Tutorial: Creación de un analizador personalizado para números de teléfono
En las soluciones de búsqueda, las cadenas que tienen patrones complejos o caracteres especiales pueden ser un desafío para trabajar porque el analizador predeterminado quita o malinterpreta partes importantes de un patrón, lo que da lugar a una mala experiencia de búsqueda cuando los usuarios no pueden encontrar la información esperada. Los números de teléfono son un ejemplo clásico de cadenas que son difíciles de analizar. Vienen en varios formatos e incluyen caracteres especiales que el analizador predeterminado omite.
Con los números de teléfono como tema, en este tutorial se examinan los problemas de los datos con patrones y se muestra cómo resolver ese problema mediante un analizador personalizado. El enfoque que se describe aquí se puede usar tal como está para los números de teléfono o adaptarse a los campos que tienen las mismas características (patrón, con caracteres especiales), como direcciones URL, correos electrónicos, códigos postales y fechas.
En este tutorial, usará un cliente REST y las API de REST de Búsqueda de Azure AI para:
- Entender el problema
- Desarrollar un analizador personalizado inicial para controlar números de teléfono
- Probar el analizador personalizado
- Iterar el diseño del analizador personalizado para mejorar aún más los resultados
Requisitos previos
Este tutorial requiere los siguientes servicios y herramientas:
Visual Studio Code con un cliente REST.
Búsqueda de Azure AI. Cree un servicio de Búsqueda de Azure AI o busque uno existente en su suscripción actual. Puede usar un servicio gratuito para este inicio rápido.
Descarga de archivos
El código fuente de este tutorial es el archivo custom-analyzer.rest en el repositorio Azure-Samples/azure-search-rest-samples de GitHub.
Copia de una clave y una dirección URL
Las llamadas REST de este tutorial requieren un punto de conexión de servicio de búsqueda y una clave de API de administración. Puede obtener estos valores en Azure Portal.
En Azure Portal, inicie sesión, vaya a la página Información general y copie la dirección URL. Un punto de conexión de ejemplo podría ser similar a
https://mydemo.search.windows.net.En Configuración>Claves, copie una clave de administrador. Las claves de administrador se utilizan para agregar, modificar y eliminar objetos. Hay dos claves de administrador intercambiables. Copie una de las dos.
Una clave de API válida genera la confianza, solicitud a solicitud, entre la aplicación que la envía y el servicio que se encarga de ella.
Creación de un índice inicial
Abra un nuevo archivo de texto en Visual Studio Code.
Establezca variables en el punto de conexión de búsqueda y la clave de API que recopiló en el paso anterior.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-URL-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HEREGuarde el archivo con una extensión de archivo
.rest.Pegue el siguiente ejemplo para crear un índice pequeño denominado
phone-numbers-indexcon dos campos:idyphone_number. Todavía no hemos definido un analizador, por lo que el analizadorstandard.lucenese usa de forma predeterminada.### Create a new index POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false } ] }Seleccione Enviar solicitud. Debe tener una respuesta
HTTP/1.1 201 Createdy el cuerpo de la respuesta debe incluir la representación JSON del esquema de índice.Cargue datos en el índice mediante documentos que contengan varios formatos de número de teléfono. Estos son los datos de prueba.
### Load documents POST {{baseUrl}}/indexes/phone-numbers-index/docs/index?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "value": [ { "@search.action": "upload", "id": "1", "phone_number": "425-555-0100" }, { "@search.action": "upload", "id": "2", "phone_number": "(321) 555-0199" }, { "@search.action": "upload", "id": "3", "phone_number": "+1 425-555-0100" }, { "@search.action": "upload", "id": "4", "phone_number": "+1 (321) 555-0199" }, { "@search.action": "upload", "id": "5", "phone_number": "4255550100" }, { "@search.action": "upload", "id": "6", "phone_number": "13215550199" }, { "@search.action": "upload", "id": "7", "phone_number": "425 555 0100" }, { "@search.action": "upload", "id": "8", "phone_number": "321.555.0199" } ] }Vamos a probar algunas consultas similares a las que podría escribir un usuario. Un usuario podría buscar
(425) 555-0100en cualquier número de formatos y esperar que se devuelvan los resultados. Empiece por buscar en(425) 555-0100:### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2024-07-01&search=(425) 555-0100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}La consulta devuelve tres de los cuatro resultados esperados, pero también devuelve dos resultados inesperados:
{ "value": [ { "@search.score": 0.05634898, "phone_number": "+1 425-555-0100" }, { "@search.score": 0.05634898, "phone_number": "425 555 0100" }, { "@search.score": 0.05634898, "phone_number": "425-555-0100" }, { "@search.score": 0.020766128, "phone_number": "(321) 555-0199" }, { "@search.score": 0.020766128, "phone_number": "+1 (321) 555-0199" } ] }Vamos a intentarlo de nuevo sin ningún formato:
4255550100.### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2024-07-01&search=4255550100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}Esta consulta todavía es peor y solo devuelve una de las cuatro coincidencias correctas.
{ "value": [ { "@search.score": 0.6015292, "phone_number": "4255550100" } ] }
Si encuentra confusos estos resultados, no es el único. En la siguiente sección, vamos a profundizar en la razón por la que se han obtenido estos resultados.
Revisión del funcionamiento de los analizadores
Para comprender estos resultados de búsqueda, es necesario comprender lo que hace el analizador. Entonces podemos probar el analizador predeterminado mediante la API de análisis, lo que proporciona una base para diseñar un analizador que satisfaga mejor nuestras necesidades.
Un analizador es un componente del motor de búsqueda de texto completo responsable del procesamiento de texto en cadenas de consulta y documentos indexados. Diferentes analizadores manipulan el texto de maneras diferentes según el escenario. En este escenario, es necesario crear un analizador adaptado a los números de teléfono.
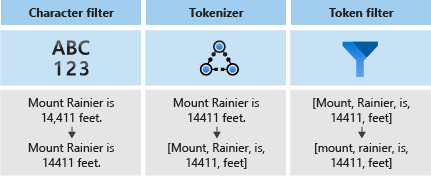
Los analizadores constan de tres componentes:
- Los filtros de caracteres que quitan o reemplazan caracteres individuales del texto de entrada.
- Un tokenizador que divide el texto de entrada en tokens que se convierten en claves en el índice de búsqueda.
- Los filtros de token que manipulan los tokens generados por el tokenizador.
En el siguiente diagrama, puede ver cómo funcionan conjuntamente estos tres componentes para tokenizar una frase:
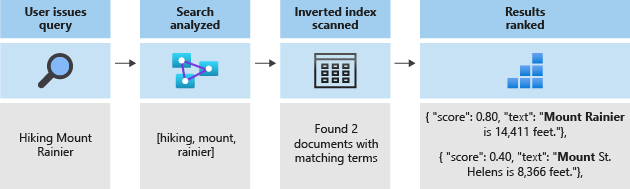
Estos tokens se almacenan en un índice invertido, lo que permite búsquedas rápidas y de texto completo. Un índice invertido permite la búsqueda de texto completo mediante la asignación de todos los términos únicos extraídos durante el análisis léxico a los documentos en los que se producen. Puede ver un ejemplo en el siguiente diagrama:

Toda la búsqueda se reduce a buscar los términos almacenados en el índice invertido. El usuario emite una consulta:
- Se analizan la consulta y sus términos.
- A continuación, se examina el índice invertido para buscar documentos con términos coincidentes.
- Por último, los documentos recuperados se clasifican con el algoritmo de puntuación.
Si los términos de la consulta no coinciden con los términos del índice invertido, no se devuelven resultados. Para más información sobre el funcionamiento de las consultas, consulte el artículo sobre la búsqueda de texto completo.
Nota
Las consultas de términos parciales son una excepción importante para esta regla. A diferencia de las consultas de términos normales, estas consultas (prefijo de consulta, consulta de caracteres comodín, consulta regex) omiten el proceso de análisis léxico. Los términos parciales solo están en minúsculas antes de que coincidan con los términos del índice. Si un analizador no está configurado para que admita estos tipos de consultas, a menudo recibirá resultados inesperados porque no existen términos coincidentes en el índice.
Análisis de analizadores mediante la API de análisis
Búsqueda de Azure AI ofrece la API de análisis que permite probar los analizadores para comprender cómo procesan el texto.
Use la siguiente solicitud para llamar a la API de análisis:
POST {{baseUrl}}/indexes/phone-numbers-index/analyze?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "(425) 555-0100",
"analyzer": "standard.lucene"
}
La API devuelve los tokens extraídos del texto mediante el analizador especificado. El analizador de Lucene estándar divide el número de teléfono en tres tokens independientes:
{
"tokens": [
{
"token": "425",
"startOffset": 1,
"endOffset": 4,
"position": 0
},
{
"token": "555",
"startOffset": 6,
"endOffset": 9,
"position": 1
},
{
"token": "0100",
"startOffset": 10,
"endOffset": 14,
"position": 2
}
]
}
Por el contrario, el número de teléfono 4255550100 con formato sin puntuación se tokeniza en un token único.
{
"text": "4255550100",
"analyzer": "standard.lucene"
}
Respuesta:
{
"tokens": [
{
"token": "4255550100",
"startOffset": 0,
"endOffset": 10,
"position": 0
}
]
}
Tenga en cuenta que tanto los términos de consulta como los documentos indizado se someten a análisis. Al pensar en los resultados de la búsqueda del paso anterior, podemos empezar a ver por qué se devolvieron los resultados.
En la primera consulta, se devolvieron números de teléfono inesperados porque uno de sus tokens, 555, coincidía con uno de los términos que buscamos. En la segunda consulta, solo se devolvió el número uno porque era el único registro que tenía un token coincidente, 4255550100.
Creación de un analizador personalizado
Ahora que entendemos los resultados que estamos viendo, vamos a crear un analizador personalizado para mejorar la lógica de tokenización.
El objetivo es proporcionar una búsqueda intuitiva en los números de teléfono, independientemente del formato en el que se encuentre la consulta o la cadena indexada. Para lograr esta salida, especificaremos un filtro de caracteres, un tokenizador y un filtro de token.
Filtros de caracteres
Los filtros de caracteres se utilizan para procesar el texto antes de introducirse en el tokenizador. Entre los usos comunes de los filtros de caracteres se incluyen el filtrado de elementos HTML o la sustitución de caracteres especiales.
En el caso de los números de teléfono, queremos quitar los caracteres especiales y los espacios en blanco, ya que no todos los formatos de número de teléfono contienen los mismos.
"charFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.MappingCharFilter",
"name": "phone_char_mapping",
"mappings": [
"-=>",
"(=>",
")=>",
"+=>",
".=>",
"\\u0020=>"
]
}
]
El filtro quita -()+. y espacios de la entrada.
| Entrada | Output |
|---|---|
(321) 555-0199 |
3215550199 |
321.555.0199 |
3215550199 |
Tokenizer
Los tokenizadores dividen el texto en tokens y descartan algunos caracteres, como los signos de puntuación, a lo largo del proceso. En muchos casos, el objetivo de la tokenización es dividir una frase en palabras individuales.
En este escenario, usaremos un tokenizador de palabras clave, keyword_v2, porque queremos capturar el número de teléfono como un solo término. Tenga en cuenta que esta no es la única manera de resolver este problema. Consulte la sección Enfoques alternativos a continuación.
Los tokenizadores de palabras clave siempre generan el mismo texto que se proporcionó como un único término.
| Entrada | Output |
|---|---|
The dog swims. |
[The dog swims.] |
3215550199 |
[3215550199] |
Filtros de token
Los filtros de token filtrarán o modificarán los tokens que el tokenizador genere. Un uso habitual de un filtro de token es poner en minúsculas todos los caracteres mediante un filtro de token en minúsculas. Otro uso habitual es el filtrado de palabras irrelevantes como the, and o is.
Aunque no es necesario usar ninguno de estos filtros para este escenario, usaremos un filtro de token de n-grama para permitir las búsquedas parciales de números de teléfono.
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2",
"name": "custom_ngram_filter",
"minGram": 3,
"maxGram": 20
}
]
NGramTokenFilterV2
El filtro de token nGram_v2 divide los tokens en n-gramas de un tamaño determinado basándose en los parámetros minGram y maxGram.
En el analizador de teléfonos, se establece minGram en 3 porque es la subcadena más corta que se espera que los usuarios busquen.
maxGram se establece en 20 para asegurarse de que todos los números de teléfono, incluso aquellos con extensiones, quepan en un único n-grama.
El efecto secundario no deseado de los n-gramas es que se devolverán algunos falsos positivos. Lo corregiremos en un paso posterior mediante la creación de un analizador independiente para búsquedas que no incluyan el filtro de token de n-grama.
| Entrada | Output |
|---|---|
[12345] |
[123, 1234, 12345, 234, 2345, 345] |
[3215550199] |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Analizador
Con nuestros filtros de caracteres, tokenizador y filtros de token preparados, estamos listos para definir el analizador.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer",
"tokenizer": "keyword_v2",
"tokenFilters": [
"custom_ngram_filter"
],
"charFilters": [
"phone_char_mapping"
]
}
]
En la API de análisis, dadas las siguientes entradas, las salidas del analizador personalizado se muestran en la siguiente tabla.
| Entrada | Salida |
|---|---|
12345 |
[123, 1234, 12345, 234, 2345, 345] |
(321) 555-0199 |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Todos los tokens de la columna de salida existen en el índice. Si nuestra consulta incluye cualquiera de esos términos, se devuelve el número de teléfono.
Recompilación mediante el nuevo analizador
Elimine el índice actual:
### Delete the index DELETE {{baseUrl}}/indexes/phone-numbers-index?api-version=2024-07-01 HTTP/1.1 api-key: {{apiKey}}Vuelva a crear el índice mediante el nuevo analizador. Este esquema de índice agrega una definición de analizador personalizada y una asignación de analizador personalizada en el campo número de teléfono.
### Create a new index POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index-2", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false, "analyzer": "phone_analyzer" } ], "analyzers": [ { "@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer", "name": "phone_analyzer", "tokenizer": "keyword_v2", "tokenFilters": [ "custom_ngram_filter" ], "charFilters": [ "phone_char_mapping" ] } ], "charFilters": [ { "@odata.type": "#Microsoft.Azure.Search.MappingCharFilter", "name": "phone_char_mapping", "mappings": [ "-=>", "(=>", ")=>", "+=>", ".=>", "\\u0020=>" ] } ], "tokenFilters": [ { "@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2", "name": "custom_ngram_filter", "minGram": 3, "maxGram": 20 } ] }
Probar el analizador personalizado
Después de volver a crear el índice, ahora puede probar el analizador mediante la siguiente solicitud:
POST {{baseUrl}}/indexes/tutorial-first-analyzer/analyze?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "+1 (321) 555-0199",
"analyzer": "phone_analyzer"
}
Ahora debería ver la colección de tokens resultantes del número de teléfono:
{
"tokens": [
{
"token": "132",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "1321",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "13215",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
...
...
...
]
}
Revisión del analizador personalizado para controlar falsos positivos
Después de realizar algunas consultas de ejemplo en el índice con el analizador personalizado, observará que la recuperación ha mejorado y que ahora se devuelven todos los números de teléfono coincidentes. Sin embargo, el filtro de token de n-grama provoca que se devuelvan también algunos falsos positivos. Se trata de un efecto secundario frecuente de un filtro de token de n-grama.
Para evitar los falsos positivos, vamos a crear un analizador independiente que realice las consultas. Este analizador es idéntico al anterior, salvo que omite el custom_ngram_filter.
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_search",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [],
"charFilters": [
"phone_char_mapping"
]
}
En la definición del índice, especificamos indexAnalyzer y searchAnalyzer.
{
"name": "phone_number",
"type": "Edm.String",
"sortable": false,
"searchable": true,
"filterable": false,
"facetable": false,
"indexAnalyzer": "phone_analyzer",
"searchAnalyzer": "phone_analyzer_search"
}
Con este cambio, está todo listo. Estos son los pasos siguientes:
Eliminar el índice.
Vuelva a crear el índice después de agregar el nuevo analizador personalizado (
phone_analyzer-search) y asigne ese analizador a la propiedadsearchAnalyzerdel campophone-number.Vuelva a cargar los datos.
Vuelva a probar las consultas para comprobar que la búsqueda funciona según lo previsto. Si usa el archivo de ejemplo, este paso crea el tercer índice denominado
phone-number-index-3.
Enfoques alternativos
El analizador descrito en la sección anterior está diseñado para maximizar la flexibilidad de la búsqueda. Sin embargo, esto es a expensas del costo que supone el almacenamiento en el índice de muchos términos que pueden no ser importantes.
En el siguiente ejemplo se muestra un analizador alternativo que es más eficaz en la tokenización, pero tiene inconvenientes.
Dada una entrada de 14255550100, el analizador no puede fragmentar lógicamente el número de teléfono. Por ejemplo, no puede separar el código de país, 1, del código de área, 425. Esta discrepancia provocaría que el número de teléfono no se devolviera si un usuario no incluyese un código de país en la búsqueda.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_shingles",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [
"custom_shingle_filter"
]
}
],
"tokenizers": [
{
"@odata.type": "#Microsoft.Azure.Search.StandardTokenizerV2",
"name": "custom_tokenizer_phone",
"maxTokenLength": 4
}
],
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.ShingleTokenFilter",
"name": "custom_shingle_filter",
"minShingleSize": 2,
"maxShingleSize": 6,
"tokenSeparator": ""
}
]
En el siguiente ejemplo, puede ver que el número de teléfono se divide en los fragmentos que los usuarios suelen buscar.
| Entrada | Salida |
|---|---|
(321) 555-0199 |
[321, 555, 0199, 321555, 5550199, 3215550199] |
En función de sus requisitos, este puede ser un enfoque más eficaz del problema.
Puntos clave
En este tutorial se ha demostrado el proceso de creación y prueba de un analizador personalizado. Ha creado un índice, ha indexado los datos y, a continuación, ha consultado en el índice para ver los resultados de búsqueda que se han devuelto. Con esto, ha usado la API de análisis para ver el proceso de análisis léxico en acción.
Aunque el analizador definido en este tutorial ofrece una solución sencilla para buscar números de teléfono, este mismo proceso se puede usar para crear un analizador personalizado para cualquier escenario que comparta características similares.
Limpieza de recursos
Cuando trabaje con su propia suscripción, al final de un proyecto, es recomendable eliminar los recursos que ya no necesite. Los recursos que se dejan en ejecución pueden costarle mucho dinero. Puede eliminar los recursos de forma individual o bien eliminar el grupo de recursos para eliminar todo el conjunto de recursos.
Puede encontrar y administrar recursos en Azure Portal mediante el vínculo Todos los recursos o Grupos de recursos en el panel de navegación izquierdo.
Pasos siguientes
Ahora que sabe cómo crear un analizador personalizado, echemos un vistazo a todos los filtros, tokenizadores y analizadores disponibles para crear una rica experiencia de búsqueda.