Azure Traffic Manager con Azure Site Recovery
Azure Traffic Manager permite controlar la distribución del tráfico a través de los puntos de conexión de la aplicación. Un punto de conexión es cualquier servicio accesible desde Internet hospedado dentro o fuera de Azure.
Traffic Manager usa el sistema de nombres de dominio (DNS) para dirigir las solicitudes del cliente al punto de conexión más adecuado en función de un método de enrutamiento del tráfico y el mantenimiento de los puntos de conexión. Traffic Manager proporciona una serie de métodos de enrutamiento del tráfico y opciones de supervisión del punto de conexión para satisfacer las distintas necesidades de las aplicaciones y los modelos de conmutación automática por error. Los clientes se conectan directamente al punto de conexión seleccionado. Traffic Manager no es un proxy ni una puerta de enlace, y no ve el tráfico que circula entre el cliente y el servicio.
En este artículo se describe cómo combinar el enrutamiento inteligente de Azure Traffic Manager con las funcionalidades de recuperación ante desastres y migración de Azure Site Recovery.
Conmutación por error del entorno local a Azure
En el primer escenario, tenemos la Compañía A donde toda su infraestructura de aplicaciones se ejecuta en el entorno local. Para garantizar la continuidad del negocio y el cumplimiento de las normas, la empresa A decide usar Azure Site Recovery para proteger sus aplicaciones.
La Compañía A ejecuta aplicaciones con puntos de conexión públicos y desea tener la posibilidad de redirigir completamente el tráfico a Azure en caso de desastre. El método de enrutamiento del tráfico de Prioridad de Azure Traffic Manager permite que la Compañía A implemente fácilmente este patrón de conmutación por error.
La configuración es la siguiente:
- La Compañía A crea un perfil de Traffic Manager.
- Mediante el método de enrutamiento de Prioridad, la Compañía A crea dos puntos de conexión: uno Principal para el entorno local y otro de Conmutación por error para Azure. Al punto de conexión Principal se le asigna la Prioridad 1 y al de Conmutación por error la Prioridad 2.
- Puesto que el punto de conexión Principal se hospeda fuera de Azure, el punto de conexión se crea como un punto de conexión Externo.
- Con Azure Site Recovery, el sitio de Azure no tiene máquinas virtuales ni aplicaciones que se ejecuten antes de la conmutación por error. Por lo tanto, el punto de conexión de Conmutación por error también se crea como un punto de conexión Externo.
- De forma predeterminada, el tráfico de usuario se dirige a la aplicación local porque ese punto de conexión lleva asociada la prioridad más alta. Si el punto de conexión Principal tiene un estado correcto, no se dirige ningún tráfico a Azure.
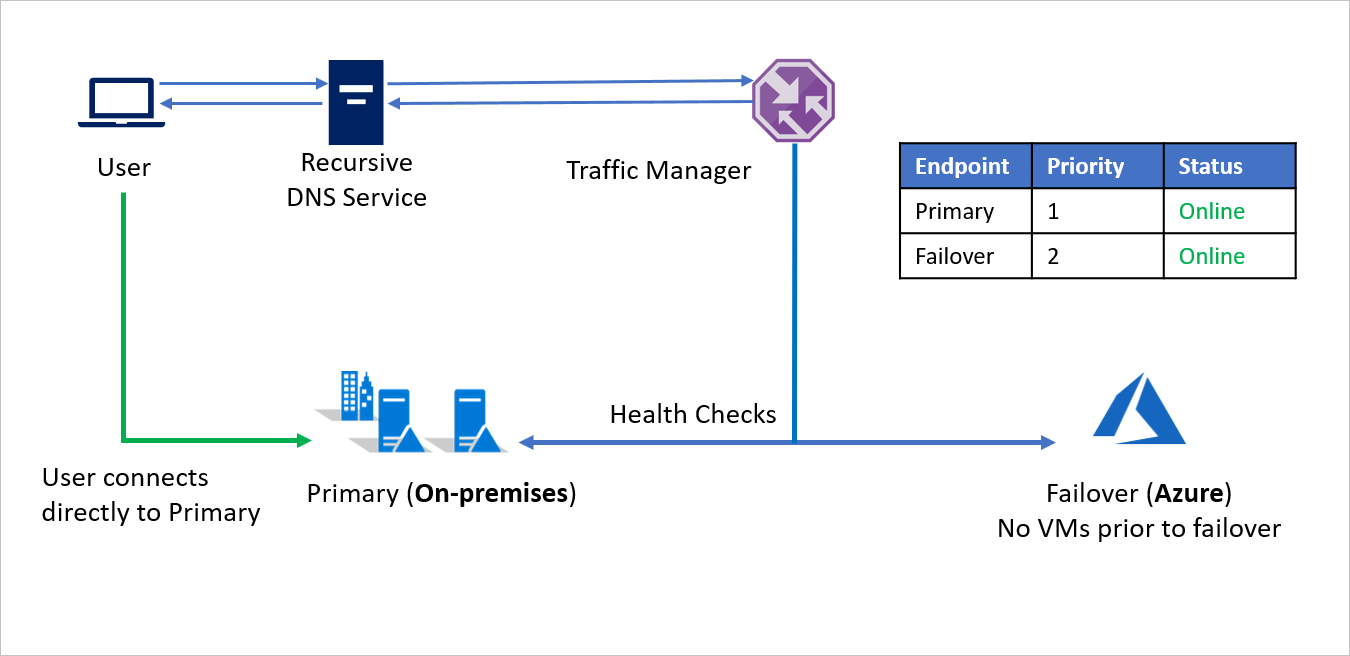
En caso de desastre, la Compañía A puede desencadenar una conmutación por error a Azure y recuperar sus aplicaciones en Azure. Cuando Azure Traffic Manager detecta que el punto de conexión Principal ya no tiene un estado correcto, usa automáticamente el punto de conexión de Conmutación por error en la respuesta DNS y los usuarios se conectan a la aplicación recuperada en Azure.

En función de sus requisitos empresariales, la Compañía A puede elegir una frecuencia de sondeo mayor o menor para cambiar entre el entorno local y Azure en caso de desastre, y así garantizar un tiempo de inactividad mínimo para los usuarios.
Cuando el desastre está controlado, la Compañía A puede conmutar por recuperación de Azure a su entorno local (VMware o Hyper-V) mediante Azure Site Recovery. Luego, cuando Traffic Manager detecta que el punto de conexión Principal tiene de nuevo un estado correcto, lo usa automáticamente en sus respuestas DNS.
Migración del entorno local a Azure
Además de la recuperación ante desastres, Azure Site Recovery también permite migraciones a Azure. Gracias a las eficaces funcionalidades de conmutación por error de prueba de Azure Site Recovery, los clientes pueden valorar el rendimiento de las aplicaciones en Azure sin que su entorno local resulte afectado. Y, cuando estén listos para migrar, pueden elegir migrar cargas de trabajo enteras todas juntas o migrarlas y escalarlas gradualmente.
El método de enrutamiento Ponderado de Azure Traffic Manager puede usarse para dirigir parte del tráfico de entrada a Azure, mientras se dirige la mayoría al entorno local. Este enfoque puede ayudar a valorar el rendimiento a escala, dado que puede seguir aumentando el peso asignado a Azure a medida que se migran más y más cargas de trabajo a Azure.
Por ejemplo, la Compañía B elige migrar en fases, así que mueve parte de su entorno de aplicaciones, pero conserva el resto de forma local. Durante las fases iniciales en que la mayor parte del entorno es local, se asigna un peso mayor a dicho entorno. Traffic Manager devuelve un punto de conexión en función de los pesos asignados a los puntos de conexión disponibles.
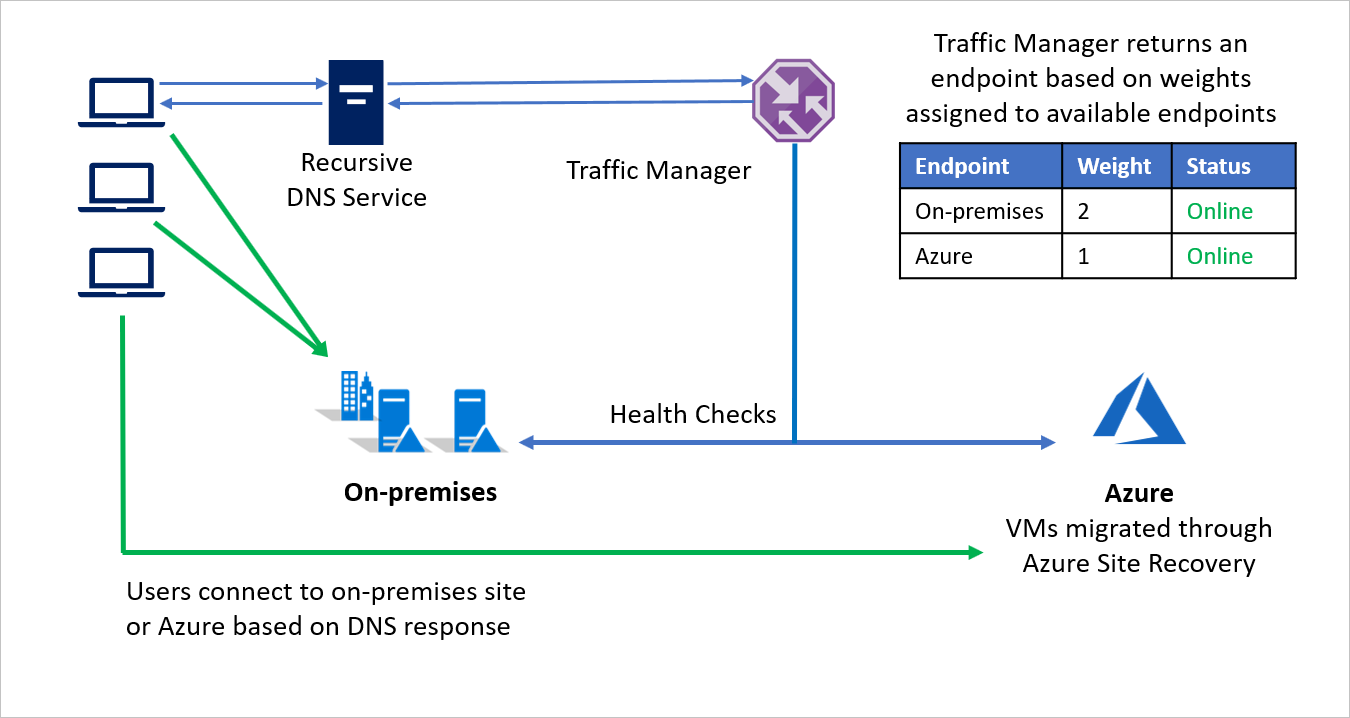
Durante la migración, ambos puntos de conexión están activos y la mayoría del tráfico se dirige al entorno local. Mientras tiene lugar la migración, se puede asignar un peso mayor al punto de conexión en Azure y, para finalizar, se puede desactivar el punto de conexión local después de la migración.
Conmutación por error de Azure a Azure
En este ejemplo, tenemos la Compañía C en la que toda su infraestructura de aplicaciones se ejecuta en Azure. Para garantizar la continuidad empresarial y por motivos de cumplimiento, la Compañía C decide usar Azure Site Recovery para proteger sus aplicaciones.
La Compañía C ejecuta aplicaciones con puntos de conexión públicos y desea tener la posibilidad de redirigir completamente el tráfico a una región diferente de Azure en caso de desastre. El método de enrutamiento de tráfico de Prioridad permite que la Compañía C implemente fácilmente este patrón de conmutación por error.
La configuración es la siguiente:
- La Compañía C crea un perfil de Traffic Manager.
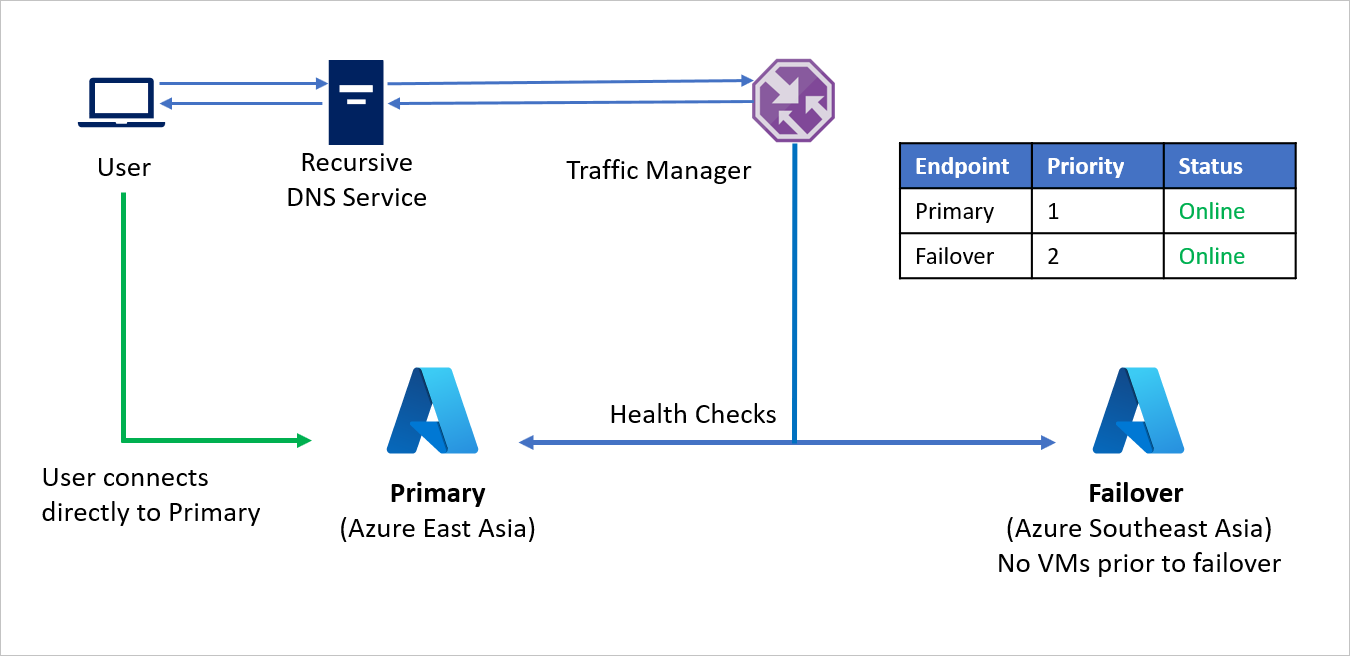
- Mediante el método de enrutamiento de Prioridad, la Compañía C crea dos puntos de conexión: uno Principal para la región de origen (Azure Este de Asia) y otro de Conmutación por error para la región de recuperación (Azure Sudeste de Asia). Al punto de conexión Principal se le asigna la Prioridad 1 y al de Conmutación por error la Prioridad 2.
- Dado que el punto de conexión Principal está hospedado en Azure, el punto de conexión puede ser un punto de conexión de Azure.
- Con Azure Site Recovery, el sitio de Azure de recuperación no tiene máquinas virtuales o aplicaciones que se ejecuten antes de la conmutación por error. Por lo tanto, el punto de conexión de Conmutación por error se puede crear como un punto de conexión Externo.
- Como el punto de conexión lleva asociada la prioridad más alta, el tráfico de usuario se dirige de forma predeterminada a la aplicación de la región de origen (Este de Asia, en este caso). Si el punto de conexión Principal tiene un estado correcto, no se dirige ningún tráfico a la región de recuperación.
En caso de desastre, la Compañía C puede desencadenar una conmutación por error y recuperar sus aplicaciones en la región de Azure de recuperación. Cuando Azure Traffic Manager detecta que el punto de conexión Principal ya no tiene un estado correcto, usa automáticamente el punto de conexión de Conmutación por error en la respuesta DNS y los usuarios se conectan a la aplicación recuperada en la región de Azure de recuperación (Sudeste de Asia).
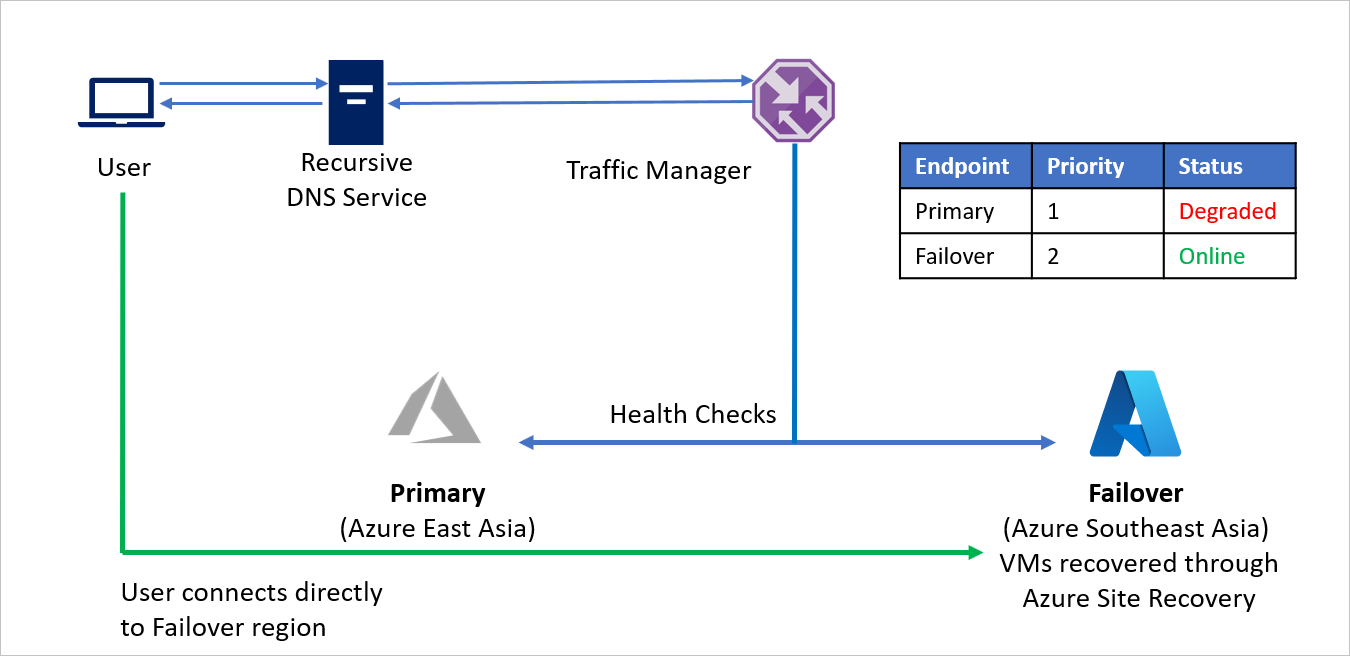
En función de sus requisitos empresariales, la Compañía C puede elegir una frecuencia de sondeo mayor o menor para cambiar entre las regiones de origen y de recuperación, y así garantizar un tiempo de inactividad mínimo para los usuarios.
Una vez controlado el desastre, la Compañía C puede conmutar por recuperación de la región de Azure de recuperación a la región de Azure de origen mediante Azure Site Recovery. Luego, cuando Traffic Manager detecta que el punto de conexión Principal tiene de nuevo un estado correcto, lo usa automáticamente en sus respuestas DNS.
Protección de aplicaciones empresariales de varias regiones
Para mejorar la experiencia del cliente, las empresas globales suelen adaptar sus aplicaciones para atender las necesidades regionales. La localización y la reducción de la latencia pueden conducir a la división de la infraestructura de aplicaciones entre regiones. Las empresas también están limitadas por las leyes sobre datos regionales en determinadas áreas y eligen aislar una parte de su infraestructura de aplicaciones dentro de los límites regionales.
Vamos a ver un ejemplo donde la Compañía D ha dividido sus puntos de conexión de aplicaciones para atender por una parte a Alemania y por la otra al resto del mundo. La Compañía D usa el método de enrutamiento Geográfico de Azure Traffic Manager para configurar este escenario. Todo el tráfico que se origina en Alemania se dirige al Punto de conexión 1 y todo el tráfico que se origina fuera de Alemania se dirige al Punto de conexión 2.
El problema con esta configuración es que si el Punto de conexión 1 deja de funcionar por algún motivo, no hay una redirección del tráfico al Punto de conexión 2. El tráfico que se origina en Alemania se sigue redirigiendo al Punto de conexión 1 sin tener en cuenta su estado, de forma que los usuarios de Alemania se quedan sin acceso a las aplicaciones de la Compañía D. Igualmente, si el Punto de conexión 2 se queda sin conexión, no hay ninguna redirección del tráfico al Punto de conexión 1.
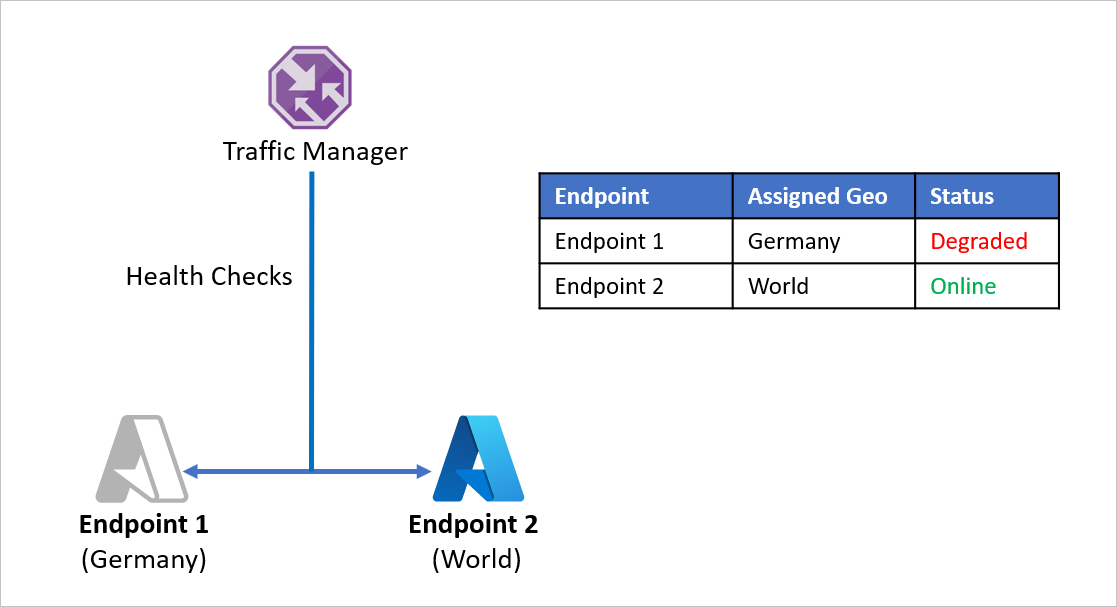
Para evitar este problema y garantizar la resistencia de las aplicaciones, la Compañía D usa perfiles de Traffic Manager anidados con Azure Site Recovery. En una configuración de perfil anidado, el tráfico no se redirige a puntos de conexión individuales, sino a otros perfiles de Traffic Manager. Así es cómo funciona esta configuración:
- En lugar de utilizar el enrutamiento Geográfico con puntos de conexión individuales, la Compañía D usa el enrutamiento Geográfico con perfiles de Traffic Manager.
- Cada perfil de Traffic Manager secundario usa el enrutamiento de Prioridad con un punto de conexión principal y de recuperación, de ahí que se anide el enrutamiento de Prioridad dentro del enrutamiento Geográfico.
- Para permitir la resistencia de la aplicación, en cada distribución de la carga de trabajo se usa Azure Site Recovery para conmutar por error a una región de recuperación en caso de desastre.
- Cuando la instancia principal de Traffic Manager recibe una consulta DNS, se dirige a la instancia de Traffic Manager secundaria pertinente, que responde a la consulta con un punto de conexión disponible.
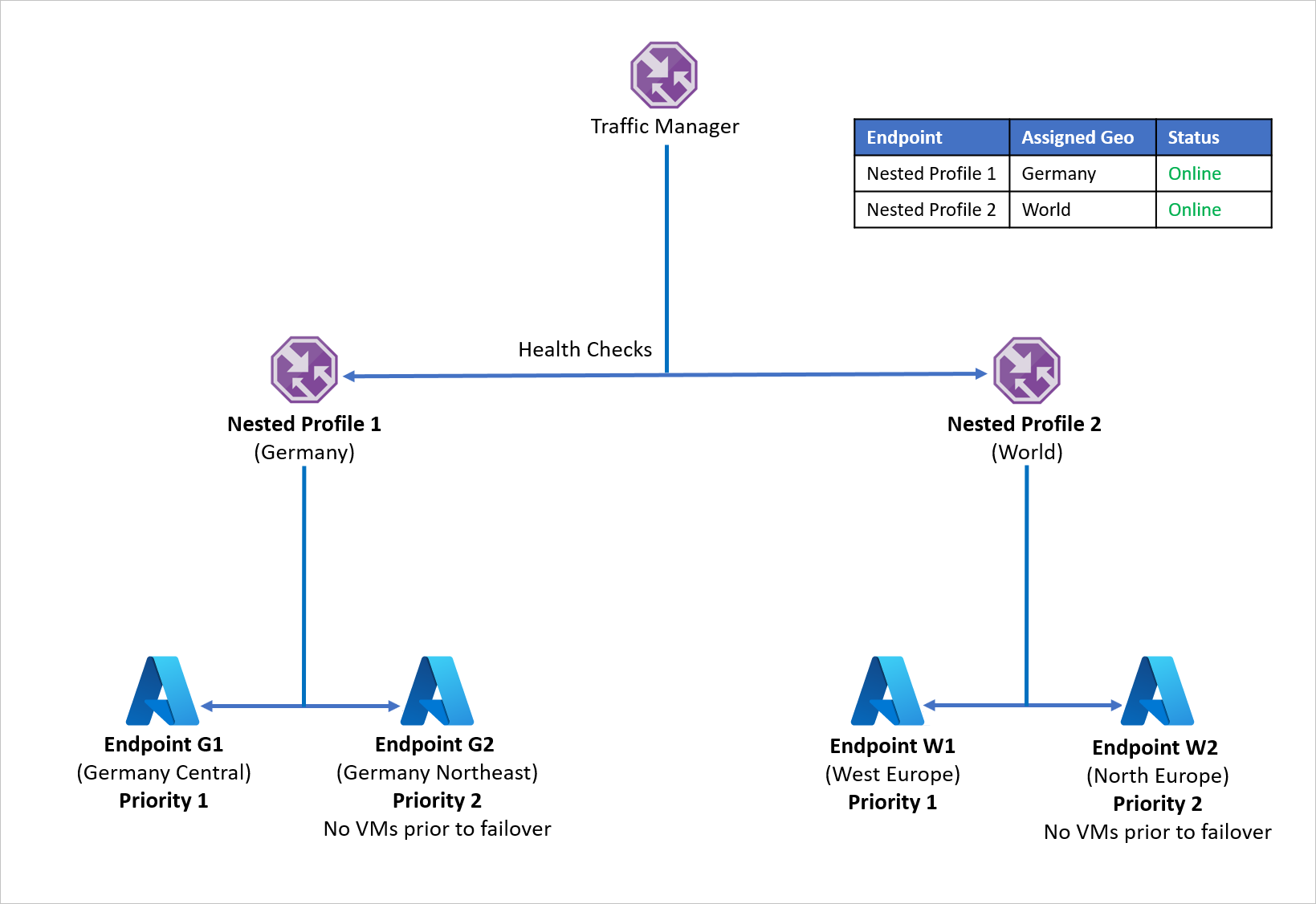
Por ejemplo, si se produce un error en el punto de conexión de Centro de Alemania, la aplicación se puede recuperar rápidamente en el Nordeste de Alemania. El nuevo punto de conexión controla el tráfico que se origina en Alemania con un tiempo de inactividad mínimo para los usuarios. Del mismo modo, una interrupción del punto de conexión en Oeste de Europa se puede controlar mediante la recuperación de la carga de trabajo de aplicación en Norte de Europa, puesto que Azure Traffic Manager redirige las solicitudes DNS al punto de conexión disponible.
La configuración anterior se puede ampliar para incluir tantas combinaciones de región y punto de conexión como sean necesarias. Traffic Manager permite hasta 10 niveles de perfiles anidados y no permite bucles dentro de la configuración anidada.
Consideraciones sobre el objetivo de tiempo de recuperación (RTO)
En la mayoría de las organizaciones, las tareas de agregar o modificar registros DNS las realiza un equipo independiente o alguna persona externa a la organización. Como consecuencia, la modificación de los registros DNS se convierte en un proceso muy complicado El tiempo necesario para actualizar los registros DNS por parte de otros equipos u organizaciones que administran la infraestructura de DNS varía de una organización a otra y afecta al RTO de la aplicación.
Con Traffic Manager, puede adelantar el trabajo necesario para las actualizaciones de DNS. No es necesaria ninguna acción manual ni mediante scripts en el momento de la conmutación por error real. Este enfoque contribuye a un cambio rápido (y de ahí a un menor RTO), además de que se evitan los costosos y trabajosos errores de cambio de DNS en caso de desastre. Con Traffic Manager, incluso el paso de conmutación por recuperación se automatiza, que, de lo contrario, habría de administrarse aparte.
El establecimiento del intervalo de sondeo correcto mediante comprobaciones básicas o rápidas de mantenimiento del intervalo puede reducir de forma considerable el RTO durante la conmutación por error y disminuir el tiempo de inactividad de los usuarios.
Además, puede optimizar el valor de período de vida (TTL) de DNS para el perfil de Traffic Manager. TTL es el valor durante el cual un cliente almacenaría en caché una entrada DNS. Un registro DNS no se consultaría dos veces en el período de TTL. Cada registro DNS tiene un TTL asociado. Si se reduce este valor se producen más consultas DNS a Traffic Manager, pero puede disminuir el RTO al detectarse las interrupciones de manera más rápida.
El TTL que experimenta el cliente tampoco aumenta si el número de resoluciones DNS entre el cliente y el servidor DNS autoritativo se incrementa. Las resoluciones DNS realizan la "cuenta atrás" del TTL y solo pasan un valor de TTL que refleja el tiempo transcurrido desde que el registro se almacenó en la caché. De esta forma, se garantiza que el registro DNS llega actualizado al cliente después del TTL, con independencia del número de resoluciones DNS en la cadena.
Pasos siguientes
- Más información sobre los métodos de enrutamiento de Traffic Manager.
- Más información sobre los perfiles anidados de Traffic Manager.
- Más información sobre la supervisión de los puntos de conexión.
- Más información sobre los planes de recuperación para automatizar la conmutación por error de las aplicaciones.