Creación de una consulta de texto completa en Búsqueda de Azure AI
Si va a crear una consulta para la búsqueda de texto completo, en este artículo se proporcionan pasos para configurar la solicitud. También presenta una estructura de consulta y explica cómo los atributos de campo y los analizadores lingüísticos pueden afectar a los resultados de la consulta.
Requisitos previos
Índice de búsqueda con campos de cadena con atributos como búsqueda.
Permisos de lectura en el índice de búsqueda. Para el acceso de lectura, incluya una clave de API de consulta en la solicitud o asigne al autor de la llamada permisos de lector de datos del índice de búsqueda.
Ejemplo de una solicitud de consulta de texto completo
En Azure AI Search, una consulta es una solicitud de solo lectura en la colección de documentación de un único índice de búsqueda, con parámetros que informan a la ejecución de consultas y dan forma a la respuesta que vuelve.
Una consulta de texto completo se especifica en un parámetro search y consta de términos, frases entre comillas y operadores. Otros parámetros agregan más definición a la solicitud.
La siguiente llamada a la API de REST Search POST muestra una solicitud de consulta mediante los parámetros mencionados anteriormente.
POST https://[service name].search.windows.net/indexes/hotels-sample-index/docs/search?api-version=2024-07-01
{
"search": "NY +view",
"queryType": "simple",
"searchMode": "all",
"searchFields": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"select": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"top": 10,
"count": true
}
Puntos clave
searchproporciona los criterios de coincidencia, normalmente términos completos o frases, con o sin operadores. Cualquier campo que tenga el atributo que permite búsquedas en el esquema de índice es un candidato para este parámetro.queryTypeestablece el analizador: simple y completo. El analizador de consultas simple predeterminado es óptimo para la búsqueda de texto completo. El analizador de consultas completo de Lucene es para construcciones de consulta avanzadas, como expresiones regulares, búsqueda de proximidad, búsqueda aproximada y comodín. Este parámetro también se puede establecer en semántico para la clasificación semántica para el modelado semántico avanzado en la respuesta de la consulta.searchModeespecifica si las coincidencias se basan en todos los criterios (favorece la precisión) o cualquiera (favorece la recuperación) en la expresión. La opción predeterminada es cualquiera. Si prevé un uso intensivo de los operadores booleanos, lo cual es más probable en los índices que contienen bloques de texto de gran tamaño (un campo de contenido o descripciones largas), asegúrese de probar las consultas con el parámetrosearchMode=Any|Allpara evaluar el impacto de esa configuración en la búsqueda booleana.searchFieldsrestringe la ejecución de consultas a campos utilizables en búsquedas. Durante el desarrollo, resulta útil usar la misma lista de campos para la selección y la búsqueda. En caso contrario, una coincidencia podría basarse en valores de campo que no se pueden ver en los resultados, lo que crea incertidumbre sobre el motivo por el que se devolvió el documento.
Parámetros que se usan para dar forma a la respuesta:
selectespecifica los campos que se van a devolver en la respuesta. Solo los campos marcados como recuperable en el índice se pueden usar en una instrucción select.topdevuelve el número especificado de documentos con la mejor coincidencia. En este ejemplo, solo se devuelven 10 resultados. Puede usar top y skip (no se muestra) para paginar los resultados.countindica cuántos documentos en el índice completo coinciden globalmente, lo que puede ser mayor de lo que se devuelve.orderbyse utiliza si desea ordenar los resultados por un valor, como una clasificación o una ubicación. De lo contrario, el valor predeterminado es usar la puntuación de relevancia para clasificar los resultados. Se le debe asignar el atributo ordenable a un campo para que pueda ser candidato para este parámetro.
Elija un cliente
Para las primeras pruebas de desarrollo y prueba de concepto, comience con Azure Portal o con un cliente REST. Ambos enfoques son interactivos, útiles para las pruebas dirigidas y le ayudan a evaluar los efectos de diferentes propiedades sin tener que escribir ningún código.
Para llamar a la búsqueda desde una aplicación, use las bibliotecas cliente de Azure.Document.Searchen los SDK de Azure para .NET, Java, JavaScript y Python.
Cuando abre un índice en Azure Portal, puede trabajar con el explorador de búsqueda junto con la definición JSON del índice en las pestañas en paralelo, para facilitar el acceso a los atributos de campo. Compruebe la tabla Campos para ver cuáles son aptos para la búsqueda, ordenables, filtrables y factibles mientras se prueban las consultas.
Inicie sesión en Azure Portal y encuentre su servicio de búsqueda.
En el servicio, seleccione Índices y elija un índice.
Se abre un índice en la pestaña Explorador de búsqueda para que pueda consultar inmediatamente. Cambie a vista JSON para especificar la sintaxis de consulta.
Esta es una expresión de consulta de búsqueda de texto completo que funciona para el índice de ejemplo Hoteles:
{ "search": "pool spa +airport", "queryType": "simple", "searchMode": "any", "searchFields": "Description, Tags", "select": "HotelName, Description, Tags", "top": 10, "count": true }En la siguiente captura de pantalla se muestra la consulta y la respuesta:
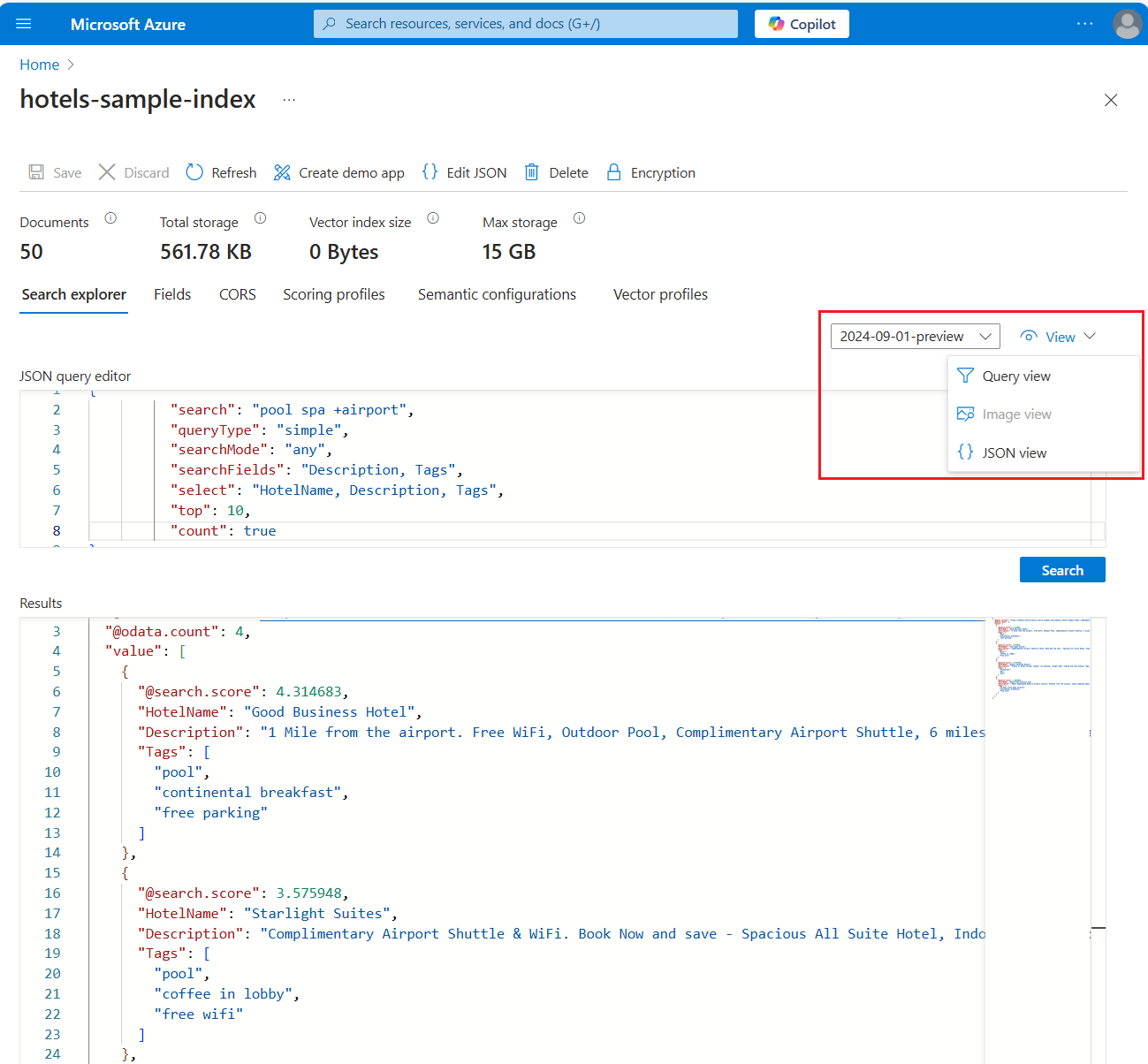
Elegir un tipo de consulta: simple | total
Si la consulta es una búsqueda de texto completo, se usa un analizador de consultas para procesar cualquier texto que se pase como términos y frases de búsqueda. Azure AI Search ofrece dos analizadores de consultas.
El analizador simple entiende la sintaxis de consulta simple. Este analizador se seleccionó como valor predeterminado, debido a su velocidad y eficacia en las consultas de texto de forma libre. La sintaxis admite operadores de búsqueda comunes (AND, OR, NOT) en las búsquedas de términos y frases, y en la búsqueda de prefijos (
*) (como ensea*para Seattle y Seaside). Como recomendación general, pruebe primero el analizador simple y, a continuación, pase al analizador completo si los requisitos de la aplicación llaman a consultas más complejas.La sintaxis de consulta completa de Lucene que se habilita al agregar
queryType=fulla la solicitud, se basa en el analizador Apache Lucene.
La sintaxis completa y la simple se superponen hasta el punto en que ambas admiten el mismo prefijo y las mismas operaciones booleanas, pero la sintaxis completa proporciona más operadores. En su totalidad, hay más operadores para las expresiones booleanas y más operadores para consultas avanzadas como la búsqueda aproximada, la búsqueda con caracteres comodín, la búsqueda de proximidad y las expresiones regulares.
Elección de los métodos de consulta
La búsqueda es fundamentalmente un ejercicio controlado por el usuario, donde los términos o frases se recopilan de un cuadro de búsqueda o de los eventos de clic de una página. En la tabla siguiente se resumen los mecanismos mediante los cuales puede recopilar las entradas de usuario y la experiencia de búsqueda esperada.
| Entrada | Experiencia |
|---|---|
| Método de búsqueda | El usuario escribe los términos o frases en un cuadro de búsqueda, con o sin operadores, y selecciona Buscar para enviar la solicitud. La búsqueda se puede usar con filtros en la misma solicitud, pero no con la opción de autocompletar o con sugerencias. |
| Método de autocompletar | El usuario escribe unos pocos caracteres y las consultas se inician después de escribir cada carácter nuevo. La respuesta es una cadena completada del índice. Si la cadena proporcionada es válida, el usuario selecciona Buscar para enviar la consulta al servicio. |
| Método de sugerencias | Igual que sucede con la opción de autocompletar, el usuario escribe unos pocos caracteres y se generan consultas incrementales. La respuesta es una lista desplegable de documentos coincidentes, que se representa normalmente con algunos campos únicos o descriptivos. Si alguna de las selecciones es válida, el usuario selecciona una y se devuelve el documento coincidente. |
| Navegación por facetas | Una página muestra vínculos de navegación en los que se puede hacer clic o rutas de navegación que restringen el ámbito de la búsqueda. Una estructura de navegación por facetas se compone de forma dinámica en función de una consulta inicial. Por ejemplo, el valor search=* se usa para rellenar un árbol de navegación por facetas que se compone de cada categoría posible. Una estructura de navegación por facetas se crea a partir de una respuesta de consulta, pero también es un mecanismo para expresar la consulta siguiente. En una referencia de la API de REST, el valor facets se documenta como un parámetro de consulta de una operación de búsqueda de documentos, pero se puede usar sin el parámetro search. |
| Método de filtro | Los filtros se usan con las facetas para restringir los resultados. Asimismo, también puede implementar un filtro en el segundo plano de la página, para inicializar, por ejemplo, la página con campos específicos del idioma. En una referencia de la API de REST, el valor $filter se documenta como un parámetro de consulta de una operación de búsqueda de documentos, pero se puede usar sin el parámetro search. |
Efecto de los atributos de campo en las consultas
Si ya conoce los tipos de consultas y su composición, puede que recuerde que los parámetros de la solicitud de consulta dependen de cómo se atribuyen los campos en un índice. Por ejemplo, solo se pueden usar campos marcados como es posible buscarlos y recuperables en las consultas y los resultados de búsqueda. Al establecer los parámetros search, filter y orderby en la solicitud, debe comprobar los atributos para evitar resultados inesperados.
En la siguiente captura de pantalla del índice de ejemplo Hoteles, solo los dos últimos campos LastRenovationDate y Rating son ordenables, un requisito para su uso en una cláusula solo "$orderby".
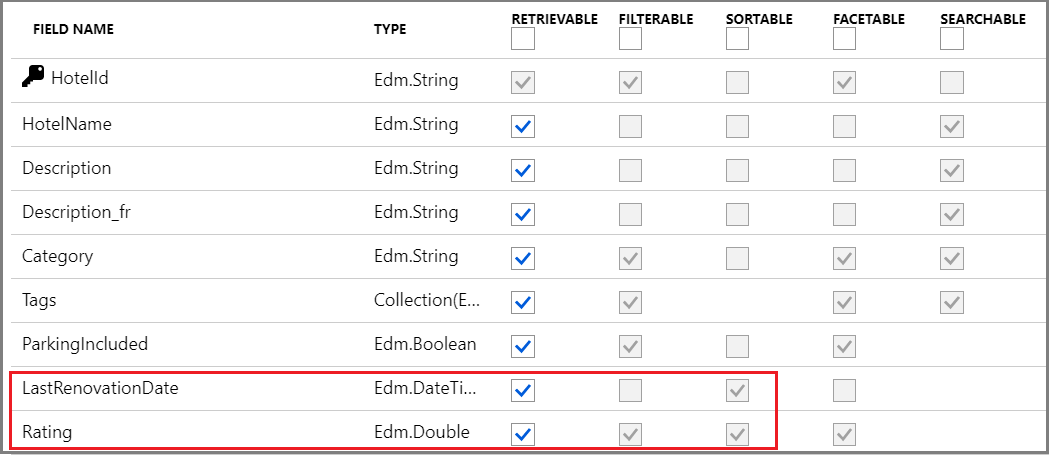
Para ver las definiciones de atributos de campo, consulte Creación de un índice (API de REST).
Efecto de los tokens en las consultas
Durante la indexación, el motor de búsqueda usa un analizador de texto en cadenas para maximizar la posibilidad de encontrar una coincidencia en el momento de la consulta. Como mínimo, las cadenas están en minúsculas, pero, dependiendo del analizador, también pueden someterse a una lematización y detener la eliminación de palabras. Las cadenas o palabras compuestas más amplias suelen dividirse con espacios en blanco, guiones o rayas, y se indexan como tokens independientes.
Lo importante aquí es que lo que cree que contiene su índice, y lo que realmente contiene, puede ser diferente. Si las consultas no devuelven los resultados esperados, puede inspeccionar los tokens que haya creado el analizador a través de la opción Analizar texto (API de REST). Para obtener más información acerca de la tokenización y el impacto en las consultas, consulte Búsqueda de términos y patrones parciales con caracteres especiales.
Contenido relacionado
Ahora que conoce mejor cómo funcionan las solicitudes de consulta, pruebe las siguientes guías de inicio rápido para obtener experiencia práctica.