Inteligencia artificial responsable en cargas de trabajo de Azure
El objetivo de la inteligencia artificial responsable en el diseño de la carga de trabajo es garantizar que el uso de algoritmos de IA sea justo, transparente e inclusivo. Los principios de seguridad bien diseñados están relacionados con un enfoque en la confidencialidad y la integridad. Las medidas de seguridad deben aplicarse para mantener la privacidad del usuario, proteger los datos y proteger la integridad del diseño, que no debe usarse incorrectamente con fines no deseados.
En las cargas de trabajo de IA, los modelos toman decisiones que suelen usar lógica opaca. Los usuarios deben confiar en la funcionalidad del sistema y sentirse seguros de que las decisiones se toman de forma responsable. Se deben evitar comportamientos no éticos, como la manipulación, la toxicidad del contenido, la infracción de la propiedad intelectual y las respuestas fabricadas.
Considere un caso de uso en el que una empresa de entretenimiento multimedia quiere proporcionar recomendaciones mediante modelos de IA. Si no se implementa la inteligencia artificial responsable y la seguridad adecuada, un actor incorrecto puede tomar el control de los modelos. El modelo puede recomendar contenido multimedia que pueda dar lugar a resultados perjudiciales. Para la organización, este comportamiento puede provocar daños en la marca, entornos no seguros y problemas legales. Por lo tanto, mantener la vigilancia ética a lo largo del ciclo de vida del sistema es esencial y no negociable.
Las decisiones éticas deben priorizar la seguridad y la administración de cargas de trabajo teniendo en cuenta los resultados humanos. Familiarícese con el marco de inteligencia artificial responsable de Microsoft y asegúrese de que los principios se reflejan y miden en el diseño. En esta imagen se muestran los conceptos básicos del marco de trabajo.
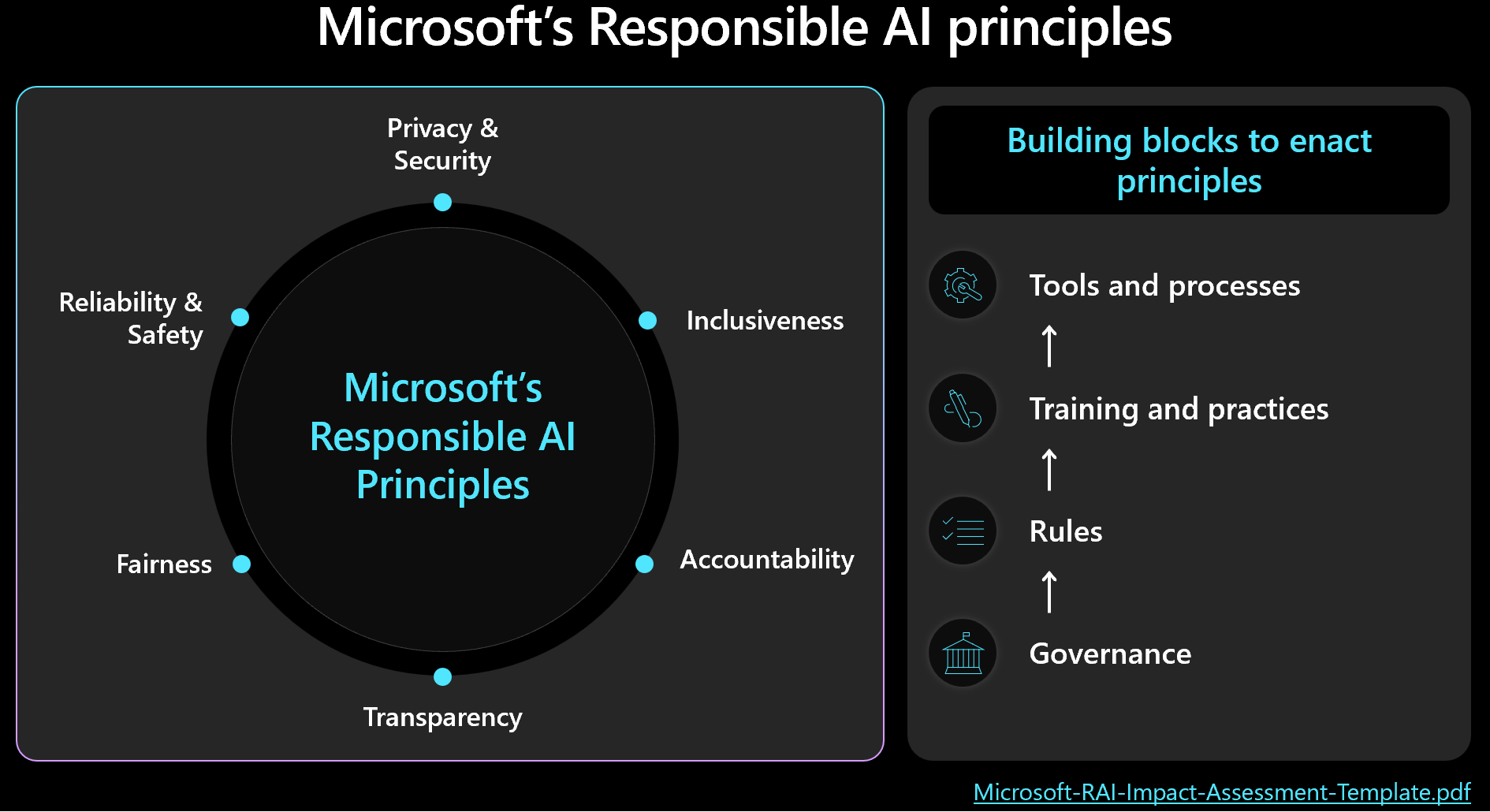
Importante
La precisión de la predicción y las métricas de IA responsable suelen estar interconectadas. Mejorar la precisión de un modelo puede mejorar su equidad y alineación con la realidad. Sin embargo, aunque la inteligencia artificial ética se alinea con frecuencia con precisión, la precisión por sí sola no incluye todas las consideraciones éticas. Es fundamental validar estos principios éticos de forma responsable.
En este artículo se proporcionan recomendaciones sobre la toma de decisiones éticas, la validación de la entrada del usuario y la garantía de una experiencia de usuario segura. También proporciona instrucciones sobre la seguridad de los datos para asegurarse de que los datos de usuario están protegidos.
Recomendaciones
Este es el resumen de las recomendaciones proporcionadas en este artículo.
| Recomendación | Descripción |
|---|---|
| Desarrolle directivas que apliquen prácticas éticas en cada fase del ciclo de vida. | Incluya elementos de lista de comprobación que indiquen explícitamente los requisitos éticos, adaptados al contexto de la carga de trabajo. Entre los ejemplos se incluyen la transparencia de los datos del usuario, la configuración del consentimiento y los procedimientos para controlar el "Derecho a olvidar". ▪ Desarrollo de las directivas de inteligencia artificial responsable ▪ Aplicación de la gobernanza en las directivas de inteligencia artificial responsable |
| Proteja los datos de usuario con el objetivo de maximizar la privacidad. | Recopile solo lo necesario y con el consentimiento adecuado del usuario. Aplique controles técnicos para proteger los perfiles de usuario, sus datos y el acceso a esos datos. ▪ Control de los datos de usuario de forma ética ▪ Inspección de los datos entrantes y salientes |
| Mantenga claras y comprensibles las decisiones de inteligencia artificial. | Mantenga explicaciones claras sobre cómo funcionan los algoritmos de recomendación y ofrezca a los usuarios información sobre el uso de datos y la toma de decisiones algorítmicas para asegurarse de que comprenden y confían en el proceso. ▪ Hacer que la experiencia del usuario sea segura |
Desarrollo de directivas de IA responsables
Documente su enfoque para el uso ético y responsable de la inteligencia artificial. Las directivas de estado explícitamente aplicadas en cada fase del ciclo de vida para que el equipo de carga de trabajo comprenda sus responsabilidades. Aunque los estándares de inteligencia artificial responsable de Microsoft proporcionan directrices, debe definir lo que significan específicamente para su contexto.
Por ejemplo, las directivas deben incluir elementos de lista de comprobación para los mecanismos en torno a la transparencia de los datos de usuario y la configuración de consentimiento, lo que idealmente permite a los usuarios no participar en la inclusión de datos. Las canalizaciones de datos, el análisis, el entrenamiento del modelo y otras fases deben respetar esa opción. Otro ejemplo es procedimientos para controlar el "Derecho a olvidar". Consulte al departamento de ética de su organización y al equipo legal para tomar decisiones informadas.
Cree directivas transparentes sobre el uso de datos y la toma de decisiones algorítmicas para garantizar que los usuarios comprendan y confíen en el proceso. Documente estas decisiones para mantener un historial claro para posibles litigios futuros.
La implementación de inteligencia artificial ética implica tres roles clave: el equipo de investigación, el equipo de directivas y el equipo de ingeniería. La colaboración entre estos equipos debe estar operativa. Si su organización tiene un equipo existente, aproveche su trabajo; De lo contrario, establezca estas prácticas usted mismo.
Tener responsabilidades en la separación de obligaciones:
El equipo de investigación lleva a cabo la detección de riesgos mediante la consultoría de directrices organizativas, estándares del sector, leyes, normativas y tácticas conocidas del equipo rojo.
El equipo de directivas desarrolla directivas específicas de la carga de trabajo, incorporando directrices de la organización principal y las regulaciones gubernamentales.
El equipo de ingeniería implementa las directivas en sus procesos y entregas, lo que garantiza que validan y prueban el cumplimiento.
Cada equipo formaliza sus directrices, pero el equipo de cargas de trabajo debe ser responsable de sus propias prácticas documentadas. El equipo debe documentar claramente los pasos adicionales o desviaciones intencionadas, asegurándose de que no hay ambigüedad sobre lo que se permite. Además, sea transparente sobre las posibles deficiencias o resultados inesperados en la solución.
Aplicación de la gobernanza en las directivas de inteligencia artificial responsable
Diseñe la carga de trabajo para cumplir con la gobernanza organizativa y normativa. Por ejemplo, si la transparencia es un requisito organizativo, determine cómo se aplica a la carga de trabajo. Identifique las áreas del diseño, el ciclo de vida, el código u otros componentes, donde se deben introducir características de transparencia para cumplir ese estándar.
Comprenda la gobernanza, la responsabilidad, los paneles de revisión y los mandatos de informes necesarios. Asegúrese de que el consejo de gobernanza apruebe y cierre los diseños de cargas de trabajo para evitar rediseños y mitigar los problemas éticos o de privacidad. Es posible que tenga que pasar por varias capas de aprobación. Esta es una estructura típica para la gobernanza.
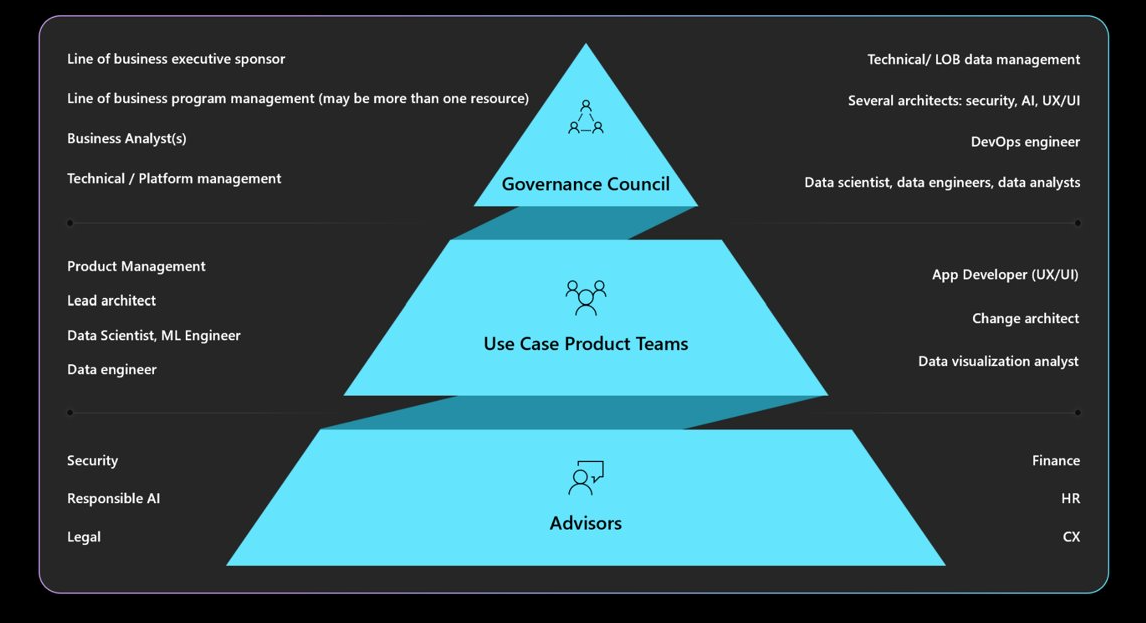
Para obtener información sobre las directivas y aprobadores de la organización, consulte Cloud Adoption Framework: Definición de una estrategia de inteligencia artificial responsable.
Hacer que la experiencia del usuario sea segura
Las experiencias de usuario deben basarse en las directrices del sector. Aproveche las ventajas de la Biblioteca de diseño de experiencias de inteligencia artificial humana de Microsoft que incluye principios y proporciona acciones de implementación y no, con ejemplos de productos de Microsoft y otros orígenes del sector.
Hay responsabilidades de carga de trabajo durante todo el ciclo de vida de la interacción del usuario a partir de la intención del usuario de usar el sistema, durante una sesión e interrupciones debido a errores del sistema. Estos son algunos procedimientos que se deben tener en cuenta:
Transparencia de compilación. Haga que los usuarios sepan cómo el sistema generó la respuesta a su consulta.
Incluya vínculos a orígenes de datos consultados por el modelo para predicciones para mejorar la confianza del usuario mostrando los orígenes de la información. El diseño de datos debe asegurarse de que estos orígenes se incluyen en los metadatos. Cuando el orquestador de una aplicación aumentada de recuperación realiza una búsqueda, recupera, por ejemplo, 20 fragmentos de documento y envía los 10 fragmentos principales, que pertenecen a tres documentos diferentes, al modelo como contexto. A continuación, la interfaz de usuario puede hacer referencia a estos tres documentos de origen al mostrar la respuesta del modelo, lo que mejora la transparencia y la confianza del usuario.
La transparencia es más importante cuando se usan agentes, que actúan como intermediarios entre interfaces front-end y sistemas back-end. Por ejemplo, en un sistema de vales, el código de orquestación interpreta la intención del usuario y realiza llamadas API a agentes para recuperar la información necesaria. Exponer estas interacciones puede hacer que el usuario sea consciente de las acciones del sistema.
Para flujos de trabajo automatizados con varios agentes implicados, cree archivos de registro que registren cada paso. Esta funcionalidad ayuda a identificar y corregir errores. Además, puede proporcionar a los usuarios explicaciones sobre las decisiones, que operacionalizan la transparencia.
Precaución
Al implementar recomendaciones de transparencia, evite sobrecargar al usuario con demasiada información. Use un enfoque gradual, donde empiece con métodos de interfaz de usuario mínimamente disruptivos.
Por ejemplo, muestre una información sobre herramientas con una puntuación de confianza del modelo. Puede incorporar un vínculo en el que los usuarios pueden hacer clic para obtener más detalles, como vínculos a documentos de origen. Este método iniciado por el usuario mantiene la interfaz de usuario no disruptiva y permite a los usuarios buscar información adicional solo si eligen.
Recopila comentarios. Implemente mecanismos de comentarios.
Evite sobrecargar a los usuarios con cuestionarios extensos después de cada respuesta. En su lugar, use mecanismos de comentarios sencillos y rápidos, como pulgares hacia arriba y abajo, o sistemas de clasificación para aspectos específicos de la respuesta en una escala de 1 a 5. Este método permite comentarios pormenorizados sin ser intrusivos, lo que ayuda a mejorar el sistema a lo largo del tiempo. Tenga en cuenta los posibles sesgos en los comentarios, ya que puede haber razones secundarias detrás de las respuestas del usuario.
La implementación de un mecanismo de comentarios afecta a la arquitectura debido a la necesidad de almacenamiento de datos. Trata esto como datos de usuario y aplica niveles de control de privacidad, según sea necesario.
Además de los comentarios de respuesta, recopile comentarios sobre la eficacia de la experiencia del usuario. Esto se puede hacer mediante la recopilación de métricas de involucración a través de la pila de supervisión del sistema.
Poner en marcha medidas de seguridad de contenido
Integre la seguridad del contenido en todas las fases del ciclo de vida de la inteligencia artificial mediante código de solución personalizado, herramientas adecuadas y prácticas de seguridad eficaces. Estas son algunas estrategias.
Anonimización de datos. A medida que los datos pasan de la ingesta a la formación o evaluación, tienen comprobaciones a lo largo del camino para minimizar el riesgo de pérdida de información personal y evitar la exposición de datos de usuario sin procesar.
Con modo carpa ration. Use la API de seguridad de contenido que evalúa las solicitudes y respuestas en tiempo real y asegúrese de que estas API son accesibles.
Identificar y mitigar amenazas. Aplique prácticas de seguridad conocidas a los escenarios de inteligencia artificial. Por ejemplo, realice el modelado de amenazas y documente amenazas y su mitigación. Los procedimientos de seguridad comunes, como los ejercicios del equipo rojo, se aplican a las cargas de trabajo de IA. Los equipos rojos pueden probar si los modelos se pueden manipular para generar contenido dañino. Estas actividades deben integrarse en las operaciones de inteligencia artificial.
Para obtener información sobre cómo realizar pruebas de equipo rojas, consulte Planning red teaming for large language models (LLMs) and their applications ( Planning red teaming for large language models (LLMs) and their applications (Planning red teaming for large language models (LLMs) and their applications(Planning red teaming for large language models (LLMs) and their applications.
Use las métricas adecuadas. Use las métricas adecuadas que sean eficaces para medir el comportamiento ético del modelo. Las métricas varían en función del tipo de modelo de IA. Es posible que la medición de modelos generativos no se aplique a los modelos de regresión. Considere un modelo que predice la esperanza de vida y los resultados afectan a las tasas de seguros. El sesgo en este modelo puede provocar problemas éticos, pero ese problema se deriva de la desviación en las pruebas de métricas principales. Mejorar la precisión puede reducir los problemas éticos, ya que las métricas éticas y de precisión suelen estar interconectadas.
Agregue instrumentación ética. Los resultados del modelo de IA deben explicarse. Debe justificar y realizar un seguimiento de cómo se realizan las inferencias, incluidos los datos usados para el entrenamiento, las características calculadas y los datos de base. En la inteligencia artificial discriminativa, puede justificar las decisiones paso a paso. Sin embargo, para los modelos generativos, la explicación de los resultados puede ser compleja. Documente el proceso de toma de decisiones para abordar posibles implicaciones legales y proporcionar transparencia.
Este aspecto de explicación debe implementarse durante todo el ciclo de vida de la inteligencia artificial. La limpieza de datos, el linaje, los criterios de selección y el procesamiento son fases críticas en las que se debe realizar un seguimiento de las decisiones.
Herramientas
Las herramientas para la seguridad del contenido y la rastreabilidad de datos, como Microsoft Purview, deben integrarse. Se puede llamar a las API de seguridad de contenido de Azure AI desde las pruebas para facilitar las pruebas de seguridad de contenido.
Azure AI Foundry proporciona métricas que evalúan el comportamiento del modelo. Para más información, consulte Métricas de evaluación y supervisión para la inteligencia artificial generativa.
Para los modelos de entrenamiento, se recomienda revisar las métricas proporcionadas por Azure Machine Learning.
Inspección de los datos entrantes y salientes
Los ataques por inyección de mensajes, como el jailbreaking, son una preocupación común para las cargas de trabajo de IA. En este caso, algunos usuarios pueden intentar usar el modelo con fines no deseados. Para garantizar la seguridad, inspeccione los datos para evitar ataques y filtrar el contenido inapropiado. Este análisis se debe aplicar tanto a la entrada del usuario como a las respuestas del sistema para asegurarse de que hay una con modo carpa ration exhaustiva en los flujos entrantes y salientes.
En escenarios en los que se realizan varias invocaciones de modelo, como a través de Azure OpenAI, para atender una sola solicitud de cliente, aplicar comprobaciones de seguridad de contenido a cada invocación puede ser costosa e innecesaria. Considere la posibilidad de centralizar ese trabajo en la arquitectura al tiempo que mantiene la seguridad como responsabilidad del lado servidor. Supongamos que una arquitectura tiene una puerta de enlace delante del punto de conexión de inferencia del modelo para descargar determinadas funcionalidades de back-end. Esa puerta de enlace se puede diseñar para controlar las comprobaciones de seguridad de contenido de las solicitudes y respuestas que el back-end puede no admitir de forma nativa. Aunque una puerta de enlace es una solución común, una capa de orquestación puede controlar estas tareas de forma eficaz en arquitecturas más sencillas. En ambos casos, puede aplicar de forma selectiva estas comprobaciones cuando sea necesario, optimizando el rendimiento y el costo.
Las inspecciones deben ser multimodales, que abarcan varios formatos. Cuando se usa la entrada multimodal, como las imágenes, es importante analizarlos para los mensajes ocultos que pueden ser perjudiciales o violentos. Es posible que estos mensajes no sean visibles inmediatamente, similares a la entrada de lápiz invisible y requieran una inspección cuidadosa. Use herramientas como las API de seguridad de contenido para este propósito.
Para aplicar directivas de privacidad y seguridad de datos, inspeccione los datos de usuario y los datos de base para el cumplimiento de las normativas de privacidad. Asegúrese de que los datos están saneados o filtrados a medida que fluyen a través del sistema. Por ejemplo, los datos de las conversaciones anteriores de soporte al cliente podrían servir como datos de base. Se debe sanear antes de reutilizarlo.
Control de los datos de usuario de forma ética
Las prácticas éticas implican un control cuidadoso de la administración de datos de usuario. Esto incluye saber cuándo usar datos y cuándo evitar confiar en los datos de usuario.
Inferencia sin compartir datos de usuario. Para compartir datos de usuario de forma segura con otras organizaciones para obtener información, use un modelo de centro de compensación. En este escenario, las organizaciones proporcionan datos a un tercero de confianza, que entrena un modelo mediante los datos agregados. A continuación, todas las instituciones pueden usar este modelo, lo que permite obtener información compartida sin exponer conjuntos de datos individuales. El objetivo es usar las funcionalidades de inferencia del modelo sin compartir datos de entrenamiento detallados.
Promover la diversidad y la inclusividad. Cuando se necesiten datos de usuario, use una amplia gama de datos, incluidos los géneros y creadores representados, para minimizar el sesgo. Implemente características que animen a los usuarios a explorar contenido nuevo y variado. Tenga una supervisión continua del uso y ajuste las recomendaciones para evitar la representación excesiva de cualquier tipo de contenido único.
Respetar el "Derecho a ser olvidado". Evite usar datos de usuario siempre que sea posible. Asegúrese de que el cumplimiento del "Derecho a olvidar" tenga medidas necesarias para asegurarse de que los datos de usuario se eliminan diligentemente.
Para garantizar el cumplimiento, puede haber solicitudes para quitar los datos de usuario del sistema. Para los modelos más pequeños, esto se puede lograr mediante el reentrenamiento con datos que excluyen información personal. Para los modelos más grandes, que pueden constar de varios modelos más pequeños y entrenados de forma independiente, el proceso es más complejo y el costo y el esfuerzo son significativos. Busque instrucciones legales y éticas sobre cómo controlar estas situaciones y asegúrese de que se incluye en la directiva de inteligencia artificial responsable, que se describe en Desarrollo de directivas de inteligencia artificial responsable.
Conservar de forma responsable. Cuando la eliminación de datos no es posible, obtenga consentimiento explícito del usuario para la recopilación de datos y proporcione directivas de privacidad claras. Recopile y conserve los datos solo cuando sea absolutamente necesario. Tener operaciones para quitar los datos de forma agresiva cuando ya no lo necesiten. Por ejemplo, borre el historial de chat tan pronto como sea práctico y anonimice los datos confidenciales antes de la retención. Asegúrese de que los métodos de cifrado avanzados se usan para estos datos en reposo.
Explicación de soporte técnico. Tomar decisiones de seguimiento en el sistema para admitir los requisitos de explicación. Desarrolle explicaciones claras sobre cómo funcionan los algoritmos de recomendación, ofreciendo a los usuarios información sobre por qué se recomienda contenido específico para ellos. El objetivo es garantizar que las cargas de trabajo de inteligencia artificial y sus resultados sean transparentes y justificables, detallando cómo se toman las decisiones, qué datos se usaron y cómo se entrenaron los modelos.
Cifrar los datos de usuario. Los datos de entrada se deben cifrar en cada fase de la canalización de procesamiento de datos desde el momento en que el usuario escribe los datos. Esto incluye los datos a medida que se mueven de un punto a otro, donde se almacenan y durante la inferencia, si es necesario. Equilibre la seguridad y la funcionalidad, pero tenga como objetivo mantener los datos privados a lo largo de su ciclo de vida.
Para obtener información sobre las técnicas de cifrado, consulte Diseño de aplicaciones.
Proporcionar controles de acceso sólidos. Varios tipos de identidades pueden acceder potencialmente a los datos de usuario. Implemente el control de acceso basado en rol (RBAC) para el plano de control y el plano de datos, que cubre la comunicación entre el usuario y el sistema al sistema.
Mantenga también la segmentación de usuarios adecuada para proteger la privacidad. Por ejemplo, Copilot para Microsoft 365 puede buscar y proporcionar respuestas basadas en los documentos y correos electrónicos específicos de un usuario, asegurándose de que solo se tiene acceso al contenido relevante para ese usuario.
Para obtener información sobre cómo aplicar controles de acceso, consulte Diseño de aplicaciones.
Reducir el área expuesta. Una estrategia fundamental del pilar De seguridad del marco bien diseñado es minimizar la superficie expuesta a ataques y proteger los recursos. Esta estrategia se debe aplicar a los procedimientos de seguridad de los puntos de conexión estándar controlando estrechamente los puntos de conexión de API, exponiendo solo los datos esenciales y evitando información extraña en las respuestas. La elección del diseño debe equilibrarse entre flexibilidad y control.
Asegúrese de que no haya ningún punto de conexión anónimo. En general, evite proporcionar a los clientes más control de lo necesario. En la mayoría de los escenarios, los clientes no necesitan ajustar hiperparámetros, excepto en entornos experimentales. Para casos de uso típicos, como interactuar con un agente virtual, los clientes solo deben controlar aspectos esenciales para garantizar la seguridad limitando el control innecesario.
Para obtener información, consulte Diseño de aplicaciones.