Inicio rápido: Ingesta de datos mediante canalizaciones de Azure Synapse (versión preliminar)
En este inicio rápido, aprenderá a cargar datos de un origen de datos en un grupo del Explorador de datos de Azure Synapse.
Prerrequisitos
Suscripción a Azure. Cree una cuenta de Azure gratuita.
Creación de un grupo de Data Explorer mediante Synapse Studio o Azure Portal
Cree una base de datos de Data Explorer.
En Synapse Studio, en el panel izquierdo, seleccione Datos.
Seleccione + (Agregar un recurso nuevo) >Grupo de explorador de datos, y use la siguiente información:
Configuración Valor sugerido Descripción Nombre del grupo contosodataexplorer Nombre del grupo de Data Explorer que se usará. Name TestDatabase El nombre de la base de datos debe ser único dentro del clúster. Período de retención predeterminado 365 El intervalo de tiempo (en días) para el que se garantiza que los datos se mantengan disponibles para consultarlos. El intervalo de tiempo se mide desde el momento en que se ingieren los datos. Período de caché predeterminado 31 El intervalo de tiempo (en días) durante el que los datos consultados con frecuencia se van a mantener disponibles en el almacenamiento SSD o en la RAM, en lugar de en el almacenamiento a largo plazo. Seleccione Crear para crear la base de datos. Normalmente se tarda menos de un minuto.
Creación de una tabla
- En Synapse Studio, en el panel izquierdo, seleccione Desarrollar.
- En Scripts de KQL, seleccione + (Agregar un recurso nuevo) >Script de KQL. En el panel derecho, puede asignar un nombre al script.
- En el menú Conectarse a, seleccione contosodataexplorer.
- En el menú Use database (Usar base de datos), seleccione TestDatabase.
- Pegue el siguiente comando y seleccione Ejecutar para crear la tabla.
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)Sugerencia
Compruebe que la tabla se creó correctamente. En el panel izquierdo, seleccione Datos, elija contosodataexplorer en el menú Más y seleccione Actualizar. En contosodataexplorer, expanda Tablas y asegúrese de que la tabla StormEvents aparece en la lista.
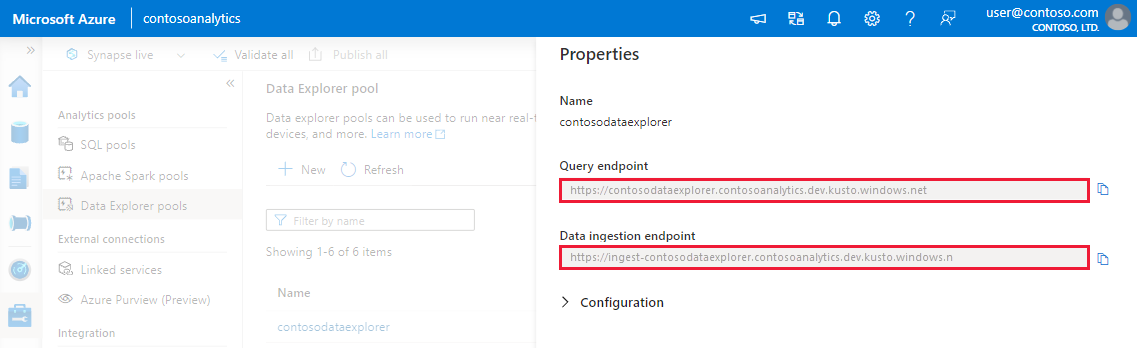
Obtenga los puntos de conexión de consulta e ingesta de datos. Necesitará el punto de conexión de consulta para configurar el servicio vinculado.
En Synapse Studio, en el panel izquierdo, seleccione Administrar>Grupos exploradores de datos.
Seleccione el grupo explorador de datos que desee utilizar para ver los detalles.
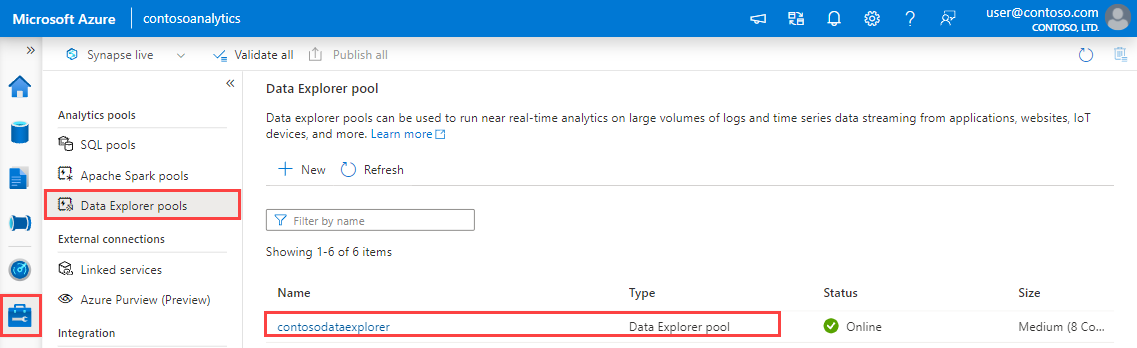
Anote los puntos de conexión de consulta e ingesta de datos. Utilice el punto de conexión de consulta como clúster al configurar las conexiones con el grupo explorador de datos. Al configurar los SDK para la ingesta de datos, use el punto de conexión de ingesta de datos.
Creación de un servicio vinculado
En Azure Synapse Analytics, un servicio vinculado es donde se define la información de conexión a otros servicios. En esta sección, creará un servicio vinculado para Azure Data Explorer.
En Synapse Studio, en el panel de la izquierda, seleccione Administrar>Servicios vinculados.
Seleccione + Nuevo.
Seleccione el servicio Azure Data Explorer en la galería y seleccione Continuar.

En la página Nuevos servicios vinculados, use la siguiente información:
Configuración Valor sugerido Description Nombre contosodataexplorerlinkedservice El nombre del nuevo servicio vinculado de Azure Data Explorer. Método de autenticación Identidad administrada Método de autenticación del nuevo servicio. Método de selección de cuentas Escribir manualmente Método para especificar el punto de conexión de consulta. Punto de conexión https://contosodataexplorer.contosoanalytics.dev.kusto.windows.net Punto de conexión de consulta que anotó anteriormente. Base de datos TestDatabase Base de datos en la que desea ingerir los datos. 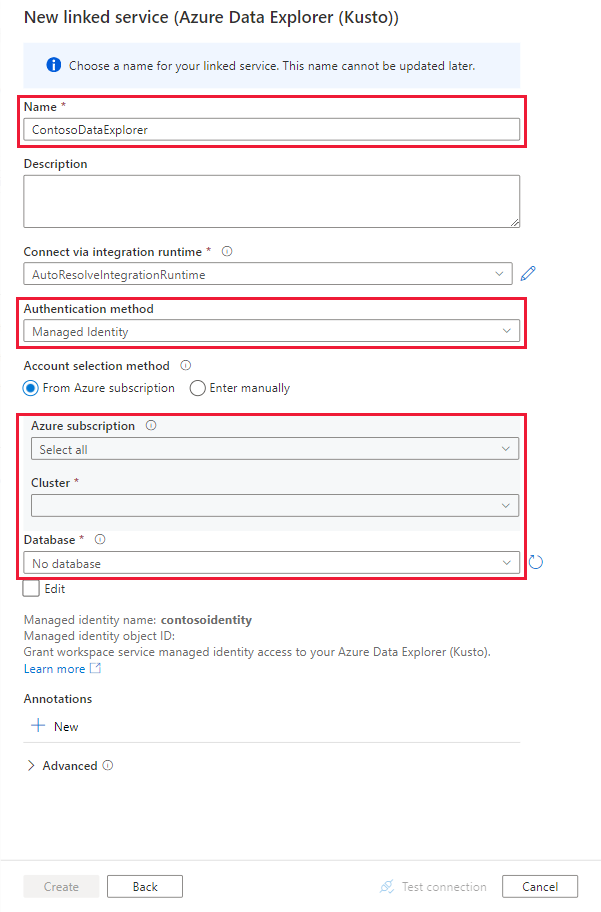
Seleccione Probar conexión para validar la configuración y, después, seleccione Crear.
Creación de una canalización para ingerir datos
Una canalización contiene el flujo lógico para una ejecución de un conjunto de actividades. En esta sección, creará una canalización que contiene una actividad de copia que ingiere datos desde un origen de su elección en un grupo del Explorador de datos.
En Synapse Studio, en el panel izquierdo, seleccione Integrar.
Seleccione +>Canalización. En el panel derecho, puede asignar un nombre a la canalización.
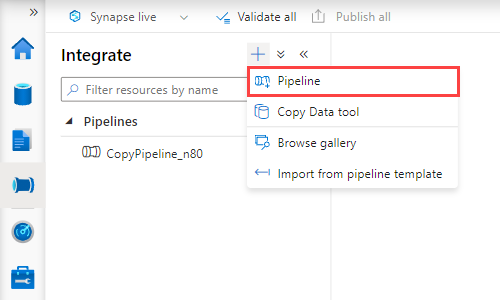
En Actividades>Move & transform (Mover y transformar), arrastre Copiar datos en el lienzo de la canalización.
Seleccione la actividad de copia y vaya a la pestaña Origen. Seleccione o cree un nuevo conjunto de datos de origen como origen desde el que copiar los datos.
Haga clic en la pestaña Receptor. Seleccione Nuevo para crear un conjunto de datos de receptor.
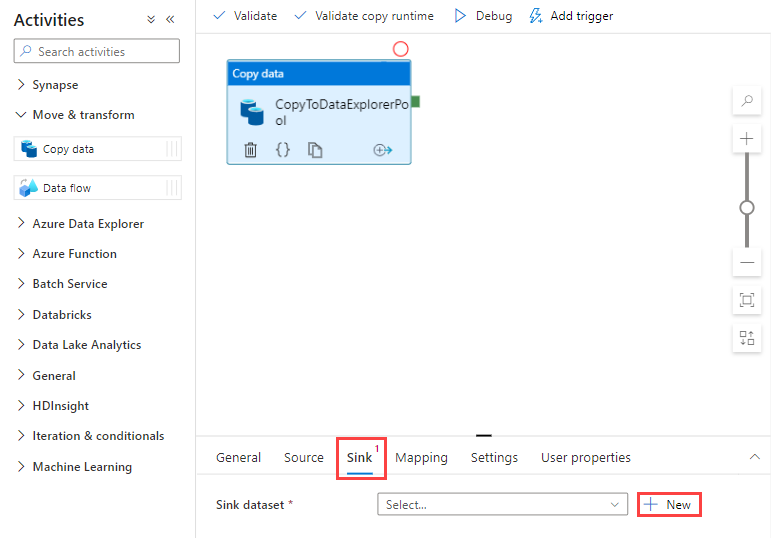
Seleccione el conjunto de datos Azure Data Explorer en la galería y seleccione Continuar.
En el panel Establecer propiedades, use la siguiente información y seleccione Aceptar.
Configuración Valor sugerido Description Nombre AzureDataExplorerTable Nombre de la nueva canalización. Servicio vinculado contosodataexplorerlinkedservice El servicio vinculado que creó anteriormente. Tabla StormEvents La tabla que creó antes. 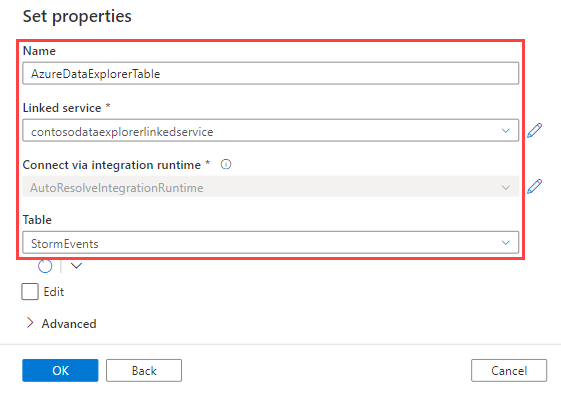
Para comprobar la canalización, seleccione Validate (Comprobar) en la barra de herramientas. Verá el resultado de la salida de la validación de canalización en el lado derecho de la página.
Depuración y publicación de la canalización
Una vez que haya terminado de configurar la canalización, puede ejecutar una depuración antes de publicar los artefactos para verificar que todo esté correcto.
Seleccione Depurar en la barra de herramientas. Verá el estado de ejecución de la canalización en la pestaña Output (Salida) en la parte inferior de la ventana.
Una vez que la ejecución de la canalización se realiza correctamente, en la barra de herramientas superior, seleccione Publish all (Publicar todo). Esta acción publica las entidades (conjuntos de datos y canalizaciones) que creó en el servicio de Synapse Analytics.
Espere a que aparezca el mensaje Successfully published (Publicado correctamente). Para ver los mensajes de notificación, seleccione el botón de campana en la esquina superior derecha.
Activación y supervisión de la canalización
En esta sección, se desencadena manualmente la canalización publicada en el paso anterior.
Seleccione Add Trigger (Agregar desencadenador) en la barra de herramientas y, después, seleccione Trigger Now (Desencadenar ahora). En la página Pipeline Run (Ejecución de la canalización), seleccione OK (Aceptar).
Vaya a la pestaña Supervisar que se encuentra en la barra lateral izquierda. Verá una ejecución de canalización que se desencadena de forma manual.
Cuando la ejecución de la canalización finaliza correctamente, seleccione el vínculo de la columna Pipeline name (Nombre de canalización) para ver los detalles de la ejecución de actividad o para volver a ejecutar la canalización. En este ejemplo, solo hay una actividad, así que solo verá una entrada en la lista.
Para más información sobre la operación de copia, seleccione el vínculo Details (Detalles) (icono de gafas) en la columna Activity name (Nombre de actividad). Puede supervisar detalles como el volumen de datos copiados desde el origen al receptor, el rendimiento de los datos, los pasos de ejecución con su duración correspondiente y las configuraciones que se utilizan.
Para volver a la vista de ejecuciones de canalización, seleccione el vínculo Todas las ejecuciones de la canalización. Seleccione Refresh (Actualizar) para actualizar la lista.
Compruebe que los datos se han escrito correctamente en el grupo del Explorador de datos.