Esta guía de inicio rápido crea y consulta un pequeño índice de inicio rápido de hoteles que contiene datos sobre 4 hoteles.
Elija un lenguaje de programación para el paso siguiente. Las bibliotecas cliente Azure.Search.Documents están disponibles en los SDK de Azure para .NET, Python, Java y JavaScript o Typescript.
Cree una aplicación de consola mediante la biblioteca cliente Azure.Search.Documents para crear, cargar y consultar un índice de búsqueda.
Como alternativa, puede descargar el código fuente para empezar con un proyecto terminado o seguir los pasos de este artículo para crear su propio proyecto.
Configurar el entorno
Inicie Visual Studio y cree un nuevo proyecto para una aplicación de consola.
En Herramientas>Administrador de paquetes NuGet seleccione Administrar paquetes NuGet para la solución.... .
Seleccione Examinar.
Busque el paquete de Azure.Search.Documents y seleccione la versión 11.0 o una posterior.
Seleccione Instalar para agregar el ensamblado al proyecto y la solución.
Creación de un cliente de búsqueda
En Program.cs, cambie el espacio de nombres a AzureSearch.SDK.Quickstart.v11 y, a continuación, agregue las siguientes directivas using.
using Azure;
using Azure.Search.Documents;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Azure.Search.Documents.Models;
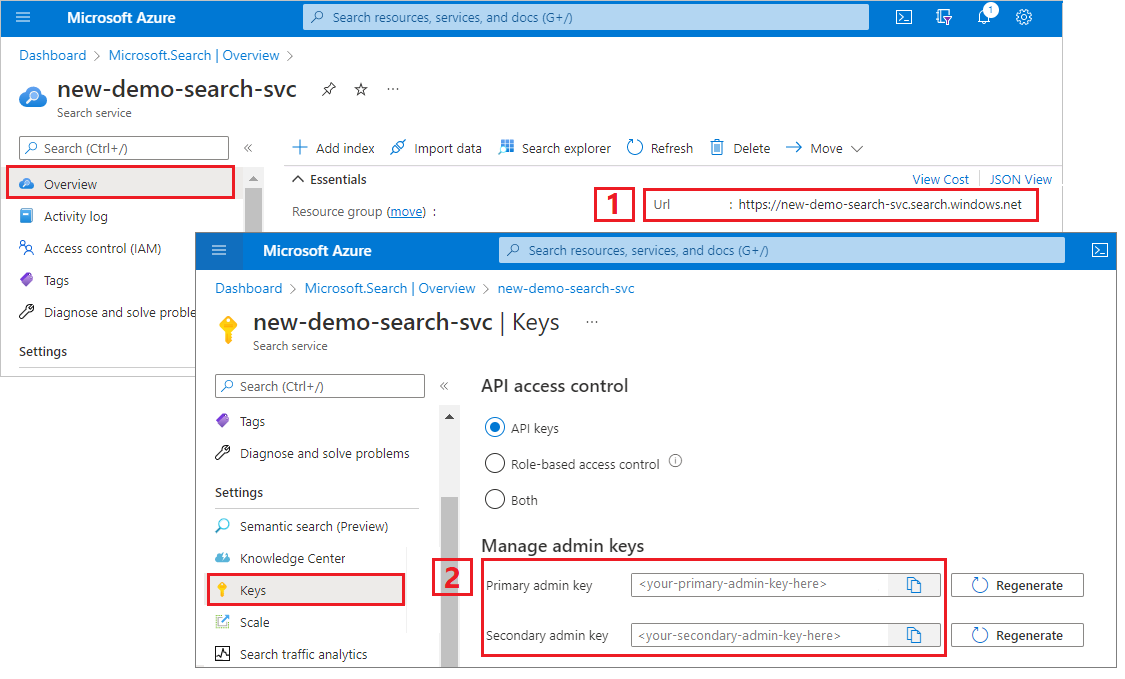
Copie el siguiente código para crear dos clientes. SearchIndexClient crea el índice y SearchClient carga y consulta uno existente. Ambos necesitan el punto de conexión de servicio y una clave de API de administración para la autenticación con derechos de creación y eliminación.
Dado que el código compila el URI automáticamente, especifique solo el nombre del servicio de búsqueda en la propiedad serviceName.
static void Main(string[] args)
{
string serviceName = "<your-search-service-name>";
string apiKey = "<your-search-service-admin-api-key>";
string indexName = "hotels-quickstart";
// Create a SearchIndexClient to send create/delete index commands
Uri serviceEndpoint = new Uri($"https://{serviceName}.search.windows.net/");
AzureKeyCredential credential = new AzureKeyCredential(apiKey);
SearchIndexClient adminClient = new SearchIndexClient(serviceEndpoint, credential);
// Create a SearchClient to load and query documents
SearchClient srchclient = new SearchClient(serviceEndpoint, indexName, credential);
. . .
}
Creación de un índice
En este inicio rápido se crea un índice de hoteles que se cargará con datos de hotel y en el que se ejecutarán consultas. En este paso, defina los campos en el índice. Cada definición de campo incluye un nombre, un tipo de datos y atributos que determinan cómo se usa el campo.
En este ejemplo, se usan métodos sincrónicos de la biblioteca Azure.Search.Documents para simplificar y mejorar la legibilidad. Sin embargo, para los escenarios de producción, debe usar métodos asincrónicos para mantener la aplicación escalable y receptiva. Por ejemplo, usaría CreateIndexAsync en lugar de CreateIndex.
Agregue una definición de clase vacía al proyecto: Hotel.cs
Copie el código siguiente en Hotel.cs para definir la estructura de un documento de hotel. Los atributos del campo determinan cómo se utilizan en una aplicación. Por ejemplo, el atributo IsFilterable se tiene que asignar a cada campo que admita una expresión de filtro.
using System;
using System.Text.Json.Serialization;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
namespace AzureSearch.Quickstart
{
public partial class Hotel
{
[SimpleField(IsKey = true, IsFilterable = true)]
public string HotelId { get; set; }
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
[SearchableField(AnalyzerName = LexicalAnalyzerName.Values.EnLucene)]
public string Description { get; set; }
[SearchableField(AnalyzerName = LexicalAnalyzerName.Values.FrLucene)]
[JsonPropertyName("Description_fr")]
public string DescriptionFr { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string Category { get; set; }
[SearchableField(IsFilterable = true, IsFacetable = true)]
public string[] Tags { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public bool? ParkingIncluded { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public DateTimeOffset? LastRenovationDate { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public double? Rating { get; set; }
[SearchableField]
public Address Address { get; set; }
}
}
En la biblioteca clienteAzure.Search.Documents puede usar SearchableField y SimpleField para optimizar las definiciones de campo. Ambos son derivados de un SearchField y pueden simplificar el código:
SimpleField puede ser cualquier tipo de datos, no permite búsquedas (se omite en las consultas de búsqueda de texto completo) y se puede recuperar (no está oculto). Otros atributos están desactivados de forma predeterminada, pero se pueden habilitar. Puede usar un SimpleField para los identificadores de documento o los campos que se usan solo en filtros, facetas o perfiles de puntuación. En caso de hacerlo, asegúrese de aplicar los atributos necesarios para el escenario, como IsKey = true para un identificador de documento. Para más información, consulte SimpleFieldAttribute.cs en el código fuente.
SearchableField debe ser una cadena y siempre permite búsquedas y se puede recuperar. Otros atributos están desactivados de forma predeterminada, pero se pueden habilitar. Ya que este tipo de campo se puede buscar, admite sinónimos y el complemento completo de las propiedades del analizador. Para más información, consulte SearchableFieldAttribute.cs en el código fuente.
Tanto si usa la API básica de SearchField, como uno de los modelos auxiliares, debe habilitar explícitamente los atributos de filtro, faceta y ordenación. Por ejemplo, IsFilterable, IsSortabley IsFacetable se tienen que atribuir explícitamente, como se muestra en el ejemplo anterior.
Agregue una segunda definición de clase vacía al proyecto: Address.cs. Pegue el código siguiente en la clase.
using Azure.Search.Documents.Indexes;
namespace AzureSearch.Quickstart
{
public partial class Address
{
[SearchableField(IsFilterable = true)]
public string StreetAddress { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string City { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string StateProvince { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string PostalCode { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string Country { get; set; }
}
}
Cree dos clases más: Hotel.Methods.cs y Address.Methods.cs para las invalidaciones de ToString(). Estas clases se usan para representar los resultados de búsqueda en la salida de la consola. El contenido de estas clases no se proporciona en este artículo, pero puede copiar el código de los archivos de GitHub.
En Program.cs, cree un objeto SearchIndex y llame al método CreateIndex para expresar el índice en el servicio de búsqueda. El índice también incluye SearchSuggester, que habilita la función autocompletar en los campos especificados.
// Create hotels-quickstart index
private static void CreateIndex(string indexName, SearchIndexClient adminClient)
{
FieldBuilder fieldBuilder = new FieldBuilder();
var searchFields = fieldBuilder.Build(typeof(Hotel));
var definition = new SearchIndex(indexName, searchFields);
var suggester = new SearchSuggester("sg", new[] { "HotelName", "Category", "Address/City", "Address/StateProvince" });
definition.Suggesters.Add(suggester);
adminClient.CreateOrUpdateIndex(definition);
}
Carga de documentos
Azure AI Search busca en el contenido almacenado en el servicio. En este paso, el usuario cargará los documentos JSON que se ajustan al índice de hotel que acaba de crear.
En Azure AI Search, los documentos de búsqueda son estructuras de datos que se pueden usar como entradas para la indexación y como salidas de las consultas. Tal como se obtienen del origen de datos externo, las entradas de documento pueden ser las filas de una base de datos, los blobs en Blob Storage o documentos JSON en el disco. En este ejemplo vamos a atajar e insertaremos los documentos JSON para cuatro hoteles en el propio código.
Al cargar documentos, tiene que utilizar un objeto IndexDocumentsBatch. Un objeto IndexDocumentsBatch contiene una colección de Acciones, y cada una de ellas contiene un documento y una propiedad que indican a Azure AI Search la acción que debe realizar (carga, combinación, eliminación y mergeOrUpload).
En Program.cs, cree una matriz de documentos y las acciones de índice y pase la matriz a IndexDocumentsBatch. Los siguientes documentos se ajustan al índice hotels-quickstart, tal como se define mediante la clase hotel.
// Upload documents in a single Upload request.
private static void UploadDocuments(SearchClient searchClient)
{
IndexDocumentsBatch<Hotel> batch = IndexDocumentsBatch.Create(
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "1",
HotelName = "Stay-Kay City Hotel",
Description = "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
DescriptionFr = "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
Category = "Boutique",
Tags = new[] { "pool", "air conditioning", "concierge" },
ParkingIncluded = false,
LastRenovationDate = new DateTimeOffset(1970, 1, 18, 0, 0, 0, TimeSpan.Zero),
Rating = 3.6,
Address = new Address()
{
StreetAddress = "677 5th Ave",
City = "New York",
StateProvince = "NY",
PostalCode = "10022",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "2",
HotelName = "Old Century Hotel",
Description = "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
DescriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
Category = "Boutique",
Tags = new[] { "pool", "free wifi", "concierge" },
ParkingIncluded = false,
LastRenovationDate = new DateTimeOffset(1979, 2, 18, 0, 0, 0, TimeSpan.Zero),
Rating = 3.60,
Address = new Address()
{
StreetAddress = "140 University Town Center Dr",
City = "Sarasota",
StateProvince = "FL",
PostalCode = "34243",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "3",
HotelName = "Gastronomic Landscape Hotel",
Description = "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.",
DescriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
Category = "Resort and Spa",
Tags = new[] { "air conditioning", "bar", "continental breakfast" },
ParkingIncluded = true,
LastRenovationDate = new DateTimeOffset(2015, 9, 20, 0, 0, 0, TimeSpan.Zero),
Rating = 4.80,
Address = new Address()
{
StreetAddress = "3393 Peachtree Rd",
City = "Atlanta",
StateProvince = "GA",
PostalCode = "30326",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "4",
HotelName = "Sublime Palace Hotel",
Description = "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.",
DescriptionFr = "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.",
Category = "Boutique",
Tags = new[] { "concierge", "view", "24-hour front desk service" },
ParkingIncluded = true,
LastRenovationDate = new DateTimeOffset(1960, 2, 06, 0, 0, 0, TimeSpan.Zero),
Rating = 4.60,
Address = new Address()
{
StreetAddress = "7400 San Pedro Ave",
City = "San Antonio",
StateProvince = "TX",
PostalCode = "78216",
Country = "USA"
}
})
);
try
{
IndexDocumentsResult result = searchClient.IndexDocuments(batch);
}
catch (Exception)
{
// If for some reason any documents are dropped during indexing, you can compensate by delaying and
// retrying. This simple demo just logs the failed document keys and continues.
Console.WriteLine("Failed to index some of the documents: {0}");
}
}
Una vez inicializado el objeto IndexDocumentsBatch, puede enviarlo al índice mediante una llamada a IndexDocuments en el objeto SearchClient.
Agregue las siguientes líneas a Main(). La carga de documentos se realiza mediante SearchClient, pero la operación también requiere derechos de administrador en el servicio, lo cual se suele asociar a SearchIndexClient. Una manera de configurar esta operación es obtener SearchClient mediante SearchIndexClient (adminClient en este ejemplo).
SearchClient ingesterClient = adminClient.GetSearchClient(indexName);
// Load documents
Console.WriteLine("{0}", "Uploading documents...\n");
UploadDocuments(ingesterClient);
Dado que se trata de una aplicación de consola que ejecuta todos los comandos secuencialmente, agregue un tiempo de espera de 2 segundos entre la indexación y las consultas.
// Wait 2 seconds for indexing to complete before starting queries (for demo and console-app purposes only)
Console.WriteLine("Waiting for indexing...\n");
System.Threading.Thread.Sleep(2000);
El retraso de 2 segundos compensa por la indexación, que es asincrónica, por lo que todos los documentos se pueden indexar antes de que se ejecutan las consultas. La codificación en un retraso solo suele ser necesaria en las pruebas, demostraciones y aplicaciones de ejemplo.
Búsqueda de un índice
Puede obtener resultados de consulta tan pronto como se indexe el primer documento, pero las pruebas reales del índice deben esperar hasta que todos los documentos estén indexados.
Esta sección agrega dos funcionalidades: la lógica de consulta y los resultados. En el caso de las consultas, use el método Search. Este método admite texto de búsqueda (la cadena de consulta) y otras opciones.
La clase SearchResults representa los resultados.
En Program.cs, cree un método WriteDocuments, que imprime los resultados de la búsqueda en la consola.
// Write search results to console
private static void WriteDocuments(SearchResults<Hotel> searchResults)
{
foreach (SearchResult<Hotel> result in searchResults.GetResults())
{
Console.WriteLine(result.Document);
}
Console.WriteLine();
}
private static void WriteDocuments(AutocompleteResults autoResults)
{
foreach (AutocompleteItem result in autoResults.Results)
{
Console.WriteLine(result.Text);
}
Console.WriteLine();
}
Cree un método RunQueries para ejecutar consultas y devolver los resultados. Los resultados son objetos de Hotel. Este ejemplo muestra la firma del método y la primera consulta. Esta consulta muestra el parámetro Select, que permite crear el resultado con los campos seleccionados del documento.
// Run queries, use WriteDocuments to print output
private static void RunQueries(SearchClient srchclient)
{
SearchOptions options;
SearchResults<Hotel> response;
// Query 1
Console.WriteLine("Query #1: Search on empty term '*' to return all documents, showing a subset of fields...\n");
options = new SearchOptions()
{
IncludeTotalCount = true,
Filter = "",
OrderBy = { "" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Address/City");
response = srchclient.Search<Hotel>("*", options);
WriteDocuments(response);
En la segunda consulta, busque un término, agregue un filtro que seleccione los documentos cuya clasificación sea mayor que 4 y, a continuación, ordene por clasificación en orden descendente. Un filtro es una expresión booleana que se evalúa en campos IsFilterable en un índice. Las consultas de filtro incluyen o excluyen valores. Como tal, no hay puntuaciones de relevancia asociadas a una consulta de filtro.
// Query 2
Console.WriteLine("Query #2: Search on 'hotels', filter on 'Rating gt 4', sort by Rating in descending order...\n");
options = new SearchOptions()
{
Filter = "Rating gt 4",
OrderBy = { "Rating desc" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Rating");
response = srchclient.Search<Hotel>("hotels", options);
WriteDocuments(response);
La tercera consulta muestra searchFields, que se usa para delimitar una operación de búsqueda de texto completo a campos específicos.
// Query 3
Console.WriteLine("Query #3: Limit search to specific fields (pool in Tags field)...\n");
options = new SearchOptions()
{
SearchFields = { "Tags" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Tags");
response = srchclient.Search<Hotel>("pool", options);
WriteDocuments(response);
La cuarta consulta muestra facets, que se puede usar para estructurar una estructura de navegación por facetas.
// Query 4
Console.WriteLine("Query #4: Facet on 'Category'...\n");
options = new SearchOptions()
{
Filter = ""
};
options.Facets.Add("Category");
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Category");
response = srchclient.Search<Hotel>("*", options);
WriteDocuments(response);
En la quinta consulta se devuelve un documento específico. Una búsqueda de documentos es una respuesta típica al evento OnClick en un conjunto de resultados.
// Query 5
Console.WriteLine("Query #5: Look up a specific document...\n");
Response<Hotel> lookupResponse;
lookupResponse = srchclient.GetDocument<Hotel>("3");
Console.WriteLine(lookupResponse.Value.HotelId);
La última consulta muestra la sintaxis de autocompletar; se simula una entrada de usuario parcial sa que se resuelve en dos posibles coincidencias en los sourceFields asociados al que se ha definido en el índice.
// Query 6
Console.WriteLine("Query #6: Call Autocomplete on HotelName that starts with 'sa'...\n");
var autoresponse = srchclient.Autocomplete("sa", "sg");
WriteDocuments(autoresponse);
Agregue RunQueries a Main().
// Call the RunQueries method to invoke a series of queries
Console.WriteLine("Starting queries...\n");
RunQueries(srchclient);
// End the program
Console.WriteLine("{0}", "Complete. Press any key to end this program...\n");
Console.ReadKey();
Las consultas anteriores muestran varias maneras de buscar términos coincidentes en una consulta: búsqueda de texto completo, filtros y autocompletar.
Las búsquedas de texto completo y los filtros se realizan mediante el método SearchClient.Search. Se puede pasar una consulta de búsqueda en la cadena searchText, mientras que una expresión de filtro se puede pasar en la propiedad Filter de la clase SearchOptions. Para filtrar sin buscar, solo tiene que pasar "*" al parámetro searchText del método Search. Para buscar sin filtrar, deje la propiedad Filter sin establecer, o no pase ninguna instancia de SearchOptions.
Ejecución del programa
Presione F5 para recompilar la aplicación y ejecutar el programa en su totalidad.
La salida incluye mensajes de Console.WriteLIne, con la incorporación de la información de la consulta y los resultados.
Use un cuaderno de Jupyter Notebook y la biblioteca azure-search-documents del SDK de Azure para Python para crear, cargar y consultar un índice de búsqueda.
Como alternativa, puede descargar y ejecutar un cuaderno terminado.
Configurar el entorno
Use Visual Studio Code con la extensión de Python (o un IDE equivalente), con Python 3.10 o posterior.
Se recomienda un entorno virtual para esta guía de inicio rápido:
Inicie Visual Studio Code.
Abra la paleta de comandos (Ctrl+Mayús+P).
Busque Python: Crear entorno.
Seleccione Venv.
Seleccione un intérprete de Python. Elija la versión 3.10 o posterior.
Puede tardar un minuto en configurarse. Si tiene problemas, consulte Entornos de Python en VS Code.
Instalación de paquetes y establecimiento de variables
Instale paquetes, incluidos azure-search-documents.
! pip install azure-search-documents==11.6.0b1 --quiet
! pip install azure-identity --quiet
! pip install python-dotenv --quiet
Proporcione el punto de conexión y la clave de API para el servicio:
search_endpoint: str = "PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE"
search_api_key: str = "PUT-YOUR-SEARCH-SERVICE-ADMIN-API-KEY-HERE"
index_name: str = "hotels-quickstart"
Creación de un índice
from azure.core.credentials import AzureKeyCredential
credential = AzureKeyCredential(search_api_key)
from azure.search.documents.indexes import SearchIndexClient
from azure.search.documents import SearchClient
from azure.search.documents.indexes.models import (
ComplexField,
SimpleField,
SearchFieldDataType,
SearchableField,
SearchIndex
)
# Create a search schema
index_client = SearchIndexClient(
endpoint=search_endpoint, credential=credential)
fields = [
SimpleField(name="HotelId", type=SearchFieldDataType.String, key=True),
SearchableField(name="HotelName", type=SearchFieldDataType.String, sortable=True),
SearchableField(name="Description", type=SearchFieldDataType.String, analyzer_name="en.lucene"),
SearchableField(name="Description_fr", type=SearchFieldDataType.String, analyzer_name="fr.lucene"),
SearchableField(name="Category", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="Tags", collection=True, type=SearchFieldDataType.String, facetable=True, filterable=True),
SimpleField(name="ParkingIncluded", type=SearchFieldDataType.Boolean, facetable=True, filterable=True, sortable=True),
SimpleField(name="LastRenovationDate", type=SearchFieldDataType.DateTimeOffset, facetable=True, filterable=True, sortable=True),
SimpleField(name="Rating", type=SearchFieldDataType.Double, facetable=True, filterable=True, sortable=True),
ComplexField(name="Address", fields=[
SearchableField(name="StreetAddress", type=SearchFieldDataType.String),
SearchableField(name="City", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="StateProvince", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="PostalCode", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="Country", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
])
]
scoring_profiles = []
suggester = [{'name': 'sg', 'source_fields': ['Tags', 'Address/City', 'Address/Country']}]
# Create the search index
index = SearchIndex(name=index_name, fields=fields, suggesters=suggester, scoring_profiles=scoring_profiles)
result = index_client.create_or_update_index(index)
print(f' {result.name} created')
Creación de una carga de documentos
Use una acción de índice para el tipo de operación, como cargar o combinar y cargar. Los documentos se originan en el ejemplo de HotelsData en GitHub.
# Create a documents payload
documents = [
{
"@search.action": "upload",
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
"Category": "Boutique",
"Tags": [ "pool", "air conditioning", "concierge" ],
"ParkingIncluded": "false",
"LastRenovationDate": "1970-01-18T00:00:00Z",
"Rating": 3.60,
"Address": {
"StreetAddress": "677 5th Ave",
"City": "New York",
"StateProvince": "NY",
"PostalCode": "10022",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "2",
"HotelName": "Old Century Hotel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Boutique",
"Tags": [ "pool", "free wifi", "concierge" ],
"ParkingIncluded": "false",
"LastRenovationDate": "1979-02-18T00:00:00Z",
"Rating": 3.60,
"Address": {
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "3",
"HotelName": "Gastronomic Landscape Hotel",
"Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel's restaurant services.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Resort and Spa",
"Tags": [ "air conditioning", "bar", "continental breakfast" ],
"ParkingIncluded": "true",
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.80,
"Address": {
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "4",
"HotelName": "Sublime Palace Hotel",
"Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.",
"Description_fr": "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.",
"Category": "Boutique",
"Tags": [ "concierge", "view", "24-hour front desk service" ],
"ParkingIncluded": "true",
"LastRenovationDate": "1960-02-06T00:00:00Z",
"Rating": 4.60,
"Address": {
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216",
"Country": "USA"
}
}
]
Cargar documentos
# Upload documents to the index
search_client = SearchClient(endpoint=search_endpoint,
index_name=index_name,
credential=credential)
try:
result = search_client.upload_documents(documents=documents)
print("Upload of new document succeeded: {}".format(result[0].succeeded))
except Exception as ex:
print (ex.message)
index_client = SearchIndexClient(
endpoint=search_endpoint, credential=credential)
Ejecución de la primera consulta
Use el método search de la clase search.client.
Este ejemplo ejecuta una búsqueda vacía (search=*), que devuelve una lista no clasificada (puntuación de búsqueda = 1,0) de documentos arbitrarios. Dado que no hay ningún criterio, en los resultados se incluyen todos los documentos.
# Run an empty query (returns selected fields, all documents)
results = search_client.search(query_type='simple',
search_text="*" ,
select='HotelName,Description',
include_total_count=True)
print ('Total Documents Matching Query:', results.get_count())
for result in results:
print(result["@search.score"])
print(result["HotelName"])
print(f"Description: {result['Description']}")
Ejecución de una consulta de términos
La siguiente consulta agrega términos completos a la expresión de búsqueda ("wifi"). Esta consulta especifica que los resultados contienen solo los campos de la instrucción select. La limitación de los campos que se devuelven reduce la cantidad de datos que se envían mediante la conexión y reduce la latencia de búsqueda.
results = search_client.search(query_type='simple',
search_text="wifi" ,
select='HotelName,Description,Tags',
include_total_count=True)
print ('Total Documents Matching Query:', results.get_count())
for result in results:
print(result["@search.score"])
print(result["HotelName"])
print(f"Description: {result['Description']}")
Agregar un filtro
Agregue una expresión de filtro que devuelva solo aquellos hoteles con una clasificación superior a cuatro en orden descendente.
# Add a filter
results = search_client.search(
search_text="hotels",
select='HotelId,HotelName,Rating',
filter='Rating gt 4',
order_by='Rating desc')
for result in results:
print("{}: {} - {} rating".format(result["HotelId"], result["HotelName"], result["Rating"]))
Adición de ámbito de campo
Agregue search_fields a la ejecución de consultas de ámbito a campos específicos.
# Add search_fields to scope query matching to the HotelName field
results = search_client.search(
search_text="sublime",
search_fields=['HotelName'],
select='HotelId,HotelName')
for result in results:
print("{}: {}".format(result["HotelId"], result["HotelName"]))
Adición de facetas
Las facetas se generan para coincidencias positivas encontradas en los resultados de búsqueda. No hay ninguna coincidencia. Si los resultados de la búsqueda no incluyen el término wifi, wifi no aparece en la estructura de navegación por facetas.
# Return facets
results = search_client.search(search_text="*", facets=["Category"])
facets = results.get_facets()
for facet in facets["Category"]:
print(" {}".format(facet))
Búsqueda de un documento
Devuelve un documento basado en su clave. Esta operación es útil si desea proporcionar detalles cuando un usuario selecciona un elemento en un resultado de búsqueda.
# Look up a specific document by ID
result = search_client.get_document(key="3")
print("Details for hotel '3' are:")
print("Name: {}".format(result["HotelName"]))
print("Rating: {}".format(result["Rating"]))
print("Category: {}".format(result["Category"]))
Adición de la función Autocompletar
Autocompletar puede proporcionar posibles coincidencias como los tipos de usuario en el cuadro de búsqueda.
Autocompletar usa un proveedor de sugerencias (sg) para saber qué campos contienen posibles coincidencias con las solicitudes del proveedor de sugerencias. En este inicio rápido, esos campos son Tags, Address/City, Address/Country.
Para simular la función autocompletar, pase las letras sa como cadena parcial. El método autocompletar de SearchClient devuelve posibles coincidencias de términos.
# Autocomplete a query
search_suggestion = 'sa'
results = search_client.autocomplete(
search_text=search_suggestion,
suggester_name="sg",
mode='twoTerms')
print("Autocomplete for:", search_suggestion)
for result in results:
print (result['text'])
Cree una aplicación de consola de Java mediante la biblioteca Azure.Search.Documents para crear, cargar y consultar un índice de búsqueda.
Como alternativa, puede descargar el código fuente para empezar con un proyecto terminado o seguir los pasos de este artículo para crear su propio proyecto.
Configurar el entorno
Use las siguientes herramientas para crear este inicio rápido.
Creación del proyecto
Inicie Visual Studio Code.
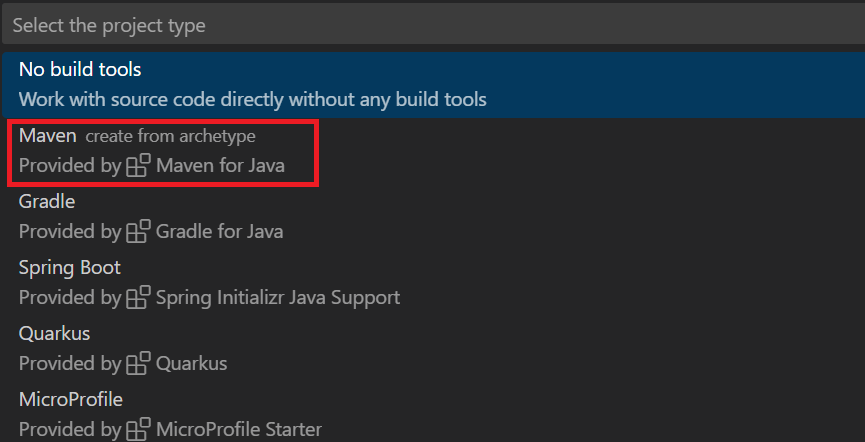
Abra la paleta de comandos mediante Ctrl+Mayús+P. Busque Crear proyecto de Java.

Seleccione Maven.
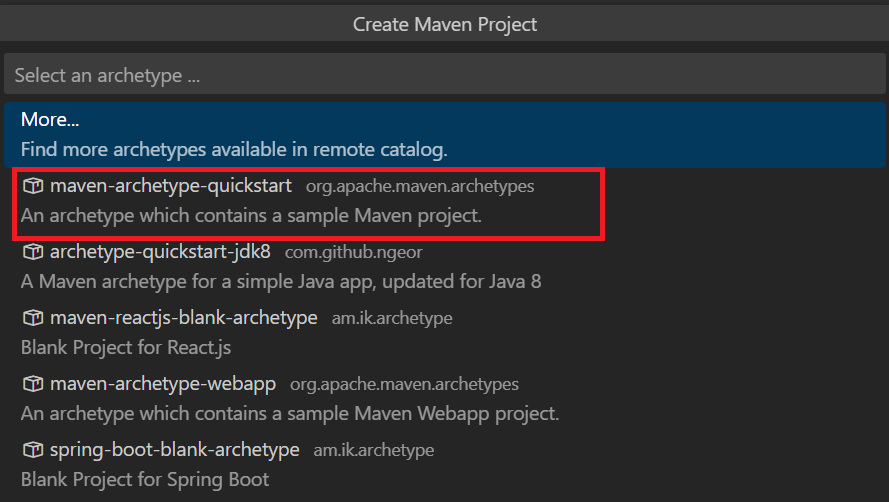
Seleccione maven-archetype-quickstart.
Seleccione la versión más reciente, actualmente 1.4.

Escriba azure.search.sample como identificador de grupo.
Escriba azuresearchquickstart como identificador de artefacto.

Seleccione la carpeta en la que se va a crear el proyecto.
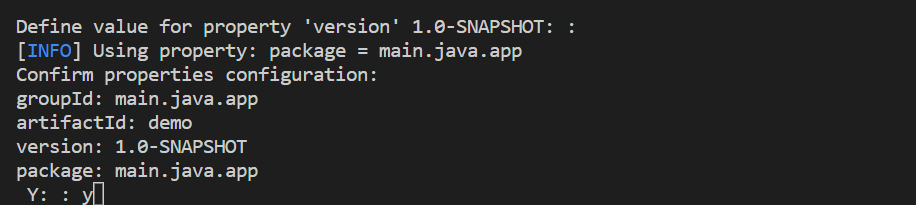
Finalice la creación del proyecto en el terminal integrado. Presione Entrar para aceptar el valor predeterminado de "1.0-SNAPSHOT" y, a continuación, escriba "y" para confirmar las propiedades del proyecto.
Abra la carpeta en la que creó el proyecto.
Especificación de las dependencias de Maven
Abra el archivo pom.xml y agregue las siguientes dependencias.
<dependencies>
<dependency>
<groupId>com.azure</groupId>
<artifactId>azure-search-documents</artifactId>
<version>11.7.3</version>
</dependency>
<dependency>
<groupId>com.azure</groupId>
<artifactId>azure-core</artifactId>
<version>1.53.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
Cambie la versión de Java del compilador a 11.
<maven.compiler.source>1.11</maven.compiler.source>
<maven.compiler.target>1.11</maven.compiler.target>
Creación de un cliente de búsqueda
Abra la clase App en src, main, java, azure, search, sample. Agregue las siguientes directivas de importación.
import java.util.Arrays;
import java.util.ArrayList;
import java.time.OffsetDateTime;
import java.time.ZoneOffset;
import java.time.LocalDateTime;
import java.time.LocalDate;
import java.time.LocalTime;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.Context;
import com.azure.search.documents.SearchClient;
import com.azure.search.documents.SearchClientBuilder;
import com.azure.search.documents.models.SearchOptions;
import com.azure.search.documents.indexes.SearchIndexClient;
import com.azure.search.documents.indexes.SearchIndexClientBuilder;
import com.azure.search.documents.indexes.models.IndexDocumentsBatch;
import com.azure.search.documents.indexes.models.SearchIndex;
import com.azure.search.documents.indexes.models.SearchSuggester;
import com.azure.search.documents.util.AutocompletePagedIterable;
import com.azure.search.documents.util.SearchPagedIterable;
En el ejemplo siguiente se incluyen marcadores de posición para un nombre de servicio de búsqueda, una clave de API de administrador que concede permisos de creación y eliminación, y el nombre del índice. Sustituya los valores válidos para los tres marcadores de posición. Cree dos clientes: SearchIndexClient crea el índice y SearchClient carga y consulta uno existente. Ambos necesitan el punto de conexión de servicio y una clave de API de administración para la autenticación con derechos de creación y eliminación.
public static void main(String[] args) {
var searchServiceEndpoint = "<YOUR-SEARCH-SERVICE-URL>";
var adminKey = new AzureKeyCredential("<YOUR-SEARCH-SERVICE-ADMIN-KEY>");
String indexName = "<YOUR-SEARCH-INDEX-NAME>";
SearchIndexClient searchIndexClient = new SearchIndexClientBuilder()
.endpoint(searchServiceEndpoint)
.credential(adminKey)
.buildClient();
SearchClient searchClient = new SearchClientBuilder()
.endpoint(searchServiceEndpoint)
.credential(adminKey)
.indexName(indexName)
.buildClient();
}
Creación de un índice
En este inicio rápido se crea un índice de hoteles que se cargará con datos de hotel y en el que se ejecutarán consultas. En este paso, defina los campos en el índice. Cada definición de campo incluye un nombre, un tipo de datos y atributos que determinan cómo se usa el campo.
En este ejemplo, se usan métodos sincrónicos de la biblioteca azure-search-documents para simplificar y mejorar la legibilidad. Sin embargo, para los escenarios de producción, debe usar métodos asincrónicos para mantener la aplicación escalable y receptiva. Por ejemplo, usaría SearchAsyncClient en lugar de SearchClient.
Agregue una definición de clase vacía al proyecto: Hotel.java
Copie el código siguiente en Hotel.java para definir la estructura de un documento de hotel. Los atributos del campo determinan cómo se utilizan en una aplicación. Por ejemplo, la anotación IsFilterable se tiene que asignar a cada campo que admita una expresión de filtro.
// Copyright (c) Microsoft Corporation. All rights reserved.
// Licensed under the MIT License.
package azure.search.sample;
import com.azure.search.documents.indexes.SearchableField;
import com.azure.search.documents.indexes.SimpleField;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonProperty;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
import java.time.OffsetDateTime;
/**
* Model class representing a hotel.
*/
@JsonInclude(Include.NON_NULL)
public class Hotel {
/**
* Hotel ID
*/
@JsonProperty("HotelId")
@SimpleField(isKey = true)
public String hotelId;
/**
* Hotel name
*/
@JsonProperty("HotelName")
@SearchableField(isSortable = true)
public String hotelName;
/**
* Description
*/
@JsonProperty("Description")
@SearchableField(analyzerName = "en.microsoft")
public String description;
/**
* French description
*/
@JsonProperty("DescriptionFr")
@SearchableField(analyzerName = "fr.lucene")
public String descriptionFr;
/**
* Category
*/
@JsonProperty("Category")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String category;
/**
* Tags
*/
@JsonProperty("Tags")
@SearchableField(isFilterable = true, isFacetable = true)
public String[] tags;
/**
* Whether parking is included
*/
@JsonProperty("ParkingIncluded")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public Boolean parkingIncluded;
/**
* Last renovation time
*/
@JsonProperty("LastRenovationDate")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public OffsetDateTime lastRenovationDate;
/**
* Rating
*/
@JsonProperty("Rating")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public Double rating;
/**
* Address
*/
@JsonProperty("Address")
public Address address;
@Override
public String toString()
{
try
{
return new ObjectMapper().writeValueAsString(this);
}
catch (JsonProcessingException e)
{
e.printStackTrace();
return "";
}
}
}
En la biblioteca cliente Azure.Search.Documents puede usar SearchableField y SimpleField para optimizar las definiciones de campo.
SimpleField puede ser cualquier tipo de datos, no permite búsquedas (se omite en las consultas de búsqueda de texto completo) y se puede recuperar (no está oculto). Otros atributos están desactivados de forma predeterminada, pero se pueden habilitar. Puede usar un SimpleField para los identificadores de documento o los campos que se usan solo en filtros, facetas o perfiles de puntuación. En caso de hacerlo, asegúrese de aplicar los atributos necesarios para el escenario, como IsKey = true para un identificador de documento.SearchableField debe ser una cadena y siempre permite búsquedas y se puede recuperar. Otros atributos están desactivados de forma predeterminada, pero se pueden habilitar. Ya que este tipo de campo se puede buscar, admite sinónimos y el complemento completo de las propiedades del analizador.
Tanto si usa la API básica de SearchField, como uno de los modelos auxiliares, debe habilitar explícitamente los atributos de filtro, faceta y ordenación. Por ejemplo, isFilterable, isSortable y isFacetable deben atribuirse explícitamente, como se muestra en el ejemplo anterior.
Agregue una segunda definición de clase vacía al proyecto: Address.java. Pegue el código siguiente en la clase.
// Copyright (c) Microsoft Corporation. All rights reserved.
// Licensed under the MIT License.
package azure.search.sample;
import com.azure.search.documents.indexes.SearchableField;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonProperty;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
/**
* Model class representing an address.
*/
@JsonInclude(Include.NON_NULL)
public class Address {
/**
* Street address
*/
@JsonProperty("StreetAddress")
@SearchableField
public String streetAddress;
/**
* City
*/
@JsonProperty("City")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String city;
/**
* State or province
*/
@JsonProperty("StateProvince")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String stateProvince;
/**
* Postal code
*/
@JsonProperty("PostalCode")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String postalCode;
/**
* Country
*/
@JsonProperty("Country")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String country;
}
En App.java, cree un objeto SearchIndex en el método main y, a continuación, llame al método createOrUpdateIndex para crear un índice en su servicio de búsqueda. El índice también incluye SearchSuggester, que habilita la función autocompletar en los campos especificados.
// Create Search Index for Hotel model
searchIndexClient.createOrUpdateIndex(
new SearchIndex(indexName, SearchIndexClient.buildSearchFields(Hotel.class, null))
.setSuggesters(new SearchSuggester("sg", Arrays.asList("HotelName"))));
Carga de documentos
Azure AI Search busca en el contenido almacenado en el servicio. En este paso, el usuario cargará los documentos JSON que se ajustan al índice de hotel que acaba de crear.
En Azure AI Search, los documentos de búsqueda son estructuras de datos que se pueden usar como entradas para la indexación y como salidas de las consultas. Tal como se obtienen del origen de datos externo, las entradas de documento pueden ser las filas de una base de datos, los blobs en Blob Storage o documentos JSON en el disco. En este ejemplo vamos a atajar e insertaremos los documentos JSON para cuatro hoteles en el propio código.
Al cargar documentos, tiene que utilizar un objeto IndexDocumentsBatch. Un objeto IndexDocumentsBatch contiene una colección de IndexActions, y cada una de ellas contiene un documento y una propiedad que indican a Azure AI Search la acción que debe realizar (carga, combinación, eliminación y mergeOrUpload).
En App.java, cree documentos y acciones de índice y, a continuación, páselos a IndexDocumentsBatch. Los siguientes documentos se ajustan al índice hotels-quickstart, tal como se define mediante la clase hotel.
// Upload documents in a single Upload request.
private static void uploadDocuments(SearchClient searchClient)
{
var hotelList = new ArrayList<Hotel>();
var hotel = new Hotel();
hotel.hotelId = "1";
hotel.hotelName = "Stay-Kay City Hotel";
hotel.description = "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.";
hotel.descriptionFr = "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.";
hotel.category = "Boutique";
hotel.tags = new String[] { "pool", "air conditioning", "concierge" };
hotel.parkingIncluded = false;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1970, 1, 18), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 3.6;
hotel.address = new Address();
hotel.address.streetAddress = "677 5th Ave";
hotel.address.city = "New York";
hotel.address.stateProvince = "NY";
hotel.address.postalCode = "10022";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "2";
hotel.hotelName = "Old Century Hotel";
hotel.description = "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.";
hotel.descriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.";
hotel.category = "Boutique";
hotel.tags = new String[] { "pool", "free wifi", "concierge" };
hotel.parkingIncluded = false;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1979, 2, 18), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 3.60;
hotel.address = new Address();
hotel.address.streetAddress = "140 University Town Center Dr";
hotel.address.city = "Sarasota";
hotel.address.stateProvince = "FL";
hotel.address.postalCode = "34243";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "3";
hotel.hotelName = "Gastronomic Landscape Hotel";
hotel.description = "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.";
hotel.descriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.";
hotel.category = "Resort and Spa";
hotel.tags = new String[] { "air conditioning", "bar", "continental breakfast" };
hotel.parkingIncluded = true;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(2015, 9, 20), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 4.80;
hotel.address = new Address();
hotel.address.streetAddress = "3393 Peachtree Rd";
hotel.address.city = "Atlanta";
hotel.address.stateProvince = "GA";
hotel.address.postalCode = "30326";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "4";
hotel.hotelName = "Sublime Palace Hotel";
hotel.description = "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.";
hotel.descriptionFr = "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.";
hotel.category = "Boutique";
hotel.tags = new String[] { "concierge", "view", "24-hour front desk service" };
hotel.parkingIncluded = true;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1960, 2, 06), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 4.60;
hotel.address = new Address();
hotel.address.streetAddress = "7400 San Pedro Ave";
hotel.address.city = "San Antonio";
hotel.address.stateProvince = "TX";
hotel.address.postalCode = "78216";
hotel.address.country = "USA";
hotelList.add(hotel);
var batch = new IndexDocumentsBatch<Hotel>();
batch.addMergeOrUploadActions(hotelList);
try
{
searchClient.indexDocuments(batch);
}
catch (Exception e)
{
e.printStackTrace();
// If for some reason any documents are dropped during indexing, you can compensate by delaying and
// retrying. This simple demo just logs failure and continues
System.err.println("Failed to index some of the documents");
}
}
Una vez que haya inicializado el objeto IndexDocumentsBatch, puede enviarlo al índice, para lo que debe realizar una llamada a indexDocuments en el objeto SearchClient.
Agregue las siguientes líneas a Main(). La carga de documentos se realiza mediante SearchClient.
// Upload sample hotel documents to the Search Index
uploadDocuments(searchClient);
Dado que se trata de una aplicación de consola que ejecuta todos los comandos secuencialmente, agregue un tiempo de espera de 2 segundos entre la indexación y las consultas.
// Wait 2 seconds for indexing to complete before starting queries (for demo and console-app purposes only)
System.out.println("Waiting for indexing...\n");
try
{
Thread.sleep(2000);
}
catch (InterruptedException e)
{
}
El retraso de 2 segundos compensa por la indexación, que es asincrónica, por lo que todos los documentos se pueden indexar antes de que se ejecutan las consultas. La codificación en un retraso solo suele ser necesaria en las pruebas, demostraciones y aplicaciones de ejemplo.
Búsqueda de un índice
Puede obtener resultados de consulta tan pronto como se indexe el primer documento, pero las pruebas reales del índice deben esperar hasta que todos los documentos estén indexados.
Esta sección agrega dos funcionalidades: la lógica de consulta y los resultados. En el caso de las consultas, use el método Search. Este método admite texto de búsqueda (la cadena de consulta) y otras opciones.
En App.java, cree un método WriteDocuments, que imprime los resultados de la búsqueda en la consola.
// Write search results to console
private static void WriteSearchResults(SearchPagedIterable searchResults)
{
searchResults.iterator().forEachRemaining(result ->
{
Hotel hotel = result.getDocument(Hotel.class);
System.out.println(hotel);
});
System.out.println();
}
// Write autocomplete results to console
private static void WriteAutocompleteResults(AutocompletePagedIterable autocompleteResults)
{
autocompleteResults.iterator().forEachRemaining(result ->
{
String text = result.getText();
System.out.println(text);
});
System.out.println();
}
Cree un método RunQueries para ejecutar consultas y devolver los resultados. Los resultados son objetos Hotel. Este ejemplo muestra la firma del método y la primera consulta. Esta consulta muestra el parámetro Select que permite crear el resultado con los campos seleccionados del documento.
// Run queries, use WriteDocuments to print output
private static void RunQueries(SearchClient searchClient)
{
// Query 1
System.out.println("Query #1: Search on empty term '*' to return all documents, showing a subset of fields...\n");
SearchOptions options = new SearchOptions();
options.setIncludeTotalCount(true);
options.setFilter("");
options.setOrderBy("");
options.setSelect("HotelId", "HotelName", "Address/City");
WriteSearchResults(searchClient.search("*", options, Context.NONE));
}
En la segunda consulta, busque un término, agregue un filtro que seleccione los documentos cuya clasificación sea mayor que 4 y, a continuación, ordene por clasificación en orden descendente. Un filtro es una expresión booleana que se evalúa en campos isFilterable en un índice. Las consultas de filtro incluyen o excluyen valores. Como tal, no hay puntuaciones de relevancia asociadas a una consulta de filtro.
// Query 2
System.out.println("Query #2: Search on 'hotels', filter on 'Rating gt 4', sort by Rating in descending order...\n");
options = new SearchOptions();
options.setFilter("Rating gt 4");
options.setOrderBy("Rating desc");
options.setSelect("HotelId", "HotelName", "Rating");
WriteSearchResults(searchClient.search("hotels", options, Context.NONE));
La tercera consulta muestra searchFields, que se usa para delimitar una operación de búsqueda de texto completo a campos específicos.
// Query 3
System.out.println("Query #3: Limit search to specific fields (pool in Tags field)...\n");
options = new SearchOptions();
options.setSearchFields("Tags");
options.setSelect("HotelId", "HotelName", "Tags");
WriteSearchResults(searchClient.search("pool", options, Context.NONE));
La cuarta consulta muestra facets, que se puede usar para estructurar una estructura de navegación por facetas.
// Query 4
System.out.println("Query #4: Facet on 'Category'...\n");
options = new SearchOptions();
options.setFilter("");
options.setFacets("Category");
options.setSelect("HotelId", "HotelName", "Category");
WriteSearchResults(searchClient.search("*", options, Context.NONE));
En la quinta consulta se devuelve un documento específico.
// Query 5
System.out.println("Query #5: Look up a specific document...\n");
Hotel lookupResponse = searchClient.getDocument("3", Hotel.class);
System.out.println(lookupResponse.hotelId);
System.out.println();
La última consulta muestra la sintaxis de autocompletar; se simula una entrada de usuario parcial s que se resuelve en dos posibles coincidencias en los sourceFields asociados al proveedor de sugerencias que se ha definido en el índice.
// Query 6
System.out.println("Query #6: Call Autocomplete on HotelName that starts with 's'...\n");
WriteAutocompleteResults(searchClient.autocomplete("s", "sg"));
Agregue RunQueries a Main().
// Call the RunQueries method to invoke a series of queries
System.out.println("Starting queries...\n");
RunQueries(searchClient);
// End the program
System.out.println("Complete.\n");
Las consultas anteriores muestran varias maneras de buscar términos coincidentes en una consulta: búsqueda de texto completo, filtros y autocompletar.
Las búsquedas de texto completo y los filtros se realizan mediante el método SearchClient.Search. Se puede pasar una consulta de búsqueda en la cadena searchText, mientras que una expresión de filtro se puede pasar en la propiedad filter de la clase SearchOptions. Para filtrar sin buscar, solo tiene que pasar "*" al parámetro searchText del método search. Para buscar sin filtrar, deje la propiedad filter sin establecer, o no pase ninguna instancia de SearchOptions.
Ejecución del programa
Presione F5 para recompilar la aplicación y ejecutar el programa en su totalidad.
La salida incluye mensajes de System.out.println, con la incorporación de la información de la consulta y los resultados.
Cree una aplicación de Node.js mediante la biblioteca @azure/search-documents para crear, cargar y consultar un índice de búsqueda.
Como alternativa, puede descargar el código fuente para empezar con un proyecto terminado o seguir los pasos de este artículo para crear su propio proyecto.
Configurar el entorno
Hemos usado las siguientes herramientas para crear este inicio rápido.
Creación del proyecto
Inicie Visual Studio Code.
Abra la paleta de comandos mediante Ctrl+Mayús+P y, luego, el terminal integrado.
Cree un directorio de desarrollo y asígnele el nombre inicio rápido:
mkdir quickstart
cd quickstart
Inicialice un proyecto vacío con npm al ejecutar el siguiente comando. Para inicializar completamente el proyecto, presione Entrar varias veces para aceptar los valores predeterminados, excepto la licencia, que debe establecer en MIT.
npm init
Instale @azure/search-documents, el SDK de JavaScript/TypeScript SDK para Azure AI Search.
npm install @azure/search-documents
Instale dotenv, que se usa para importar las variables de entorno, como su nombre de servicio de búsqueda y clave de API.
npm install dotenv
Vaya al directorio inicio rápido y confirme que ha configurado el proyecto y sus dependencias, para lo que debe comprobar que el archivo package.json es similar al siguiente código JSON:
{
"name": "quickstart",
"version": "1.0.0",
"description": "Azure AI Search Quickstart",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [
"Azure",
"Search"
],
"author": "Your Name",
"license": "MIT",
"dependencies": {
"@azure/search-documents": "^11.3.0",
"dotenv": "^16.0.2"
}
}
Cree un archivo .env que contenga los parámetros del servicio de búsqueda:
SEARCH_API_KEY=<YOUR-SEARCH-ADMIN-API-KEY>
SEARCH_API_ENDPOINT=<YOUR-SEARCH-SERVICE-URL>
Reemplace el valor YOUR-SEARCH-SERVICE-URL por el nombre de la dirección URL del punto de conexión del servicio de búsqueda. Reemplace <YOUR-SEARCH-ADMIN-API-KEY> por la clave de administrador que anotó anteriormente.
Creación del archivo index.js
A continuación, se crea un archivo index.js, que es el archivo principal que hospeda el código.
Al principio de este archivo, se importa la biblioteca @azure/search-documents:
const { SearchIndexClient, SearchClient, AzureKeyCredential, odata } = require("@azure/search-documents");
A continuación, es preciso requerir que el paquete dotenv lea los parámetros del archivo .env como se indica a continuación:
// Load the .env file if it exists
require("dotenv").config();
// Getting endpoint and apiKey from .env file
const endpoint = process.env.SEARCH_API_ENDPOINT || "";
const apiKey = process.env.SEARCH_API_KEY || "";
Con las importaciones y las variables de entorno incorporadas, ya se puede definir la función principal.
La mayor parte de la funcionalidad del SDK es asincrónica, por lo que async es la función principal. También se incluye main().catch() debajo de la función principal para detectar y registrar los errores encontrados:
async function main() {
console.log(`Running Azure AI Search JavaScript quickstart...`);
if (!endpoint || !apiKey) {
console.log("Make sure to set valid values for endpoint and apiKey with proper authorization.");
return;
}
// remaining quickstart code will go here
}
main().catch((err) => {
console.error("The sample encountered an error:", err);
});
A continuación, se puede crear un índice.
Crear índice
Cree el archivo hotels_quickstart_index.json. Este archivo define la forma en que Azure AI Search funciona con los documentos que va a cargar en el paso siguiente. Cada campo se identificará mediante un elemento name y tendrá un elemento especificado type. Cada campo también tiene una serie de atributos del índice que especifican si Azure AI Search puede buscar, filtrar, ordenar y cambiar las facetas del campo. La mayoría de los campos son tipos de datos simples; pero algunos, como AddressType, son tipos complejos que le permiten crear estructuras de datos enriquecidos en el índice. Puede leer más sobre los tipos de datos admitidos y los atributos de índice descritos en Creación de un índice (REST).
Agregue el siguiente contenido a hotels_quickstart_index.json, o bien descargue el archivo.
{
"name": "hotels-quickstart",
"fields": [
{
"name": "HotelId",
"type": "Edm.String",
"key": true,
"filterable": true
},
{
"name": "HotelName",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": true,
"facetable": false
},
{
"name": "Description",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "en.lucene"
},
{
"name": "Description_fr",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "fr.lucene"
},
{
"name": "Category",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Tags",
"type": "Collection(Edm.String)",
"searchable": true,
"filterable": true,
"sortable": false,
"facetable": true
},
{
"name": "ParkingIncluded",
"type": "Edm.Boolean",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "LastRenovationDate",
"type": "Edm.DateTimeOffset",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Rating",
"type": "Edm.Double",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Address",
"type": "Edm.ComplexType",
"fields": [
{
"name": "StreetAddress",
"type": "Edm.String",
"filterable": false,
"sortable": false,
"facetable": false,
"searchable": true
},
{
"name": "City",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "StateProvince",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "PostalCode",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Country",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [
"HotelName"
]
}
]
}
Con la definición del índice implementada, hay que importar hotels_quickstart_index.json al principio de index.js, con el fin de que la función principal pueda acceder a la definición del índice.
const indexDefinition = require('./hotels_quickstart_index.json');
Dentro de la función principal, se crea SearchIndexClient, que se usa para crear y administrar los índices de Azure AI Search.
const indexClient = new SearchIndexClient(endpoint, new AzureKeyCredential(apiKey));
Luego, se puede eliminar el índice si ya existe. Esta operación es una práctica común para el código de prueba o demostración.
Para ello, se define una función simple que intenta eliminar el índice.
async function deleteIndexIfExists(indexClient, indexName) {
try {
await indexClient.deleteIndex(indexName);
console.log('Deleting index...');
} catch {
console.log('Index does not exist yet.');
}
}
Para ejecutar la función, se extrae el nombre del índice de la definición del índice y se pasa indexName, junto con indexClient, a la función deleteIndexIfExists().
const indexName = indexDefinition["name"];
console.log('Checking if index exists...');
await deleteIndexIfExists(indexClient, indexName);
Después, se puede crear el índice con el método createIndex().
console.log('Creating index...');
let index = await indexClient.createIndex(indexDefinition);
console.log(`Index named ${index.name} has been created.`);
Ejecución del ejemplo
En este punto, ya está listo para ejecutar el ejemplo. Use una ventana de terminal para ejecutar el siguiente comando:
node index.js
Si descargó el código fuente y aún no ha instalado los paquetes necesarios, ejecute npm install primero.
Verá una serie de mensajes en los que se describen las acciones realizadas por el programa.
Abra la página Información general del servicio de búsqueda en Azure Portal. Seleccione la pestaña Índices. Debe ver algo parecido al siguiente ejemplo:
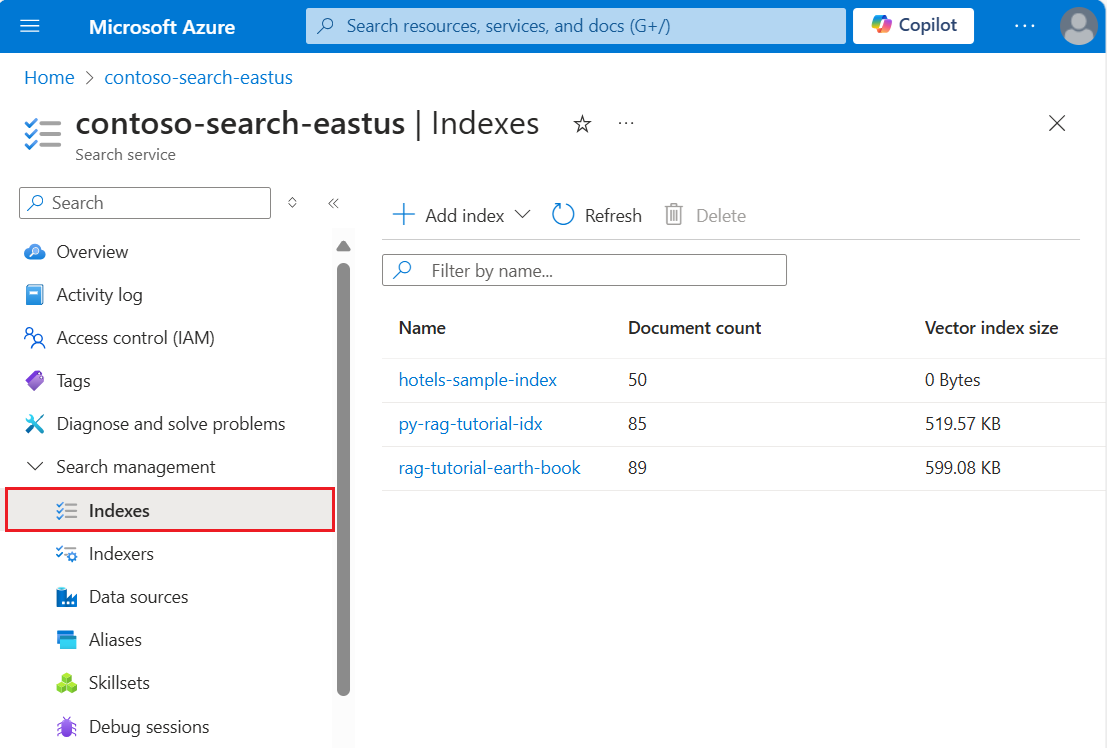
En el paso siguiente, agregará datos al índice.
Carga de documentos
En Azure AI Search, los documentos son estructuras de datos que son tanto entradas para la indexación como salidas de las consultas. Estos datos se pueden insertar en el índice, o bien se puede usar un indexador. En ese caso, los documentos se insertarán mediante programación en el índice.
Las entradas de documentos pueden ser filas de una base de datos, blobs en Blob Storage o, como en este ejemplo, documentos JSON en el disco. Puede descargar hotels.json, o bien puede crear su propio archivo hotels.json con el contenido siguiente:
{
"value": [
{
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
"Category": "Boutique",
"Tags": ["pool", "air conditioning", "concierge"],
"ParkingIncluded": false,
"LastRenovationDate": "1970-01-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "677 5th Ave",
"City": "New York",
"StateProvince": "NY",
"PostalCode": "10022"
}
},
{
"HotelId": "2",
"HotelName": "Old Century Hotel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Boutique",
"Tags": ["pool", "free wifi", "concierge"],
"ParkingIncluded": "false",
"LastRenovationDate": "1979-02-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243"
}
},
{
"HotelId": "3",
"HotelName": "Gastronomic Landscape Hotel",
"Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Resort and Spa",
"Tags": ["air conditioning", "bar", "continental breakfast"],
"ParkingIncluded": "true",
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.8,
"Address": {
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326"
}
},
{
"HotelId": "4",
"HotelName": "Sublime Palace Hotel",
"Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.",
"Description_fr": "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.",
"Category": "Boutique",
"Tags": ["concierge", "view", "24-hour front desk service"],
"ParkingIncluded": true,
"LastRenovationDate": "1960-02-06T00:00:00Z",
"Rating": 4.6,
"Address": {
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216"
}
}
]
}
De forma parecida a como se hizo con indexDefinition, también es preciso importar hotels.json al principio de index.js, con el fin de que se pueda acceder a los datos en la función principal.
const hotelData = require('./hotels.json');
Para indexar los datos en el índice de búsqueda, ahora es preciso crear SearchClient. Mientras que SearchIndexClient se usa para crear y administrar un índice, SearchClient se usa para cargar documentos y realizar consultas en el índice.
Hay dos formas de crear una SearchClient. La primera opción consiste en crear SearchClient desde cero:
const searchClient = new SearchClient(endpoint, indexName, new AzureKeyCredential(apiKey));
Como alternativa, puede utilizar el método getSearchClient() de SearchIndexClient para crear SearchClient:
const searchClient = indexClient.getSearchClient(indexName);
Ahora que el cliente está definido, cargue los documentos en el índice de búsqueda. En este caso, usamos el método mergeOrUploadDocuments(), que carga los documentos o los combina con un documento existente si ya existe un documento con la misma clave.
console.log('Uploading documents...');
let indexDocumentsResult = await searchClient.mergeOrUploadDocuments(hotelData['value']);
console.log(`Index operations succeeded: ${JSON.stringify(indexDocumentsResult.results[0].succeeded)}`);
Vuelva a ejecutar el programa con node index.js. Verá un conjunto de mensajes ligeramente distintos de los que ha visto en el paso 1. Esta vez, el índice sí existe y debería ver un mensaje relativo a su eliminación antes de que la aplicación cree el nuevo y publique datos en él.
Antes de ejecutar las consultas en el paso siguiente, defina una función para que el programa espere un segundo. Esta operación se realiza con fines de demostración o prueba, con el fin de garantizar que la indexación finaliza y que los documentos están disponibles en el índice para nuestras consultas.
function sleep(ms) {
var d = new Date();
var d2 = null;
do {
d2 = new Date();
} while (d2 - d < ms);
}
Para que el programa espere un segundo, llame a la función sleep como se indica a continuación:
sleep(1000);
Búsqueda de un índice
Una vez que haya creado un índice y se hayan cargado los documentos, estará listo para enviarle consultas. En esta sección, enviamos cinco consultas diferentes al índice de búsqueda para mostrar diferentes partes de la funcionalidad de consulta que tiene a su disposición.
Las consultas se escriben en una función sendQueries(), a la que llamamos en la función principal como se indica a continuación:
await sendQueries(searchClient);
Para enviar las consultas, se usa el método search() de searchClient. El primer parámetro es el texto de búsqueda y el segundo parámetro especifica opciones de búsqueda.
La primera consulta busca *, lo que equivale a buscar todo y seleccionar tres de los campos del índice. Es aconsejable usar select solo en los campos en que sea necesario, ya que la extracción de datos innecesarios puede agregar latencia a las consultas.
En esta consulta, searchOptions también tiene includeTotalCount establecido en true, lo que devuelve el número de resultados coincidentes que se han encontrado.
async function sendQueries(searchClient) {
console.log('Query #1 - search everything:');
let searchOptions = {
includeTotalCount: true,
select: ["HotelId", "HotelName", "Rating"]
};
let searchResults = await searchClient.search("*", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log(`Result count: ${searchResults.count}`);
// remaining queries go here
}
Las restantes consultas que se describen a continuación también se deben agregar a la función sendQueries(). Aquí aparecen separadas para mejorar la legibilidad.
En la siguiente consulta, se especifica el término de búsqueda "wifi" y también se incluye un filtro para que se devuelvan solo los resultados en los que el estado sea igual a 'FL'. Los resultados también se ordenan por el valor de Rating del hotel.
console.log('Query #2 - Search with filter, orderBy, and select:');
let state = 'FL';
searchOptions = {
filter: odata`Address/StateProvince eq ${state}`,
orderBy: ["Rating desc"],
select: ["HotelId", "HotelName", "Rating"]
};
searchResults = await searchClient.search("wifi", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
Luego, la búsqueda se limita a un único campo mediante el uso del parámetro searchFields. Este enfoque es una excelente opción si desea que la consulta sea más eficaz, pero solo si sabe que le interesan las coincidencias de determinados campos.
console.log('Query #3 - Limit searchFields:');
searchOptions = {
select: ["HotelId", "HotelName", "Rating"],
searchFields: ["HotelName"]
};
searchResults = await searchClient.search("Sublime Palace", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log();
Otra opción común que se incluye en las consultas es facets. Las facetas le permiten crear filtros en la interfaz de usuario, con el fin de que los usuarios sepan fácilmente por qué valores pueden filtrar.
console.log('Query #4 - Use facets:');
searchOptions = {
facets: ["Category"],
select: ["HotelId", "HotelName", "Rating"],
searchFields: ["HotelName"]
};
searchResults = await searchClient.search("*", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
La consulta final utiliza el método getDocument() de searchClient. Esto le permite recuperar de forma eficaz un documento por su clave.
console.log('Query #5 - Lookup document:');
let documentResult = await searchClient.getDocument(key='3')
console.log(`HotelId: ${documentResult.HotelId}; HotelName: ${documentResult.HotelName}`)
Ejecución del ejemplo
Ejecute el programa mediante node index.js. Ahora, además de los pasos anteriores, se envían las consultas y los resultados se escriben en la consola.
Cree una aplicación de Node.js mediante la biblioteca @azure/search-documents para crear, cargar y consultar un índice de búsqueda.
Como alternativa, puede descargar el código fuente para empezar con un proyecto terminado o seguir los pasos de este artículo para crear su propio proyecto.
Configurar el entorno
Hemos usado las siguientes herramientas para crear este inicio rápido.
Creación del proyecto
Inicie Visual Studio Code.
Abra la paleta de comandos mediante Ctrl+Mayús+P y, luego, el terminal integrado.
Cree un directorio de desarrollo y asígnele el nombre inicio rápido:
mkdir quickstart
cd quickstart
Inicialice un proyecto vacío con npm al ejecutar el siguiente comando. Para inicializar completamente el proyecto, presione Entrar varias veces para aceptar los valores predeterminados, excepto la licencia, que debe establecer en MIT.
npm init
Instale @azure/search-documents, el SDK de JavaScript/TypeScript SDK para Azure AI Search.
npm install @azure/search-documents
Instale dotenv, que se usa para importar las variables de entorno, como su nombre de servicio de búsqueda y clave de API.
npm install dotenv
Vaya al directorio inicio rápido y confirme que ha configurado el proyecto y sus dependencias, para lo que debe comprobar que el archivo package.json es similar al siguiente código JSON:
{
"name": "quickstart",
"version": "1.0.0",
"description": "Azure AI Search Quickstart",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [
"Azure",
"Search"
],
"author": "Your Name",
"license": "MIT",
"dependencies": {
"@azure/search-documents": "^12.1.0",
"dotenv": "^16.4.5"
}
}
Cree un archivo .env que contenga los parámetros del servicio de búsqueda:
SEARCH_API_KEY=<YOUR-SEARCH-ADMIN-API-KEY>
SEARCH_API_ENDPOINT=<YOUR-SEARCH-SERVICE-URL>
Reemplace el valor YOUR-SEARCH-SERVICE-URL por el nombre de la dirección URL del punto de conexión del servicio de búsqueda. Reemplace <YOUR-SEARCH-ADMIN-API-KEY> por la clave de administrador que anotó anteriormente.
Creación de un archivo de index.ts
A continuación, creamos un archivo index.ts, que es el archivo principal que hospedará nuestro código.
Al principio de este archivo, se importa la biblioteca @azure/search-documents:
import {
AzureKeyCredential,
ComplexField,
odata,
SearchClient,
SearchFieldArray,
SearchIndex,
SearchIndexClient,
SearchSuggester,
SimpleField
} from "@azure/search-documents";
A continuación, es preciso requerir que el paquete dotenv lea los parámetros del archivo .env como se indica a continuación:
// Load the .env file if it exists
import dotenv from 'dotenv';
dotenv.config();
// Getting endpoint and apiKey from .env file
const endpoint = process.env.SEARCH_API_ENDPOINT || "";
const apiKey = process.env.SEARCH_API_KEY || "";
Con las importaciones y las variables de entorno incorporadas, ya se puede definir la función principal.
La mayor parte de la funcionalidad del SDK es asincrónica, por lo que async es la función principal. También se incluye main().catch() debajo de la función principal para detectar y registrar los errores encontrados:
async function main() {
console.log(`Running Azure AI Search JavaScript quickstart...`);
if (!endpoint || !apiKey) {
console.log("Make sure to set valid values for endpoint and apiKey with proper authorization.");
return;
}
// remaining quickstart code will go here
}
main().catch((err) => {
console.error("The sample encountered an error:", err);
});
A continuación, se puede crear un índice.
Crear índice
Cree el archivo hotels_quickstart_index.json. Este archivo define la forma en que Azure AI Search funciona con los documentos que va a cargar en el paso siguiente. Cada campo se identificará mediante un elemento name y tendrá un elemento especificado type. Cada campo también tiene una serie de atributos del índice que especifican si Azure AI Search puede buscar, filtrar, ordenar y cambiar las facetas del campo. La mayoría de los campos son tipos de datos simples; pero algunos, como AddressType, son tipos complejos que le permiten crear estructuras de datos enriquecidos en el índice. Puede leer más sobre los tipos de datos admitidos y los atributos de índice descritos en Creación de un índice (REST).
Agregue el siguiente contenido a hotels_quickstart_index.json, o bien descargue el archivo.
{
"name": "hotels-quickstart",
"fields": [
{
"name": "HotelId",
"type": "Edm.String",
"key": true,
"filterable": true
},
{
"name": "HotelName",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": true,
"facetable": false
},
{
"name": "Description",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "en.lucene"
},
{
"name": "Description_fr",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "fr.lucene"
},
{
"name": "Category",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Tags",
"type": "Collection(Edm.String)",
"searchable": true,
"filterable": true,
"sortable": false,
"facetable": true
},
{
"name": "ParkingIncluded",
"type": "Edm.Boolean",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "LastRenovationDate",
"type": "Edm.DateTimeOffset",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Rating",
"type": "Edm.Double",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Address",
"type": "Edm.ComplexType",
"fields": [
{
"name": "StreetAddress",
"type": "Edm.String",
"filterable": false,
"sortable": false,
"facetable": false,
"searchable": true
},
{
"name": "City",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "StateProvince",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "PostalCode",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Country",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [
"HotelName"
]
}
]
}
Con la definición de índice en vigor, queremos importar hotels_quickstart_index.json en la parte superior de index.ts para que la función principal pueda acceder a la definición del índice.
// Importing the index definition and sample data
import indexDefinition from './hotels_quickstart_index.json';
interface HotelIndexDefinition {
name: string;
fields: SimpleField[] | ComplexField[];
suggesters: SearchSuggester[];
};
const hotelIndexDefinition: HotelIndexDefinition = indexDefinition as HotelIndexDefinition;
Dentro de la función principal, se crea SearchIndexClient, que se usa para crear y administrar los índices de Azure AI Search.
const indexClient = new SearchIndexClient(endpoint, new AzureKeyCredential(apiKey));
Luego, se puede eliminar el índice si ya existe. Esta operación es una práctica común para el código de prueba o demostración.
Para ello, se define una función simple que intenta eliminar el índice.
async function deleteIndexIfExists(indexClient: SearchIndexClient, indexName: string): Promise<void> {
try {
await indexClient.deleteIndex(indexName);
console.log('Deleting index...');
} catch {
console.log('Index does not exist yet.');
}
}
Para ejecutar la función, se extrae el nombre del índice de la definición del índice y se pasa indexName, junto con indexClient, a la función deleteIndexIfExists().
// Getting the name of the index from the index definition
const indexName: string = hotelIndexDefinition.name;
console.log('Checking if index exists...');
await deleteIndexIfExists(indexClient, indexName);
Después, se puede crear el índice con el método createIndex().
console.log('Creating index...');
let index = await indexClient.createIndex(hotelIndexDefinition);
console.log(`Index named ${index.name} has been created.`);
Ejecución del ejemplo
En este momento, está listo para compilar y ejecutar el ejemplo. Use una ventana de terminal para ejecutar los comandos siguientes para compilar el origen y tsc, a continuación, ejecute el origen con node:
tsc
node index.ts
Si descargó el código fuente y aún no ha instalado los paquetes necesarios, ejecute npm install primero.
Verá una serie de mensajes en los que se describen las acciones realizadas por el programa.
Abra la página Información general del servicio de búsqueda en Azure Portal. Seleccione la pestaña Índices. Debe ver algo parecido al siguiente ejemplo:
En el paso siguiente, agregará datos al índice.
Carga de documentos
En Azure AI Search, los documentos son estructuras de datos que son tanto entradas para la indexación como salidas de las consultas. Estos datos se pueden insertar en el índice, o bien se puede usar un indexador. En ese caso, los documentos se insertarán mediante programación en el índice.
Las entradas de documentos pueden ser filas de una base de datos, blobs en Blob Storage o, como en este ejemplo, documentos JSON en el disco. Puede descargar hotels.json, o bien puede crear su propio archivo hotels.json con el contenido siguiente:
{
"value": [
{
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
"Category": "Boutique",
"Tags": ["pool", "air conditioning", "concierge"],
"ParkingIncluded": false,
"LastRenovationDate": "1970-01-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "677 5th Ave",
"City": "New York",
"StateProvince": "NY",
"PostalCode": "10022"
}
},
{
"HotelId": "2",
"HotelName": "Old Century Hotel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Boutique",
"Tags": ["pool", "free wifi", "concierge"],
"ParkingIncluded": "false",
"LastRenovationDate": "1979-02-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243"
}
},
{
"HotelId": "3",
"HotelName": "Gastronomic Landscape Hotel",
"Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Resort and Spa",
"Tags": ["air conditioning", "bar", "continental breakfast"],
"ParkingIncluded": "true",
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.8,
"Address": {
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326"
}
},
{
"HotelId": "4",
"HotelName": "Sublime Palace Hotel",
"Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.",
"Description_fr": "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.",
"Category": "Boutique",
"Tags": ["concierge", "view", "24-hour front desk service"],
"ParkingIncluded": true,
"LastRenovationDate": "1960-02-06T00:00:00Z",
"Rating": 4.6,
"Address": {
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216"
}
}
]
}
De forma similar a lo que hicimos con indexDefinition, también es necesario importar hotels.json en la parte superior de index.ts para que se pueda acceder a los datos en nuestra función principal.
import hotelData from './hotels.json';
interface Hotel {
HotelId: string;
HotelName: string;
Description: string;
Description_fr: string;
Category: string;
Tags: string[];
ParkingIncluded: string | boolean;
LastRenovationDate: string;
Rating: number;
Address: {
StreetAddress: string;
City: string;
StateProvince: string;
PostalCode: string;
};
};
const hotels: Hotel[] = hotelData["value"];
Para indexar los datos en el índice de búsqueda, ahora es preciso crear SearchClient. Mientras que SearchIndexClient se usa para crear y administrar un índice, SearchClient se usa para cargar documentos y realizar consultas en el índice.
Hay dos formas de crear una SearchClient. La primera opción consiste en crear SearchClient desde cero:
const searchClient = new SearchClient<Hotel>(endpoint, indexName, new AzureKeyCredential(apiKey));
Como alternativa, puede utilizar el método getSearchClient() de SearchIndexClient para crear SearchClient:
const searchClient = indexClient.getSearchClient<Hotel>(indexName);
Ahora que el cliente está definido, cargue los documentos en el índice de búsqueda. En este caso, usamos el método mergeOrUploadDocuments(), que carga los documentos o los combina con un documento existente si ya existe un documento con la misma clave. A continuación, compruebe que la operación se realizó correctamente porque existe al menos el primer documento.
console.log("Uploading documents...");
const indexDocumentsResult = await searchClient.mergeOrUploadDocuments(hotels);
console.log(`Index operations succeeded: ${JSON.stringify(indexDocumentsResult.results[0].succeeded)}`);
Vuelva a ejecutar el programa con tsc && node index.ts. Verá un conjunto de mensajes ligeramente distintos de los que ha visto en el paso 1. Esta vez, el índice sí existe y debería ver un mensaje relativo a su eliminación antes de que la aplicación cree el nuevo y publique datos en él.
Antes de ejecutar las consultas en el paso siguiente, defina una función para que el programa espere un segundo. Esta operación se realiza con fines de demostración o prueba, con el fin de garantizar que la indexación finaliza y que los documentos están disponibles en el índice para nuestras consultas.
function sleep(ms: number): Promise<void> {
return new Promise((resolve) => setTimeout(resolve, ms));
}
Para que el programa espere un segundo, llame a la función sleep:
sleep(1000);
Búsqueda de un índice
Una vez que haya creado un índice y se hayan cargado los documentos, estará listo para enviarle consultas. En esta sección, enviamos cinco consultas diferentes al índice de búsqueda para mostrar diferentes partes de la funcionalidad de consulta que tiene a su disposición.
Las consultas se escriben en una función sendQueries(), a la que llamamos en la función principal como se indica a continuación:
await sendQueries(searchClient);
Para enviar las consultas, se usa el método search() de searchClient. El primer parámetro es el texto de búsqueda y el segundo parámetro especifica opciones de búsqueda.
La primera consulta busca *, lo que equivale a buscar todo y seleccionar tres de los campos del índice. Es aconsejable usar select solo en los campos en que sea necesario, ya que la extracción de datos innecesarios puede agregar latencia a las consultas.
En esta consulte, searchOptions también tiene includeTotalCount establecido en true, lo que devolverá el número de resultados coincidentes que se han encontrado.
async function sendQueries(
searchClient: SearchClient<Hotel>
): Promise<void> {
// Query 1
console.log('Query #1 - search everything:');
const selectFields: SearchFieldArray<Hotel> = [
"HotelId",
"HotelName",
"Rating",
];
const searchOptions1 = {
includeTotalCount: true,
select: selectFields
};
let searchResults = await searchClient.search("*", searchOptions1);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log(`Result count: ${searchResults.count}`);
// remaining queries go here
}
Las restantes consultas que se describen a continuación también se deben agregar a la función sendQueries(). Aquí aparecen separadas para mejorar la legibilidad.
En la siguiente consulta, se especifica el término de búsqueda "wifi" y también se incluye un filtro para que se devuelvan solo los resultados en los que el estado sea igual a 'FL'. Los resultados también se ordenan por el valor de Rating del hotel.
console.log('Query #2 - search with filter, orderBy, and select:');
let state = 'FL';
const searchOptions2 = {
filter: odata`Address/StateProvince eq ${state}`,
orderBy: ["Rating desc"],
select: selectFields
};
searchResults = await searchClient.search("wifi", searchOptions2);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
Luego, la búsqueda se limita a un único campo mediante el uso del parámetro searchFields. Este enfoque es una excelente opción si desea que la consulta sea más eficaz, pero solo si sabe que le interesan las coincidencias de determinados campos.
console.log('Query #3 - limit searchFields:');
const searchOptions3 = {
select: selectFields,
searchFields: ["HotelName"] as const
};
searchResults = await searchClient.search("Sublime Palace", searchOptions3);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
Otra opción común que se incluye en las consultas es facets. Las facetas permiten proporcionar la exploración en profundidad autodireccional de los resultados en la interfaz de usuario. Los resultados de facetas se pueden convertir en casillas en el panel de resultados.
console.log('Query #4 - limit searchFields and use facets:');
const searchOptions4 = {
facets: ["Category"],
select: selectFields,
searchFields: ["HotelName"] as const
};
searchResults = await searchClient.search("*", searchOptions4);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
La consulta final utiliza el método getDocument() de searchClient. Esto le permite recuperar de forma eficaz un documento por su clave.
console.log('Query #5 - Lookup document:');
let documentResult = await searchClient.getDocument('3')
console.log(`HotelId: ${documentResult.HotelId}; HotelName: ${documentResult.HotelName}`)
Volver a ejecutar la muestra
Compile y ejecute el programa con tsc && node index.ts. Ahora, además de los pasos anteriores, se envían las consultas y los resultados se escriben en la consola.
Cuando trabaje con su propia suscripción, es una buena idea al final de un proyecto identificar si todavía se necesitan los recursos que ha creado. Los recursos que se dejan en ejecución pueden costarle mucho dinero. Puede eliminar los recursos de forma individual o bien eliminar el grupo de recursos para eliminar todo el conjunto de recursos.
Si está usando un servicio gratuito, recuerde que está limitado a tres índices, indexadores y orígenes de datos. Puede eliminar elementos individuales en Azure Portal para mantenerse por debajo del límite.
En este inicio rápido, ha realizado un conjunto de tareas para crear un índice, cargar documentos en él y ejecutar consultas. En diferentes fases, hemos atajado para simplificar el código y mejorar la legibilidad y la comprensión. Ahora que ya conoce los conceptos básicos, pruebe el tutorial que llama a las API de Azure AI Search en una aplicación web.