación de .NET o como un PDF descargable y gratuito que se puede leer sin conexión.

En la mayoría de los casos, un contenedor se puede considerar como una instancia de un proceso. Un proceso no mantiene un estado persistente. Si bien un contenedor puede escribir en su almacenamiento local, suponer que una instancia permanecerá indefinidamente sería como suponer que una sola ubicación en memoria será duradera. Debe suponer que las imágenes de contenedor, como los procesos, tienen varias instancias o finalmente se terminarán. Si se administran con un orquestador de contenedores, debe suponer que podrían desplazarse de un nodo o máquina virtual a otro.
Las soluciones siguientes se usan para administrar datos en aplicaciones de Docker:
Desde el host de Docker, como volúmenes de Docker:
Los volúmenes se almacenan en un área del sistema de archivos de host administrado por Docker.
Los montajes de enlace pueden asignar cualquier carpeta en el sistema de archivos de host, por lo que el acceso no se puede controlar desde el proceso de Docker y puede suponer un riesgo de seguridad ya que un contenedor podría acceder a carpetas del sistema operativo confidenciales.
Los montajes tmpfs son como carpetas virtuales que solo existen en la memoria del host y nunca se escriben en el sistema de archivos.
Desde el almacenamiento remoto:
Azure Storage, que proporciona almacenamiento con distribución geográfica y representa una buena solución de persistencia a largo plazo para los contenedores.
Bases de datos relacionales remotas como Azure SQL Database, bases de datos NoSQL como Azure Cosmos DB o servicios de caché como Redis.
Desde el contenedor de Docker:
- Superposición del sistema de archivos. Esta característica de Docker implementa una tarea de copia en escritura que almacena información actualizada en el sistema de archivos raíz del contenedor. Esa información se coloca "encima" de la imagen original en la que se basa el contenedor. Si se elimina el contenedor del sistema, estos cambios se pierden. Por tanto, si bien es posible guardar el estado de un contenedor dentro de su almacenamiento local, diseñar un sistema sobre esta base entraría en conflicto con la idea del diseño del contenedor, que de manera predeterminada es sin estado.
Sin embargo, el uso de los volúmenes de Docker es ahora la mejor manera de controlar datos locales en Docker. Si necesita obtener más información sobre el almacenamiento en contenedores, consulte Docker storage drivers (Controladores de almacenamiento de Docker) y About storage drivers (Sobre los controladores de almacenamiento).
Los siguientes puntos proporcionan más información sobre estas opciones:
Los volúmenes son directorios asignados desde el sistema operativo del host a directorios en contenedores. Cuando el código en el contenedor tiene acceso al directorio, ese acceso es realmente a un directorio en el sistema operativo del host. Este directorio no está asociado a la duración del contenedor y Docker lo administra y aísla de la funcionalidad básica de la máquina host. Por tanto, los volúmenes de datos están diseñados para conservar los datos independientemente de la vida del contenedor. Si elimina un contenedor o una imagen del host de Docker, los datos que se conservan en el volumen de datos no se eliminan.
Los volúmenes pueden tener nombre o ser anónimos (predeterminado). Los volúmenes con nombre son la evolución de los Contenedores de volúmenes de datos y facilitan el uso compartido de datos entre contenedores. Los volúmenes también admiten controladores de volumen, que le permiten almacenar datos en hosts remotos, entre otras opciones.
Los montajes de enlace están disponibles desde hace mucho tiempo y permiten la asignación de cualquier carpeta a un punto de montaje en un contenedor. Los montajes de enlace tienen más limitaciones que los volúmenes y algunos problemas de seguridad importantes, por lo que los volúmenes son la opción recomendada.
Los montajes tmpfs son básicamente carpetas virtuales que solo existen en la memoria del host y nunca se escriben en el sistema de archivos. Son rápidos y seguros, pero usan memoria y solo están diseñados para datos temporales y no persistentes.
Tal como se muestra en la figura 4-5, los volúmenes de Docker normales pueden almacenarse fuera de los propios contenedores, pero dentro de los límites físicos del servidor de host o de la máquina virtual. Pero los contenedores de Docker no pueden acceder a un volumen desde un servidor de host o máquina virtual a otro. En otras palabras, con estos volúmenes, no es posible administrar los datos que se comparten entre contenedores que se ejecutan en otros hosts de Docker, aunque se podría lograr con un controlador de volumen que sea compatible con los hosts remotos.
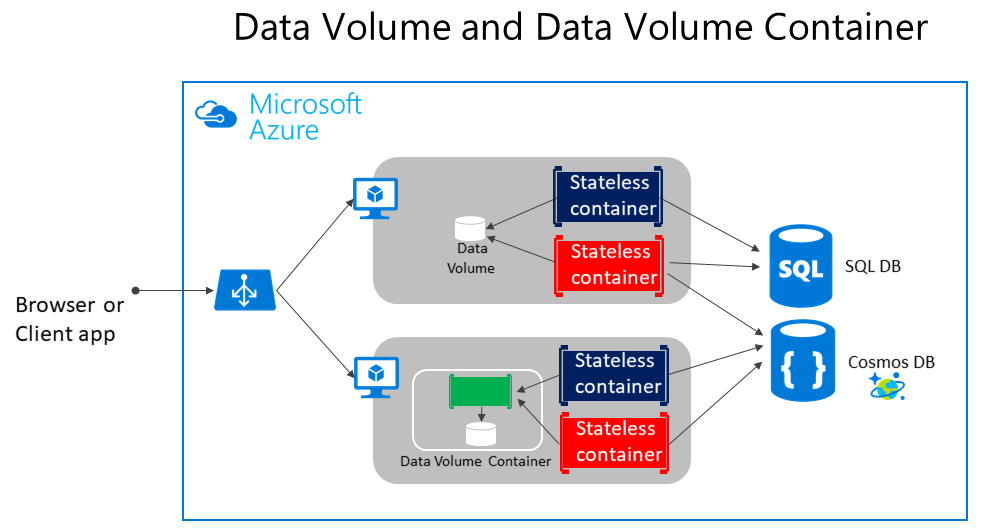
Figura 4-5. Volúmenes y orígenes de datos externos para aplicaciones basadas en contenedor
Los volúmenes se pueden compartir entre contenedores, pero solo en el mismo host, a menos que use un controlador remoto compatible con hosts remotos. Además, cuando un orquestador administra los contenedores de Docker, estos podrían "moverse" entre hosts, según las optimizaciones que el clúster realice. Por tanto, no se recomienda usar volúmenes de datos para los datos empresariales. Pero son un buen mecanismo para trabajar con archivos de seguimiento, archivos temporales o similares que no afectarán a la coherencia de los datos empresariales.
Las herramientas de orígenes de datos remotos y caché como Azure SQL Database, Azure Cosmos DB o una caché remota como Redis pueden usarse en aplicaciones en contenedores del mismo modo que se usan al desarrollar sin contenedores. Se trata de una manera comprobada para almacenar datos de aplicaciones empresariales.
Azure Storage. Normalmente, los datos empresariales deben colocarse en recursos o bases de datos externos, como Azure Storage. Azure Storage, en concreto, proporciona los siguientes servicios en la nube:
Blob Storage almacena datos de objetos no estructurados. Un blob puede ser cualquier tipo de texto o datos binarios, como documentos o archivos multimedia (archivos de imagen, audio y vídeo). El almacenamiento de blobs a veces se conoce también como almacenamiento de objetos.
El almacenamiento de archivos ofrece almacenamiento compartido para aplicaciones heredadas mediante el protocolo SMB estándar. Las máquinas virtuales de Azure y los servicios en la nube pueden compartir datos de archivos en los componentes de la aplicación a través de recursos compartidos montados. Las aplicaciones locales pueden tener acceso a datos de archivos en un recurso compartido a través de la API de REST de servicio de archivos.
El almacenamiento de tablas almacena conjuntos de datos estructurados. El almacenamiento de tabla es un almacén de datos del atributo de clave NoSQL, lo que permite desarrollar y acceder rápidamente a grandes cantidades de datos.
Bases de datos relacionales y bases de datos NoSQL. Hay muchas opciones para bases de datos externas, desde bases de datos relacionales como SQL Server, PostgreSQL u Oracle hasta bases de datos NoSQL como Azure Cosmos DB, MongoDB, etc. Estas bases de datos no se van a explicar en esta guía porque pertenecen a un tema completamente diferente.