Planeación de la capacidad para las aplicaciones de Service Fabric
En este documento se ofrece información sobre cómo estimar la cantidad de recursos (CPU, RAM o almacenamiento en disco) que necesita para ejecutar las aplicaciones de Azure Service Fabric. Es normal que las necesidades de recursos cambien con el paso del tiempo. Normalmente necesitará menos recursos mientras desarrolla o prueba su servicio y luego una cantidad mayor cuando pase a producción y su aplicación se vuelva cada vez más popular. Al diseñar la aplicación, piense en los requisitos a largo plazo y haga elecciones que permitan escalar el servicio para adaptarse a las elevadas exigencias de los clientes.
Cuando cree el clúster de Service Fabric, decidirá qué tipos de máquinas virtuales (VM) lo compondrán. Cada máquina virtual viene con una cantidad limitada de recursos en forma de CPU (núcleos y velocidad), ancho de banda de red, RAM y almacenamiento en disco. A medida que crezca su servicio con el tiempo, puede actualizar a máquinas virtuales que ofrezcan mayores recursos o agregar más máquinas virtuales al clúster. Para esto último, debe diseñar su servicio inicialmente para que pueda aprovechar las nuevas máquinas virtuales que se agreguen de forma dinámica al clúster.
Algunos servicios administran pocos datos o ninguno en las propias máquinas virtuales. Por lo tanto, el planeamiento de la capacidad de estos servicios debe centrarse principalmente en el rendimiento, lo que supone seleccionar las CPU adecuadas (núcleos y velocidad) de las máquinas virtuales. Además, debe tener en cuenta el ancho de banda de red y, incluso con qué frecuencia se producen transferencias de red y la cantidad de datos que se transfieren. Si el servicio debe funcionar bien a medida que aumente su uso, puede agregar más máquinas virtuales al clúster y equilibrar la carga de las solicitudes de red entre todas las máquinas virtuales.
En el caso de servicios que administran gran cantidad de datos en las máquinas virtuales, el planeamiento de la capacidad debe centrarse principalmente en el tamaño. Por tanto, debe considerar cuidadosamente la capacidad de la RAM y del almacenamiento de disco de la máquina virtual. El sistema de administración de memoria virtual de Windows crea espacio en disco, como la RAM, para el código de aplicación. Además, el entorno de tiempo de ejecución de Service Fabric proporciona paginación inteligente que mantiene en memoria solo los datos activos y mueve al disco los inactivos. Así las aplicaciones pueden usar más memoria que la disponible físicamente en la máquina virtual. Con solo más RAM aumenta el rendimiento, dado que la máquina virtual puede mantener más almacenamiento en disco en la memoria RAM. La máquina virtual que seleccione debe tener un disco lo suficientemente grande como para almacenar los datos que quiera en la máquina virtual. De igual forma, la máquina virtual debe tener suficiente RAM para proporcionar el rendimiento deseado. Si los datos del servicio aumentan con el tiempo, puede agregar más máquinas virtuales al cluster y distribuir los datos entre todas las máquinas virtuales.
Determinación del número de nodos que necesita
La creación de particiones para el servicio le permite escalar horizontalmente los datos del servicio. Para más información sobre las particiones, consulte Creación de particiones de Service Fabric. Cada partición debe ajustarse a una sola máquina virtual, pero se pueden colocar varias particiones (pequeñas) en una sola máquina virtual. Por lo tanto, tener más particiones pequeñas le proporciona mayor flexibilidad que tener pocas particiones más grandes. El inconveniente es que el hecho de tener muchas particiones aumenta la sobrecarga de Service Fabric y no podrá realizar operaciones de transacciones entre ellas. También, existe la posibilidad de un mayor tráfico de red si su código de servicio necesita acceder con frecuencia a fragmentos de datos que residen en particiones diferentes. Al diseñar su servicio, debe sopesar detenidamente estas ventajas e inconvenientes hasta dar con una estrategia de partición efectiva.
Supongamos que la aplicación tiene un único servicio con estado que tiene un tamaño de almacén que se espera que crezca a DB_Size GB en un año. Desea agregar más aplicaciones (y particiones) porque observa un crecimiento más allá de ese año. El factor de replicación (RF), que determina el número de réplicas del servicio que afecta al valor de DB_Size total. El tamaño de DB_Size total en todas las réplicas es el factor de replicación multiplicado por el valor de DB_Size. Node_Size representa el espacio en disco o la memoria RAM por cada nodo que desea usar para el servicio. Para conseguir el mejor rendimiento, el valor de DB_Size debe ajustarse a la memoria en el clúster, y se debe elegir el valor de Node_Size que más se aproxime a la RAM de la máquina virtual. Al asignar un valor de Node_Size que sea mayor que la capacidad de RAM, está confiando en la paginación proporcionada por el entorno de tiempo de ejecución de Service Fabric. Por lo tanto, es posible que si los datos enteros se consideran activos (dado que entonces los datos están paginados dentro y fuera), el rendimiento no sea óptimo. Sin embargo, en servicios en los que solo una fracción de los datos es activa, este enfoque resulta más rentable.
El número de nodos necesario para obtener el máximo rendimiento se puede calcular de la manera siguiente:
Number of Nodes = (DB_Size * RF)/Node_Size
Consideración sobre el crecimiento
Puede calcular el número de nodos en función del valor de DB_Size de crecimiento que espera del servicio, además del valor de DB_Size con el que comienza. Después, aumente el número de nodos a medida que el servicio crece, a fin de evitar un aprovisionamiento excesivo del número de nodos. Sin embargo, el número de particiones debería basarse en el número de nodos necesarios al ejecutar su servicio con un crecimiento máximo.
Resulta conveniente disponer de máquinas adicionales en cualquier momento, así puede controlar los posibIes picos o errores inesperados (por ejemplo, si algunas máquinas virtuales se vuelven inactivas). Aunque la capacidad adicional se debe determinar teniendo en cuenta los picos esperados, un punto de partida es reservar algunas máquinas adicionales (un 5 o 10 por ciento adicional).
Todo lo anterior se refiere a un único servicio con estado. Si tiene más de un servicio con estado, tendrá que agregar a la ecuación el valor de DB_Size asociado con los otros servicios. Como alternativa, puede calcular el número de nodos por separado para cada servicio con estado. El servicio puede tener réplicas o particiones que no están equilibradas. Tenga en cuenta que hay particiones que pueden tener más datos que otras. Para más información sobre la creación de particiones, consulte el artículo sobre la creación de particiones en los procedimientos recomendados. Sin embargo, la ecuación anterior es independiente del número de particiones y réplicas, ya que Service Fabric se asegura de que las réplicas se distribuyan entre los nodos de una manera optimizada.
Uso de una hoja de cálculo para calcular costos
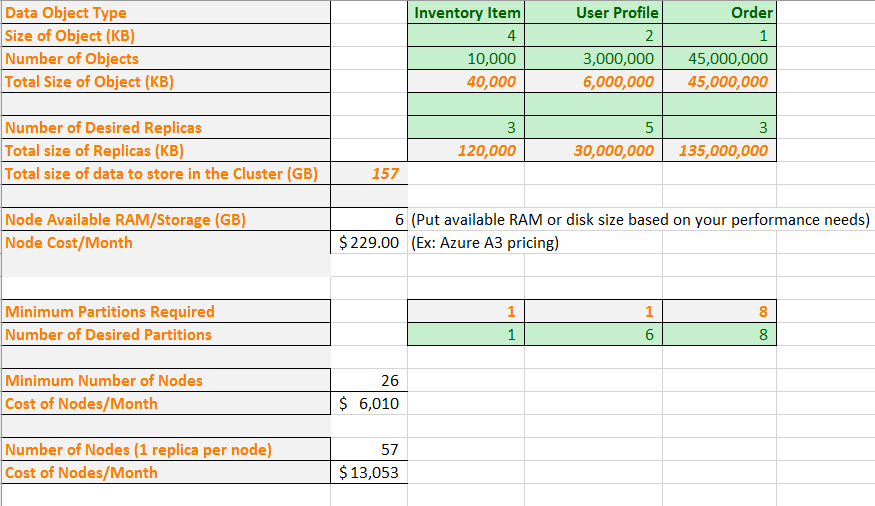
A continuación vamos a usar la fórmula anterior con números reales. En la hoja de cálculo de ejemplo se muestra cómo planear la capacidad de una aplicación que contiene tres tipos de objetos de datos. Para cada objeto, estimamos su tamaño y cuántos objetos esperamos que tenga. También hemos seleccionado el número de réplicas que queremos de cada tipo de objeto. La hoja de cálculo calcula la cantidad total de memoria que se almacenará en el clúster.
A continuación, escribimos un tamaño de máquina virtual y un costo mensual. En función del tamaño de la máquina virtual, la hoja de cálculo nos dice el número mínimo de particiones entre las que debe dividir los datos para que quepan físicamente en los nodos. Puede que quiera un número mayor de particiones para adaptarse a las necesidades específicas de cálculo y tráfico de red de su aplicación. La hoja de cálculo muestra que el número de particiones que administran los objetos del perfil de usuario ha aumentado de uno a seis.
Ahora, en función de esta información, la hoja de cálculo muestra que podría obtener físicamente todos los datos con las particiones y réplicas deseadas en un clúster de 26 nodos. Sin embargo, este clúster estaría muy cargado, así que puede que quiera nodos adicionales para hacer frente a posible actualizaciones y errores de los nodos. La hoja de cálculo también muestra que tener más de 57 nodos no proporciona ningún valor adicional, ya que tendría nodos vacíos. De nuevo, puede que desee de todas formas llegar a 57 nodos en previsión de actualizaciones o errores de los nodos. Puede ajustar la hoja de cálculo para que coincida con las necesidades específicas de su aplicación.
Pasos siguientes
Consulte Creación de particiones de los servicios de Service Fabric para más información al respecto.