Tutorial: Implementación del patrón de captura de Data Lake para actualizar una tabla de Databricks Delta
En este tutorial se muestra cómo controlar eventos en una cuenta de almacenamiento que tiene un espacio de nombres jerárquico.
Creará una pequeña solución que permitirá a un usuario rellenar una tabla de Databricks Delta al cargar un archivo de valores separados por comas (CSV) que describe un pedido de ventas. Esta solución se creará conectando una suscripción a Event Grid, una función de Azure y un trabajo en Azure Databricks.
En este tutorial, aprenderá lo siguiente:
- Creará una suscripción a Event Grid que llama a una función de Azure.
- Creará una función de Azure que recibe una notificación de un evento y, a continuación, ejecuta el trabajo en Azure Databricks.
- Creará un trabajo de Databricks que inserta un pedido de cliente en una tabla de Databricks Delta que se encuentra en la cuenta de almacenamiento.
Crearemos esta solución en orden inverso, empezando por el área de trabajo de Azure Databricks.
Requisitos previos
Cree una cuenta de almacenamiento que tenga un espacio de nombres jerárquico (Azure Data Lake Storage). En este tutorial se usa una cuenta de almacenamiento denominada
contosoorders.Consulte Creación de una cuenta de almacenamiento para su uso con Azure Data Lake Storage habilitado.
Asegúrese de que la cuenta de usuario tiene asignado el rol Colaborador de datos de Storage Blob.
Cree una entidad de servicio, cree un secreto de cliente y, a continuación, conceda a la entidad de servicio acceso a la cuenta de almacenamiento.
Consulte Tutorial: Conexión a Azure Data Lake Storage (pasos 1 a 3). Después de completar estos pasos, asegúrese de pegar los valores de identificador de inquilino, identificador de aplicación y secreto de cliente en un archivo de texto. ya que los necesitará pronto.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Creación de un pedido de ventas
En primer lugar, cree un archivo CSV que describa un pedido de ventas y, a continuación, cargue ese archivo en la cuenta de almacenamiento. Más adelante, usará los datos de este archivo para rellenar la primera fila de la tabla de Databricks Delta.
Vaya a la nueva cuenta de almacenamiento en Azure Portal.
Seleccione Explorador de almacenamiento->Contenedores de blobs->Agregar contenedor y cree un nuevo contenedor denominado Datos.
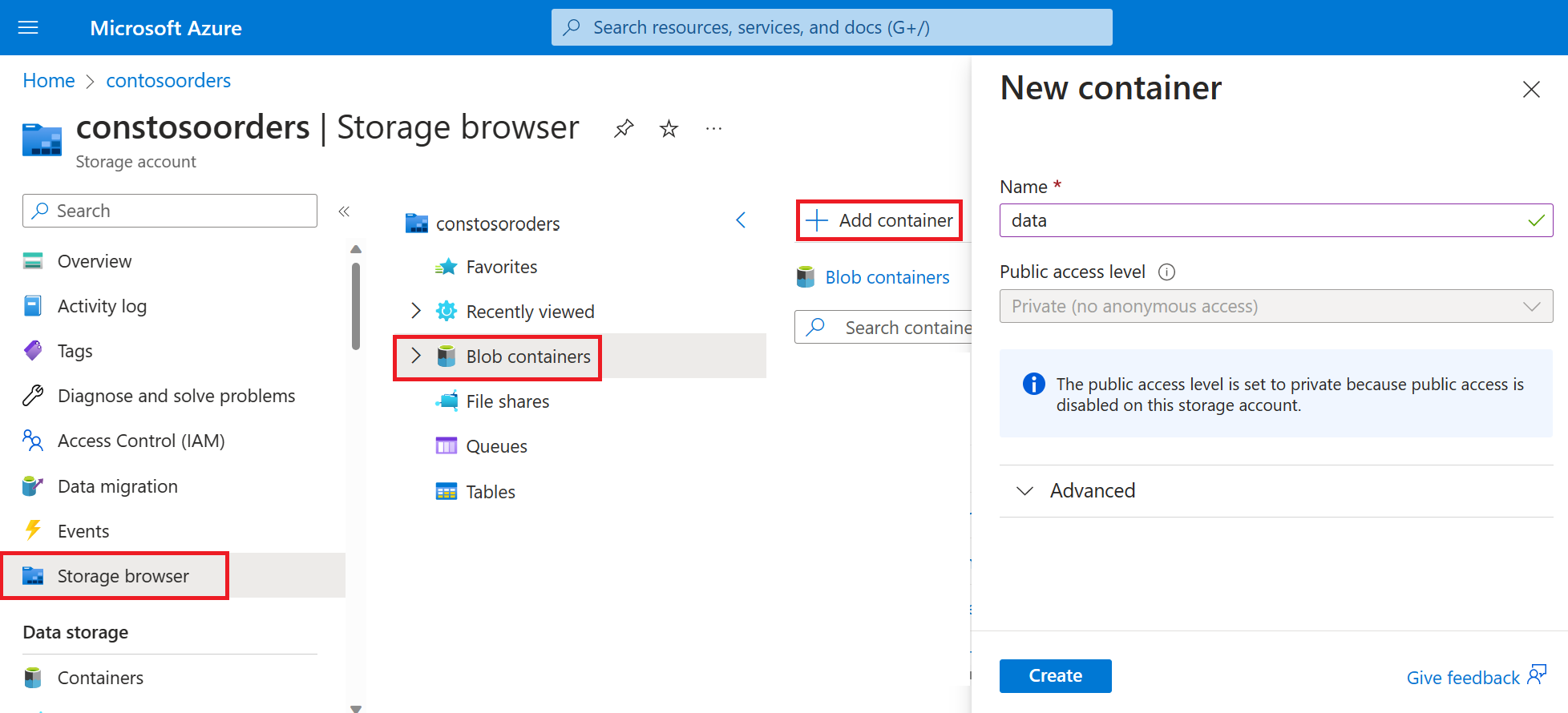
En el contenedor data, cree un directorio denominado input.
En un editor de texto, pegue el texto siguiente.
InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536365,85123A,WHITE HANGING HEART T-LIGHT HOLDER,6,12/1/2010 8:26,2.55,17850,United KingdomGuarde este archivo en el equipo local y asígnele el nombre data.csv.
En el explorador de almacenamiento, cargue este archivo en la carpeta input.
Creación de un trabajo en Azure Databricks
En esta sección, realizará estas tareas:
- Crear un área de trabajo de Azure Databricks.
- Cree un cuaderno.
- Crear y rellenar una tabla de Databricks Delta.
- Agregar código que inserta filas en la tabla de Databricks Delta.
- Crear un trabajo.
Creación de un área de trabajo de Azure Databricks
En esta sección, creará un área de trabajo de Azure Databricks mediante Azure Portal.
Crear un área de trabajo de Azure Databricks. Asigne a esa área de trabajo el nombre
contoso-orders. Consulte Creación de un área de trabajo de Azure Databricks.Crear un clúster. Asigne el nombre
customer-order-clusteral clúster. Consulte Creación de un clúster.Cree un cuaderno. Asigne al cuaderno el nombre
configure-customer-tabley elija Python como lenguaje predeterminado del mismo. Consulte Creación de un cuaderno.
Creación y relleno de una tabla de Databricks Delta
En el cuaderno que ha creado, copie y pegue el siguiente bloque de código en la primera celda, pero no ejecute el código aún.
Reemplace los valores de marcador de posición
appId,passwordytenantpor los valores que recopiló al completar los requisitos previos de este tutorial.dbutils.widgets.text('source_file', "", "Source File") spark.conf.set("fs.azure.account.auth.type", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id", "<appId>") spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>") spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<tenant>/oauth2/token") adlsPath = 'abfss://data@contosoorders.dfs.core.windows.net/' inputPath = adlsPath + dbutils.widgets.get('source_file') customerTablePath = adlsPath + 'delta-tables/customers'Este código crea un widget denominado source_file. Más adelante, creará una función de Azure que llama a este código y pasa una ruta de acceso de archivo a ese widget. Este código también autentica la entidad de servicio con la cuenta de almacenamiento y crea algunas variables que usará en otras celdas.
Nota:
En una configuración de producción, considere la posibilidad de almacenar su clave de autenticación en Azure Databricks. A continuación, agregue una clave de búsqueda a su bloque de código en lugar de la clave de autenticación.
Por ejemplo, en lugar de usar esta línea de código:spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>"), debería usar la siguiente:spark.conf.set("fs.azure.account.oauth2.client.secret", dbutils.secrets.get(scope = "<scope-name>", key = "<key-name-for-service-credential>")).
Una vez completado este tutorial, consulte el artículo Azure Data Lake Storage en el sitio Web de Azure Databricks para ver ejemplos de este enfoque.Presione las teclas MAYÚS + ENTRAR para ejecutar el código de este bloque.
Copie y pegue el siguiente bloque de código en una celda diferente y, a continuación, presione las teclas MAYÚS + ENTRAR para ejecutar el código de este bloque.
from pyspark.sql.types import StructType, StructField, DoubleType, IntegerType, StringType inputSchema = StructType([ StructField("InvoiceNo", IntegerType(), True), StructField("StockCode", StringType(), True), StructField("Description", StringType(), True), StructField("Quantity", IntegerType(), True), StructField("InvoiceDate", StringType(), True), StructField("UnitPrice", DoubleType(), True), StructField("CustomerID", IntegerType(), True), StructField("Country", StringType(), True) ]) rawDataDF = (spark.read .option("header", "true") .schema(inputSchema) .csv(adlsPath + 'input') ) (rawDataDF.write .mode("overwrite") .format("delta") .saveAsTable("customer_data", path=customerTablePath))Este código crea la tabla de Databricks Delta en la cuenta de almacenamiento y, a continuación, carga algunos datos iniciales del archivo CSV que cargó anteriormente.
Después de que este bloque de código se ejecute correctamente, quítelo del cuaderno.
Agregar código que inserta filas en la tabla de Databricks Delta
Copie y pegue el siguiente bloque de código en otra celda, pero no ejecute la celda.
upsertDataDF = (spark .read .option("header", "true") .csv(inputPath) ) upsertDataDF.createOrReplaceTempView("customer_data_to_upsert")Este código inserta datos en una vista de tabla temporal con datos de un archivo CSV. La ruta de acceso a ese archivo CSV procede del widget de entrada que creó en un paso anterior.
Copie y pegue el siguiente bloque de código en una celda distinta. Este código combina el contenido de la vista de tabla temporal con la tabla de Databricks Delta.
%sql MERGE INTO customer_data cd USING customer_data_to_upsert cu ON cd.CustomerID = cu.CustomerID WHEN MATCHED THEN UPDATE SET cd.StockCode = cu.StockCode, cd.Description = cu.Description, cd.InvoiceNo = cu.InvoiceNo, cd.Quantity = cu.Quantity, cd.InvoiceDate = cu.InvoiceDate, cd.UnitPrice = cu.UnitPrice, cd.Country = cu.Country WHEN NOT MATCHED THEN INSERT (InvoiceNo, StockCode, Description, Quantity, InvoiceDate, UnitPrice, CustomerID, Country) VALUES ( cu.InvoiceNo, cu.StockCode, cu.Description, cu.Quantity, cu.InvoiceDate, cu.UnitPrice, cu.CustomerID, cu.Country)
Creación de un trabajo
Cree un trabajo que ejecute el cuaderno que creó anteriormente. Más adelante, creará una función de Azure que ejecuta este trabajo cuando se produce un evento.
Seleccione Nuevo->Trabajo.
Asigne un nombre al trabajo, elija el cuaderno que creó y el clúster. A continuación, seleccione Crear para crear el trabajo.
Creación de una Función de Azure
Cree una función de Azure que ejecute el trabajo.
En el área de trabajo de Azure Databricks, haga clic en el nombre de usuario en la barra superior y seleccione Configuración de usuario en la lista desplegable.
Seleccione Generar nuevo token en la pestaña Tokens de acceso.
Copie el token que se muestra y haga clic en Listo.
En la esquina superior del área de trabajo de Databricks, elija el icono de personas y, a continuación, seleccione Configuración de usuario.

Seleccione el botón Generar nuevo token y, después, el botón Generar.
Asegúrese de copiar el token en un lugar seguro. La función de Azure necesita este token para autenticarse con Databricks, para poder ejecutar el trabajo.
En el menú de Azure Portal o en la página Principal, seleccione Crear un recurso.
En la página Nuevo, seleccione Compute>Function App.
En la pestaña Aspectos básicos de la página Crear aplicación de funciones, elija un grupo de recursos y, a continuación, cambie o compruebe la siguiente configuración:
Configuración Valor Nombre de la aplicación de funciones contosoorder Pila en tiempo de ejecución .NET Publicar Código Sistema operativo Windows Tipo de plan Consumo (sin servidor) Seleccione Revisar y crear y, luego, Crear.
Cuando se complete la implementación, seleccione Ir al recurso para abrir la página Información general de la aplicación de funciones.
En el grupo Configuración, seleccione Configuración.
En la página Configuración de la aplicación, seleccione el botón Nueva configuración de la aplicación para agregar cada opción de configuración.

Agregue la configuración siguiente:
Nombre del valor Value DBX_INSTANCE La región del área de trabajo de Databricks. Por ejemplo: westus2.azuredatabricks.netDBX_PAT El token de acceso personal que generó anteriormente. DBX_JOB_ID El identificador del trabajo en ejecución. Seleccione Guardar para confirmar esta configuración.
En el grupo Funciones, seleccione Funciones y Crear.
Seleccione Azure Event Grid Trigger (Desencadenador de Azure Event Grid).
Instale la extensión Microsoft.Azure.WebJobs.Extensions.EventGrid si se le solicita. Si tiene que instalarla, tendrá que volver a seleccionar Azure Event Grid Trigger (Desencadenador de Azure Event Grid) para crear la función.
Aparecerá el panel Nueva función.
En el panel Nueva función, asigne a la función el nombre UpsertOrder y seleccione el botón Crear.
Reemplace el contenido del archivo de código por este código y seleccione el botón Guardar:
#r "Azure.Messaging.EventGrid" #r "System.Memory.Data" #r "Newtonsoft.Json" #r "System.Text.Json" using Azure.Messaging.EventGrid; using Azure.Messaging.EventGrid.SystemEvents; using Newtonsoft.Json; using Newtonsoft.Json.Linq; private static HttpClient httpClient = new HttpClient(); public static async Task Run(EventGridEvent eventGridEvent, ILogger log) { log.LogInformation("Event Subject: " + eventGridEvent.Subject); log.LogInformation("Event Topic: " + eventGridEvent.Topic); log.LogInformation("Event Type: " + eventGridEvent.EventType); log.LogInformation(eventGridEvent.Data.ToString()); if (eventGridEvent.EventType == "Microsoft.Storage.BlobCreated" || eventGridEvent.EventType == "Microsoft.Storage.FileRenamed") { StorageBlobCreatedEventData fileData = eventGridEvent.Data.ToObjectFromJson<StorageBlobCreatedEventData>(); if (fileData.Api == "FlushWithClose") { log.LogInformation("Triggering Databricks Job for file: " + fileData.Url); var fileUrl = new Uri(fileData.Url); var httpRequestMessage = new HttpRequestMessage { Method = HttpMethod.Post, RequestUri = new Uri(String.Format("https://{0}/api/2.0/jobs/run-now", System.Environment.GetEnvironmentVariable("DBX_INSTANCE", EnvironmentVariableTarget.Process))), Headers = { { System.Net.HttpRequestHeader.Authorization.ToString(), "Bearer " + System.Environment.GetEnvironmentVariable("DBX_PAT", EnvironmentVariableTarget.Process)}, { System.Net.HttpRequestHeader.ContentType.ToString(), "application/json" } }, Content = new StringContent(JsonConvert.SerializeObject(new { job_id = System.Environment.GetEnvironmentVariable("DBX_JOB_ID", EnvironmentVariableTarget.Process), notebook_params = new { source_file = String.Join("", fileUrl.Segments.Skip(2)) } })) }; var response = await httpClient.SendAsync(httpRequestMessage); response.EnsureSuccessStatusCode(); } } }
Este código analiza la información sobre el evento de almacenamiento que se ha generado y, a continuación, crea un mensaje de solicitud con la dirección URL del archivo que desencadenó el evento. Como parte del mensaje, la función pasa un valor al widget source_file que creó anteriormente. El código de la función envía el mensaje al trabajo de Databricks y usa el token que obtuvo anteriormente como autenticación.
Creación de una suscripción de Event Grid
En esta sección, creará una suscripción a Event Grid que llama a la función de Azure cuando los archivos se cargan en la cuenta de almacenamiento.
Seleccione Integración y, en la página Integración, seleccione Desencadenador de Event Grid.
En el panel Editar desencadenador, asigne al evento el nombre
eventGridEventy, a continuación, seleccione Crear suscripción de eventos.Nota
El nombre
eventGridEventcoincide con el parámetro denominado que se pasa a la función de Azure.En la pestaña Aspectos básicos de la página Crear suscripción de eventos, cambie o compruebe la siguiente configuración:
Configuración Valor Nombre contoso-order-event-subscription Tipo de tema Cuenta de almacenamiento Recurso de origen contosoorders Nombre del tema del sistema <create any name>Filtro para tipos de evento Blob creado y Blob eliminado Seleccione el botón Crear.
Comprobación de la suscripción a Event Grid
Cree un archivo denominado
customer-order.csv, pegue la siguiente información en ese archivo y guárdelo en el equipo local.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,228,1/1/2018 9:01,33.85,20993,Sierra LeoneEn el Explorador de Storage, cargue este archivo en la carpeta input de su cuenta de almacenamiento.
Al cargar un archivo, se genera el evento Microsoft.Storage.BlobCreated. Event Grid notifica a todos los suscriptores de ese evento. En nuestro caso, la función de Azure es el único suscriptor. La función de Azure analiza los parámetros del evento para determinar qué evento se ha producido. A continuación, pasa la dirección URL del archivo al trabajo de Databricks. El trabajo de Databricks lee el archivo y agrega una fila a la tabla de Databricks Delta que se encuentra en su cuenta de almacenamiento.
Para comprobar si el trabajo se realizó correctamente, consulte las ejecuciones del trabajo. Verá un estado de finalización. Para obtener más información sobre cómo ver las ejecuciones de un trabajo, consulte Visualización de ejecuciones de un trabajo.
En una nueva celda del libro, ejecute esta consulta para ver la tabla Delta actualizada.
%sql select * from customer_dataLa tabla devuelta muestra el registro más reciente.

Para actualizar este registro, cree un archivo denominado
customer-order-update.csv, pegue la siguiente información en ese archivo y guárdelo en el equipo local.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,22,1/1/2018 9:01,33.85,20993,Sierra LeoneEste archivo CSV es casi idéntico al anterior, salvo que la cantidad del pedido se cambia de
228a22.En el Explorador de Storage, cargue este archivo en la carpeta input de su cuenta de almacenamiento.
Ejecute la consulta
selectde nuevo para ver la tabla delta actualizada.%sql select * from customer_dataLa tabla devuelta muestra el registro actualizado.

Limpieza de recursos
Cuando ya no los necesite, elimine el grupo de recursos y todos los recursos relacionados. Para ello, seleccione el grupo de recursos de la cuenta de almacenamiento y seleccione Eliminar.