Análisis de datos con Apache Spark
En este tutorial, aprenderá a realizar análisis de datos exploratorios mediante Azure Open Datasets y Apache Spark. A continuación, visualizará los resultados en un cuaderno de Synapse Studio en Azure Synapse Analytics.
En concreto, se analizará el conjunto de datos de taxis de Nueva York (NYC). Los datos están disponibles a través de Azure Open Datasets. Este subconjunto del conjunto de datos contiene información sobre las carreras de los taxis amarillos: información sobre cada carrera, la hora y la ubicación de inicio y fin, el costo y otros atributos interesantes.
Antes de empezar
Cree un grupo de Apache Spark, para lo que puede seguir el tutorial Creación de un grupo de Apache Spark.
Descarga y preparación de los datos
Cree un cuaderno mediante el kernel de PySpark. Para obtener instrucciones, consulte Creación de un cuaderno.
Nota
Debido a la existencia del kernel PySpark, no necesitará crear ningún contexto explícitamente. El contexto de Spark se crea automáticamente al ejecutar la primera celda de código.
En este tutorial, se usaran varias bibliotecas para facilitar la visualización del conjunto de datos. Para realizar este análisis, importe las siguientes bibliotecas:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pdDado que los datos sin procesar están en formato de Parquet, puede usar el contexto de Spark para extraer el archivo a la memoria como trama de datos directamente. Cree un DataFrame de Spark. Para ello, recupere los datos mediante Open Datasets API. En este caso, se usan las propiedades del esquema de lectura del DataFrame de Spark para inferir los tipos de datos y el esquema.
from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())Después de leer los datos, se realizará un filtrado inicial para limpiar el conjunto de datos. Se podrían quitar las columnas innecesarias y agregar columnas que extraigan información importante. Además, también se filtrarán las anomalías del conjunto de datos.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
Análisis de datos
Los analistas de datos disponen de una amplia gama de herramientas que pueden ayudarles a extraer información de los datos. En esta parte del tutorial, le guiaremos a través de algunas herramientas útiles disponibles en los cuadernos de Azure Synapse Analytics. En este análisis, queremos conocer los factores que generan mayores propinas en los taxis durante el período seleccionado.
Apache Spark SQL Magic
En primer lugar, usaremos el cuaderno de Azure Synapse para hacer un análisis exploratorio de los datos con comandos magic y SQL de Apache Spark. Una vez que tengamos nuestra consulta, visualizaremos los resultados mediante la funcionalidad chart options integrada.
En el cuaderno, cree una celda y copie el código siguiente. Con esta consulta queremos saber cómo han cambiado los importes medios de las propinas en el período seleccionado. Esta consulta también nos ayudará a identificar otra información útil, como el importe mínimo y máximo de las propinas por día y el importe medio de la tarifa.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCUna vez que finaliza la ejecución de la consulta, se pueden visualizar los resultados cambiando a la vista de gráfico. En este ejemplo se crea un gráfico de líneas mediante la especificación del campo
day_of_monthcomo la clave yavgTipAmountcomo el valor. Una vez que haya seleccionado las opciones deseadas, seleccione Aplicar para actualizar el gráfico.
Visualización de datos
Además de las opciones de gráficos integradas del cuaderno, puede usar bibliotecas de código abierto populares para crear sus propias visualizaciones. En los ejemplos siguientes, usaremos Seaborn y Matplotlib. Se trata de bibliotecas de Python que se usan con frecuencia para la visualización de datos.
Nota
De forma predeterminada, cada grupo de Apache Spark de Azure Synapse Analytics contiene un conjunto de bibliotecas predeterminadas y usadas con frecuencia. La lista completa de bibliotecas se puede ver en la documentación del runtime de Azure Synapse. Además, para que el código de terceros o de compilación local esté disponible para las aplicaciones, puede instalar una biblioteca en uno de los grupos de Spark.
Para que el desarrollo sea más fácil y menos costoso, se reducirá el conjunto de datos de la muestra. Usaremos la funcionalidad de muestreo de Apache Spark integrada. Además, tanto Seaborn como Matplotlib requieren un DataFrame de Pandas o una matriz de NumPy. Para obtener un DataFrame de Pandas, usaremos el comando
toPandas()para convertir dicho DataFrame.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()Queremos conocer la distribución de las sugerencias en nuestro conjunto de datos. Usaremos Matplotlib para crear un histograma que muestre la distribución del importe de las propinas y el número de ellas. En función de la distribución, podemos ver que las sugerencias están sesgadas hacia cantidades inferiores o iguales a 10 USD.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()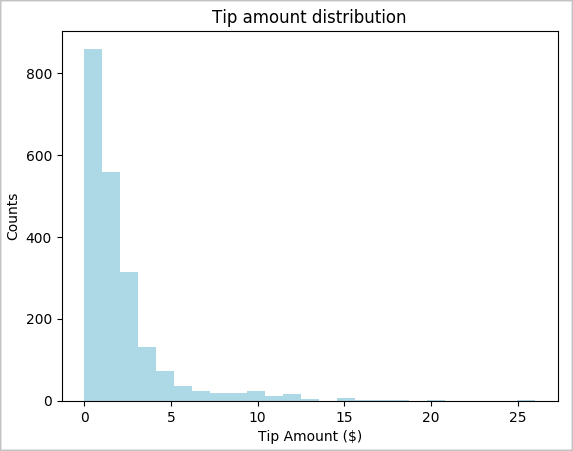
A continuación, queremos conocer la relación entre las propinas de una carrera dada y el día de la semana. Usamos Seaborn para crear un diagrama de cajas que resume las tendencias de cada día de la semana.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()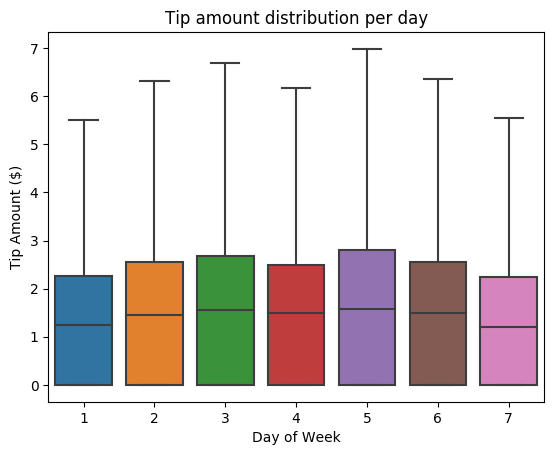
Otra hipótesis nuestra podría ser que hay una relación positiva entre el número de pasajeros y el importe total de las propinas de los taxis. Para comprobar esta relación, ejecutamos el siguiente código para generar un diagrama de cajas que ilustra la distribución de las propinas por número de pasajeros.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()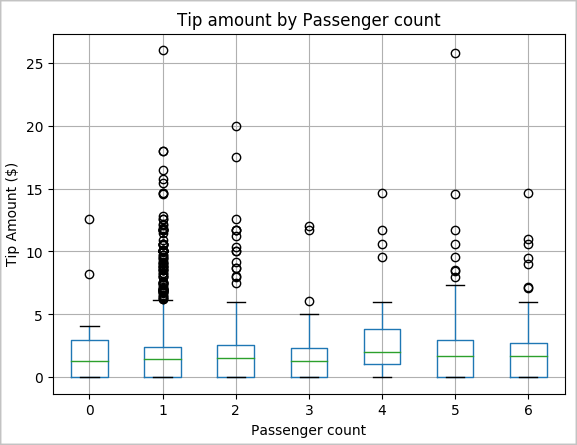
Por último, queremos conocer la relación entre el importe de las carreras y el importe de las propinas. En función de los resultados, podemos ver que hay varias observaciones en las que las personas no dejan propina. Sin embargo, también vemos una relación positiva entre los importes de las propinas y la tarifa general.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()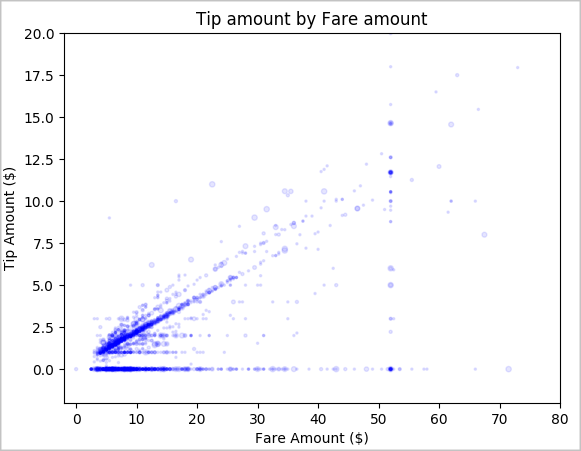
Apagado de la instancia de Spark
Después de finalizar la ejecución de la aplicación, cierre el cuaderno para liberar los recursos. Cierre la pestaña o bien seleccione Finalizar sesión en el panel de estado en la parte inferior del cuaderno.
Consulte también
- Información general: Apache Spark en Azure Synapse Analytics
- Creación de un modelo de Machine Learning con Apache SparkML