Opciones de configuración para minimizar la latencia de red con aplicaciones SAP
Importante
En noviembre de 2021, hemos realizado cambios significativos en la forma en que se deben usar los grupos con ubicación por proximidad con la carga de trabajo de SAP en implementaciones zonales.
Las aplicaciones SAP basadas en la arquitectura SAP NetWeaver o SAP S/4HANA son sensibles a la latencia de red entre la capa de aplicación de SAP y el nivel de base de datos de SAP. Esta sensibilidad es el resultado de la mayor parte de la lógica de negocios que se ejecuta en el nivel de aplicación. Dado que el nivel de aplicación de SAP ejecuta la lógica de negocios, emite consultas al nivel de base de datos con una elevada frecuencia a una velocidad de miles o decenas de miles de consultas por segundo. En la mayoría de los casos, la naturaleza de estas consultas es sencilla. A menudo, se pueden ejecutar en el nivel de base de datos en 500 microsegundos o menos.
El tiempo invertido en la red para enviar una consulta de este tipo desde la capa de aplicación al nivel de base de datos y recibir el conjunto de resultados influye considerablemente en el tiempo que se tarda en ejecutar procesos empresariales. Esta sensibilidad a la latencia de red es la razón por la que se debe lograr una latencia de red mínima en proyectos de implementación de SAP. Consulte la Nota de SAP 1100926 - Preguntas más frecuentes: rendimiento de red para obtener directrices para clasificar la latencia de red.
En muchas regiones de Azure, el número de centros de datos ha crecido. Al mismo tiempo, los clientes, especialmente para los sistemas SAP de gama alta, usan familias de máquinas virtuales más especiales, como la familia Mv2 o Mv3 y versiones más recientes. Son tipos de máquinas virtuales de Azure que no siempre están disponibles en cada uno de los centros de datos que se recopilan en una región de Azure. Estos hechos pueden crear oportunidades para optimizar la latencia de red entre la capa de aplicación de SAP y la capa de DBMS de SAP.
Azure proporciona diferentes opciones de implementación para cargas de trabajo de SAP. Para el tipo de implementación elegido, tiene opciones para optimizar la latencia de red, si es necesario. La información detallada sobre cada opción se describe exhaustivamente en las secciones siguientes de este artículo:
- Grupos con ubicación por proximidad
- Conjunto de escalado de máquinas virtuales con orquestación flexible
Grupos con ubicación por proximidad
grupos de selección de ubicación de proximidad habilitar la agrupación de diferentes tipos de máquina virtual en una sola columna vertebral de red, lo que garantiza una latencia de red baja óptima entre ellos. Cuando la primera máquina virtual se implementa en el grupo con ubicación por proximidad, esa máquina virtual se enlaza a un tronco de red específico. Como todas las demás máquinas virtuales que se van a implementar en el mismo grupo con ubicación por proximidad, esas máquinas virtuales se agrupan en la misma zona de red. Aunque esta posibilidad sea muy atractiva, el uso de la construcción incluye también algunas restricciones y dificultades:
- No se debe suponer que todos los tipos de máquinas virtuales de Azure están disponibles en todos los centros de datos de Azure o en todos y cada uno de los troncos de red. Como resultado, se puede restringir la combinación de diferentes tipos de máquinas virtuales dentro de un grupo con ubicación por proximidad. Estas restricciones se producen porque es posible que el hardware de host necesario para ejecutar un tipo de máquina virtual determinado no esté presente en el centro de datos o en la zona de red a la que se asignó el grupo con ubicación por proximidad.
- Al cambiar el tamaño de las partes de las máquinas virtuales que se encuentran dentro de un grupo con ubicación por proximidad, no se dede suponer automáticamente que, en todos los casos, el nuevo tipo de máquina virtual está disponible en el mismo centro de datos o en la zona de red a la que se asignó el grupo con ubicación por proximidad.
- A medida que Azure retira hardware, puede forzar que determinadas máquinas virtuales de un grupo con ubicación por proximidad se muevan a otro centro de datos de Azure o a otro tronco de red. Para más información sobre este caso, consulte el documento Grupos con ubicación por proximidad.
Importante
Como resultado de las posibles restricciones, solo se deben usar grupos con ubicación por proximidad:
- Cuando sea necesario en determinados escenarios (consulte más adelante)
- Cuando la latencia de red entre la capa de aplicación y la capa de DBMS es demasiado alta y afecta a la carga de trabajo
- Solo en la granularidad de un único sistema SAP y no en todo el entorno del sistema o en un entorno completo de SAP
- Para mantener al mínimo los distintos tipos de máquina virtual y el número de máquinas virtuales dentro de un grupo con ubicación por proximidad
Escenarios en los que se pueden usar grupos de selección de ubicación de proximidad para optimizar la latencia de red:
- Quiere implementar los recursos críticos de la carga de trabajo de SAP en distintas zonas de disponibilidad y, por otro lado, necesita máquinas virtuales del nivel de aplicación para distribuirse entre distintos dominios de error mediante conjuntos de disponibilidad en cada una de las zonas. En este caso, como se describe más adelante en el documento, los grupos de selección de ubicación de proximidad son el pegamento necesario.
- Implemente la carga de trabajo de SAP con conjuntos de disponibilidad. Donde el nivel de base de datos de SAP, el nivel de aplicación de SAP y las máquinas virtuales ASCS/SCS se agrupan en tres conjuntos de disponibilidad diferentes. En tal caso, quiere asegurarse de que los conjuntos de disponibilidad no se distribuyen en toda la región de Azure, ya que esto podría depender de la región de Azure, dar lugar a una latencia de red que podría afectar negativamente a la carga de trabajo de SAP.
- Los grupos de selección de ubicación por proximidad se usan para agrupar máquinas virtuales para lograr una latencia de red más baja posible entre los servicios hospedados en las máquinas virtuales. Por ejemplo, la latencia dentro de una zona de disponibilidad por sí sola no cumple los requisitos de la aplicación.
En cuanto al escenario de implementación n.º 2, en muchas regiones, especialmente regiones sin zonas de disponibilidad y la mayoría de las regiones con zonas de disponibilidad, la latencia de red es independiente de dónde se encuentra la tierra de las máquinas virtuales. Aunque hay algunas regiones de Azure que no pueden proporcionar una experiencia suficientemente buena sin colocar los tres conjuntos de disponibilidad diferentes sin el uso de grupos con ubicación por proximidad.
¿Qué son los grupos de selección de ubicación de proximidad?
Un grupo de selección de ubicación de proximidad de Azure es una construcción lógica. Cuando se define un grupo con ubicación por proximidad, se enlaza a una región de Azure y a un grupo de recursos de Azure. Cuando se implementan VM, las siguientes hacen referencia a un grupo de selección de ubicación de proximidad:
- La primera máquina virtual de Azure implementada en una zona de red con muchas unidades de proceso de Azure y baja latencia de red. Este tipo de zona de red a menudo coincide con un único centro de datos de Azure. Puede pensar en la primera máquina virtual como una "máquina virtual de ámbito" que se implementa en una unidad de escalado de proceso basada en algoritmos de asignación de Azure que finalmente se combinan con parámetros de implementación.
- Todas las máquinas virtuales posteriores implementadas que hacen referencia al grupo con ubicación por proximidad se implementarán en la misma red que la primera máquina virtual.
Nota
Si no hay ningún hardware de host implementado que pueda ejecutar un tipo de máquina virtual específica en el mismo tronco de red en el que se colocó la primera máquina virtual, la implementación del tipo de máquina virtual solicitada no se realizará correctamente. Verá un mensaje de error de asignación que indica que la máquina virtual no se puede admite dentro del perímetro del grupo con ubicación por proximidad.
Para reducir el riesgo de lo anterior, se recomienda usar la opción de intención al crear el grupo de selección de ubicación de proximidad. La opción de intención permite enumerar los tipos de máquina virtual que pretende incluir en el grupo de selección de ubicación de proximidad. Esta lista de tipos de máquina virtual se llevará a cabo para encontrar el mejor centro de datos que hospeda estos tipos de máquina virtual. Si se encuentra este tipo de centro de datos, se creará el PPG y se limitará al centro de datos que cumpla los requisitos de SKU de máquina virtual. Si no se encuentra ningún centro de datos de este tipo, se producirá un error en la creación del grupo de selección de ubicación de proximidad. Puede encontrar más información en la documentación PPG: Uso de la intención para especificar tamaños de máquina virtual. Tenga en cuenta que las situaciones de capacidad reales no se tienen en cuenta en las comprobaciones desencadenadas por la opción de intención. Como resultado, todavía podría haber errores de asignación basados en una capacidad insuficiente disponible.
Un único grupo de recursos de Azure puede tener varios grupos de selección de ubicación de proximidad asignados. Sin embargo, un grupo de selección de ubicación de proximidad solo se puede asignar a un grupo de recursos de Azure.
Para obtener más información e ejemplos de implementación de grupos de selección de ubicación por proximidad, vea la documentación disponible.
Grupos con ubicación por proximidad con implementaciones zonales
Es importante proporcionar una latencia de red razonablemente baja entre el nivel de aplicación de SAP y el nivel de DBMS. En la mayoría de las situaciones, una sola implementación zonal cumple este requisito. En el caso de un conjunto limitado de escenarios, es posible que una sola implementación zonal no cumpla los requisitos de latencia de la aplicación. Estas situaciones requieren la ubicación de la máquina virtual lo más cerca posible y permiten una latencia de red razonablemente baja, se puede definir un grupo de selección de ubicación de proximidad de Azure para este tipo de sistema SAP.
Evite la agrupación de varios sistemas de producción o de no producción de SAP en un único grupo con ubicación por proximidad. Evite las agrupaciones de sistemas SAP porque cuantos más sistemas se agrupen en un grupo con ubicación por proximidad, mayor será la probabilidad de lo siguiente:
- Para que necesite un tipo de máquina virtual que no esté disponible en el tronco de la red en la que se asignó el grupo con ubicación por proximidad.
- Esos recursos de máquinas virtuales no estándar, como las máquinas virtuales de la serie M, podrían acabar sin cumplirse cuando necesite expandir el número de máquinas virtuales en un grupo con ubicación por proximidad con el tiempo.
En función de muchas mejoras implementadas por Microsoft en las regiones de Azure para reducir la latencia de red dentro de una zona de disponibilidad de Azure, la guía de implementación al usar grupos de selección de ubicación de proximidad para implementaciones zonales tiene el siguiente aspecto:
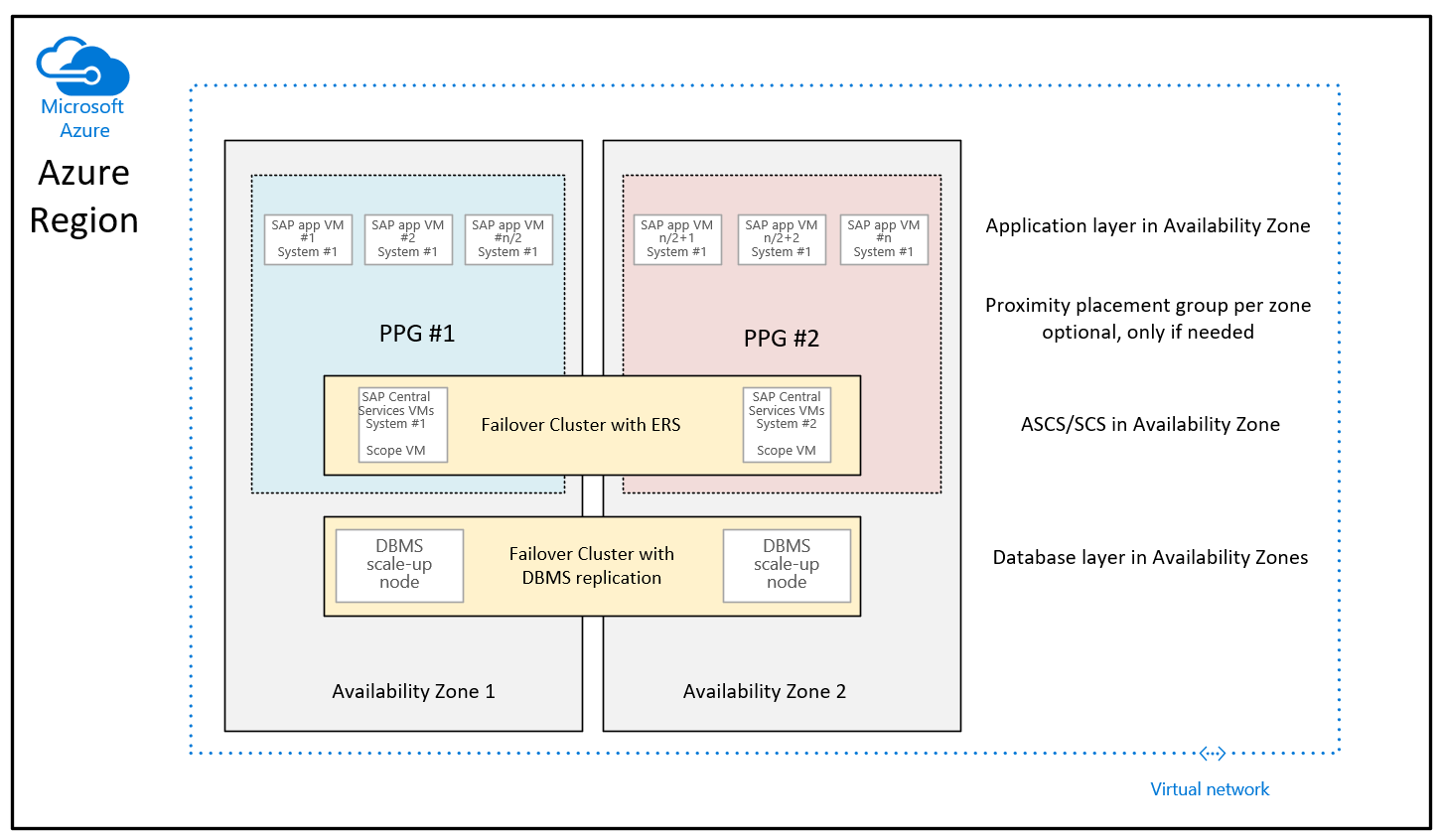
La diferencia con la recomendación dada hasta ahora es que las máquinas virtuales de base de datos de las dos zonas ya no forman parte de los grupos con ubicación por proximidad. Los grupos con ubicación por proximidad por zona ahora están limitados con la implementación de la máquina virtual que ejecuta las instancias de ASCS/SCS de SAP. Esto también significa que para las regiones en las que varios centros de datos recopilan zonas de disponibilidad, la instancia de ASCS/SCS y el nivel de aplicación podría ejecutarse bajo una columna vertebral de red y las máquinas virtuales de base de datos podrían ejecutarse bajo otra columna vertebral de red. Aunque con las mejoras de red realizadas, la latencia de red entre el nivel de aplicación de SAP y el nivel de DBMS todavía debe ser suficiente para un rendimiento y un procesamiento suficientemente buenos. La ventaja de esta nueva configuración es que tiene más flexibilidad para cambiar el tamaño de las máquinas virtuales o cambiar a nuevos tipos de máquina virtual con la capa de DBMS o la capa de aplicación del sistema SAP.
En el caso especial del uso de Azure NetApp Files en el entorno de DBMS y la funcionalidad de Azure NetApp Files relacionada del grupo de volúmenes de aplicación de Azure NetApp Files para SAP HANA y su necesidad de grupos con ubicación por proximidad, consulte el documento Volúmenes de NFS v4.1 en Azure NetApp Files para SAP HANA.
Grupos con ubicación por proximidad con implementaciones de conjuntos de zonas de disponibilidad
En este caso, el propósito es usar grupos con ubicación por proximidad para colocar las máquinas virtuales que se implementan a través de diferentes conjuntos de disponibilidad. En este escenario de uso, no se usa una implementación controlada en distintas zonas de disponibilidad de una región. En su lugar, quiere implementar el sistema SAP mediante conjuntos de disponibilidad. Como resultado, tiene al menos un conjunto de disponibilidad para las máquinas virtuales de DBMS, las máquinas virtuales de ASCS/SCS y las máquinas virtuales de nivel de aplicación. Dado que no se puede especificar en el momento de la implementación de una máquina virtual un conjunto de disponibilidad Y una zona de disponibilidad, no se puede controlar dónde se asignarán las máquinas virtuales de los distintos conjuntos de disponibilidad. Esto podría dar lugar a algunas regiones de Azure en las que la latencia de red entre diferentes máquinas virtuales podría ser demasiado alta para proporcionar una experiencia de rendimiento lo suficientemente buena. Por lo tanto, la arquitectura resultante tendría el siguiente aspecto:
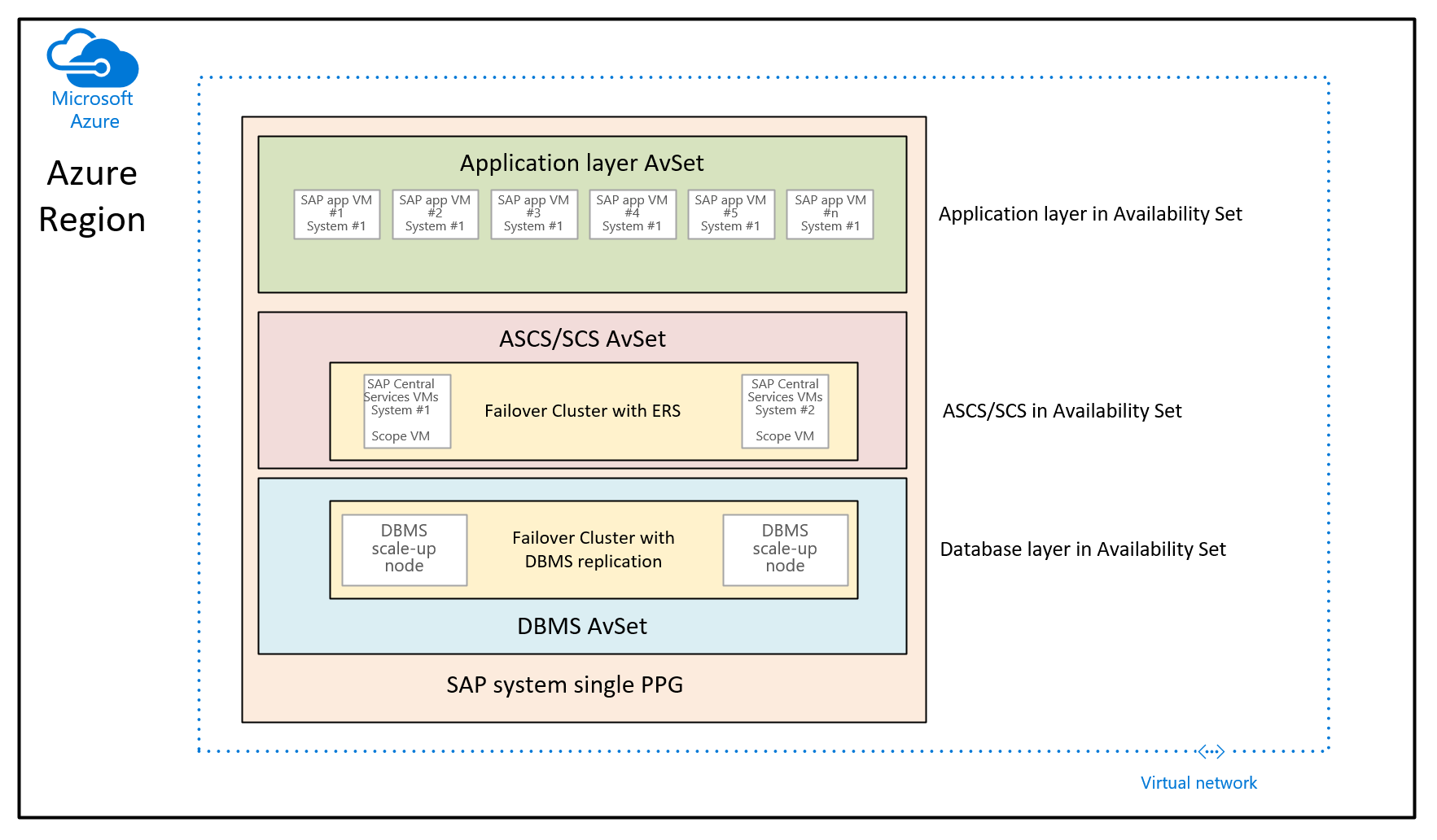
En este gráfico, se asignaría un único grupo con ubicación por proximidad a un único sistema SAP. Este grupo con ubicación por proximidad se asigna a los tres conjuntos de disponibilidad. A continuación, el ámbito del grupo con ubicación por proximidad se establece mediante la implementación de las primeras máquinas virtuales de nivel de base de datos en el conjunto de disponibilidad de DBMS. Esta recomendación de arquitectura coloca todas las máquinas virtuales en el mismo tronco de red. Se presentan las restricciones mencionadas anteriormente en este artículo. Por lo tanto, la arquitectura del grupo con ubicación por proximidad debe usarse con poca frecuencia.
Combinación de conjuntos de disponibilidad y zonas de disponibilidad con grupos de selección de ubicación por proximidad
Uno de los problemas para usar zonas de disponibilidad para implementaciones del sistema SAP es que no se puede implementar el nivel de aplicación de SAP mediante conjuntos de disponibilidad dentro de la zona de disponibilidad específica. Quiere que la capa de aplicación de SAP se implemente en las mismas zonas que las máquinas virtuales ASCS/SCS. La referencia a una zona de disponibilidad y un conjunto de disponibilidad al implementar una sola máquina virtual no es posible hasta ahora. Pero simplemente la implementación de una máquina virtual que indica una zona de disponibilidad, pierde la capacidad de asegurarse de que las máquinas virtuales de capa de aplicación se distribuyen entre diferentes dominios de actualización y error.
Mediante los grupos de selección de ubicación de proximidad, puede evitar esta restricción. A continuación, se muestra la secuencia de implementación:
- Cree un grupo de selección de ubicación de proximidad.
- Para implementar la máquina virtual de anclaje, se recomienda que sea la máquina virtual ASCS/SCS; para ello, haga referencia a una zona de disponibilidad.
- Cree un conjunto de disponibilidad que haga referencia al grupo de selección de ubicación de proximidad de Azure. (Vea el comando más adelante en este artículo).
- Implemente las VM del nivel de aplicación haciendo referencia al conjunto de disponibilidad y al grupo de selección de ubicación de proximidad.
Importante
Es importante comprender que no se garantiza que los discos de las máquinas virtuales de capa de aplicación se asignen en la misma zona de disponibilidad que las máquinas virtuales se dirigen al uso del grupo de selección de ubicación de proximidad. El resultado de la implementación que se muestra en los pasos siguientes puede ser que las máquinas virtuales se asignen en la misma columna vertebral de red y con esa misma zona de disponibilidad que la máquina virtual de anclaje. Pero es posible que los discos respectivos (disco duro virtual base y discos de almacenamiento en bloques de Azure montados) no se asignen en la misma estructura de red o incluso en la misma zona de disponibilidad. En su lugar, los discos de esas máquinas virtuales se pueden asignar en cualquiera de los centros de datos de la región específica. Aunque los discos de la máquina virtual de anclaje que se implementaron mediante la definición de una zona se implementarán en la misma zona en la que la máquina virtual se implementó.
En lugar de implementar la primera máquina virtual como se muestra en la sección anterior, se hace referencia a una zona de disponibilidad y al grupo de selección de ubicación de proximidad al implementar la máquina virtual:
New-AzVm -ResourceGroupName "ppgexercise" -Name "centralserviceszone1" -Location "westus2" -OpenPorts 80,3389 -Zone "1" -ProximityPlacementGroup "collocate" -Size "Standard_E8s_v4"
Una implementación correcta de esta máquina virtual hospedaría la instancia de ASCS/SCS del sistema SAP en una zona de disponibilidad. En este caso, la máquina virtual y el disco duro virtual base de la máquina virtual y los discos de almacenamiento en bloques de Azure potencialmente montados se asignan dentro de la misma zona de disponibilidad. El ámbito del grupo de selección de ubicación de proximidad se fija en una de las columnas de red de la zona de disponibilidad definida.
En el paso siguiente, debe crear los conjuntos de disponibilidad que quiere usar para el nivel de aplicación de su sistema SAP.
Defina y cree el grupo con ubicación por proximidad. El comando para crear el conjunto de disponibilidad requiere una referencia adicional al identificador del grupo de selección de ubicación de proximidad (no al nombre). Puede obtener el identificador del grupo de selección de ubicación de proximidad mediante este comando:
Get-AzProximityPlacementGroup -ResourceGroupName "ppgexercise" -Name "collocate"
Al crear el conjunto de disponibilidad, debe tener en cuenta parámetros adicionales al usar discos administrados (valores predeterminados, a menos que se especifique lo contrario) y grupos de selección de ubicación de proximidad:
New-AzAvailabilitySet -ResourceGroupName "ppgexercise" -Name "ppgavset" -Location "westus2" -ProximityPlacementGroupId "/subscriptions/my very long ppg id string" -sku "aligned" -PlatformUpdateDomainCount 3 -PlatformFaultDomainCount 2
Idealmente, debe utilizar tres dominios de error. Sin embargo, el número de dominios de error admitidos puede variar de una región a otra. En este caso, el número máximo de dominios de error posibles para las regiones específicas es dos. Para implementar las VM del nivel de aplicación, debe agregar una referencia al nombre del conjunto de disponibilidad y el nombre del grupo de selección de ubicación de proximidad, como se muestra aquí:
New-AzVm -ResourceGroupName "ppgexercise" -Name "appinstance1" -Location "westus2" -OpenPorts 80,3389 -AvailabilitySetName "myppgavset" -ProximityPlacementGroup "collocate" -Size "Standard_E16s_v4"
Nota:
Los discos de las máquinas virtuales implementadas en el conjunto de disponibilidad anterior no se ven obligados a asignarse en la misma zona de disponibilidad que la máquina virtual. Aunque ha logrado que las máquinas virtuales de capa de aplicación se repartan entre dominios de error diferentes bajo el mismo tronco de red en el que se asigna la máquina virtual de anclaje, los discos, aunque también se asignan en distintos dominios de error pueden asignarse en diferentes ubicaciones en un ámbito de toda la región.
El resultado de esta implementación es:
- Central Services para el sistema SAP que se encuentra en una zona de disponibilidad específica.
- Una capa de aplicación de SAP que se encuentra a través de conjuntos de disponibilidad en el mismo tronco de red que la máquina virtual o las máquinas virtuales de servicios centrales de SAP (ASCS/SCS).
Nota
Dado que implementa una máquina virtual de DBMS y ASCS/SCS en una zona y una segunda máquina virtual de DBMS y ASCS/SCS en otra zona para crear una configuración de alta disponibilidad, será necesario disponer de grupos con ubicación por proximidad diferentes para cada una de las zonas. Lo mismo se aplica a cualquier conjunto de disponibilidad que use.
Cambio de las configuraciones de grupos con ubicación por proximidad de un sistema existente
Si ha implementado grupos con ubicación por proximidad según las recomendaciones dadas hasta ahora y desea ajustarse a la nueva configuración, puede hacerlo con los métodos descritos en estos artículos:
- Implementación de máquinas virtuales en grupos con ubicación por proximidad con la CLI de Azure.
- Implementación de máquinas virtuales en grupos con ubicación por proximidad con PowerShell.
También puede usar estos comandos para los casos en los que se producen errores de asignación en los casos en los que no se pueda mover a un nuevo tipo de máquina virtual con una máquina virtual existente en el grupo con ubicación por proximidad.
Conjunto de escalado de máquinas virtuales con orquestación flexible
Para evitar las limitaciones asociadas al grupo con ubicación por proximidad, se recomienda implementar la carga de trabajo de SAP en zonas de disponibilidad mediante un conjunto de escalado flexible con FD=1. Esta estrategia de implementación garantiza que las máquinas virtuales implementadas en cada zona no estén restringidas a un único centro de datos o tronco de red, y todos los componentes del sistema SAP, como las bases de datos, ASCS/ERS y la capa de aplicación se limitan dentro de una zona. Con todos los componentes del sistema SAP que se limitan al nivel zonal, la latencia de red entre distintos componentes de un único sistema SAP debe ser suficiente para garantizar un rendimiento y capacidad de procesamiento satisfactorios. La ventaja clave de esta nueva opción de implementación con un conjunto de escalado flexible con FD=1 es que proporciona mayor flexibilidad para cambiar el tamaño de las máquinas virtuales o cambiar a nuevos tipos de máquina virtual para todas las capas del sistema SAP. Además, el conjunto de escalado asignaría máquinas virtuales entre varios dominios de error dentro de una sola zona, lo que es ideal para ejecutar varias máquinas virtuales de la capa de aplicación en cada zona. Para más información, consulte el documento conjunto de escalado de máquinas virtuales para la carga de trabajo de SAP.
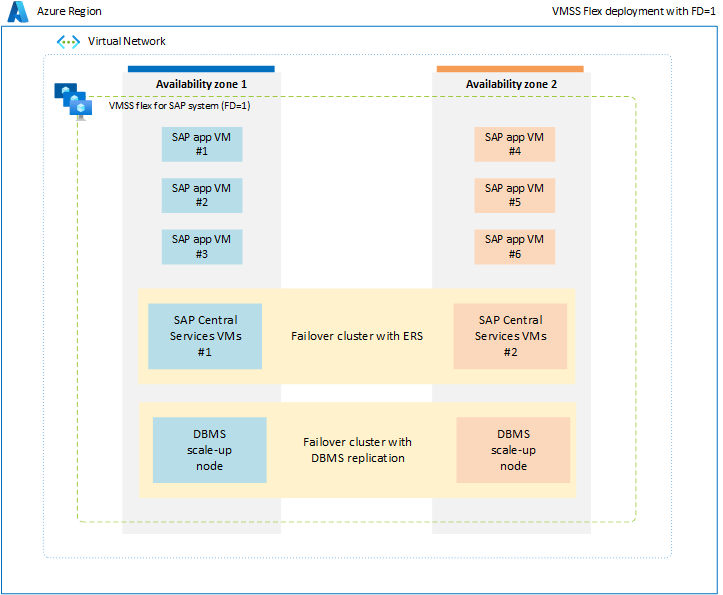
En un entorno que no sea de producción o que no sea de alta disponibilidad, es posible implementar todos los componentes del sistema SAP, incluida la base de datos, ASCS y el nivel de aplicación, dentro de una sola zona mediante un conjunto de escalado flexible con FD=1.
Opciones de implementación recomendadas anteriormente
En esta sección se incluyen detalles sobre las opciones de implementación recomendadas anteriormente para optimizar la latencia de red para SAP. Con las nuevas características y el crecimiento de Azure a lo largo del tiempo, los detalles de esta sección solo se deben aplicar en casos poco frecuentes.
Grupos de selección de ubicación de proximidad para todo el sistema SAP con implementaciones zonales
El uso del grupo de selección de ubicación de proximidad que se recomienda hasta ahora, tiene un aspecto similar al de este gráfico.

Cree un grupo de selección de ubicación de proximidad (PPG) en cada una de las dos zonas de disponibilidad en las que implementó el sistema SAP. Todas las máquinas virtuales de una zona determinada forman parte del grupo con ubicación por proximidad individual de esa zona concreta. Empiece en cada zona con la implementación de la máquina virtual de DBMS para definir el ámbito de PPG y, a continuación, implemente la máquina virtual ASCS en la misma zona y PPG. En un tercer paso, creará un conjunto de disponibilidad de Azure, asignará el conjunto de disponibilidad al PPG con ámbito e implementará el nivel de aplicación de SAP en él. La ventaja de esta configuración fue que todos los componentes están bien alineados debajo de la misma columna vertebral de red. La gran desventaja es que la flexibilidad para cambiar el tamaño de las máquinas virtuales puede ser limitada.
En función de muchas mejoras implementadas por Microsoft en las regiones de Azure para reducir la latencia de red dentro de una zona de disponibilidad de Azure, existe la guía de implementación actual para las implementaciones zonales en este artículo.
Grupos de selección de ubicación de proximidad y HANA (instancias grandes)
Si algunos de los sistemas SAP se basan en Instancias grandes de HANA para la capa de base de datos, puede experimentar mejoras significativas en la latencia de red entre la unidad de instancias grandes de HANA y las máquinas virtuales de Azure cuando se usan unidades de HANA (instancias grandes) que se implementan en filas o sellos de Revisión 4. Una de las mejoras es que cuando se implementan unidades de HANA (instancias grandes), lo hacen con un grupo de selección de ubicación de proximidad. Puede usar ese grupo de selección de ubicación de proximidad para implementar las máquinas virtuales del nivel de aplicación. Como resultado, esas VM se implementarán en el mismo centro de datos que hospeda la unidad de HANA (instancias grandes).
Para determinar si la unidad de HANA (instancias grandes) está implementada en un sello o fila de la revisión 4, consulte el artículo Control de instancias grandes de HANA en Azure mediante Azure Portal. En la información general de los atributos de la unidad de HANA (instancias grandes), también puede determinar el nombre del grupo de selección de ubicación de proximidad porque se creó cuando se implementó la unidad de HANA (instancias grandes). El nombre que aparece en la información general de los atributos es el nombre del grupo de selección de ubicación de proximidad en el que debe implementar las VM del nivel de aplicación.
En comparación con los sistemas SAP que usan solo máquinas virtuales de Azure, cuando se usan instancias grandes de HANA, tiene menos flexibilidad a la hora de decidir el número de grupos de recursos de Azure que se van a usar. Todas las unidades de HANA (instancias grandes) de un inquilino de HANA (instancias grandes) se agrupan en un único grupo de recursos, tal como se describe en este artículo. A menos que realice una implementación en distintos inquilinos para separar, por ejemplo, sistemas de producción y de no producción u otros sistemas, todas las unidades de HANA (instancias grandes) se implementarán en un mismo inquilino de HANA (instancias grandes). Este inquilino tiene una relación uno a uno con un grupo de recursos. Sin embargo, se definirá un grupo de selección de ubicación de proximidad independiente para cada una de las unidades.
Como resultado, las relaciones entre grupos de recursos de Azure y grupos de selección de ubicación de proximidad para un solo inquilino tendrán el siguiente aspecto:

Pasos siguientes
Consulte la documentación:
- Lista de comprobación de planeamiento e implementación de cargas de trabajo de SAP en Azure
- Implementación de máquinas virtuales en grupos de selección de ubicación de proximidad con la CLI de Azure
- Implementación de máquinas virtuales en grupos de selección de ubicación de proximidad con PowerShell
- Consideraciones para la implementación de DBMS de Azure Virtual Machines para la carga de trabajo de SAP