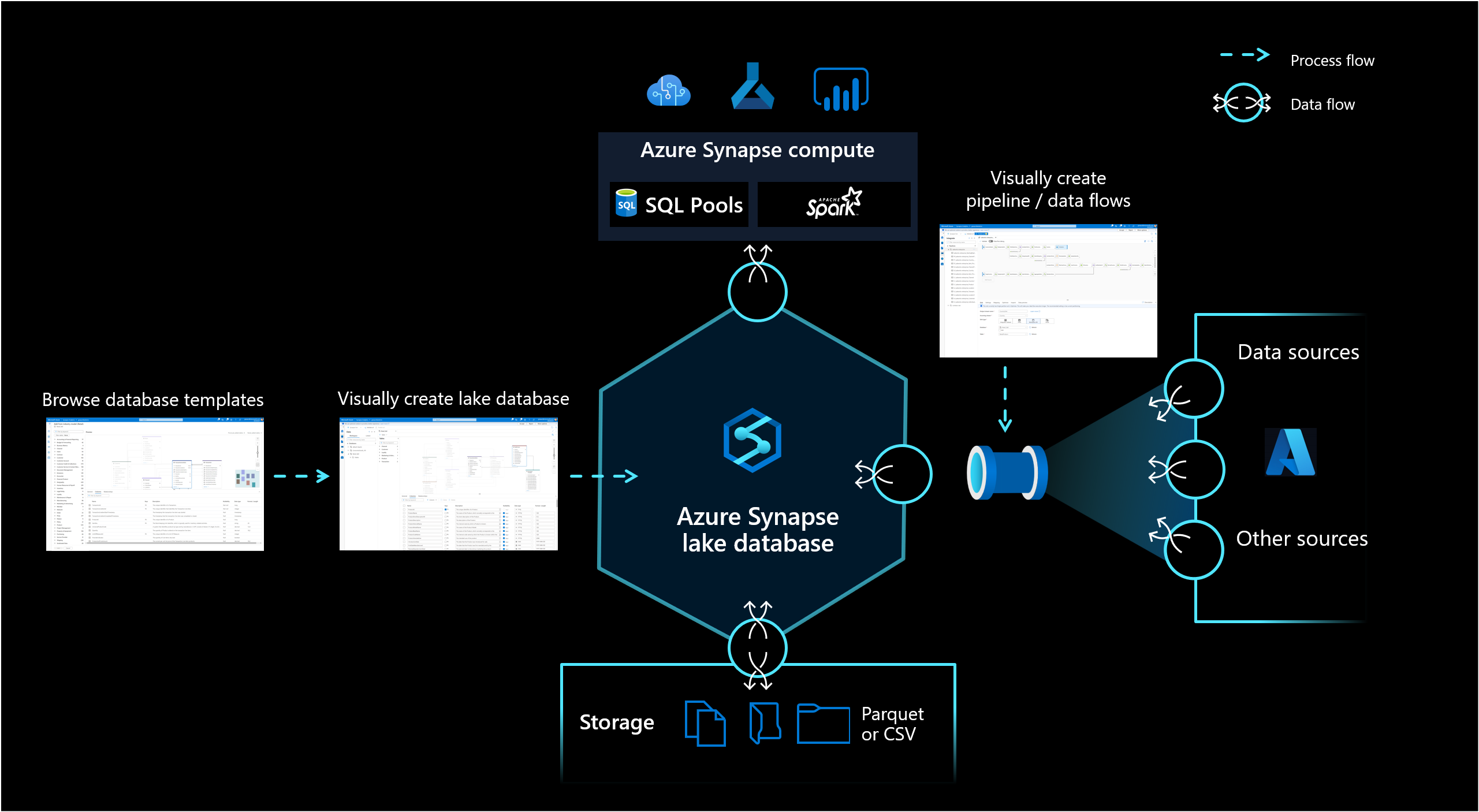
Base de datos de lago
La base de datos lago de Azure Synapse Analytics permite a los clientes reunir el diseño de la base de datos, la metainformación sobre los datos almacenados y la posibilidad de describir cómo y dónde se deben almacenar los datos. La base de datos de lago aborda el desafío de los lagos de datos actuales, donde es difícil entender cómo se estructuran los datos.
Diseñador de bases de datos
El nuevo diseñador de bases de datos de Synapse Studio ofrece la posibilidad de crear un modelo de datos para la base de datos de lago y agregarle información adicional. Todas las entidades y atributos se pueden describir para proporcionar más información sobre el modelo, que no solo contiene entidades, sino también relaciones. En concreto, la imposibilidad de modelar relaciones ha sido un desafío para la interacción en el lago de datos. Este desafío se aborda ahora con un diseñador integrado que proporciona posibilidades que han estado disponibles en las bases de datos, pero no en el lago. Además, la capacidad de agregar descripciones y posibles valores de demostración al modelo permite que las personas que interactúen con él en el futuro tengan información donde la necesiten para comprender mejor los datos.
Nota:
El tamaño máximo de los metadatos de una base de datos de lago es de 10 GB. Se producirá un error al intentar publicar o actualizar un modelo que supere los 10 GB de tamaño. Para resolver este problema, reduzca el tamaño del modelo quitando tablas y columnas. Considere la posibilidad de dividir modelos grandes en varias bases de datos de lago para evitar este límite.
Almacenamiento de datos
Las bases de datos de lago usan un lago de datos en la cuenta de Azure Storage para almacenar los datos de la base de datos. Los datos se pueden almacenar en formato de archivo .csv, Parquet o Delta y se pueden usar diferentes configuraciones para optimizar el almacenamiento. Cada base de datos de lago usa un servicio vinculado para definir la ubicación de la carpeta de datos raíz. Para cada entidad, se crean carpetas independientes de forma predeterminada dentro de esta carpeta de base de datos en el lago de datos. De forma predeterminada, todas las tablas de una base de datos de lago usan el mismo formato, pero los formatos y la ubicación de los datos se pueden cambiar por entidad si se solicita.
Nota
La publicación de una base de datos de lago no crea ninguna de las estructuras o esquemas subyacentes necesarios para consultar los datos en Spark o SQL. Después de publicarlos, cargue los datos en la base de datos de Lake mediante canalizaciones para empezar a consultarlos.
Actualmente, no se admite la compatibilidad con el formato Delta para las bases de datos de lago en Synapse Studio.
La sincronización de objetos de base de datos de lago entre el almacenamiento y Synapse es unidireccional. Asegúrese de realizar las creaciones o modificaciones del esquema de los objetos de base de datos de lago mediante el diseñador de bases de datos de Synapse Studio. Si realiza estos cambios desde Spark o directamente en el almacenamiento, las definiciones de las bases de datos de lago no se sincronizarán. Si esto sucede, es posible que vea definiciones de base de datos de lago anteriores en el diseñador de bases de datos. Deberá replicar y publicar estos cambios en el diseñador de bases de datos para volver a sincronizar las bases de datos del lago.
Proceso de base de datos
La base de datos lago se expone en el grupo de SQL sin servidor de Synapse SQL y Apache Spark que proporciona a los usuarios la capacidad de desacoplar el almacenamiento del proceso. Los metadatos asociados a la base de datos de lago facilitan que los distintos motores de proceso no solo proporcionen una experiencia integrada, sino que también usen información adicional (por ejemplo, relaciones) que no se admite originalmente en el lago de datos.
Contenido relacionado
Siga explorando las funcionalidades del diseñador de bases de datos mediante los vínculos siguientes.