Replicación de mensajes y federación entre regiones
Dentro de los espacios de nombres, Azure Service Bus admite la creación de topologías de suscripciones a colas y temas encadenadas mediante el reenvío automático para permitir la implementación de varios patrones de enrutamiento. Por ejemplo, puede proporcionar a los asociados colas dedicadas para la que tengan permisos de envío o recepción y que se puedan suspender temporalmente si es necesario, y conectarlas de forma flexible a otras entidades que sean privadas para la aplicación. También puede crear topologías complejas de enrutamiento en varias fases, o puede crear colas de estilo buzón, que vacían las suscripciones de temas de tipo cola y permiten una mayor capacidad de almacenamiento por suscriptor.
Muchas soluciones sofisticadas también requieren que los mensajes se repliquen entre los límites del espacio de nombres para implementar estos y otros patrones. Es posible que los mensajes deban fluir entre espacios de nombres asociados a varios inquilinos de aplicaciones diferentes, o a través de varias regiones de Azure diferentes.
La solución mantendrá varios espacios de nombres de Service Bus en distintas regiones y replicará mensajes entre colas y temas; o puede que intercambie mensajes con orígenes y destinos como Azure Event Hubs, Azure IoT Hub o Apache Kafka.
En estos escenarios se centra este artículo.
Patrones de federación
Existen numerosas razones para querer mover mensajes entre las entidades de Service Bus, como Colas o Temas, o entre Service Bus y otros orígenes y destinos.
Si comparamos el conjunto de patrones similar de Event Hubs, la federación de entidades de tipo cola es más compleja, ya que las colas de mensajes prometen a sus consumidores la propiedad exclusiva sobre cualquier mensaje único y se espera que mantengan el orden de llegada en la entrega de mensajes y que el agente coordine la distribución equitativa de los mensajes entre consumidores simultáneos.
Existen impedimentos prácticos, incluidas las restricciones del teorema de CAP, que hacen que sea difícil proporcionar una vista unificada de una cola que esté disponible a la vez en varias regiones y que permita que los consumidores simultáneos distribuidos regionalmente tomen posesión exclusiva de los mensajes. Esta cola distribuida geográficamente requeriría una replicación completamente coherente no solo de los mensajes, sino también del estado de entrega de cada uno antes de que los mensajes se puedan poner a disposición de los consumidores. Uno de los objetivos de una coherencia completa en una cola hipotética distribuida regionalmente choca directamente con el objetivo principal que prácticamente tienen todos los clientes de Azure Service Bus al considerar los escenarios de federación: disponibilidad y confiabilidad máximas de sus soluciones.
Los patrones aquí presentados, por tanto, se centran en la disponibilidad y la confiabilidad, a la vez que también pretenden evitar la pérdida de información y la administración duplicada de los mensajes.
Resistencia contra eventos de disponibilidad regional
Aunque la disponibilidad y la confiabilidad máximas son las prioridades operativas principales de Service Bus, hay muchas maneras de impedir que un productor o consumidor se comuniquen con su instancia de Service Bus "principal" asignada debido a problemas de red o de resolución de nombres; también, puede suceder que una entidad de Service Bus deje de responder temporalmente o que devuelva errores. El procesador de mensajes designado también podría dejar de estar disponible.
Estas condiciones no son tan "desastrosas" como para desear abandonar la implementación regional por completo como podría hacer en una situación de recuperación ante desastres. Sin embargo, el escenario empresarial de algunas aplicaciones podría estar ya afectado por eventos de disponibilidad que no duran más de unos minutos o incluso segundos. Azure Service Bus se usa a menudo en entornos de nube híbrida y con clientes que residen en el perímetro de la red, por ejemplo, en tiendas minoristas, restaurante, sucursales bancarias, sitios de fabricación, instalaciones de logística y aeropuertos. Es posible que un problema de enrutamiento o de congestión de la red afecte a la capacidad de un sitio para alcanzar su punto de conexión de Service Bus asignado, mientras que un punto de conexión secundario en una región distinta podría estar accesible. Al mismo tiempo, los sistemas que procesan mensajes que llegan de estos sitios pueden seguir teniendo impedimentos de acceso tanto al punto de conexión principal como al secundario de Service Bus.
Existen muchos ejemplos prácticos de estas aplicaciones de nube híbrida y perimetrales con una baja tolerancia empresarial a los efectos de los problemas transitorios de enrutamiento de red o disponibilidad de una entidad de Service Bus. Entre ellos cabe citar el procesamiento de pagos en los sitios de comercio minorista, el embarque en las puertas de los aeropuertos y los pedidos mediante el teléfono móvil en los restaurantes, todos los cuales se paralizan completa e instantáneamente cada vez que no está disponible la ruta de comunicación confiable.
En esta categoría, se describen tres patrones distribuidos distintos: replicación "todo-activo", replicación "activo-pasivo" y replicación de "desborde".
Replicación todo activo
El patrón de replicación "todo-activo" permite que una réplica activa del mismo tema (o cola) lógico esté disponible en varios espacios de nombres (y regiones) y que todos los mensajes estén disponibles en todas las réplicas, con independencia de dónde se hayan puesto en cola. Normalmente, el patrón conserva el orden de los mensajes con respecto a cualquier editor.
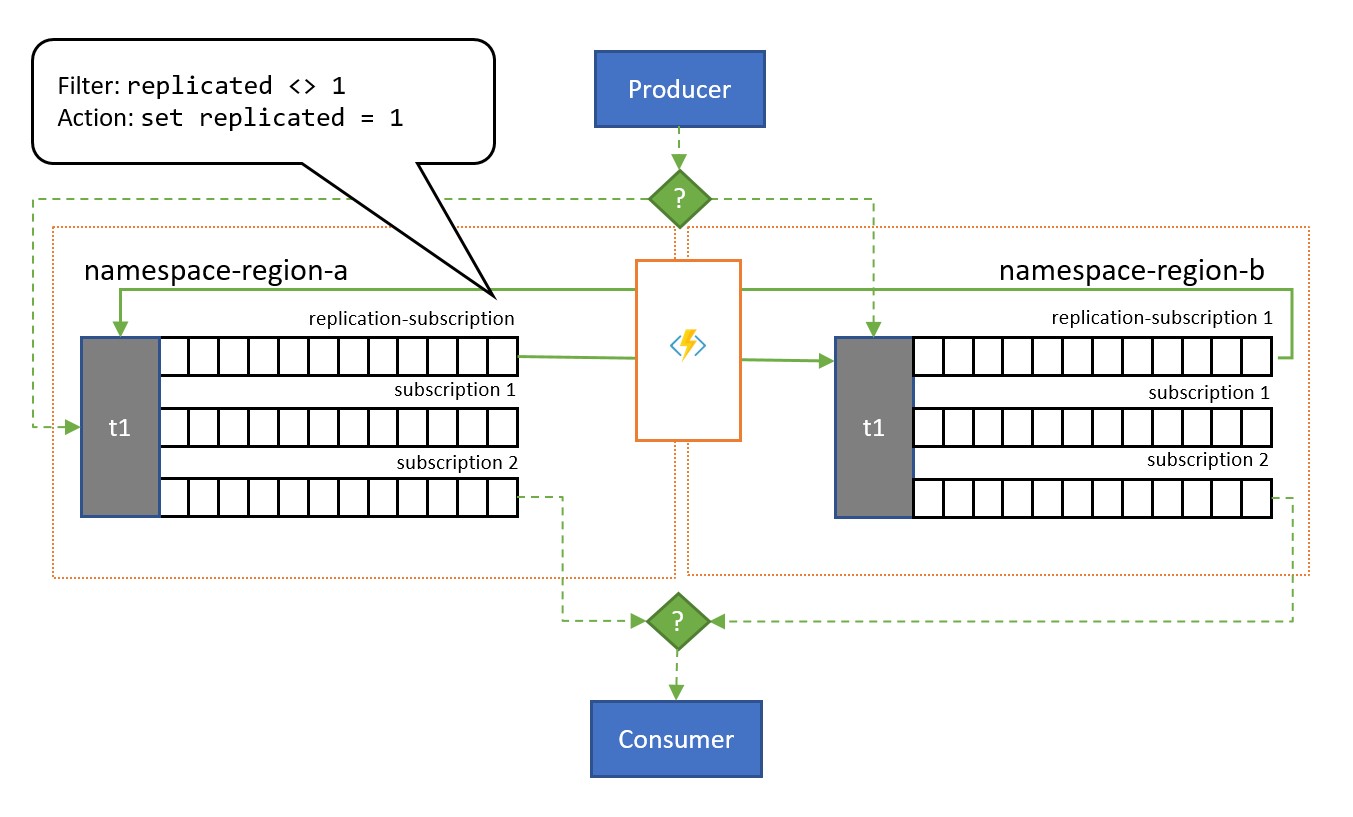
Como se muestra en la ilustración, el patrón generalmente se apoya en los temas de Service Bus. Un tema para cada espacio de nombres que participará en el esquema de replicación. Cada uno de estos temas tiene una "suscripción de replicación" para cualquiera de los otros temas en los que se replicarán los mensajes. En la ilustración anterior, simplemente tenemos un par de temas y, por lo tanto, una única suscripción de replicación para el otro tema. En un escenario con tres espacios de nombres {N1, N2, N3} , un tema del espacio de nombres n1 tendría dos suscripciones de replicación, una para el tema correspondiente en n2 y otra para el tema correspondiente en n3.
Cada suscripción de replicación tiene una regla que combina una expresión de filtro SQL (replicated <> 1) y una acción de SQL (set replicated = 1). El filtro de la regla garantiza que solo los mensajes en los que la propiedad personalizada replication no esté establecida o no tengan el valor 1 sean elegibles para esta suscripción, y la acción establece esa propiedad exacta en el valor 1 de cada mensaje seleccionado justo después. El efecto es que, cuando el mensaje se copia en el tema correspondiente, ya no es elegible para la replicación en la dirección opuesta y, por lo tanto, se evita que los mensajes reboten entre las réplicas.
Una suscripción con una regla respectiva puede agregarse fácilmente a cualquier tema mediante la CLI de Azure, como esta.
az servicebus topic subscription rule create --resource-group myresourcegroup \
--namespace mynamespace --topic-name mytopic \
--subscription-name replication --name replication \
--action-sql-expression "set replication = 1" \
--filter-sql-expression "replication IS NULL"
Para modelar una cola, cada tema está restringido solo a una suscripción normal (distinta de las suscripciones de replicación) que todos los consumidores comparten.
El modelo de replicación todo activo coloca una copia de cada mensaje enviado en cualquiera de los temas en cada uno de los temas. Esto significa que el código de aplicación de cada región verá y procesará todos los mensajes. Este patrón es adecuado para escenarios en los que los datos se comparten en varias regiones, o si, por lo general, se desea un procesamiento redundante. Si necesita procesar todos los mensajes solo una vez, como con una cola normal, debe tener en cuenta uno de los dos patrones siguientes.
Replicación activo-pasivo
El patrón de replicación "activo-pasivo" es una variación del patrón anterior donde solo uno de los temas (el "principal") se usa activamente en la aplicación para enviar y recibir mensajes y los mensajes se replican en un tema secundario en caso de que el tema principal deje de estar disponible o no se pueda acceder a él.
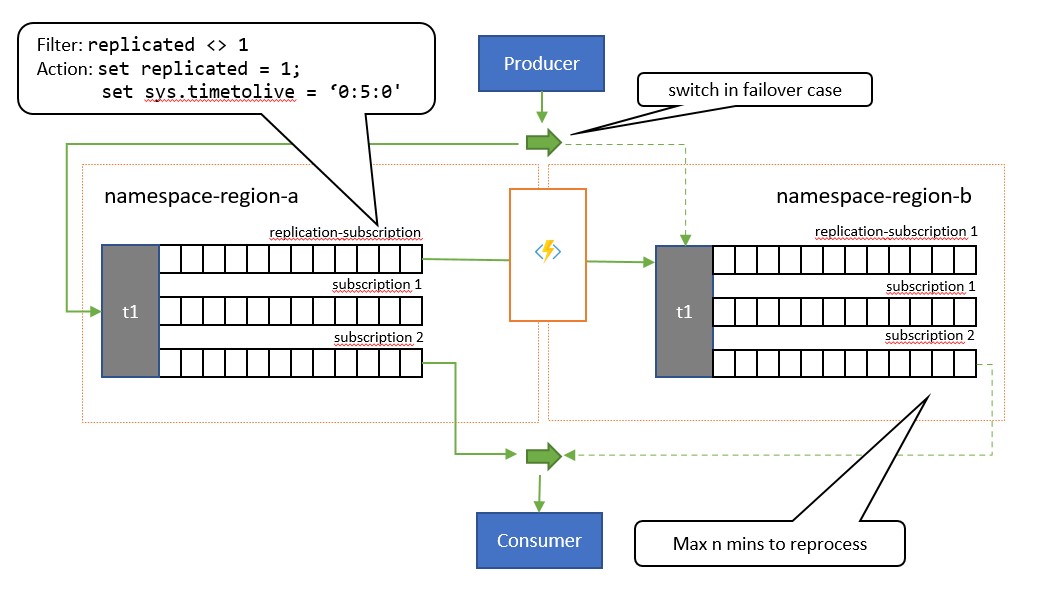
La principal diferencia entre este patrón y el patrón anterior es que la replicación es unidireccional desde el tema principal hasta el tema secundario. El tema secundario nunca se convierte en el principal, pero es una opción de copia de seguridad para cuando el tema principal está temporalmente inutilizable.
La ventaja de usar este patrón es que intenta ayudar a minimizar el procesamiento duplicado. Durante la replicación, la propiedad del mensaje TimeToLive se establece en una duración en los mensajes replicados que refleja el tiempo esperado durante el que un error de la réplica principal provocará una conmutación por error. Por ejemplo, si su escenario de caso de uso requiere que el consumidor conmute a la réplica secundaria en un 1 minuto como máximo cuando la recuperación de mensajes de la réplica principal comienza a mostrar problemas, la réplica secundaria debería tener todos los mensajes disponibles a los que no se pudo acceder en la principal, pero un número mínimo de mensajes que ya se habían procesado desde la principal antes de que aparecieran los problemas. Si establecemos el valor de TimeToLive en dos veces ese período, 2 minutos, durante la replicación (set sys.TimeToLive = '0:2:0' en la acción de la regla), la réplica secundaria solo conservará los mensajes durante 2 minutos y descartará los más antiguos. Esto significa que, cuando el receptor conmuta a la réplica secundaria, se pueden leer rápidamente los mensajes y descartar los anteriores al último que se procesó y, luego, realizar el procesamiento desde el primer mensaje que todavía no ha aparecido. La duración real de la retención dependerá del caso de uso específico y de lo rápido que quiera y pueda conmutar a la réplica secundaria en la aplicación. El valor TimeToLive se respeta en el intervalo de unos segundos a días.
Mientras la aplicación usa la réplica secundaria, también puede publicar directamente en el tema secundario, que, entonces, actúa como lo haría cualquier tema normal. Después de la conmutación a la réplica secundaria, el consumidor verá una combinación de mensajes replicados y mensajes publicados directamente en esta. Por lo tanto, la aplicación debe cambiar primero la publicación de nuevo a la réplica principal y seguir permitiendo el vaciado de los mensajes publicados localmente antes de volver a cambiar al consumidor a la réplica secundaria. Debido a que la replicación se reanuda automáticamente una vez que la réplica principal vuelve a estar disponible, el consumidor también recibirá los nuevos mensajes publicados en la réplica principal durante ese tiempo, aunque con una latencia algo más alta.
Este patrón es adecuado para escenarios en los que los mensajes deben procesarse una sola vez. La aplicación debe cooperar en el seguimiento de los mensajes que se han procesado desde la réplica principal, ya que se encontrarán duplicados durante la ejecución de la ventana de conmutación por error en la réplica secundaria y se volverán a encontrar duplicados mientras se cambia de nuevo. El criterio de desduplicación debe ser un valor de
MessageIdproporcionado por la aplicación. El valor deEnqueuedTimeUtctambién es adecuado como indicador de marca de agua, pero la aplicación debe permitir alguna deriva de reloj (varios segundos) entre la réplica principal y la secundaria como con cualquier sistema distribuido.
Replicación de desborde
El patrón de replicación de "desborde" permite el uso activo/activo de varias entidades de Service Bus en varias regiones para tratar el escenario en el que el estado de Service Bus es correcto, pero el consumidor se ve desbordado por el número de mensajes pendientes o no está inmediatamente disponible. Una razón de ello podría ser que una base de datos que respalda el proceso del consumidor puede ser lenta o no estar disponible. Este patrón funciona con colas sin formato y con suscripciones a temas.
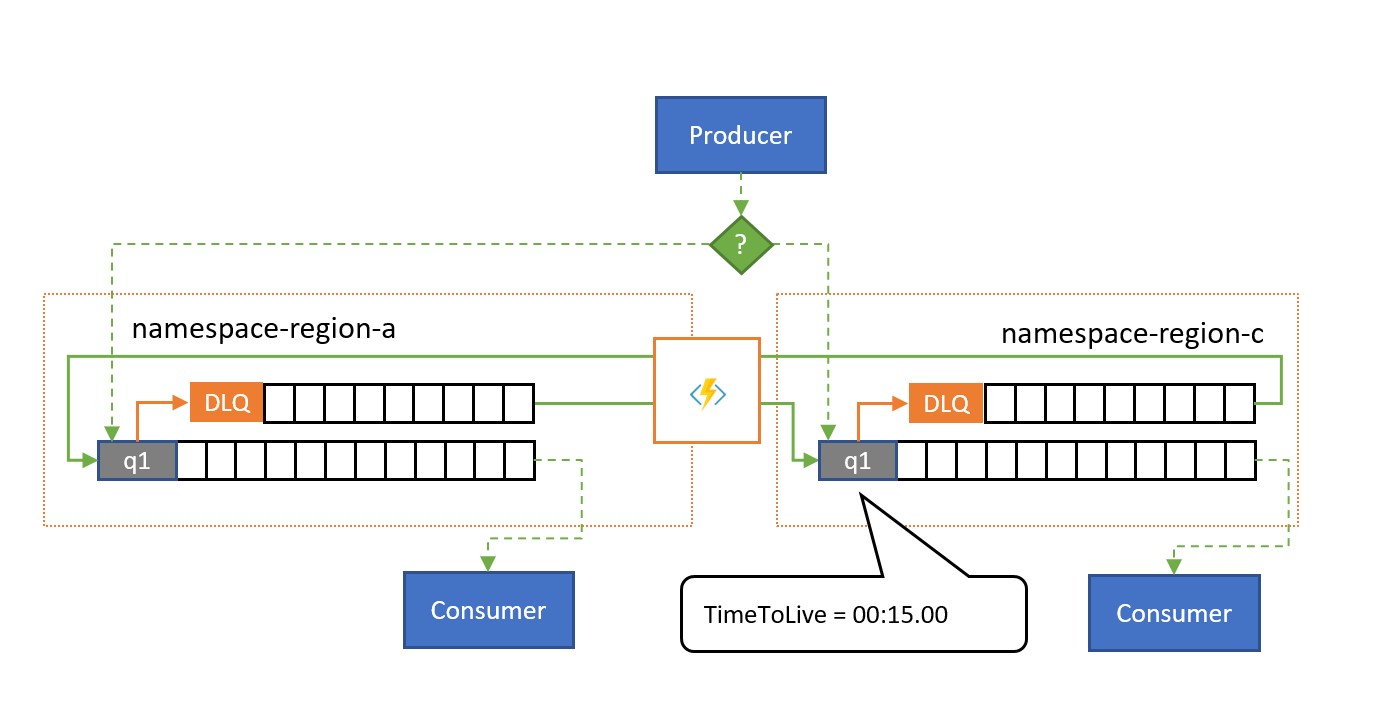
Como se muestra en la ilustración, el patrón de replicación de desborde replica los mensajes de una cola de mensajes fallidos asociada de una cola o suscripción a una cola o tema emparejados en un espacio de nombres diferente.
Si no hay una situación de error, los dos espacios de nombres se usan en paralelo: cada uno recibe un subconjunto del tráfico de mensajes general y sus consumidores asociados administran ese subconjunto. Cuando uno de los consumidores comienza a presentar tasas de error elevadas o se detiene de inmediato, los mensajes correspondientes terminan en la cola de mensajes fallidos bien porque se supera el número de entregas o porque expiran. Es entonces cuando las tareas de replicación los recogen y los vuelven a poner en cola, en la cola emparejada, donde se presentan al consumidor con un estado supuestamente correcto.
Si el procesamiento debe realizarse dentro de un plazo determinado, el valor de TimeToLive de la cola o los mensajes debe establecerse de modo que la réplica secundaria de desborde aún pueda procesarlos a tiempo; por ejemplo, TimeToLive se puede establecer en la mitad del tiempo permitido.
Al igual que con el patrón todo-activo, la aplicación puede agregar un indicador al mensaje si este ya se ha replicado una vez para que no rebote entre el par de colas, sino que se publique en una cola auxiliar que actúe como cola de mensajes fallidos para el patrón compuesto.
Este patrón es adecuado en escenarios en los que la preocupación principal es defenderse contra los problemas de disponibilidad de los consumidores o de los recursos de los que estos dependen, y también para redistribuir los picos de tráfico de una de las colas emparejadas. También ofrece protección en caso de que uno de los espacios de nombres no esté disponible si los consumidores leen las dos colas, pero el retraso de replicación impuesto por la expiración de
TimeToLivepuede hacer que los mensajes dentro de ese período de tiempo se dejen abandonados en el espacio de nombres no disponible.
Optimización de la latencia
Los temas se usan para distribuir información a varios consumidores. En algunos casos, como el de los consumidores con una distribución geográfica amplia, puede ser beneficioso replicar los mensajes de un tema a otro de un espacio de nombres secundario más próximo a los consumidores.
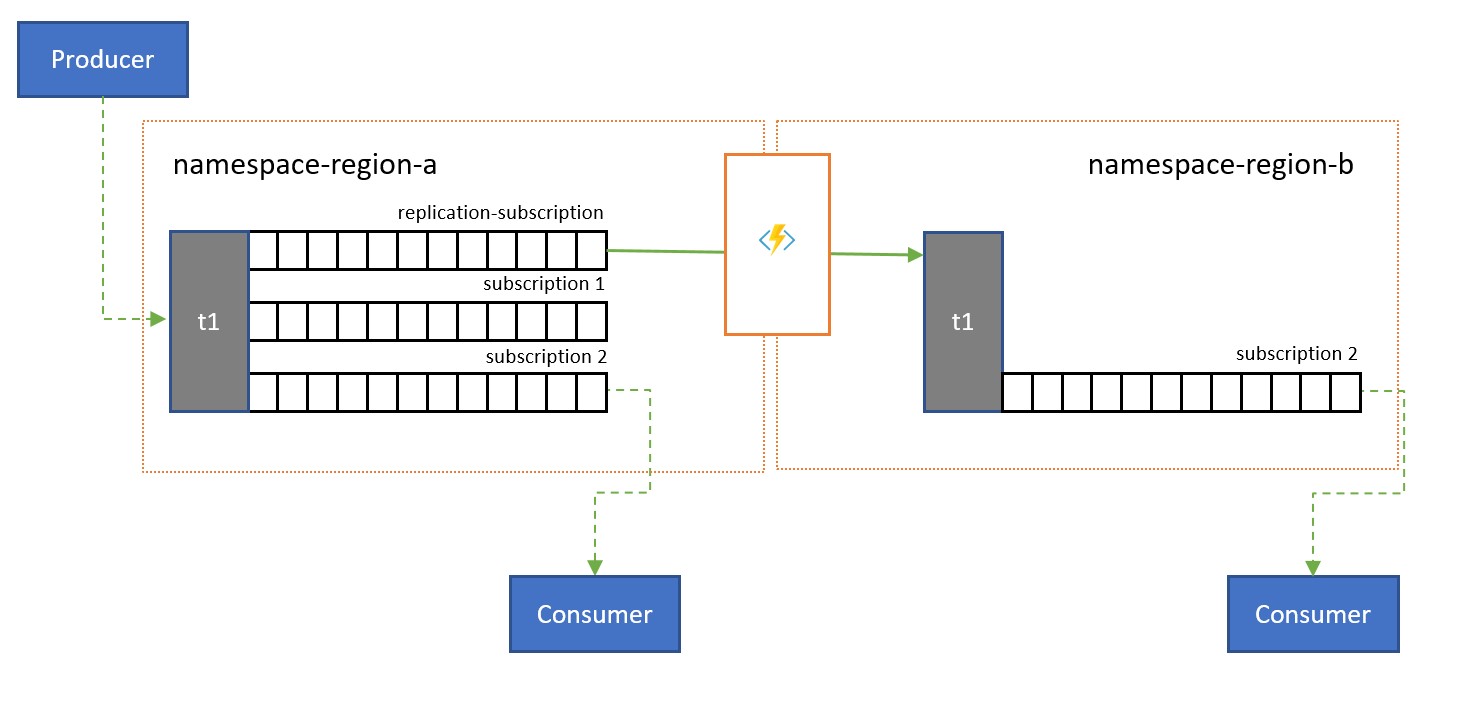
Por ejemplo, al compartir datos entre centros continentales regionales, es más eficaz transferir la información solo una vez entre los centros y que los consumidores obtengan su copia de los datos de esos centros.
Las transferencias de replicación se pueden realizar en lotes, que a menudo los consumidores obtienen y resuelven los mensajes uno a uno. Con una latencia de red base de 100 ms entre, por ejemplo, Norteamérica y Europa, cada mensaje tarda 200 ms más en procesarse durante los dos recorridos de ida y vuelta a una entidad remota para la adquisición y la resolución de los mensajes, en comparación con una entidad de la misma región.
Validación, reducción y enriquecimiento
Es posible que los clientes externos a su propia solución envíen mensajes a una cola o un tema de Service Bus.
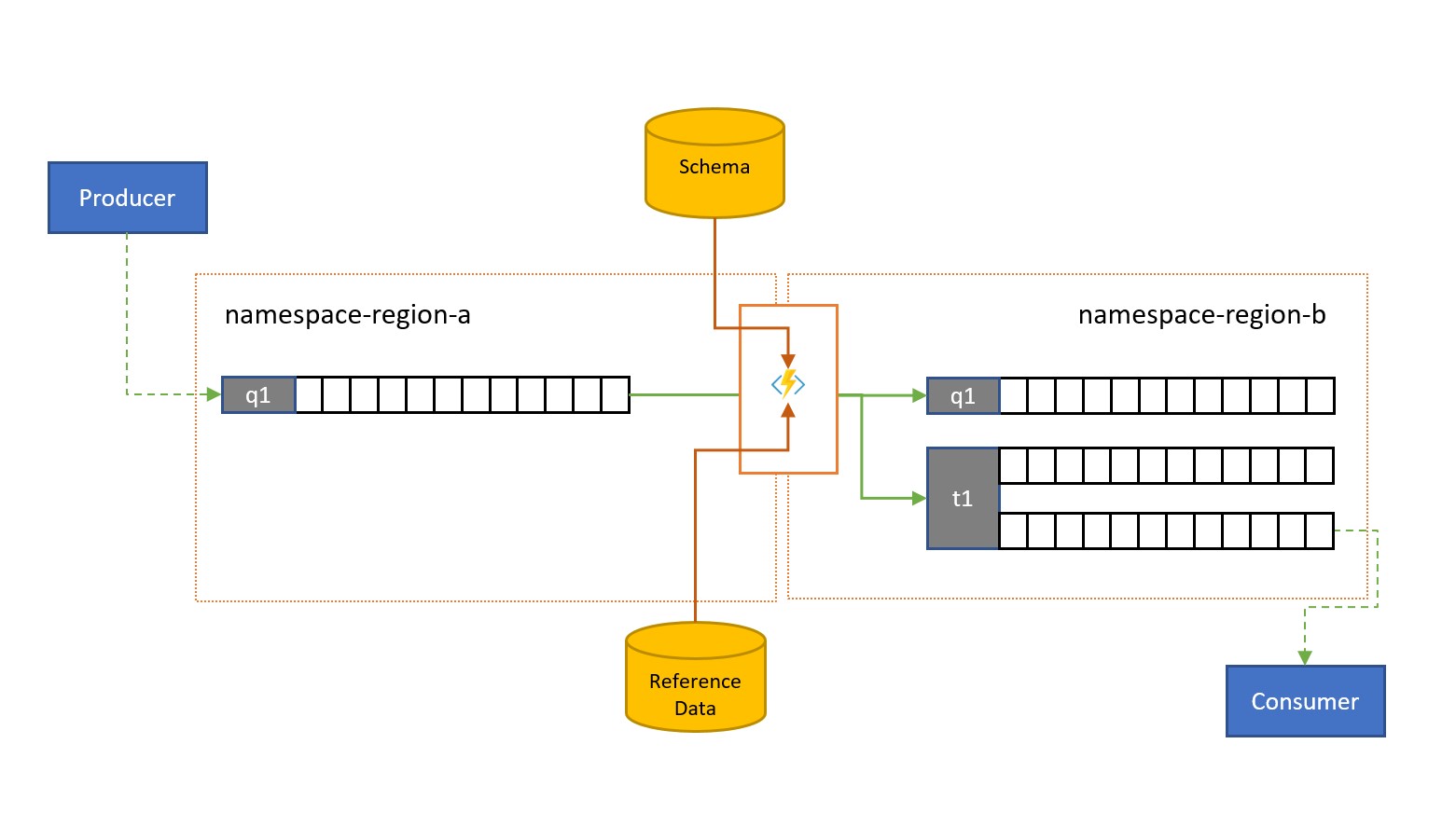
Estos mensajes pueden requerir la comprobación del cumplimiento de un esquema determinado y que los mensajes no conformes se descarten o se coloquen en la cola de mensajes fallidos. Puede que se deba reducir la complejidad de algunos mensajes omitiendo datos o enriquecer otros agregando datos en función de búsquedas de datos de referencia. Las operaciones se pueden realizar con funcionalidad personalizada en la tarea de replicación.
Replicación de transmisión a la cola
Azure Event Hubs es una solución perfecta para administrar volúmenes extremos de eventos entrantes. Sin embargo, ni Event Hubs ni motores similares, como Apache Kafka, proporcionan un modelo de consumidor simultáneo administrado por el servicio en el que varios consumidores puedan administrar a la vez los mensajes desde el mismo origen sin arriesgarse al procesamiento duplicado y, finalmente, resolver esos mensajes una vez que se han procesado.
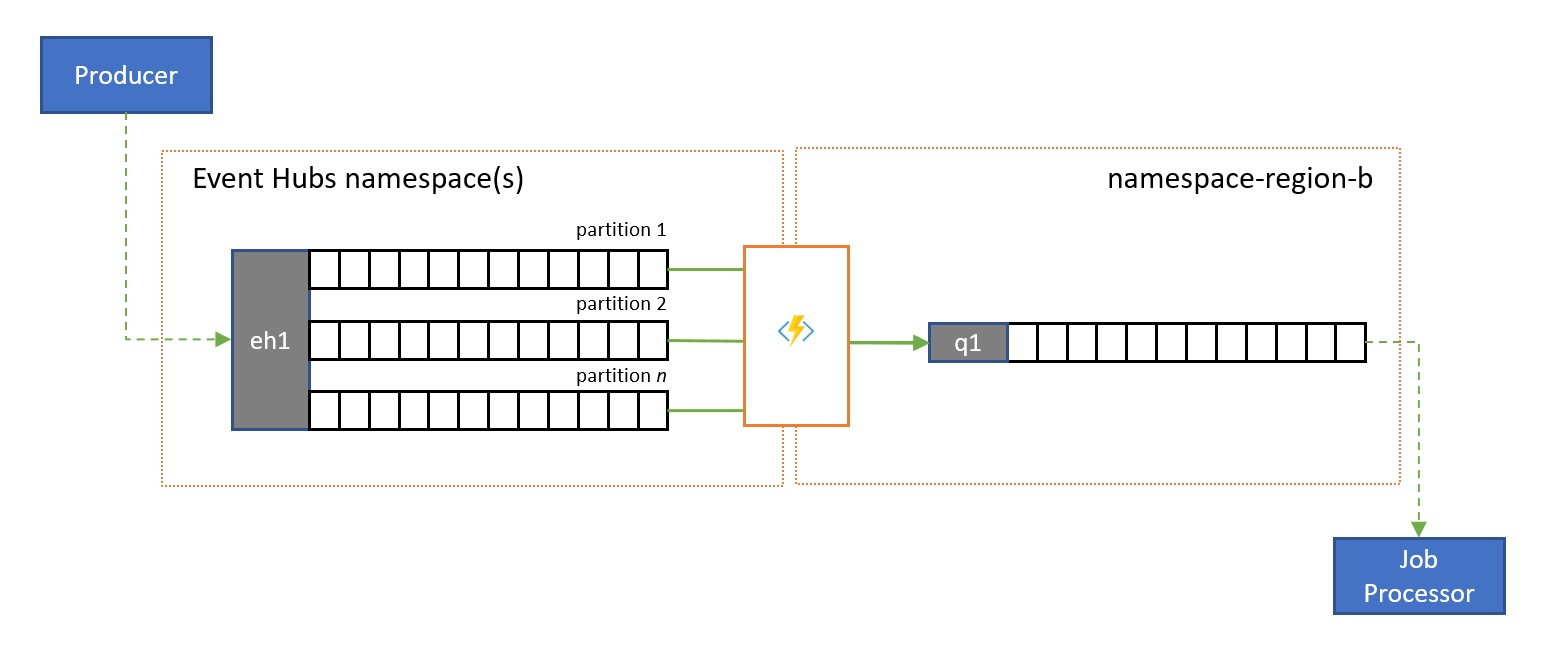
En una replicación de transmisión a la cola, el contenido de una sola partición del centro de eventos o el contenido de un centro de eventos completo se transfiere a una cola de Service Bus, desde donde los mensajes se pueden procesar de forma segura, de manera transaccional y con consumidores simultáneos. Esta replicación también permite el uso de todas las demás funcionalidades de Service Bus con esos mensajes, como el enrutamiento con temas y la demultiplexación basada en sesión.
Consolidación y normalización
Las soluciones globales suelen constar de superficies regionales que son en gran medida independientes, por ejemplo, tienen sus propias funcionalidades de procesamiento; sin embargo, las perspectivas suprarregionales y globales requerirán la integración de datos y, por lo tanto, una consolidación centralizada de los mismos datos del mensaje que se evalúan en las superficies regionales respectivas para la perspectiva local.
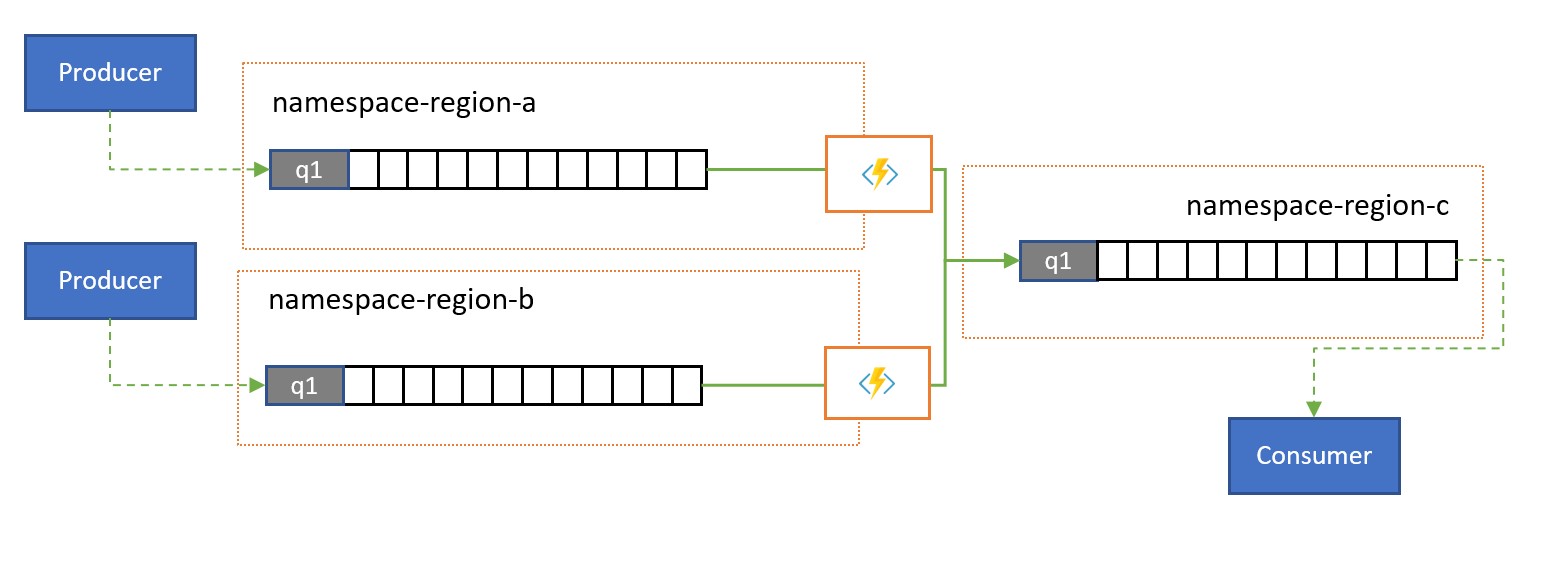
La normalización es un tipo de escenario de consolidación en el que dos o más secuencias entrantes de mensajes transportan el mismo tipo de información, pero con distintas estructuras o codificaciones, y los mensajes deben transcodificarse o transformarse para poderse consumir.
La normalización también puede incluir trabajo criptográfico, como descifrar cargas cifradas de un extremo a otro y volver a cifrarlas con diferentes claves y algoritmos para el público del consumidor de nivel inferior.
División y enrutamiento
Los temas de Service Bus y sus reglas de suscripción se suelen usar para filtrar una secuencia de mensajes para un público determinado y, luego, ese público obtiene el conjunto filtrado de una suscripción.
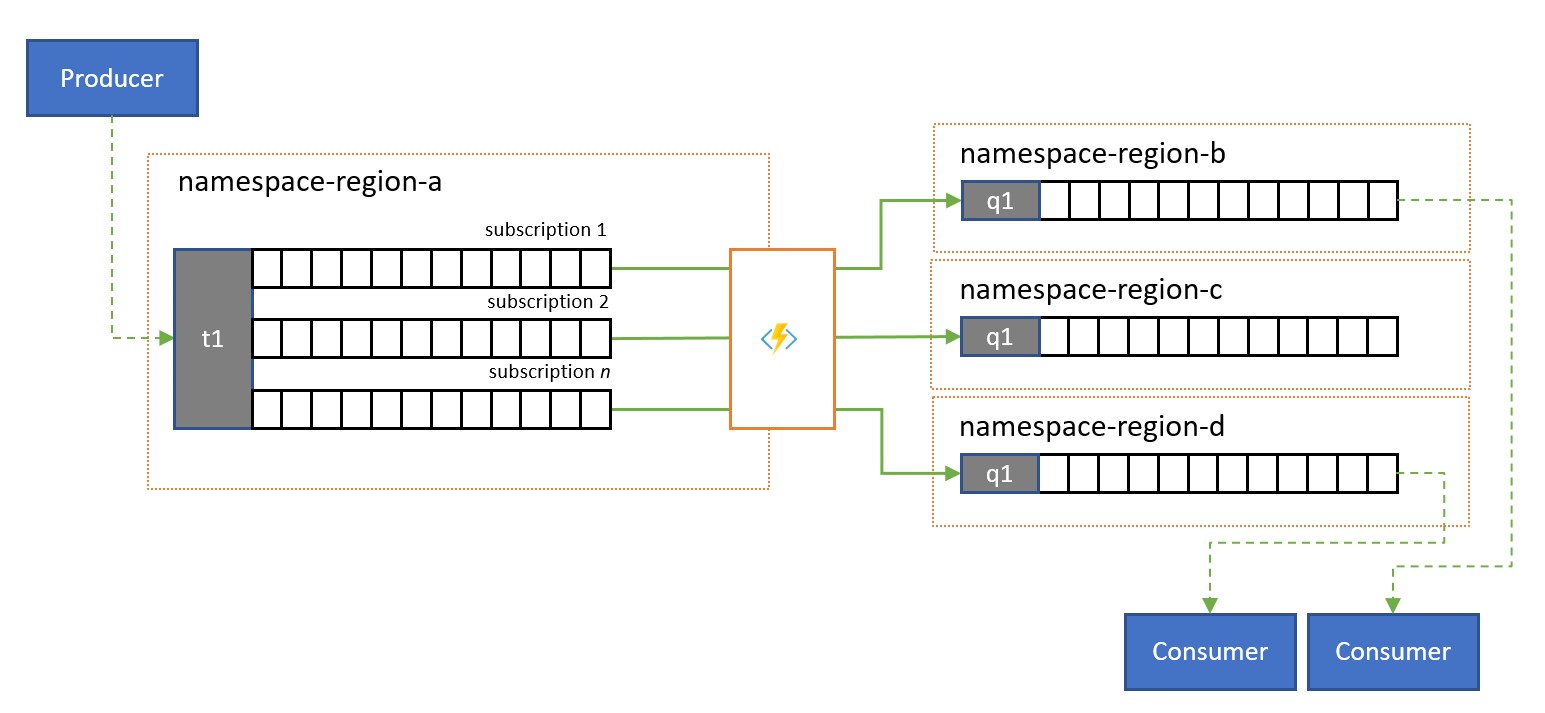
En un sistema global en el que el público de esos mensajes está distribuido globalmente o pertenece a distintas aplicaciones, la replicación se puede utilizar para transferir mensajes de dicha suscripción a una cola o un tema de un espacio de nombres diferente del lugar donde se consumen.
Aplicaciones de replicación en Azure Functions
Para implementar los patrones anteriores se requiere un entorno de ejecución escalable y confiable para las tareas de replicación que quiera configurar y ejecutar. En Azure, el entorno de tiempo de ejecución más adecuado para las tareas sin estado es Azure Functions.
Azure Functions puede ejecutarse en una identidad administrada de Azure, de modo que las tareas de replicación se pueden integrar con las reglas de control de acceso basado en rol de los servicios de origen y destino sin tener que administrar secretos a lo largo de la ruta de replicación. En el caso de los orígenes y destinos de replicación que requieran credenciales explícitas, Azure Functions puede almacenar los valores de configuración de esas credenciales en el almacenamiento con acceso estrictamente controlado dentro de Azure Key Vault.
Además, Azure Functions permite que las tareas de replicación se integren directamente con las redes virtuales y los puntos de conexión de servicio de Azure en todos los servicios de mensajería de Azure, y se integra fácilmente con Azure Monitor.
Más importante aún es que Azure Functions cuenta con desencadenadores y enlaces de salida pregenerados y escalables para Azure Event Hubs, Azure IoT Hub, Azure Service Bus, Azure Event Grid y Azure Queue Storage, extensiones personalizadas para RabbitMQ y Apache Kafka. La mayoría de los desencadenadores se adaptan dinámicamente a las necesidades de rendimiento al escalar y reducir verticalmente el número de instancias que se ejecutan a la vez en función de las métricas documentadas.
Con el plan de consumo de Azure Functions, los desencadenadores pregenerados pueden incluso realizar la reducción vertical a cero mientras no haya mensajes disponibles para la replicación, lo que significa que no se generan costos por mantener la configuración lista para escalarse de nuevo horizontalmente. La principal desventaja de usar el plan de consumo es que la latencia de las tareas de replicación "que se reactivan" desde este estado es bastante mayor que con los planes de hospedaje en los que la infraestructura se mantiene en ejecución.
En contraste con todo esto, los motores de replicación más comunes de mensajería y eventos, como MirrorMaker de Apache Kafka requieren que proporcione un entorno de hospedaje y que escale el motor de replicación por su cuenta. Esto incluye configurar e integrar las características de seguridad y red y facilitar el flujo de supervisión de los datos, e incluso así, no tiene la oportunidad de insertar tareas de replicación personalizadas en el flujo.
Tareas de replicación con Azure Logic Apps
Una alternativa sin código para realizar la replicación mediante Functions sería usar Logic Apps en su lugar. Logic Apps tiene tareas de replicación predefinidas para Service Bus. Estas tareas pueden ayudar a configurar la replicación entre diferentes instancias y se pueden ajustar para personalizarlas aún más.
Pasos siguientes
En este artículo, se ha explorado una serie de patrones de federación y se ha explicado el papel de Azure Functions como entorno de ejecución de replicación de eventos y mensajería en Azure.
A continuación, podría documentarse sobre cómo configurar una aplicación de réplica con Azure Functions y, luego, cómo replicar flujos de eventos entre Event Hubs y otros diversos sistemas de mensajería y eventos: