Tutorial de REST: Uso de conjuntos de aptitudes para generar contenido que se puede buscar en la Búsqueda de Azure AI
En este tutorial, aprenderá a llamar a las API de REST que crean una canalización de enriquecimiento con IA para la extracción y las transformaciones de contenido durante la indexación.
Los conjuntos de aptitudes agregan procesamiento de IA al contenido sin procesar, lo que hace que ese contenido sea más uniforme y se pueda buscar. Una vez que sepa cómo funcionan los conjuntos de aptitudes, puede admitir una amplia gama de transformaciones: desde el análisis de imágenes hasta el procesamiento de lenguaje natural, para el procesamiento personalizado que proporcione externamente.
En este tutorial, aprenderá a:
- Definir objetos en una canalización de enriquecimiento.
- Crear un conjunto de aptitudes. Invocar OCR, detección de idioma, reconocimiento de entidades y extracción de frases clave.
- Ejecutar la canalización. Crear y cargar un índice de búsqueda.
- Comprobar los resultados mediante la búsqueda de texto completo.
Si no tiene una suscripción a Azure, abra una cuenta gratuita antes de empezar.
Información general
En este tutorial se usa un cliente REST y las API de REST de la Búsqueda de Azure AI para crear un origen de datos, un índice, un indexador y un conjunto de aptitudes.
El indexador controla cada paso de la canalización, empezando por la extracción de contenido de datos de ejemplo (texto e imágenes no estructurados) en un contenedor de blobs en Azure Storage.
Una vez extraído el contenido, el conjunto de aptitudes ejecuta aptitudes integradas de Microsoft para buscar y extraer información. Estas aptitudes incluyen el reconocimiento óptico de caracteres (OCR) en imágenes, la detección de idiomas en texto, la extracción de frases clave y el reconocimiento de entidades (organizaciones). La nueva información creada por el conjunto de aptitudes se envía a los campos de un índice. Una vez que se rellenan los datos del índice, se pueden usar los campos en las consultas, las facetas y los filtros.
Requisitos previos
Nota:
Puede usar un servicio de búsqueda gratuito para este tutorial. El nivel gratis le limita a tres índices, tres indexadores y tres orígenes de datos. En este tutorial se crea uno de cada uno. Antes de empezar, asegúrese de que haya espacio en el servicio para aceptar los nuevos recursos.
Descarga de archivos
Descargue un archivo ZIP del repositorio de datos de ejemplo y extraiga el contenido. Más información.
Carga de datos de ejemplo en Azure Storage
En Azure Storage, cree un contenedor y asígnele el nombre cog-search-demo.
Obtenga una cadena de conexión de almacenamiento para poder formular una conexión en Azure AI Search.
A la izquierda, seleccione Teclas de acceso.
Copie la cadena de conexión para la clave uno o la clave dos. La cadena de conexión es parecida a la del ejemplo siguiente:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Servicios de Azure AI
El enriquecimiento con IA integrado tiene el respaldo de los servicios de Azure AI, lo que incluye el servicio de lenguaje y Visión de Azure AI para el procesamiento de imágenes y del lenguaje natural. Para cargas de trabajo pequeñas como en este tutorial, puede usar la asignación gratuita de veinte transacciones por indexador. Para cargas de trabajo más grandes, adjunte un recurso de varias regiones de Servicios de Azure AI a un conjunto de aptitudes para los precios de pago por uso.
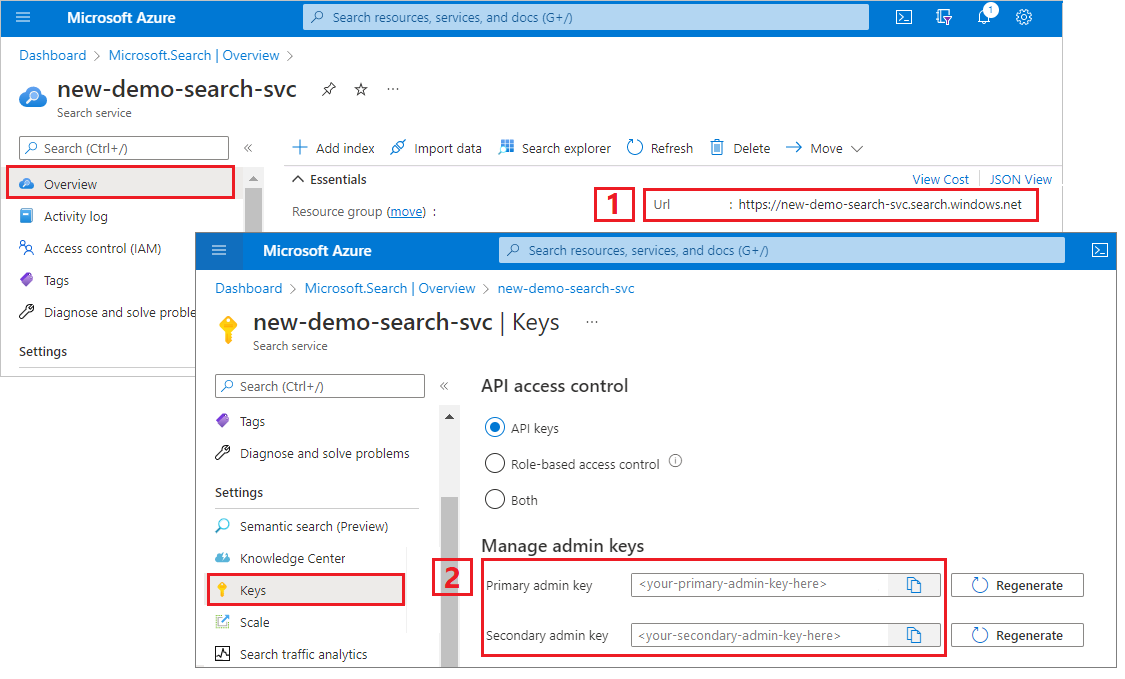
Copia de una dirección URL del servicio de búsqueda y una clave de API
Para este tutorial, las conexiones a la búsqueda de Azure AI requieren un punto de conexión y una clave de API. Puede obtener estos valores en Azure Portal.
Inicie sesión en Azure Portal, vaya a la página Información general del servicio de búsqueda y copie la dirección URL. Un punto de conexión de ejemplo podría ser similar a
https://mydemo.search.windows.net.En Configuración>Claves, copie una clave de administrador. Las claves de administrador se utilizan para agregar, modificar y eliminar objetos. Hay dos claves de administrador intercambiables. Copie una de las dos.
Configuración del archivo REST
Inicie Visual Studio Code y abra el archivo skillset-tutorial.rest. Consulte Inicio rápido: Búsqueda de texto mediante REST si necesita ayuda con el cliente REST.
Proporcione valores de las variables: punto de conexión del servicio de búsqueda, clave de API de administración del servicio de búsqueda, un nombre de índice, una cadena de conexión a la cuenta de Azure Storage y el nombre del contenedor de blobs.
Creación de la canalización
El enriquecimiento con IA está controlado por indexadores. En esta parte del tutorial se crean cuatro objetos: origen de datos, definición de índice, conjunto de aptitudes, indexador.
Paso 1: Creación de un origen de datos
Llame a Create Data Source (creación de un origen de datos) para configurar la cadena de conexión al contenedor de blobs que contiene los archivos de datos de ejemplo.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Paso 2: Creación de un conjunto de aptitudes
Llame a Create Skillset (creación de un conjunto de aptitudes) para especificar qué pasos de enriquecimiento se aplican al contenido. Las aptitudes se ejecutan en paralelo a menos que haya una dependencia.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ss",
"description": "Apply OCR, detect language, extract entities, and extract key-phrases.",
"cognitiveServices": null,
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name":"offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"textSplitMode": "pages",
"maximumPageLength": 4000,
"defaultLanguageCode": "en",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.LanguageDetectionSkill",
"description": "If you have multilingual content, adding a language code is useful for filtering",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "languageName",
"targetName": "language"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Organization"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "organizations",
"targetName": "organizations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Location"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "locations",
"targetName": "locations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Person"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons",
"targetName": "persons"
}
]
}
]
}
Puntos clave:
El cuerpo de la solicitud especifica las siguientes aptitudes integradas:
Habilidad Descripción Reconocimiento óptico de caracteres Reconoce texto y números en archivos de imagen. Combinación de texto Crea "contenido combinado" que recombina contenido previamente separado, útil para documentos con imágenes insertadas (PDF, DOCX, etc.). Las imágenes y el texto se separan durante la fase de descifrado de documentos. La aptitud de fusión mediante combinación los vuelve a combinar mediante la inserción de cualquier texto reconocido, títulos de imagen o etiquetas creados durante el enriquecimiento en la misma ubicación en que se extrajo la imagen en el documento. Al trabajar con contenido combinado en un conjunto de aptitudes, este nodo contiene todo el texto del documento, incluidos los documentos de solo texto que nunca se someten a OCR o al análisis de imágenes. Detección de idioma Detecta el idioma y genera un nombre de idioma o un código. En los conjuntos de datos multilingües, un campo de idioma puede ser útil para los filtros. Reconocimiento de entidades Extrae los nombres de las personas, organizaciones y ubicaciones del contenido combinado. División de texto Divide el contenido combinado de gran tamaño en fragmentos más pequeños antes de llamar a la aptitud de extracción de frases clave. La extracción de frases clave acepta entradas de 50 000 caracteres o menos. Algunos de los archivos de ejemplo deben dividirse para no superar este límite. Extracción de frases clave Extrae las principales frases clave. Cada aptitud se ejecuta en el contenido del documento. Durante el procesamiento, Azure AI Search descifra todos los documentos para leer el contenido de diferentes formatos de archivo. El texto encontrado procedente del archivo de origen se coloca en un campo
contentgenerado, uno para cada documento. Como tal, la entrada pasa a ser"/document/content".Para la extracción de las frases clave, al usar el separador de texto para dividir los archivos grandes en páginas, el contenido de la aptitud de la extracción de frases clave es
"document/pages/*"(para cada página del documento) en lugar de"/document/content".
Nota:
Las salidas se pueden asignar a un índice, usar como entrada para una aptitud descendente, o ambas cosas como sucede con el código de idioma. En el índice, un código de idioma es útil para el filtrado. Para obtener más información sobre los conceptos básicos del conjunto de aptitudes, consulte el tema sobre la definición de un conjunto de aptitudes.
Paso 3: Creación de un índice
Llame a Create Index para proporcionar el esquema que se usa para crear índices invertidos y otras construcciones en Azure AI Search.
El componente mayor de un índice es la colección de campos, donde el tipo de datos y los atributos determinan tanto el contenido como el comportamiento en Azure AI Search. Asegúrese de que tiene campos para la salida recién generada.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idx",
"defaultScoringProfile": "",
"fields": [
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "text",
"type": "Collection(Edm.String)",
"facetable": false,
"filterable": true,
"searchable": true,
"sortable": false
},
{
"name": "language",
"type": "Edm.String",
"searchable": false,
"sortable": true,
"filterable": true,
"facetable": false
},
{
"name": "keyPhrases",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "organizations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "persons",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "locations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "metadata_storage_path",
"type": "Edm.String",
"key": true,
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
}
]
}
Paso 4: Creación y ejecución de un indexador
Llame a Create Indexer (creación de un indizador) para impulsar la canalización. Los tres componentes que ha creado hasta ahora (origen de datos, conjunto de aptitudes e índice) son entradas para un indexador. La creación del indexador en Azure AI Search es el evento que pone toda la canalización en movimiento.
Este paso puede tardar varios minutos en completarse. Aunque el conjunto de datos es pequeño, las aptitudes analíticas realiza un uso intensivo de los recursos.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idxr",
"description": "",
"dataSourceName" : "cog-search-demo-ds",
"targetIndexName" : "cog-search-demo-idx",
"skillsetName" : "cog-search-demo-ss",
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" }
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
}
],
"outputFieldMappings" :
[
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "content"
},
{
"sourceFieldName" : "/document/normalized_images/*/text",
"targetFieldName" : "text"
},
{
"sourceFieldName" : "/document/organizations",
"targetFieldName" : "organizations"
},
{
"sourceFieldName": "/document/language",
"targetFieldName": "language"
},
{
"sourceFieldName" : "/document/persons",
"targetFieldName" : "persons"
},
{
"sourceFieldName" : "/document/locations",
"targetFieldName" : "locations"
},
{
"sourceFieldName" : "/document/pages/*/keyPhrases/*",
"targetFieldName" : "keyPhrases"
}
],
"parameters":
{
"batchSize": 1,
"maxFailedItems":-1,
"maxFailedItemsPerBatch":-1,
"configuration":
{
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages"
}
}
}
Puntos clave:
El cuerpo de la solicitud incluye referencias a los objetos anteriores, propiedades de configuración necesarias para el procesamiento de imágenes y dos tipos de asignaciones de campos.
"fieldMappings"se procesan antes que el conjunto de aptitudes y envían el contenido del origen de datos a los campos de destino de un índice. Usará asignaciones de campos para enviar contenido existente sin modificar al índice. Si los tipos y nombres de campo son los mismos en ambos extremos, no se requiere ninguna asignación."outputFieldMappings"son para los campos creados por aptitudes, después de la ejecución del conjunto de aptitudes. Las referencias asourceFieldNameenoutputFieldMappingsno existen hasta que el descifrado de documentos o el enriquecimiento las crean.targetFieldNamees un campo de un índice definido en el esquema del índice.El parámetro
"maxFailedItems"se establece en -1, lo que indica al motor de indexación que omita los errores durante la importación de datos. Esto es aceptable porque hay muy pocos documentos en el origen de datos de demostración. Para un origen de datos mayor, debería establecer un valor mayor que 0.La instrucción
"dataToExtract":"contentAndMetadata"le indica al indizador que extraiga automáticamente los valores de la propiedad de contenido del blob y los metadatos de cada objeto.El parámetro
imageActionindica al indexador que extraiga el texto de las imágenes que se encuentran en el origen de datos. La configuración de"imageAction":"generateNormalizedImages", en combinación con OCR Skill y Text Merge Skill, le dice al indexador que extraiga texto de las imágenes (por ejemplo, la palabra "stop" de una señal de Stop de tráfico) y lo inserte como parte del campo de contenido. Este comportamiento se aplica tanto a las imágenes insertadas (por ejemplo, una imagen dentro de un PDF) como a los archivos de imagen independientes, como un archivo JPG.
Nota:
La creación de un indexador invoca la canalización. Si hay problemas para conectar con los datos, las entradas y salidas de asignación o el orden de las operaciones, se muestran en esta fase. Para volver a ejecutar la canalización con los cambios de código o script, deberá quitar primero los objetos. Para más información, consulte Restablecer y volver a ejecutar.
Supervisión de la indexación
La indexación y el enriquecimiento comienzan en cuanto se envía la solicitud de creación de indexador. En función de la complejidad y las operaciones del conjunto de aptitudes, la indexación puede tardar un tiempo.
Para averiguar si el indexador todavía se está ejecutando, llame a Get Indexer Status (obtener estado de indizador) para comprobar el estado del indizador.
### Get Indexer Status (wait several minutes for the indexer to complete)
GET {{baseUrl}}/indexers/cog-search-demo-idxr/status?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Puntos clave:
Las advertencias son comunes en algunos escenarios y no siempre indican un problema. Por ejemplo, si un contenedor de blobs incluye archivos de imagen y la canalización no controla imágenes, recibirá una advertencia que indica que no se procesaron las imágenes.
En este ejemplo, hay un archivo PNG que no contiene texto. Ninguna de las cinco aptitudes basadas en texto (detección de idioma, reconocimiento de entidades de ubicaciones, organizaciones, personas y extracción de frases clave) se pueden ejecutar en este archivo. La notificación resultante se muestra en el historial de ejecución.
Comprobar los resultados
Ahora que ha creado un índice que contiene contenido generado por inteligencia artificial, llame a Search Documents (búsqueda de documentos) para ejecutar algunas consultas para ver los resultados.
### Query the index\
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"select": "metadata_storage_name,language,organizations",
"count": true
}
Los filtros pueden ayudarle a restringir los resultados a los elementos de interés:
### Filter by organization
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"filter": "organizations/any(organizations: organizations eq 'Microsoft')",
"select": "metadata_storage_name,organizations",
"count": true
}
Estas consultas muestran algunas de las formas en que puede trabajar con sintaxis de consulta y filtros en nuevos campos creados por Azure AI Search. Para más ejemplos de consultas, vea Ejemplos de la API REST de búsqueda de documentos, Ejemplos de consulta de sintaxis simple y Ejemplos de consultas que usan la sintaxis de búsqueda de Lucene "completa".
Restablecer y volver a ejecutar
Durante las primeras fases del desarrollo, es habitual la iteración sobre el diseño. Restablecer y volver a ejecutar ayuda con la iteración.
Puntos clave
En este tutorial se muestran los pasos básicos para usar las API de REST para crear una canalización de enriquecimiento con IA: un origen de datos, un conjunto de aptitudes, un índice y un indexador.
Se presentaron las aptitudes integradas, junto con la definición del conjunto de aptitudes que muestra los mecanismos de encadenamiento de aptitudes, mediante entradas y salidas. También ha aprendido que outputFieldMappings en la definición del indexador se necesita para enrutar los valores enriquecidos de la canalización a un índice que permita búsquedas en un servicio Azure AI Search.
Por último, ha aprendido cómo probar los resultados y restablecer el sistema para otras iteraciones. Ha aprendido que emitir consultas en el índice devuelve la salida creada por la canalización de indexación enriquecida.
Limpieza de recursos
Cuando trabaje con su propia suscripción, al final de un proyecto, es recomendable eliminar los recursos que ya no necesite. Los recursos que se dejan en ejecución pueden costarle mucho dinero. Puede eliminar los recursos de forma individual o bien eliminar el grupo de recursos para eliminar todo el conjunto de recursos.
Puede encontrar y administrar recursos en Azure Portal mediante el vínculo Todos los recursos o Grupos de recursos en el panel de navegación izquierdo.
Pasos siguientes
Ahora que está familiarizado con todos los objetos de una canalización de enriquecimiento con IA, dele un vistazo más de cerca a las definiciones y conocimientos individuales del conjunto de aptitudes.