Tutorial: Text Analytics con los servicios de Azure AI
En este tutorial, aprenderá a usar Text Analytics para analizar texto no estructurado en Azure Synapse Analytics. Text Analytics es un componente de los servicios de Azure AI que permite efectuar tareas de minería y análisis de texto mediante características de procesamiento de lenguaje natural (NLP).
En este tutorial se muestra cómo usar el análisis de textos con SynapseML para:
- Detectar etiquetas de opinión en el nivel de oración o documento
- Identificar el idioma de una entrada de texto determinada
- Reconocer entidades de un texto con vínculos a una base de conocimientos ya conocida
- Extracción de frases clave de un texto
- Identificar distintas entidades del texto y clasificarlas en clases o tipos predefinidos
- Identificar y censurar entidades confidenciales en un texto determinado
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
- Necesitará un área de trabajo de Azure Synapse Analytics con una cuenta de almacenamiento de Azure Data Lake Storage Gen2 que esté configurada como almacenamiento predeterminado. Asegúrese de que es el colaborador de datos de Storage Blob en el sistema de archivos de Data Lake Storage Gen2 con el que trabaja.
- Grupo de Spark en el área de trabajo de Azure Synapse Analytics. Para más información, consulte el artículo sobre creación de un grupo de Spark en Azure Synapse.
- Pasos previos a la configuración descritos en el tutorial Configuración de servicios de Azure AI en Azure Synapse.
Introducción
Abra Synapse Studio y cree un nuevo cuaderno. Para empezar, importe SynapseML.
import synapse.ml
from synapse.ml.services import *
from pyspark.sql.functions import col
Configuración del análisis de texto
Use el análisis de texto vinculado que configuró en los pasos de preconfiguración.
linked_service_name = "<Your linked service for text analytics>"
Opinión de texto
El análisis de sentimiento de texto proporciona una manera de detectar las etiquetas de opinión (como "negativo", "neutral" y "positivo") y puntuaciones de confianza en la oración y en el nivel de documento. Consulte los idiomas admitidos en la APÌ Text Analytics para obtener la lista de idiomas habilitados.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("I am so happy today, it's sunny!", "en-US"),
("I am frustrated by this rush hour traffic", "en-US"),
("The Azure AI services on spark aint bad", "en-US"),
], ["text", "language"])
# Run the Text Analytics service with options
sentiment = (TextSentiment()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("sentiment")
.setErrorCol("error")
.setLanguageCol("language"))
# Show the results of your text query in a table format
results = sentiment.transform(df)
display(results
.withColumn("sentiment", col("sentiment").getItem("document").getItem("sentences")[0].getItem("sentiment"))
.select("text", "sentiment"))
Resultados esperados
| text | opinión |
|---|---|
| ¡Estoy tan feliz hoy, es soleado! | positiva |
| Estoy frustrado por este tráfico de hora punta | negativa |
| Los servicios de Azure AI en Spark no están mal | neutral |
Detector de idioma
El detector de idioma evalúa la entrada de texto para cada documento y devuelve identificadores de idioma con una puntuación que indica la solidez análisis. Esta capacidad es útil para los almacenes de contenido que recopilan texto arbitrario, donde el idioma es desconocido. Consulte los idiomas admitidos en la APÌ Text Analytics para obtener la lista de idiomas habilitados.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("Hello World",),
("Bonjour tout le monde",),
("La carretera estaba atascada. Había mucho tráfico el día de ayer.",),
("你好",),
("こんにちは",),
(":) :( :D",)
], ["text",])
# Run the Text Analytics service with options
language = (LanguageDetector()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("language")
.setErrorCol("error"))
# Show the results of your text query in a table format
display(language.transform(df))
Resultados esperados
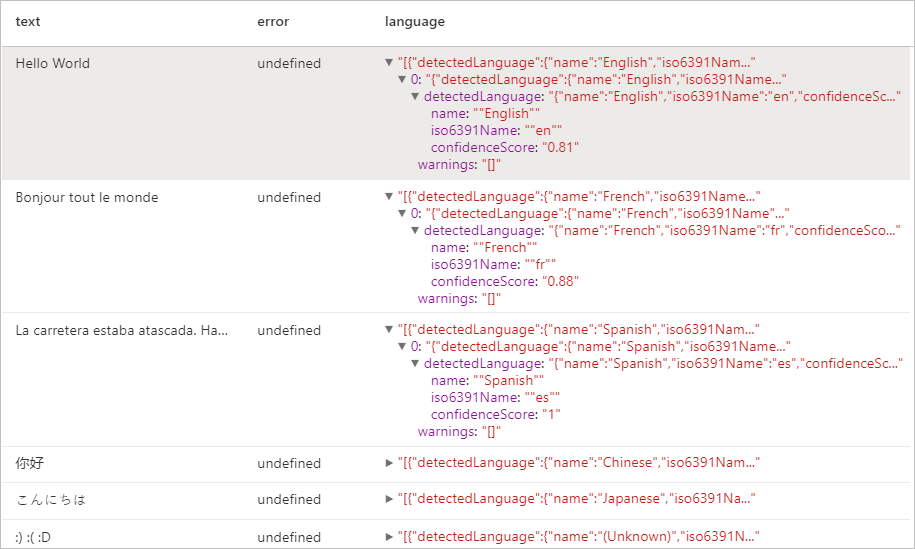
Detector de entidad
El detector de entidad devuelve una lista de entidades reconocidas con vínculos a una base de conocimientos ya conocida. Consulte los idiomas admitidos en la APÌ Text Analytics para obtener la lista de idiomas habilitados.
df = spark.createDataFrame([
("1", "Microsoft released Windows 10"),
("2", "In 1975, Bill Gates III and Paul Allen founded the company.")
], ["if", "text"])
entity = (EntityDetector()
.setLinkedService(linked_service_name)
.setLanguage("en")
.setOutputCol("replies")
.setErrorCol("error"))
display(entity.transform(df).select("if", "text", col("replies").getItem("document").getItem("entities").alias("entities")))
Resultados esperados
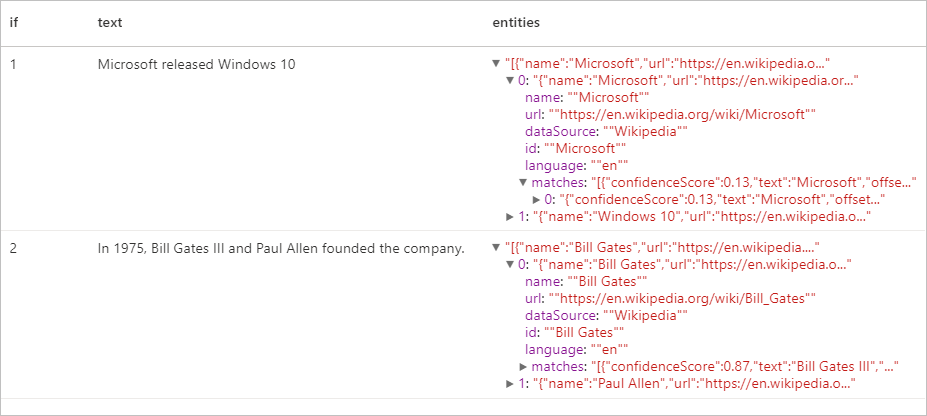
Extracción de frases clave
La extracción de frases clave evalúa el texto no estructurado y devuelve una lista de frases clave. Esta capacidad es útil si necesita identificar rápidamente los principales puntos en una colección de documentos. Consulte los idiomas admitidos en la APÌ Text Analytics para obtener la lista de idiomas habilitados.
df = spark.createDataFrame([
("en", "Hello world. This is some input text that I love."),
("fr", "Bonjour tout le monde"),
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer.")
], ["lang", "text"])
keyPhrase = (KeyPhraseExtractor()
.setLinkedService(linked_service_name)
.setLanguageCol("lang")
.setOutputCol("replies")
.setErrorCol("error"))
display(keyPhrase.transform(df).select("text", col("replies").getItem("document").getItem("keyPhrases").alias("keyPhrases")))
Resultados esperados
| text | keyPhrases |
|---|---|
| Hola mundo. Este es un texto de entrada que me encanta. | "["Hello world","input text"]" |
| Bonjour tout le monde | "["Bonjour","monde"]" |
| La carretera estaba atascada. Había mucho tráfico el día de ayer. | "["mucho tráfico","día","carretera","ayer"]" |
Reconocimiento de entidades con nombre (NER)
El reconocimiento de entidades con nombre (NER) es la capacidad para identificar diferentes entidades en el texto y clasificarlas en clases o tipos predefinidos, como: persona, ubicación, evento, producto y organización. Consulte los idiomas admitidos en la APÌ Text Analytics para obtener la lista de idiomas habilitados.
df = spark.createDataFrame([
("1", "en", "I had a wonderful trip to Seattle last week."),
("2", "en", "I visited Space Needle 2 times.")
], ["id", "language", "text"])
ner = (NER()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(ner.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Resultados esperados
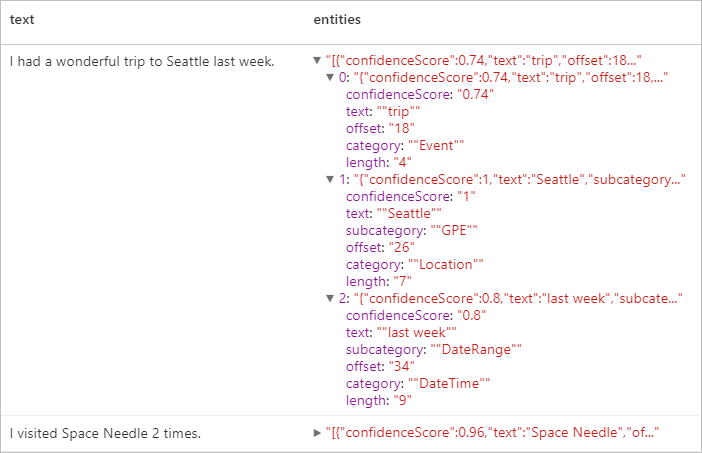
Información de identificación personal (PII) V3.1
La característica PII forma parte de NER y puede identificar y suprimir entidades confidenciales en texto que están asociadas a una persona individual, como: el número de teléfono, la dirección de correo electrónico, la dirección de correo electrónico y el número de pasaporte. Consulte los idiomas admitidos en la APÌ Text Analytics para obtener la lista de idiomas habilitados.
df = spark.createDataFrame([
("1", "en", "My SSN is 859-98-0987"),
("2", "en", "Your ABA number - 111000025 - is the first 9 digits in the lower left hand corner of your personal check."),
("3", "en", "Is 998.214.865-68 your Brazilian CPF number?")
], ["id", "language", "text"])
pii = (PII()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(pii.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Resultados esperados
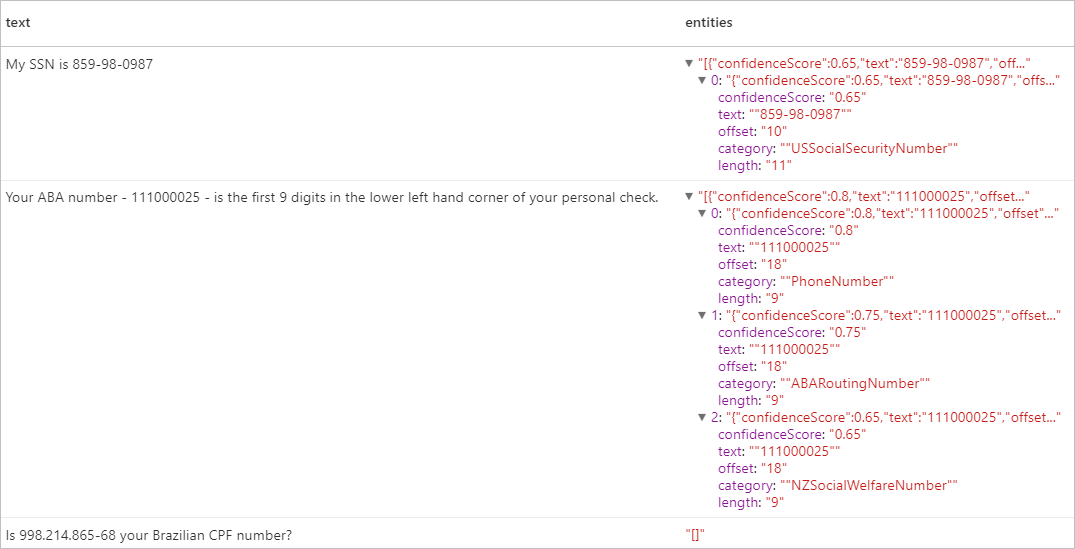
Limpieza de recursos
Para asegurarse de que se cierra la instancia de Spark, finalice todas las sesiones (cuadernos) conectadas. El grupo se cierra cuando se alcanza el tiempo de inactividad especificado en el grupo de Apache Spark. También puede decidir finalizar la sesión en la barra de estado en la parte superior derecha del cuaderno.
