Acerca de los planes de recuperación
En este artículo se proporciona información general sobre los planes de recuperación de Azure Site Recovery.
Un plan de recuperación agrupa máquinas en grupos de recuperación, para la conmutación por error. Un plan de recuperación ayudar a definir un proceso de recuperación sistemático mediante la creación de unidades pequeñas e independientes que puede conmutar por error. Normalmente, una unidad representa una aplicación en el entorno.
- Un plan de recuperación define cómo conmutan por error las máquinas y la secuencia en la que se inician después de la conmutación por error.
- Los planes de recuperación se pueden usar para la conmutación por error a Azure y la conmutación por recuperación desde Azure.
- Se pueden agregar hasta 100 instancias protegidas a un plan de recuperación.
- Puede personalizar un plan agregándole un orden, instrucciones y tareas.
- Cuando un plan está definido, puede ejecutar una conmutación por error en él.
- Se puede hacer referencia a las máquinas en varios planes de recuperación; de este modo, los planes posteriores omiten la implementación o inicio de una máquina si se implementó anteriormente a través de otro plan de recuperación.
- Después de la conmutación por error, se recomienda no cambiar una máquina virtual de un plan de recuperación y agregarla a otro, ya que nuestro back-end usa el nombre del plan de recuperación para identificar la operación de conmutación por error.
¿Por qué usar un plan de recuperación?
Utilice planes de recuperación para:
- Modelar una aplicación alrededor de sus dependencias.
- Automatizar las tareas de recuperación para reducir el objetivo de tiempo de recuperación (RTO).
- Verificar que está preparado para la migración o la recuperación ante desastres asegurándose de que las aplicaciones forman parte de un plan de recuperación.
- Ejecutar conmutaciones por error de prueba en los planes de recuperación para garantizar que la recuperación ante desastres o la migración funciona según lo previsto.
Modelado de aplicaciones
Puede planear y crear un grupo de recuperación para capturar propiedades específicas de la aplicación. Por ejemplo, consideremos una aplicación típica de tres niveles con un back-end de servidor SQL, un software intermedio y un front-end web. Por lo general, personalizará el plan de recuperación para que las máquinas de cada nivel se inicien en el orden correcto después de la conmutación por error.
- El back-end SQL debe iniciarse en primer lugar, luego el software intermedio y, por último, el front-end web.
- Este orden garantiza que para cuando la última máquina se inicia, la aplicación está en funcionamiento.
- Este orden garantiza que cuando el software intermedio se inicia e intenta conectarse al nivel de SQL Server, este nivel ya se está ejecutando.
- Este orden también ayuda a garantizar que el servidor front-end se inicie el último, por lo que los usuarios finales no se conectan a la dirección URL de la aplicación hasta que todos los componentes estén en funcionamiento y la aplicación esté lista para aceptar solicitudes.
Para crear este orden, se agregan grupos al grupo de recuperación y se incorporan máquinas a los grupos.
Cuando se especifica el orden, se utiliza la secuenciación. Las acciones se ejecutan en paralelo según corresponda para mejorar el RTO de recuperación de aplicaciones.
Las máquinas de un único grupo conmutan por error en paralelo.
Las máquinas de diferentes grupos conmutan por error en el orden del grupo, por lo que las máquinas del grupo 2 inician su conmutación por error después de que las máquinas del grupo 1 hayan conmutado por error y se hayan iniciado.
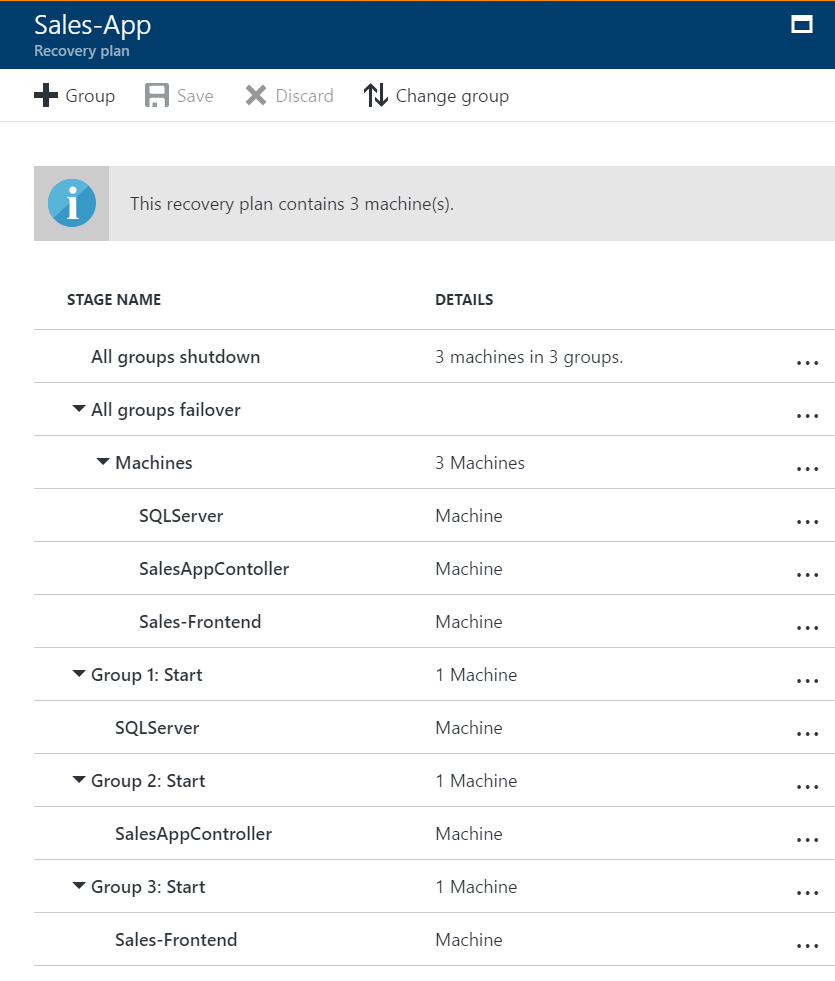
Con esta personalización implementada, aquí se muestra lo que ocurre cuando se ejecuta una conmutación por error en el plan de recuperación:
- Un paso de apagado intenta desactivar las máquinas locales. La excepción es si se ejecuta una conmutación por error de prueba, en cuyo caso el sitio primario continúa ejecutándose.
- El apagado desencadena una conmutación por error en paralelo de todas las máquinas del plan de recuperación.
- La conmutación por error prepara los discos de la máquina virtual mediante los datos replicados.
- Los grupos de inicio se ejecutan en orden e inician las máquinas de cada grupo. En primer lugar, se ejecuta el grupo 1, luego el grupo 2 y, por último, el grupo 3. Si hay más de una máquina en un grupo, todas las máquinas se inician en paralelo.
Automatización de tareas en los planes de recuperación
La recuperación de aplicaciones de gran tamaño puede ser una tarea compleja. Los pasos manuales hacen que el proceso sea propenso a errores y la persona que ejecuta la conmutación por error podría no conocer las complejidades de la aplicación. Puede usar un plan de recuperación para imponer el orden y automatizar las acciones necesarias en cada paso utilizando para ello runbooks de Azure Automation para conmutar por error a Azure o scripts. En el caso de tareas que no se pueden automatizar, puede insertar pausas para acciones manuales en los planes de recuperación. Hay un par de tipos de tareas que puede configurar:
- Tareas en la VM de Azure después de la conmutación por error: cuando conmuta por error a Azure, normalmente debe realizar acciones para poder conectarse a la VM después de la conmutación por error. Por ejemplo:
- Crear una dirección IP pública en la VM de Azure.
- Asignar a un grupo de seguridad de red al adaptador de red de la VM de Azure.
- Agregar un equilibrador de carga a un conjunto de disponibilidad.
- Tareas dentro de la VM después a la conmutación por error: estas tareas normalmente reconfiguran la aplicación que se ejecuta en la máquina a fin de que siga funcionando correctamente en el nuevo entorno. Por ejemplo:
- Modificar la cadena de conexión de base de datos dentro de la máquina.
- Cambiar la configuración o las reglas del servidor web.
Ejecución de una conmutación por error de prueba en los planes de recuperación
Puede usar un plan de recuperación para desencadenar una conmutación por error de prueba. Utilice los siguientes procedimientos recomendados:
Complete siempre una conmutación por error de prueba en una aplicación antes de ejecutar una conmutación por error completa. Las conmutaciones por error de prueba ayudan a comprobar si la aplicación aparece en el sitio de recuperación.
Si observa que le falta algo, desencadene una limpieza y luego vuelva a ejecutar la conmutación por error de prueba.
Ejecute una conmutación por error de prueba varias veces hasta que sepa con certeza que la aplicación se recupera sin problemas.
Como cada aplicación es diferente, es necesario crear planes de recuperación personalizados para cada de ellas una y ejecutar una conmutación por error de prueba en todas ellas.
Las aplicaciones y sus dependencias cambian con frecuencia. Para asegurarse de que los planes de recuperación están actualizados, ejecute una conmutación por error de prueba para cada aplicación trimestralmente.
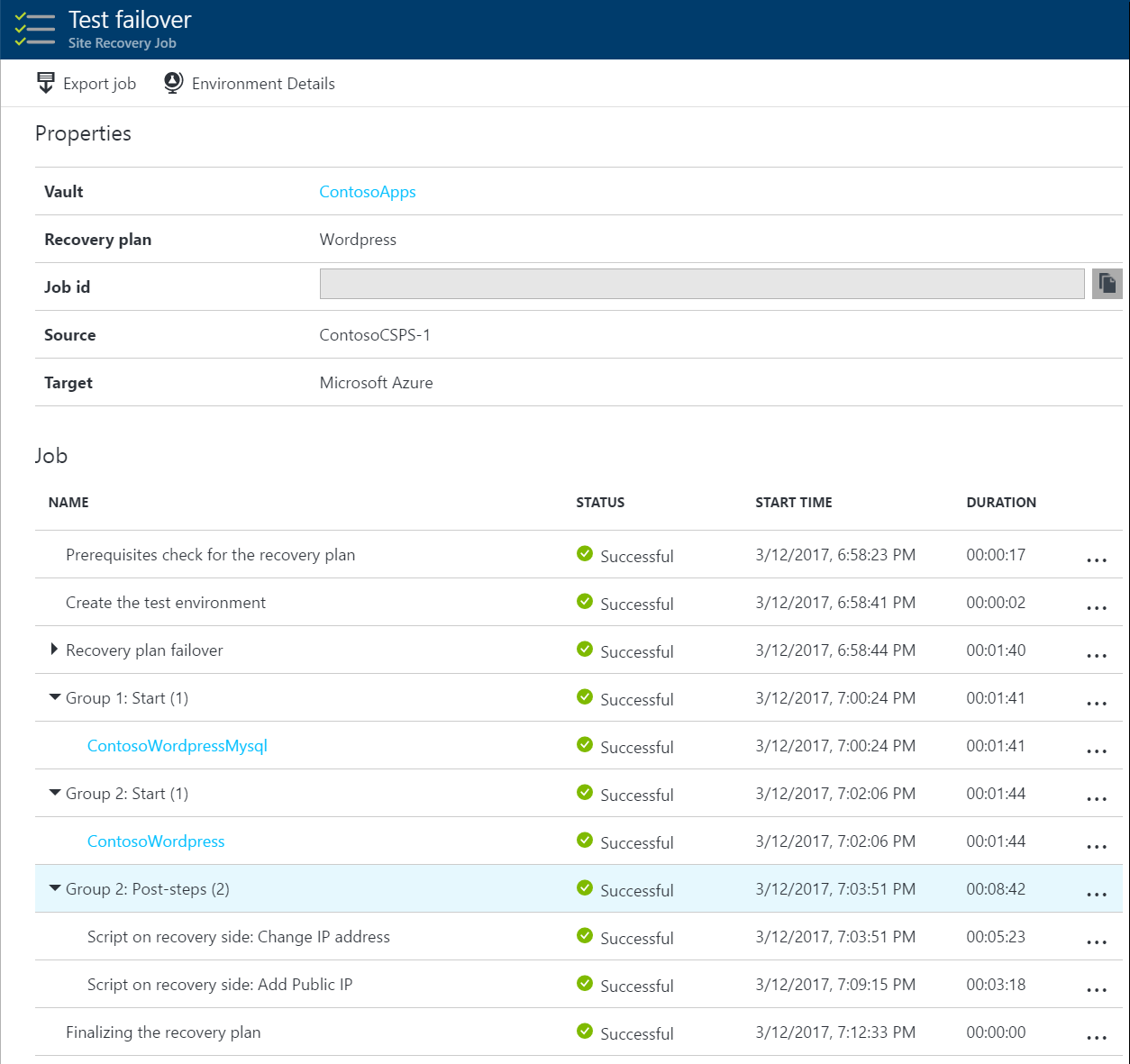
Visualización de un vídeo de plan de recuperación
Vea un vídeo de ejemplo rápido que muestra una conmutación por error al hacer clic para un plan de recuperación para una aplicación de WordPress de dos niveles.