Conector del grupo de SQL dedicado de Azure Synapse para Apache Spark
Introducción
El conector del grupo de SQL dedicado de Azure Synapse para Apache Spark en Azure Synapse Analytics permite la transferencia eficaz de conjuntos de datos de gran volumen entre el tiempo de ejecución de Apache Spark y el grupo de SQL dedicado. El conector se incluye como una biblioteca predeterminada con el área de trabajo de Azure Synapse. El conector se implementa mediante el lenguaje Scala. El conector admite Scala y Python. Para usar el conector con otras opciones de lenguaje de cuaderno, use el comando magic %%spark de Spark.
En líneas generales, el conector ofrece las funcionalidades siguientes:
- Lectura del grupo de SQL dedicado de Azure Synapse:
- Lectura de grandes conjuntos de datos de vistas y tablas de grupos de SQL dedicados de Synapse (internas y externas).
- Compatibilidad completa con la inserción de predicados, donde los filtros de DataFrame se asignan a la inserción de predicado SQL correspondiente.
- Compatibilidad con la eliminación de columnas.
- Compatibilidad con la inserción de consultas.
- Escritura en el grupo de SQL dedicado de Azure Synapse:
- Ingesta de datos de gran volumen en tipos de tabla internos y externos.
- Compatibilidad con las siguientes preferencias de modo de guardado de DataFrame:
AppendErrorIfExistsIgnoreOverwrite
- Escritura en el tipo de tabla externa compatible con el formato de archivo de texto delimitado y Parquet (por ejemplo, CSV).
- Para escribir datos en tablas internas, el conector usa ahora una instrucción COPY en lugar del enfoque CETAS/CTAS.
- Mejoras para optimizar el rendimiento de la escritura de un extremo a otro.
- Introducción de un manipulador de devolución de llamada opcional (argumento de función de Scala) que los clientes pueden usar para recibir métricas posteriores a la escritura.
- Algunos ejemplos incluyen el número de registros, la duración para completar una determinada acción, así como el motivo del error.
Enfoque de orquestación
Lectura
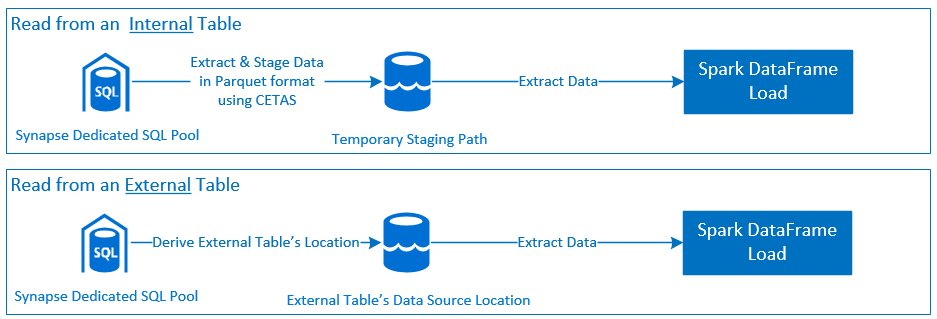
Escritura
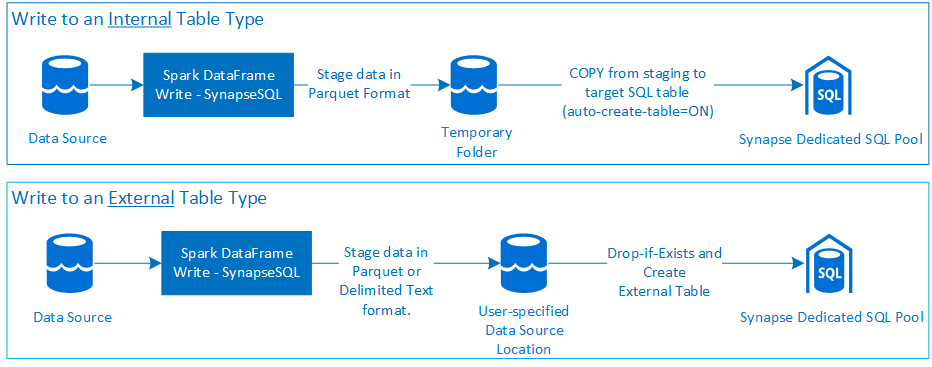
Requisitos previos
En esta sección, se describen los requisitos previos, como la configuración de los recursos de Azure necesarios y los pasos para configurarlos.
Recursos de Azure
Revise y configure los siguientes recursos dependientes de Azure:
- Azure Data Lake Storage: se usa como cuenta de almacenamiento principal para el área de trabajo de Azure Synapse.
- Área de trabajo de Azure Synapse: cree cuadernos, compile e implemente flujos de trabajo de entrada-salida basados en DataFrame.
- Grupo de SQL dedicado (anteriormente SQL DW) para el almacenamiento de datos empresariales.
- Grupo de Spark sin servidor de Azure Synapse: entorno de ejecución de Spark donde los trabajos se ejecutan como aplicaciones de Spark.
Preparación de la base de datos
Conéctese a la base de datos del grupo de SQL dedicado de Synapse y ejecute las siguientes instrucciones de configuración:
Cree un usuario de base de datos asignado a la identidad de usuario de Microsoft Entra (Azure AD) que se usa para iniciar sesión en el área de trabajo de Azure Synapse.
CREATE USER [username@domain.com] FROM EXTERNAL PROVIDER;Cree un esquema en el que se definirán las tablas para que el conector pueda escribir y leer correctamente las tablas respectivas.
CREATE SCHEMA [<schema_name>];
Autenticación
Autenticación basada en Microsoft Entra ID
La autenticación basada en Microsoft Entra ID es un enfoque de autenticación integrada. El usuario debe iniciar sesión correctamente en el área de trabajo de Azure Synapse Analytics.
Autenticación básica
El enfoque de autenticación básica requiere que el usuario configure las opciones username y password. Consulte la sección: Opciones de configuración para más información sobre los parámetros de configuración pertinentes para leer y escribir en tablas en el grupo de SQL dedicado de Azure Synapse.
Authorization
Azure Data Lake Storage Gen2
Hay dos maneras de conceder permisos de acceso a Azure Data Lake Storage Gen2, cuenta de almacenamiento:
- Rol de control de acceso basado en roles: Colaborador de datos de blobs de almacenamiento
- La asignación de
Storage Blob Data Contributor Roleconcede al usuario permisos de lectura, escritura y eliminación en los contenedores de blobs de Azure Storage. - RBAC ofrece un enfoque de control general en el nivel de contenedor.
- La asignación de
-
Listas de control de acceso (ACL)
- El enfoque de ACL permite controles específicos de rutas de acceso o archivos específicos en una carpeta determinada.
- Las comprobaciones de ACL no se aplican si el usuario ya tiene permisos concedidos mediante el enfoque RBAC.
- Existen dos tipos de permisos de ACL:
- Permisos de acceso (se aplican en un nivel u objeto específicos).
- Permisos predeterminados (se aplican automáticamente para todos los objetos secundarios en el momento de su creación).
- Los tipos de permisos incluyen:
-
Executepermite recorrer o navegar por las jerarquías de carpetas. -
Readpermite la lectura. -
Writepermite la escritura.
-
- Es importante configurar las ACL para que el conector pueda escribir y escribir y leer correctamente desde las ubicaciones de almacenamiento.
Nota
Si desea ejecutar cuadernos mediante canalizaciones del área de trabajo de Synapse, también debe conceder permisos de acceso enumerados anteriormente a la identidad administrada predeterminada del área de trabajo de Synapse. El nombre de identidad administrada predeterminado del área de trabajo es el mismo que el nombre del área de trabajo.
Para usar el área de trabajo de Synapse con cuentas de almacenamiento protegidas, se debe configurar un punto de conexión privado administrado desde el cuaderno. El punto de conexión privado administrado debe aprobarse desde la sección
Private endpoint connectionsde la cuenta de almacenamiento de ADLS Gen2 en elNetworkingpanel.
Grupo de SQL dedicado de Azure Synapse
Para habilitar la interacción correcta con el grupo de SQL dedicado de Azure Synapse se necesita la siguiente autorización, a menos que sea un usuario configurado también como Active Directory Admin en el punto de conexión de SQL dedicado:
Escenario de lectura
Conceda al usuario
db_exportermediante el procedimiento almacenado del sistemasp_addrolemember.EXEC sp_addrolemember 'db_exporter', [<your_domain_user>@<your_domain_name>.com];
Escenario de escritura
- El conector usa el comando COPY para escribir datos desde el almacenamiento provisional a la ubicación administrada de la tabla interna.
Configure los permisos necesarios que se describen aquí.
A continuación se muestra un fragmento de código de acceso rápido:
--Make sure your user has the permissions to CREATE tables in the [dbo] schema GRANT CREATE TABLE TO [<your_domain_user>@<your_domain_name>.com]; GRANT ALTER ON SCHEMA::<target_database_schema_name> TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has ADMINISTER DATABASE BULK OPERATIONS permissions GRANT ADMINISTER DATABASE BULK OPERATIONS TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has INSERT permissions on the target table GRANT INSERT ON <your_table> TO [<your_domain_user>@<your_domain_name>.com]
- El conector usa el comando COPY para escribir datos desde el almacenamiento provisional a la ubicación administrada de la tabla interna.
Documentación de la API
Conector del grupo de SQL dedicado de Azure Synapse para Apache Spark: documentación de la API.
Opciones de configuración
Para arrancar y orquestar correctamente la operación de lectura o escritura, el conector espera determinados parámetros de configuración. La definición de objeto:com.microsoft.spark.sqlanalytics.utils.Constants proporciona una lista de constantes estandarizadas para cada clave de parámetro.
A continuación se muestra la lista de opciones de configuración en función de su uso:
-
Lectura con la autenticación basada en Microsoft Entra ID
- Las credenciales se asignan automáticamente y no es necesario que el usuario proporcione opciones de configuración específicas.
- Se requiere un argumento de tres partes de nombre de tabla en
synapsesqlel método para leer la tabla respectiva en el grupo de SQL dedicado de Azure Synapse.
-
Lectura con la autenticación básica
- Punto de conexión de SQL dedicado de Azure Synapse
-
Constants.SERVER: punto de conexión del grupo de SQL dedicado de Synapse (Servidor FQDN) -
Constants.USER: nombre de usuario de SQL. -
Constants.PASSWORD: contraseña de usuario de SQL.
-
- Punto de conexión de Azure Data Lake Storage (Gen2): carpetas de almacenamiento provisional
-
Constants.DATA_SOURCE: la ruta de almacenamiento establecida en el parámetro de ubicación del origen de datos se usa para el almacenamiento provisional de datos.
-
- Punto de conexión de SQL dedicado de Azure Synapse
-
Escritura con la autenticación basada en Microsoft Entra ID
- Punto de conexión de SQL dedicado de Azure Synapse
- De forma predeterminada, el conector deduce el punto de conexión de SQL dedicado de Synapse mediante el nombre de la base de datos establecido en el
synapsesqlparámetro de nombre de tabla de tres partes del método. - Como alternativa, los usuarios pueden usar la opción
Constants.SERVERpara especificar el punto de conexión de sql. Asegúrese de que el punto de conexión alberga la base de datos correspondiente con el esquema correspondiente.
- De forma predeterminada, el conector deduce el punto de conexión de SQL dedicado de Synapse mediante el nombre de la base de datos establecido en el
- Punto de conexión de Azure Data Lake Storage (Gen2): carpetas de almacenamiento provisional
- Para el tipo de tabla interna:
- Configure las opciones
Constants.TEMP_FOLDERoConstants.DATA_SOURCE. - Si el usuario decide proporcionar la opción
Constants.DATA_SOURCE, la carpeta de almacenamiento provisional se derivará mediante el valorlocationde DataSource. - Si se proporcionan ambas, se usará el valor de la opción
Constants.TEMP_FOLDER. - En ausencia de una opción de carpeta de almacenamiento provisional, el conector derivará una en función de la configuración de ejecución
spark.sqlanalyticsconnector.stagingdir.prefix.
- Configure las opciones
- Para el tipo de tabla externa:
-
Constants.DATA_SOURCEes una opción de configuración obligatoria. - El conector usa la ruta de acceso de almacenamiento establecida en el parámetro de ubicación del origen de datos en combinación con el
locationargumento para el métodosynapsesqly deriva la ruta de acceso absoluta para conservar los datos de la tabla externa. - Si no se especifica el
locationargumento para el métodosynapsesql, el conector derivará el valor de ubicación como<base_path>/dbName/schemaName/tableName.
-
- Para el tipo de tabla interna:
- Punto de conexión de SQL dedicado de Azure Synapse
-
Escritura con la autenticación básica
- Punto de conexión de SQL dedicado de Azure Synapse
-
Constants.SERVER: punto de conexión del grupo de SQL dedicado de Synapse (Servidor FQDN). -
Constants.USER: nombre de usuario de SQL. -
Constants.PASSWORD: contraseña de usuario de SQL. -
Constants.STAGING_STORAGE_ACCOUNT_KEY: asociada a la cuenta de almacenamiento que albergaConstants.TEMP_FOLDERS(solo tipos de tabla internos) oConstants.DATA_SOURCE.
-
- Punto de conexión de Azure Data Lake Storage (Gen2): carpetas de almacenamiento provisional
- Las credenciales de autenticación básica de SQL no se aplican para acceder a los puntos de conexión de almacenamiento.
- Por lo tanto, asegúrese de asignar permisos de acceso de almacenamiento pertinentes, tal y como se describe en la sección Azure Data Lake Storage Gen2.
- Punto de conexión de SQL dedicado de Azure Synapse
Plantillas de código
En esta sección se muestran plantillas de código de referencia que describen cómo usar e invocar el conector de grupo de SQL dedicado de Azure Synapse para Apache Spark.
Nota:
Uso del conector en Python-
- El conector solo se admite en Python para Spark 3. Para Spark 2.4 (no compatible), podemos usar la API del conector Scala para interactuar con el contenido de un DataFrame en PySpark mediante DataFrame.createOrReplaceTempView o DataFrame.createOrReplaceGlobalTempView. Consulte la sección - Uso de datos materializados entre celdas.
- El identificador de devolución de llamada no está disponible en Python.
Lectura del grupo de SQL dedicado de Azure Synapse
Solicitud de lectura: synapsesql firma del método
Lectura de una tabla mediante la autenticación basada en Microsoft Entra ID
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Lectura de una consulta mediante la autenticación basada en Microsoft Entra ID
Nota:
Restricciones durante la lectura de la consulta:
- El nombre de la tabla y la consulta no pueden especificarse al mismo tiempo.
- Solo se permiten las consultas de selección. No se permiten instrucciones SQL de DDL y DML.
- Las opciones de selección y filtro del dataframe no se insertan en el grupo dedicado de SQL cuando se especifica una consulta.
- La lectura de una consulta solo está disponible en Spark 3.
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.option(Constants.QUERY, "select <column_name>, count(*) as cnt from <schema_name>.<table_name> group by <column_name>")
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>")
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Lectura de una tabla mediante la autenticación básica
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the table will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Lectura de una consulta mediante la autenticación básica
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config or as a Constant - Constants.DATABASE
spark.conf.set("spark.sqlanalyticsconnector.dw.database", "<database_name>")
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
option(Constants.QUERY, "select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>" ).
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Escritura en el grupo de SQL dedicado de Azure Synapse
Solicitud de escritura: synapsesql firma del método
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None,
callBackHandle=Option[(Map[String, Any], Option[Throwable])=>Unit]):Unit
Escritura con la autenticación basada en Microsoft Entra ID
En la siguiente plantilla de código completa se describe cómo usar el conector para situaciones de escritura:
//Add required imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Define read options for example, if reading from CSV source, configure header and delimiter options.
val pathToInputSource="abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_folder>/<some_dataset>.csv"
//Define read configuration for the input CSV
val dfReadOptions:Map[String, String] = Map("header" -> "true", "delimiter" -> ",")
//Initialize DataFrame that reads CSV data from a given source
val readDF:DataFrame=spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(1000) //Reads first 1000 rows from the source CSV input.
//Setup and trigger the read DataFrame for write to Synapse Dedicated SQL Pool.
//Fully qualified SQL Server DNS name can be obtained using one of the following methods:
// 1. Synapse Workspace - Manage Pane - SQL Pools - <Properties view of the corresponding Dedicated SQL Pool>
// 2. From Azure Portal, follow the bread-crumbs for <Portal_Home> -> <Resource_Group> -> <Dedicated SQL Pool> and then go to Connection Strings/JDBC tab.
//If `Constants.SERVER` is not provided, the value will be inferred by using the `database_name` in the three-part table name argument to the `synapsesql` method.
//Like-wise, if `Constants.TEMP_FOLDER` is not provided, the connector will use the runtime staging directory config (see section on Configuration Options for details).
val writeOptionsWithAADAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Setup optional callback/feedback function that can receive post write metrics of the job performed.
var errorDuringWrite:Option[Throwable] = None
val callBackFunctionToReceivePostWriteMetrics: (Map[String, Any], Option[Throwable]) => Unit =
(feedback: Map[String, Any], errorState: Option[Throwable]) => {
println(s"Feedback map - ${feedback.map{case(key, value) => s"$key -> $value"}.mkString("{",",\n","}")}")
errorDuringWrite = errorState
}
//Configure and submit the request to write to Synapse Dedicated SQL Pool (note - default SaveMode is set to ErrorIfExists)
//Sample below is using AAD-based authentication approach; See further examples to leverage SQL Basic auth.
readDF.
write.
//Configure required configurations.
options(writeOptionsWithAADAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Optional parameter that is used to specify external table's base folder; defaults to `database_name/schema_name/table_name`
location = None,
//Optional parameter to receive a callback.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
//If write request has failed, raise an error and fail the Cell's execution.
if(errorDuringWrite.isDefined) throw errorDuringWrite.get
Escritura con la autenticación básica
El siguiente fragmento de código reemplaza la definición de escritura descrita en la sección Escritura mediante autenticación basada en Microsoft Entra ID para enviar una solicitud de escritura mediante el enfoque de autenticación básica de SQL:
//Define write options to use SQL basic authentication
val writeOptionsWithBasicAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
//Set database user name
Constants.USER -> "<user_name>",
//Set database user's password
Constants.PASSWORD -> "<user_password>",
//Required only when writing to an external table. For write to internal table, this can be used instead of TEMP_FOLDER option.
Constants.DATA_SOURCE -> "<Name of the datasource as defined in the target database>"
//To be used only when writing to internal tables. Storage path will be used for data staging.
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Configure and submit the request to write to Synapse Dedicated SQL Pool.
readDF.
write.
options(writeOptionsWithBasicAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Not required for writing to an internal table
location = None,
//Optional parameter.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
En un enfoque de autenticación básica, para leer datos de una ruta de acceso de almacenamiento de origen, se requieren otras opciones de configuración. En el siguiente fragmento de código se proporciona un ejemplo para leer un origen de datos de Azure Data Lake Storage Gen2 con las credenciales de entidad de servicio:
//Specify options that Spark runtime must support when interfacing and consuming source data
val storageAccountName="<storageAccountName>"
val storageContainerName="<storageContainerName>"
val subscriptionId="<AzureSubscriptionID>"
val spnClientId="<ServicePrincipalClientID>"
val spnSecretKeyUsedAsAuthCred="<spn_secret_key_value>"
val dfReadOptions:Map[String, String]=Map("header"->"true",
"delimiter"->",",
"fs.defaultFS" -> s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net",
s"fs.azure.account.auth.type.$storageAccountName.dfs.core.windows.net" -> "OAuth",
s"fs.azure.account.oauth.provider.type.$storageAccountName.dfs.core.windows.net" ->
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id" -> s"$spnClientId",
"fs.azure.account.oauth2.client.secret" -> s"$spnSecretKeyUsedAsAuthCred",
"fs.azure.account.oauth2.client.endpoint" -> s"https://login.microsoftonline.com/$subscriptionId/oauth2/token",
"fs.AbstractFileSystem.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.Abfs",
"fs.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem")
//Initialize the Storage Path string, where source data is maintained/kept.
val pathToInputSource=s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net/<base_path_for_source_data>/<specific_file (or) collection_of_files>"
//Define data frame to interface with the data source
val df:DataFrame = spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(100)
Modos de guardado de DataFrame compatibles
Se admiten los siguientes modos de guardado al escribir datos de origen en una tabla de destino del grupo de SQL dedicado de Azure Synapse:
- ErrorIfExists (modo de guardado predeterminado)
- Si existe la tabla de destino, la escritura se anula y se devuelve una excepción al destinatario. De lo contrario, se crea una nueva tabla con datos de las carpetas de almacenamiento provisional.
- Ignore
- Si la tabla de destino existe, la escritura omitirá la solicitud de escritura sin devolver ningún error. De lo contrario, se crea una nueva tabla con datos de las carpetas de almacenamiento provisional.
- Sobrescribir
- Si la tabla de destino existe, los datos existentes en el destino se reemplazarán por los datos de las carpetas de almacenamiento provisional. De lo contrario, se crea una nueva tabla con datos de las carpetas de almacenamiento provisional.
- Append
- Si la tabla de destino existe, los nuevos datos se anexarán a ella. De lo contrario, se crea una nueva tabla con datos de las carpetas de almacenamiento provisional.
Manipulador de la devolución de llamada de solicitud de escritura
Los nuevos cambios de la API de ruta de acceso de escritura introdujeron una característica experimental para proporcionar al cliente un mapa de clave-valor> de métricas posteriores a la escritura. Las claves de las métricas se definen en la nueva definición de objeto Constants.FeedbackConstants. Las métricas se pueden recuperar como una cadena JSON pasando el manipulador de devolución de llamada, (Scala Function). A continuación aparece la firma de función:
//Function signature is expected to have two arguments - a `scala.collection.immutable.Map[String, Any]` and an Option[Throwable]
//Post-write if there's a reference of this handle passed to the `synapsesql` signature, it will be invoked by the closing process.
//These arguments will have valid objects in either Success or Failure case. In case of Failure the second argument will be a `Some(Throwable)`.
(Map[String, Any], Option[Throwable]) => Unit
A continuación se muestran algunas métricas importantes (presentadas en mayúsculas y minúsculas):
WriteFailureCauseDataStagingSparkJobDurationInMillisecondsNumberOfRecordsStagedForSQLCommitSQLStatementExecutionDurationInMillisecondsrows_processed
A continuación se muestra una cadena JSON de ejemplo con métricas posteriores a la escritura:
{
SparkApplicationId -> <spark_yarn_application_id>,
SQLStatementExecutionDurationInMilliseconds -> 10113,
WriteRequestReceivedAtEPOCH -> 1647523790633,
WriteRequestProcessedAtEPOCH -> 1647523808379,
StagingDataFileSystemCheckDurationInMilliseconds -> 60,
command -> "COPY INTO [schema_name].[table_name] ...",
NumberOfRecordsStagedForSQLCommit -> 100,
DataStagingSparkJobEndedAtEPOCH -> 1647523797245,
SchemaInferenceAssertionCompletedAtEPOCH -> 1647523790920,
DataStagingSparkJobDurationInMilliseconds -> 5252,
rows_processed -> 100,
SaveModeApplied -> TRUNCATE_COPY,
DurationInMillisecondsToValidateFileFormat -> 75,
status -> Completed,
SparkApplicationName -> <spark_application_name>,
ThreePartFullyQualifiedTargetTableName -> <database_name>.<schema_name>.<table_name>,
request_id -> <query_id_as_retrieved_from_synapse_dedicated_sql_db_query_reference>,
StagingFolderConfigurationCheckDurationInMilliseconds -> 2,
JDBCConfigurationsSetupAtEPOCH -> 193,
StagingFolderConfigurationCheckCompletedAtEPOCH -> 1647523791012,
FileFormatValidationsCompletedAtEPOCHTime -> 1647523790995,
SchemaInferenceCheckDurationInMilliseconds -> 91,
SaveModeRequested -> Overwrite,
DataStagingSparkJobStartedAtEPOCH -> 1647523791993,
DurationInMillisecondsTakenToGenerateWriteSQLStatements -> 4
}
Más ejemplos de código
Uso de datos materializados entre celdas
La opción createOrReplaceTempView del DataFrame de Spark se puede usar para acceder a los datos capturados en otra celda mediante el registro de una vista temporal.
- Celda en la que se capturan datos (por ejemplo, con la preferencia de lenguaje del cuaderno como
Scala)
//Necessary imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Configure options and read from Synapse Dedicated SQL Pool.
val readDF = spark.read.
//Set Synapse Dedicated SQL End Point name.
option(Constants.SERVER, "<synapse-dedicated-sql-end-point>.sql.azuresynapse.net").
//Set database user name.
option(Constants.USER, "<user_name>").
//Set database user's password.
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
option(Constants.DATA_SOURCE,"<data_source_name>").
//Set the three-part table name from which the read must be performed.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Optional - specify number of records the DataFrame would read.
limit(10)
//Register the temporary view (scope - current active Spark Session)
readDF.createOrReplaceTempView("<temporary_view_name>")
- Ahora, cambie la preferencia de lenguaje del cuaderno a
PySpark (Python)y capture los datos de la vista registrada<temporary_view_name>
spark.sql("select * from <temporary_view_name>").show()
Control de respuestas
La invocación synapsesql tiene dos posibles estados finales: correcto o con errores. En esta sección se describe cómo controlar la respuesta de solicitud para cada escenario.
Respuesta de solicitud de lectura
Al finalizar, el fragmento de código de respuesta de lectura se muestra en la salida de la celda. Cualquier error en la celda actual también cancelará las ejecuciones de celdas posteriores. La información detallada del error está disponible en los registros de la aplicación Spark.
Respuesta de solicitud de escritura
De forma predeterminada, se imprime una respuesta de escritura en la salida de la celda. En caso de error, la celda actual se marca como errónea y se anularán las ejecuciones de celdas posteriores. El otro enfoque consiste en pasar la opción de manipulador de devolución de llamada al método synapsesql. El manipulador de devolución de llamada proporcionará acceso mediante programación a la respuesta de escritura.
Otras consideraciones
- Al leer las tablas del grupo de SQL dedicado de Azure Synapse:
- Considere la posibilidad de aplicar los filtros necesarios en el DataFrame para aprovechar la característica de eliminación de columnas del conector.
- El escenario de lectura no admite la cláusula
TOP(n-rows)al enmarcar las instrucciones de consultaSELECT. La opción para limitar los datos es usar la cláusula limit(.) de DataFrame.- Consulte el ejemplo de la sección: Uso de datos materializados entre celdas.
- Al escribir en las tablas del grupo de SQL dedicado de Azure Synapse:
- Para los tipos de tablas internas:
- Las tablas se crean con la distribución de datos ROUND_ROBIN.
- Los tipos de columna se deducen del DataFrame que leen datos del origen. Las columnas de cadena se asignan a
NVARCHAR(4000).
- Para los tipos de tablas externas:
- El paralelismo inicial de DataFrame controla la organización de datos para la tabla externa.
- Los tipos de columna se deducen del DataFrame que leen datos del origen.
- Se puede lograr una mejor distribución de datos entre ejecutores mediante el ajuste del parámetro
spark.sql.files.maxPartitionBytesy el parámetrorepartitionde DataFrame. - Al escribir grandes conjuntos de datos, tenga en cuenta el impacto de la configuración del nivel de rendimiento de DWU que limita el tamaño de la transacción.
- Para los tipos de tablas internas:
- Supervise las tendencias de uso de Azure Data Lake Storage Gen2 para detectar comportamientos de limitación que pueden afectar al rendimiento de lectura y escritura.