Optimización de consultas mediante la simulación de trabajos
Una manera de mejorar el rendimiento de un trabajo de Azure Stream Analytics (ASA) consiste en aplicar el paralelismo en la consulta. En este artículo se muestra cómo usar la simulación de trabajos en Azure Portal y Visual Studio Code (VS Code) para evaluar el paralelismo de consultas para un trabajo de Stream Analytics. Aprenderá a visualizar una ejecución de consultas con un número diferente de unidades de streaming y a mejorar el paralelismo de consultas en función de las sugerencias de edición.
¿Qué es la consulta paralela?
El paralelismo de consultas divide la carga de trabajo de una consulta mediante la creación de varios procesos (o nodos de streaming) y la ejecuta en paralelo. Reduce considerablemente el tiempo de ejecución general de la consulta y, por tanto, se necesitan menos horas de streaming.
Para que un trabajo sea paralelo, todas las entradas, salidas y pasos de consulta deben alinearse y usar las mismas claves de partición. La creación de particiones lógicas de consulta viene determinada por las claves que se usan para agregaciones (GROUP BY).
Si quiere obtener más información sobre la paralelización de consultas, consulte Sacar provecho de la paralelización de consultas en Azure Stream Analytics.
Uso de la simulación de trabajos en VS Code
La característica de simulación de trabajos simula cómo se ejecutaría el trabajo en Azure. En este tutorial, aprenderá a mejorar el rendimiento de las consultas en función de las sugerencias de edición y a hacer que se ejecuten en paralelo. Por ejemplo, se usa un trabajo no paralelo que toma los datos de entrada de un centro de eventos y envía los resultados a otro centro de eventos.
Requisitos previos:
- Extensión de herramientas de ASA para VS Code. Para instalarla, consulte esta guía.
- Configure la entrada y salida en directo para el trabajo de Stream Analytics.
- La entrada y la salida dinámicas se deben incluir en la consulta.
Nota
La simulación de trabajos no puede simular la topología de la ejecución de trabajos para las entradas y salidas locales. No se enviaría ningún dato al destino de salida durante la simulación.
Abra el proyecto de ASA en VS Code. Vaya al archivo de consulta *.asaql y seleccione Simular trabajo para iniciar la simulación de trabajos.

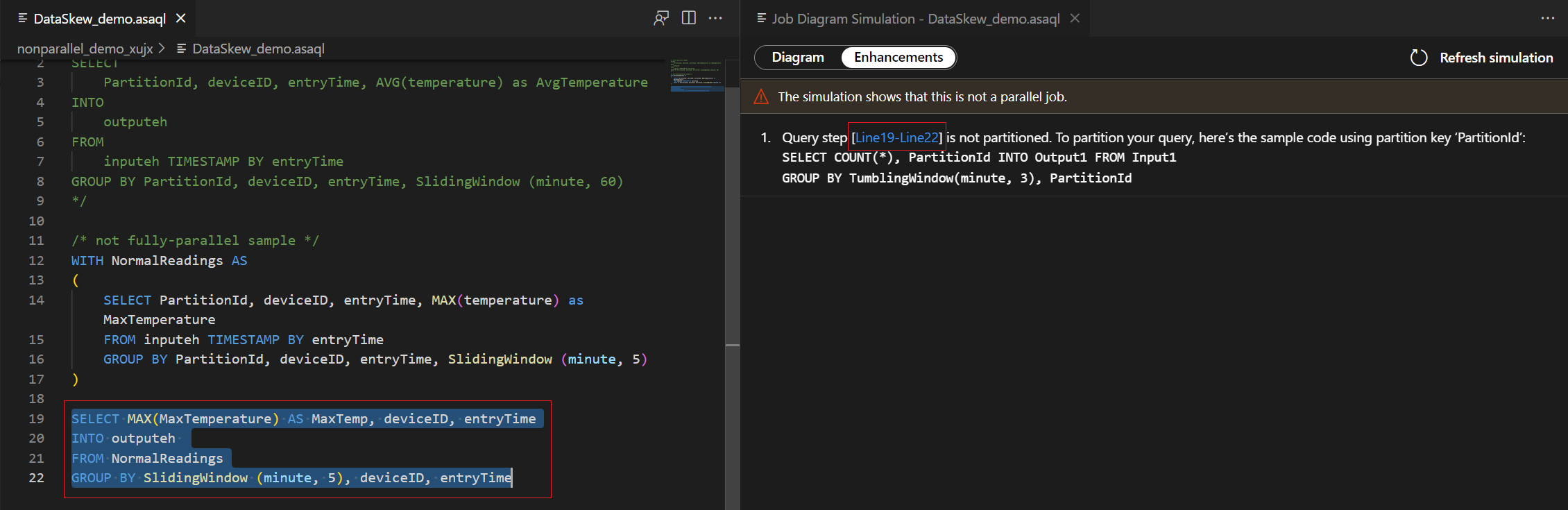
En la pestaña Diagrama se muestra el número de nodos de streaming asignados al trabajo y el número de particiones en cada nodo de streaming. La captura de pantalla siguiente es un ejemplo de un trabajo no paralelo donde los datos fluyen entre nodos.

Dado que esta consulta NO está en paralelo, puede seleccionar la pestaña Mejoras para ver sugerencias sobre la optimización de la consulta.

Seleccione el paso de consulta en la lista de mejoras y verá que las líneas correspondientes están resaltadas y que puede editar la consulta en función de las sugerencias.
Nota
Se trata de sugerencias de edición para mejorar el paralelismo de consultas. Sin embargo, si usa la función de agregado entre todas las particiones, es posible que no se aplique una consulta paralela a los escenarios.
En este ejemplo, agregará PartitionId a la línea 22 y guardará el cambio. A continuación, puede usar Actualizar simulación para obtener el nuevo diagrama.

También puede ajustar las unidades de streaming para simular cómo se asignan los nodos de streaming con diferentes SU. Así se hace una idea de cuántas SU necesita para administrar la carga de trabajo.







Uso de la simulación de trabajos en Azure Portal
- Vaya al editor de consultas en Azure Portal y seleccione Simulación de trabajos en el panel inferior. Simula el trabajo que ejecuta la topología en función de la consulta y las unidades de streaming predefinidas.

- Seleccione Mejoras para ver las sugerencias para mejorar el paralelismo de consultas.
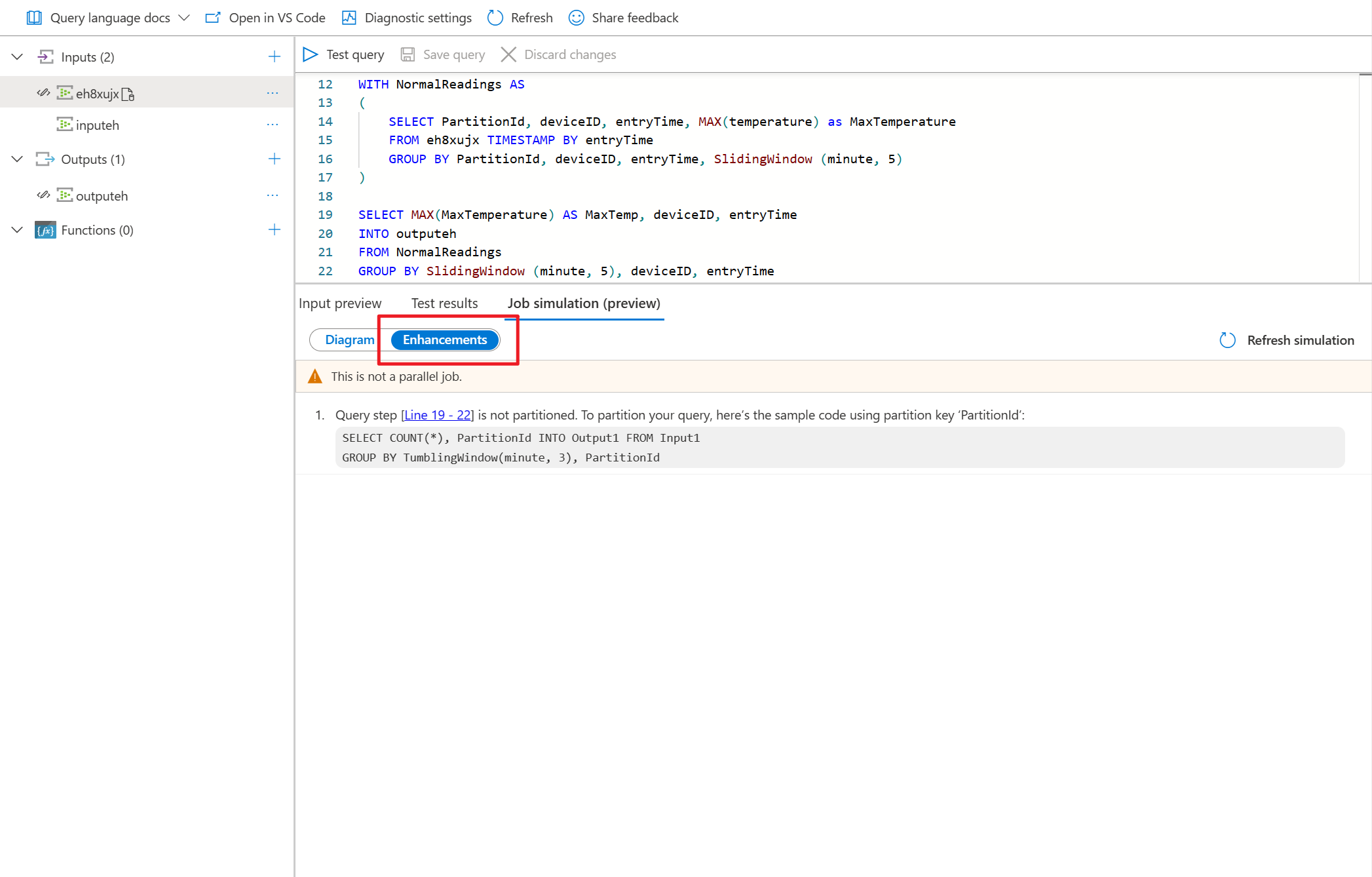
- Ajuste las unidades de streaming para ver cuántas SU necesita para controlar la carga de trabajo.




Diagrama de nivel de procesador
Una vez que haya ajustado las unidades de streaming para simular la topología del trabajo, puede expandir cualquiera de los nodos de streaming para observar cómo se procesan los datos en el nivel de procesador.

El diagrama de nivel de procesador le permite:
- observe cómo se asignan las particiones de entrada y se procesan en cada nodo de streaming.
- Averigüe cuál es el turno de tiempo para cada procesador informático.
- proporcione información sobre si los procesadores de entrada y salida están alineados en paralelo.
Para asignar el procesador con el paso de consulta, seleccione dos veces en el diagrama. Esta característica le ayuda a localizar los pasos de la consulta que realizan la agregación.

Sugerencias de mejora
Estas son las explicaciones de las mejoras:
| Tipo | Significado |
|---|---|
| No se admite la partición personalizada | Cambie la clave de partición "xxx" de entrada a "xxx". |
| Número de particiones que no coinciden | La entrada y la salida deben tener el mismo número de particiones. |
| Claves de partición que no coinciden | La entrada, la salida y cada paso de la consulta deben usar la misma clave de partición. |
| Número de particiones de entrada que no coinciden | Todas las entradas deben tener el mismo número de particiones. |
| Claves de partición de entrada que no coinciden | Todas las entradas deben usar la misma clave de partición. |
| Nivel de compatibilidad bajo | Actualice CompatibilityLevel en el archivo JobConfig.json. |
| No se encontró la clave de partición de salida | Debe usar la clave de partición especificada para la salida. |
| No se admite la partición personalizada | Solo puede usar claves de partición predefinidas. |
| Paso de la consulta que no usa la partición | La consulta no usa ninguna cláusula PARTITION BY. |
Pasos siguientes
Si quiere obtener más información sobre la paralelización de consultas y el diagrama de trabajos, consulte estos tutoriales: