Carga de trabajo de SAP en escenarios admitidos en máquinas virtuales de Azure
El diseño de la arquitectura de los sistemas SAP NetWeaver, Business One, Hybris o S/4HANA en Azure abre muchas oportunidades diferentes para las distintas arquitecturas y herramientas que se pueden usar para obtener una implementación escalable, eficiente y de alta disponibilidad. Aunque depende del sistema operativo o DBMS utilizado, existen restricciones. Además, no todos los escenarios que se admiten de forma local se admiten de la misma manera en Azure. Este documento le guiará a través de las configuraciones admitidas que no son de alta disponibilidad y las configuraciones y arquitecturas de alta disponibilidad que usan máquinas virtuales de Azure de forma exclusiva.
Nota:
El servicio de HANA (instancias grandes) ha llegado a su ocaso y ya no acepta nuevos clientes. Todavía se pueden proporcionar unidades para los clientes existentes de instancias grandes de HANA. Para ver las alternativas, consulte las ofertas de máquinas virtuales de Azure con certificación HANA en el directorio de hardware de HANA. Para ver los escenarios aún admitidos para los clientes existentes de HANA (instancias grandes), consulte el artículo Escenarios admitidos para instancias grandes de HANA.
Restricciones generales de las plataformas
Azure tiene varias plataformas, además de las llamadas máquinas virtuales nativas de Azure, que se ofrecen como servicio de primera entidad. HANA (instancias grandes), en el ocaso de su existencia, es una de esas plataformas. Azure VMware Services es otro de esos servicios de primera entidad. Azure VMware Services no es compatible con SAP en general para hospedar cargas de trabajo de SAP. Consulte la nota de soporte técnico de SAP 2138865 para aplicaciones SAP en VMware Cloud sobre productos y configuraciones de máquina virtual admitidos para obtener más información sobre la compatibilidad con VMware en distintas plataformas.
Además de Active Directory local, Azure ofrece un servicio SaaS administrado de Active Directory con Microsoft Entra Domain Services (AD tradicional administrado por Microsoft) y Microsoft Entra ID. Los componentes de SAP hospedados en el sistema operativo Windows suelen depender del uso de Windows Active Directory. En este caso, la instancia tradicional de Active Directory, ya que está hospedada en el entorno local, o Microsoft Entra Domain Services (todavía en pruebas). Pero estos componentes de SAP no pueden funcionar con el Microsoft Entra ID nativo. El motivo es que todavía hay grandes brechas en la funcionalidad entre Active Directory en su formulario local o su formulario SaaS (Microsoft Entra Domain Services) y el Microsoft Entra ID nativo. Esta dependencia es la razón por la que las cuentas de Microsoft Entra no son compatibles con las aplicaciones basadas en SAP NetWeaver y S/4 HANA en el sistema operativo Windows. En estos escenarios, deben usarse las cuentas tradicionales de Active Directory.
| Servicio de AD | Aplicaciones compatibles basadas en SAP NetWeaver y S/4 HANA en el sistema operativo Windows |
|---|---|
| Windows Active Directory local | Compatible |
| Servicios de dominio de Microsoft Entra | Compatible |
| Microsoft Entra ID | No compatible |
Lo anterior no afecta al uso de cuentas de Microsoft Entra para escenarios de inicio de sesión único (SSO) con aplicaciones SAP.
Configuración de 2 niveles
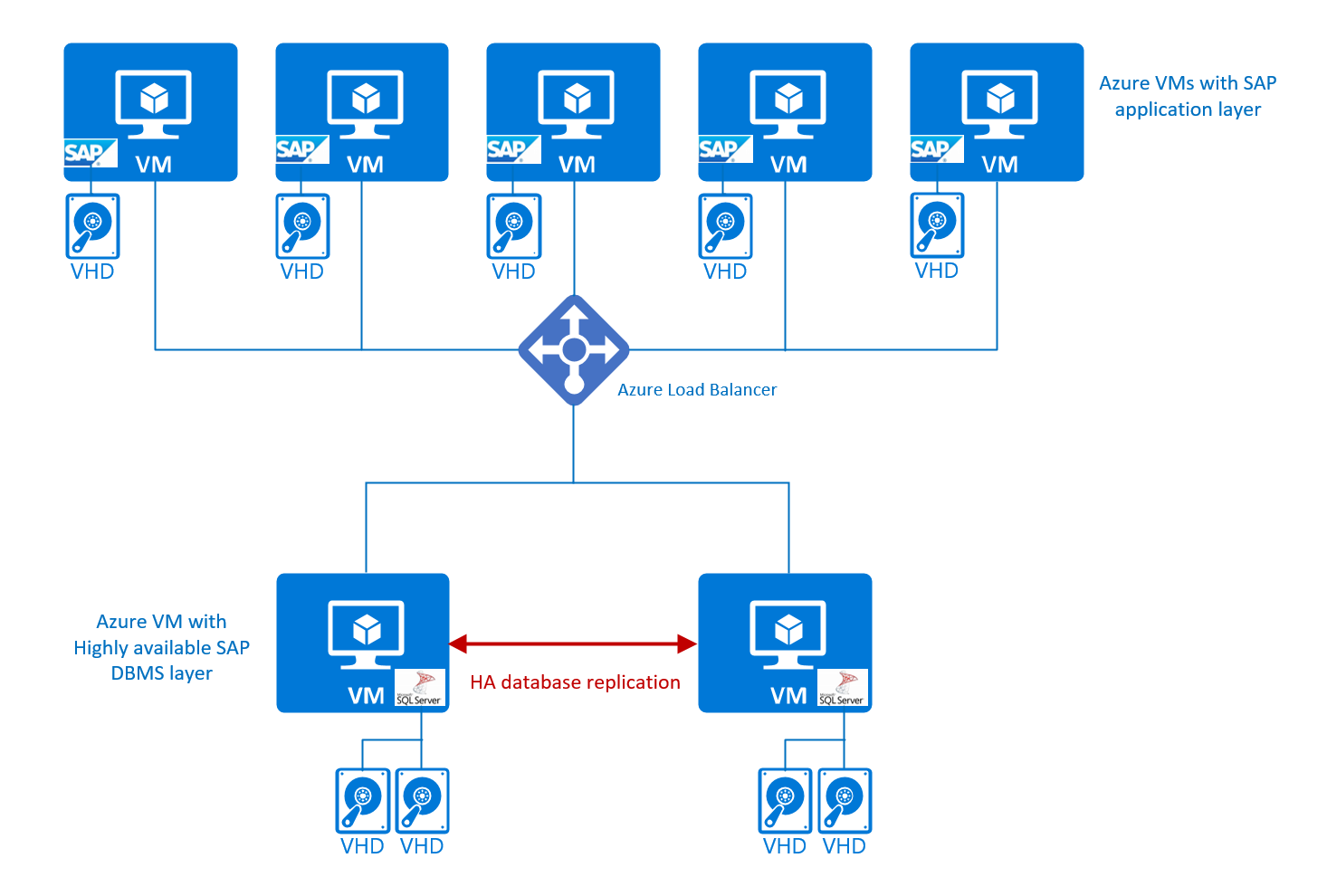
Se considera que una configuración de 2 niveles de SAP se ha creado a partir de una capa combinada del DBMS de SAP y el nivel de aplicación que se ejecuta en el mismo servidor o unidad de máquina virtual. El segundo nivel se considera la capa de la interfaz de usuario. En una configuración de 2 niveles, el DBMS y la capa de la aplicación de SAP comparten los recursos de la máquina virtual de Azure. Como resultado, debe configurar los distintos componentes de forma que no compitan por los recursos. También debe tener cuidado de no sobrescribir los recursos de la máquina virtual. Esta configuración no proporciona ninguna alta disponibilidad, más allá de los Acuerdos de Nivel de Servicio de Azure de los distintos componentes de Azure implicados.
Una representación gráfica de este tipo de configuración puede ser similar a la siguiente:
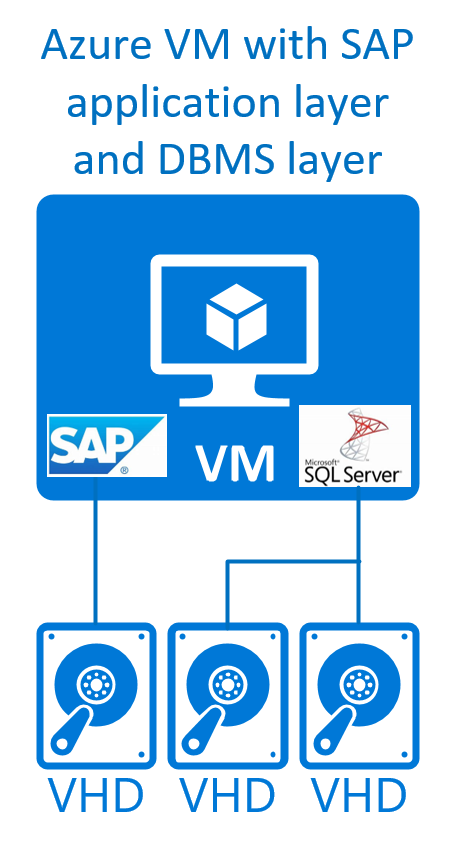
Estas configuraciones se admiten con Windows, Red Hat, SUSE y Oracle Linux para los sistemas DBMS de SQL Server, Oracle, Db2, maxDB y SAP ASE para los casos de producción y de no producción. En SAP HANA como DBMS, SAP admite este escenario, tal como se indica en la Nota de SAP n.º 1953429. Hasta ahora, ninguna de las distribuciones de Linux ha proporcionado suficiente documentación de alta disponibilidad para configurar y operar un clúster de Pacemaker en esta configuración. Como resultado, este tipo de configuraciones solo se admite en Azure para casos que no son de producción y no requieren un clúster de conmutación por error de alta disponibilidad.
Para todas las combinaciones de SO/DBMS compatibles en Azure, se admite este tipo de configuración. Sin embargo, es obligatorio establecer la configuración de los componentes de DBMS y de SAP de forma que no compitan por la memoria y los recursos de CPU y sobrepasen así los recursos físicamente disponibles. Esto se debe hacer restringiendo la memoria que el DBMS puede asignar. También debe limitar la memoria extendida de SAP en las instancias de la aplicación. También debe supervisar el consumo de CPU de la máquina virtual para asegurarse de que los componentes no estén maximizando los recursos de la CPU.
Nota
En el caso de los sistemas SAP de producción, se recomienda una alta disponibilidad adicional y configuraciones de recuperación ante desastres eventuales, como se describe más adelante en este documento.
Configuración de 3 niveles
En estas configuraciones, se separa el nivel de aplicación de SAP y el nivel de DBMS en diferentes máquinas virtuales. Por lo general, esto se hace en sistemas más grandes y sin buscar mayor flexibilidad en los recursos del nivel de aplicación de SAP. En la configuración más sencilla, no hay alta disponibilidad más allá de los Acuerdos de Nivel de Servicio de Azure de los distintos componentes de Azure implicados.
La representación gráfica tiene el siguiente aspecto:
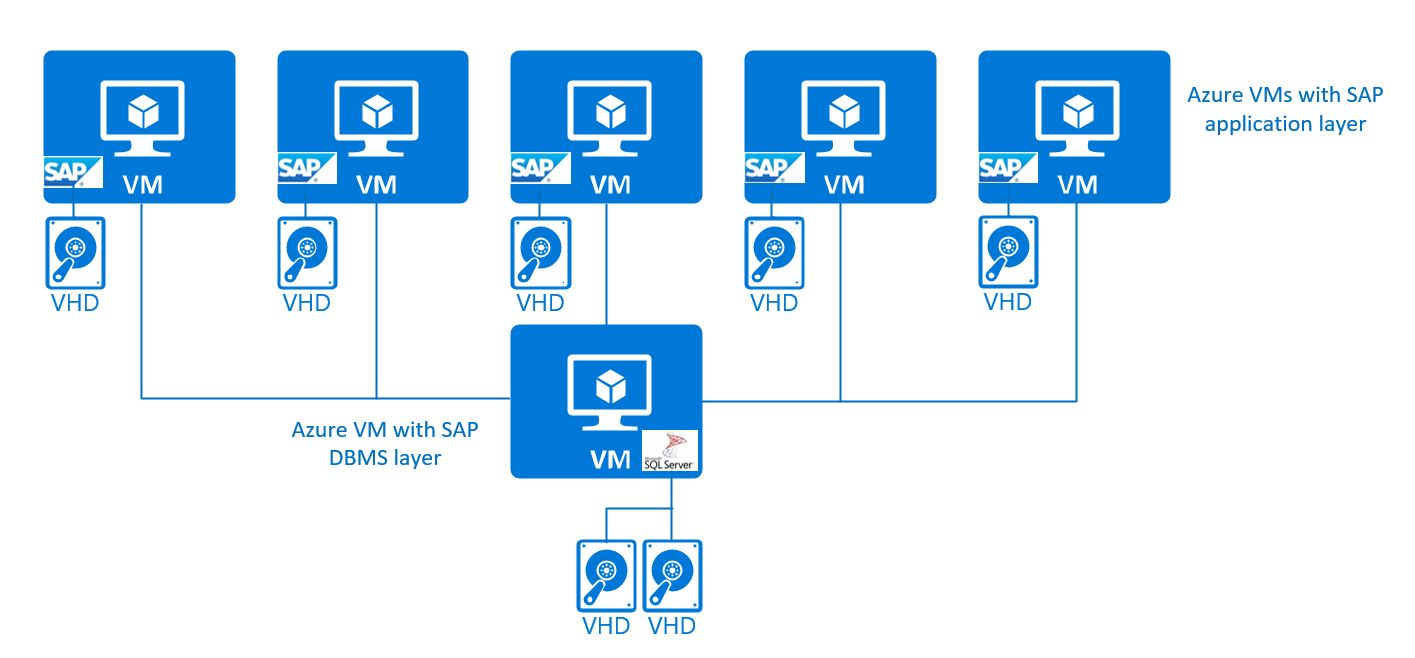
Este tipo de configuración se admite en Windows, Red Hat, SUSE y Oracle Linux para los sistemas DBMS de SQL Server, Oracle, Db2, SAP HANA, maxDB y SAP ASE para los casos de producción y de no producción. Para simplificar, no hemos distinguido entre las instancias de servicios centrales de SAP y las instancias de diálogo de SAP en el nivel de aplicación de SAP. En esta sencilla configuración de 3 niveles, no habría ninguna protección de alta disponibilidad para los servicios centrales de SAP.
Nota
En el caso de los sistemas SAP de producción, se recomienda una alta disponibilidad adicional y configuraciones de recuperación ante desastres eventuales, como se describe más adelante en este documento.
Varias instancias de DBMS por máquina virtual
En este tipo de configuración, se hospedan varias instancias de DBMS por cada máquina virtual de Azure. El motivo puede ser tener menos sistemas operativos que mantener y, con eso, menos costes. Otros motivos son tener más flexibilidad y eficiencia al compartir recursos de una máquina virtual mayor o una unidad de instancia grande de HANA entre varias instancias de DBMS. Hasta ahora, estas configuraciones se mostraban principalmente para sistemas que no son de producción.
Una configuración como esta podría ser similar a la siguiente:
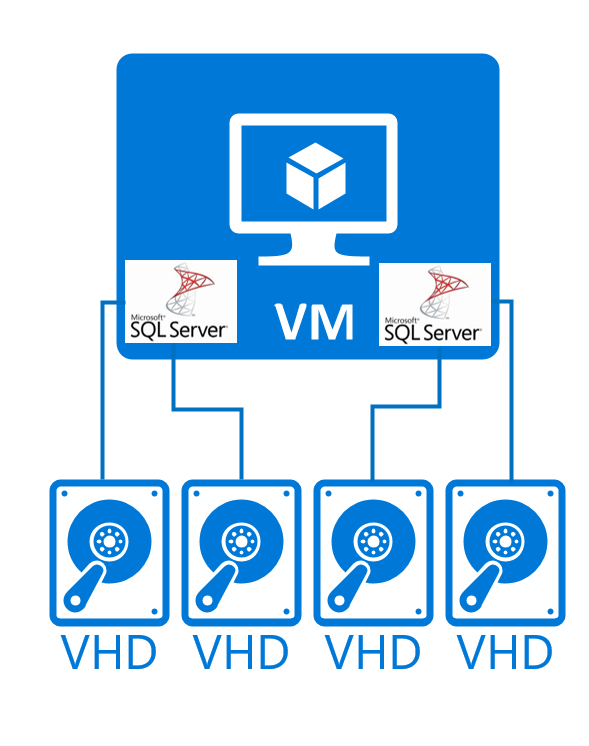
Este tipo de implementación de DBMS es compatible con:
- SQL Server en Windows
- IBM Db2. Encuentre detalles en el artículo Varias instancias (Linux, UNIX)
- Para Oracle. Para obtener más información, consulte la nota de soporte de SAP 1778431 y las notas de SAP relacionadas.
- Para SAP HANA, se admiten varias instancias en una máquina virtual, en un método de implementación que SAP llama MCOS. Para obtener más información, consulte el artículo de SAP Varios sistemas SAP HANA en un host (MCOS).
Al ejecutar varias instancias de base de datos en un host, debe asegurarse de que las distintas instancias no compitan por los recursos y, por tanto, superen los límites de recursos físicos de la máquina virtual. Esto es especialmente pertinente en el caso de la memoria en la que es necesario limitar la memoria que puede asignar cualquiera de las instancias que comparten la máquina virtual. También podría ser pertinente para los recursos de CPU que pueden consumir las distintas instancias de base de datos. Todos los sistemas de base de datos mencionados tienen configuraciones que permiten limitar la asignación de memoria y los recursos de CPU en un nivel de instancia. Para que este tipo de configuración sea compatible con las máquinas virtuales de Azure, se espera que los discos o volúmenes que se usan para los archivos de registro de datos y para registrar o rehacer de las bases de datos administradas por las distintas instancias sean independientes. En otras palabras, se supone que los archivos de registro de datos o para registrar/rehacer de las bases de datos administrados por una instancia de DBMS diferente no deben compartir los mismos discos o volúmenes.
Nota
En el caso de los sistemas SAP de producción, se recomienda una alta disponibilidad adicional y configuraciones de recuperación ante desastres eventuales, como se describe más adelante en este documento. Las máquinas virtuales con varias instancias de DBMS no se admiten con las configuraciones de alta disponibilidad descritas más adelante en este documento.
Varias instancias de diálogo de SAP en una máquina virtual
En muchos casos, se han implementado varias instancias de diálogo en servidores sin sistema operativo o incluso en máquinas virtuales que se ejecutan en nubes privadas. Estas configuraciones buscaban adaptar determinadas instancias de diálogo de SAP a ciertas cargas de trabajo, funcionalidad empresarial o tipos de carga de trabajo. La razón para no aislar esas instancias en máquinas virtuales independientes era el esfuerzo del mantenimiento y las operaciones del sistema operativo. O, en muchos casos, los costos en caso de que el anfitrión o el operador de la máquina virtual solicitasen una cuota mensual por máquina virtual operada y administrada. En Azure, un escenario de hospedaje de varias instancias de diálogo de SAP dentro de una sola máquina virtual es compatible con fines de producción y no producción en los sistemas operativos Windows, Red Hat, SUSE y Oracle Linux. El parámetro kernel de SAP PHYS_MEMSIZE, disponible en los kernel modernos de Linux y Windows, debe establecerse si varias instancias del servidor de aplicaciones de SAP se ejecutan en una sola máquina virtual. También se recomienda limitar la expansión de la memoria extendida de SAP en sistemas operativos, como Windows, donde se implementa el crecimiento automático de la memoria extendida de SAP. Esto puede hacerse con el parámetro de perfil predeterminado em/max_size_MB.
Una configuración de 3 niveles en la que varias instancias de diálogo de SAP se ejecutan en máquinas virtuales de Azure puede tener el aspecto siguiente:
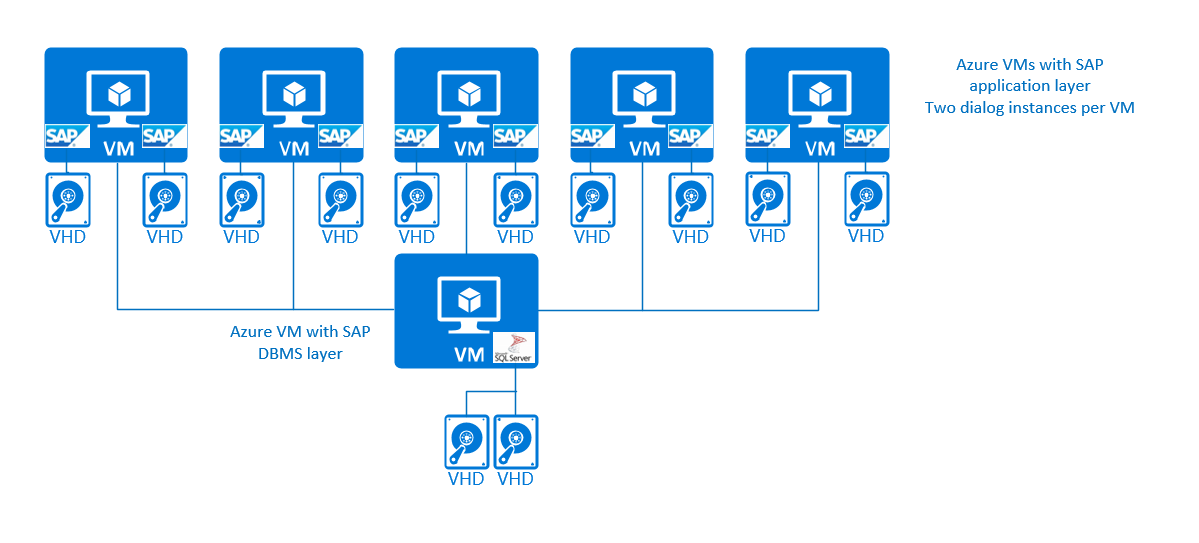
Para simplificar, no hemos distinguido entre las instancias de servicios centrales de SAP y las instancias de diálogo de SAP en el nivel de aplicación de SAP. En esta sencilla configuración de 3 niveles, no habría ninguna protección de alta disponibilidad para los servicios centrales de SAP. En el caso de los sistemas de producción, no se recomienda dejar los servicios centrales de SAP desprotegidos. Para obtener información específica sobre las llamadas configuraciones de varios SID en torno a las instancias centrales de SAP y la alta disponibilidad de dichas configuraciones de varios SID, consulte secciones posteriores de este documento.
Protección de alta disponibilidad para el nivel de DBMS de SAP
A medida que implementa sistemas de producción de SAP, debe considerar el tipo en espera activa de configuraciones de alta disponibilidad. Especialmente con SAP HANA, donde los datos deben cargarse en memoria antes de poder obtener el máximo rendimiento y escalabilidad, la recuperación del servicio de Azure no es una medida ideal para lograr una alta disponibilidad.
En general, Microsoft solo admite configuraciones de alta disponibilidad y paquetes de software que se describen en los escenarios de carga de trabajo de SAP. Puede leer la misma declaración en la nota de SAP 1928533. Microsoft no proporcionará soporte técnico para otras plataformas de software de terceros de alta disponibilidad que no estén documentadas por Microsoft con la carga de trabajo de SAP. En tales casos, el proveedor de terceros del marco de alta disponibilidad es la parte auxiliar para la configuración de alta disponibilidad, que debe ser contratada por usted como cliente en el proceso de soporte técnico. En este artículo se van a mencionar excepciones.
En general, Microsoft admite un conjunto limitado de configuraciones de alta disponibilidad en máquinas virtuales de Azure o unidades de HANA (instancias grandes).
En el caso de las máquinas virtuales de Azure, se admiten las siguientes configuraciones de alta disponibilidad en el nivel de DBMS:
- Replicación del sistema SAP HANA basada en Linux Pacemaker en SUSE y Red Hat. Vea los artículos detallados:
- Configuraciones de n+m de escalado horizontal de SAP HANA mediante Azure NetApp Files en SUSE y Red Hat. Los detalles aparecen en estos artículos:
- Implementación de un sistema de escalabilidad horizontal de SAP HANA con nodo en espera en VM de Azure mediante Azure NetApp Files en SUSE Linux Enterprise Server
- Implementación de un sistema de escalabilidad horizontal de SAP HANA con nodo en espera en VM de Azure mediante Azure NetApp Files en Red Hat Enterprise Linux
- Clúster de conmutación por error de SQL Server basado en servicios de archivos de escalabilidad horizontal de Windows. No obstante, la recomendación de los sistemas de producción es usar SQL Server Always On en lugar de la agrupación en clústeres. SQL Server Always On proporciona una mejor disponibilidad mediante almacenamiento independiente. Los detalles se describen en este artículo:
- SQL Server Always On es compatible con el sistema operativo Windows para SQL Server en Azure. Esta es la configuración que se recomienda de forma predeterminada para las instancias de SQL Server de producción en Azure. Los detalles aparecen en estos artículos:
- Oracle Data Guard para Windows y Oracle Linux. Puede encontrar más información sobre Oracle Linux en este artículo:
- Aquí se proporciona la documentación detallada de IBM Db2 HADR en SUSE y RHEL para SUSE y RHEL mediante Pacemaker:
- La configuración de SAP ASE y SAP maxDB tal y como se detalla en estos documentos:
- Los escenarios de alta disponibilidad de instancias grandes de HANA se detallan en:
Importante
Para ninguno de los escenarios descritos anteriormente se admiten configuraciones de varias instancias de DBMS en una máquina virtual. Esto significa que, en cada uno de los casos, solo se puede implementar una instancia de base de datos por máquina virtual y protegerse con los métodos de alta disponibilidad descritos. La protección de varias instancias de DBMS en el mismo clúster de conmutación por error de Windows o Pacemaker NO se admite en este momento. También se admite Oracle Data Guard para casos de implementación de instancia única por máquina virtual.
Varios sistemas de base de datos permiten hospedar varias bases de datos en una instancia de DBMS. Al igual que para SAP HANA, se pueden hospedar varias bases de datos en varios contenedores de base de datos (MDC). En los casos en los que estas configuraciones de varias bases de datos funcionan en un recurso de clúster de conmutación por error, se admiten estas configuraciones. Las configuraciones que no se admiten son casos en los que se necesitarían varios recursos de clúster. En el caso de las configuraciones en las que se definirían varios grupos de disponibilidad de SQL Server, en una instancia de SQL Server.
En función de los sistemas operativos o de DBMS, es posible que componentes como Azure Load Balancer no sean necesarios como parte de la arquitectura de la solución.
Específicamente para maxDB, la configuración de almacenamiento debe ser diferente. Con maxDB, los archivos de datos y registro deben encontrarse en el almacenamiento compartido para las configuraciones de alta disponibilidad. Solo en el caso de maxDB se admite el almacenamiento compartido para lograr una alta disponibilidad. Para todos los demás DBMS, las pilas de almacenamiento independientes por nodo son las únicas configuraciones de disco compatibles.
Se sabe que existen otros marcos de alta disponibilidad y se sabe que se ejecutan también en Microsoft Azure. Sin embargo, Microsoft no ha probado estos marcos. Si desea compilar la configuración de alta disponibilidad con estas plataformas, debe trabajar con el proveedor de ese software en materia de:
- Desarrollo de una arquitectura de implementación
- Implementación de la arquitectura
- Compatibilidad de la arquitectura
Importante
Microsoft Azure Marketplace ofrece una variedad de dispositivos de software que proporcionan soluciones de almacenamiento sobre el almacenamiento nativo de Azure. Estos dispositivos flexibles se pueden usar para crear recursos compartidos de NFS y, en teoría, podrían usarse en las implementaciones escaladas de SAP HANA en las que se requiere un nodo en espera. Debido a varios motivos, ninguno de estos dispositivos de software de almacenamiento es compatible con ninguna de las implementaciones de DBMS de Microsoft y SAP en Azure. En este momento no se admiten implementaciones de DBMS en recursos compartidos de SMB. Las implementaciones de DBMS en los recursos compartidos de NFS se limitan a recursos compartidos de NFS 4.1 en Azure NetApp Files.
Alta disponibilidad para los servicios centrales de SAP
Los servicios centrales de SAP representan un segundo único punto de error de la configuración de SAP. Como resultado, también necesitará proteger estos procesos de servicios centrales. La oferta compatible y documentada para cargas de trabajo de SAP es esta:
- Servidor de clústeres de conmutación por error de Windows con servicios de archivos de escalabilidad horizontal de Windows para sapmnt y directorio de transporte global. Los detalles se describen en este artículo:
- Agrupación de una instancia de ASCS/SCS de SAP en un clúster de conmutación por error de Windows con un recurso compartido de archivos en Azure
- Preparación de la infraestructura de Azure para la alta disponibilidad de SAP con un clúster de conmutación por error de Windows y el recurso compartido de archivos para instancias de SAP ASCS/SCS
- Servidor de clústeres de conmutación por error de Windows con recurso compartido de archivos de SMB basado en Azure NetApp Files para sapmnt y directorio de transporte global. Los detalles aparecen en este artículo:
- Servidor de clústeres de conmutación por error de Windows basado en SIOS
Datakeeper. Aunque está documentado por Microsoft, necesita una relación de soporte técnico con SIOS, por lo que puede interactuar con el soporte técnico de SIOS al usar esta solución. Los detalles se describen en este artículo:- Agrupación de una instancia de ASCS/SCS de SAP en un clúster de conmutación por error de Windows con un disco compartido de clúster en Azure
- Preparación de la infraestructura de Azure para alta disponibilidad de SAP con un clúster de conmutación por error de Windows y un disco compartido para ASCS/SCS de SAP
- Pacemaker en el sistema operativo SUSE con la creación de un recurso compartido de archivos de NFS de alta disponibilidad con dos máquinas virtuales de SUSE y
drdbpara la replicación de archivos. Los detalles están documentados en el artículo. - Sistema operativo SUSE en Pacemaker con el uso de recursos compartidos de archivos de NFS proporcionados por Azure NetApp Files. Los detalles están documentados en
- Pacemaker en el sistema operativo Red Hat con recurso compartido de archivos de NFS hospedado en un clúster de
glusterfs. Se puede encontrar más detalles en los artículos siguientes: - Pacemaker en el sistema operativo Red Hat con recurso compartido de archivos NFS hospedado en Azure NetApp Files. Los detalles se describen en este artículo:
De las soluciones enumeradas, necesita una relación de soporte técnico con SIOS para admitir el producto Datakeeper y para interactuar con SIOS directamente en caso de detectar problemas. En función de la licencia de Windows, Red Hat o sistema operativo SUSE, también podría ser necesario tener un contrato de soporte técnico con el proveedor del sistema operativo para plena compatibilidad con las configuraciones de alta disponibilidad enumeradas.
La configuración también se puede mostrar como:
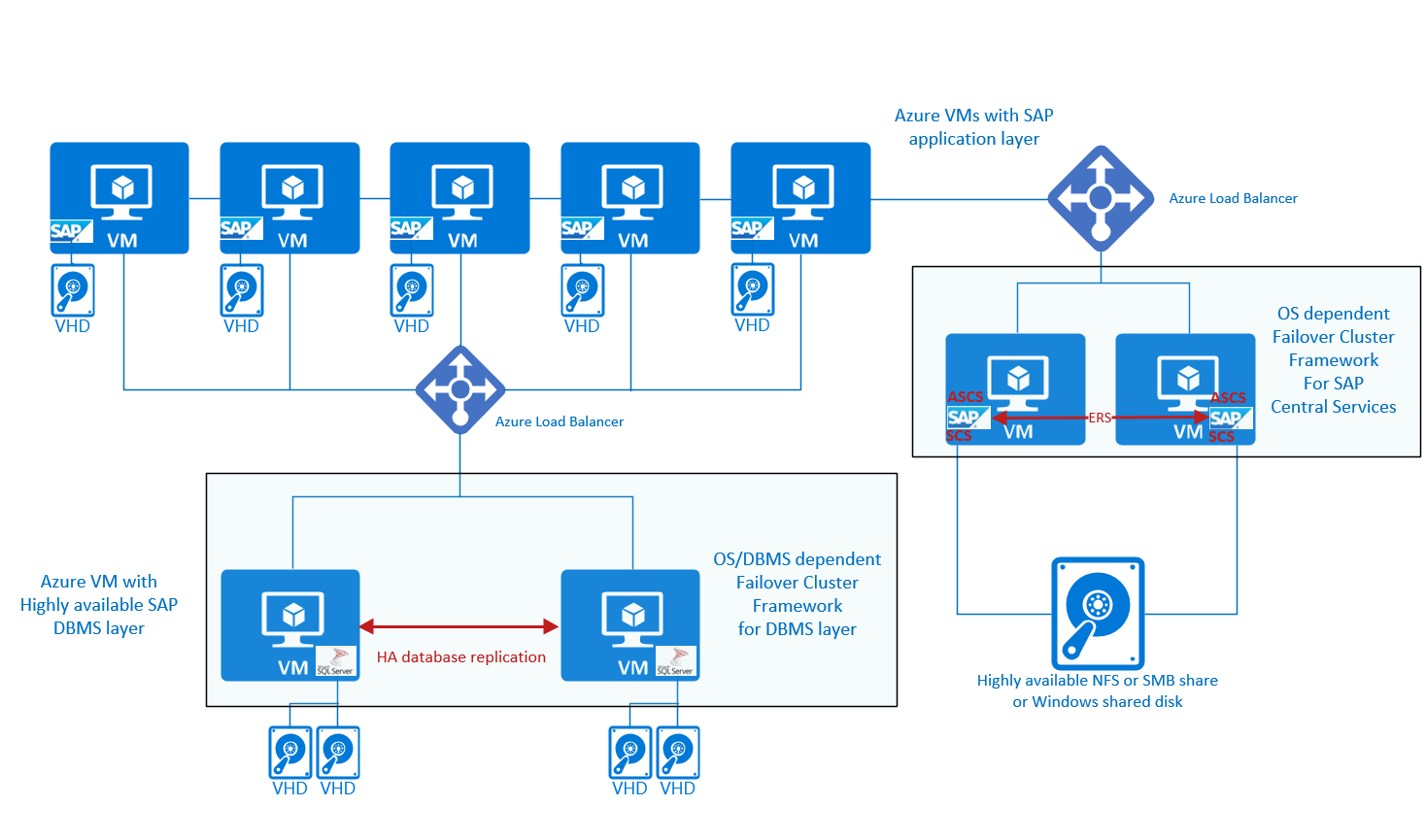
En el lado derecho de los gráficos, se muestran los servicios centrales de SAP de alta disponibilidad. Además de tener los servicios centrales de SAP protegidos con una plataforma de clúster de conmutación por error que puede conmutar por error en escenarios de error, es necesario tener un recurso compartido de archivos de NFS o SMB de alta disponibilidad o un disco compartido de Windows para asegurarse de que el directorio de transporte global y sapmnt estén disponibles independientemente de la existencia de una sola máquina virtual. Asimismo, algunas de las soluciones, como el servidor de clústeres de conmutación por error de Windows y Pacemaker, van a requerir que una instancia de Azure Load Balancer dirija o redirija el tráfico a un nodo en buen estado.
En la lista que se muestra, no hay ninguna mención al sistema operativo Oracle Linux. Oracle Linux no admite Pacemaker como marco de clústeres. Si desea implementar el sistema SAP en Oracle Linux y necesita un marco de alta disponibilidad para Oracle Linux, debe trabajar con proveedores de terceros. Uno de los proveedores es SIOS con su conjunto de protección para Linux compatible con SAP en Azure. Para más información, lea la nota de SAP 1662610 - Detalles de compatibilidad del conjunto de protección de SIOS para Linux para obtener más detalles.
Almacenamiento compatible con los escenarios de servicios centrales de SAP enumerados anteriormente
Dado que solo un subconjunto de tipos de almacenamiento de Azure proporciona recursos compartidos de archivos de NFS o SMB de alta disponibilidad para el uso en nuestros escenarios de clúster de SAP Central Services, se muestra una lista de tipos de almacenamiento admitidos.
- El servidor de clústeres de conmutación por error de Windows con el servidor de archivos de escalabilidad horizontal de Windows se puede implementar en todos los tipos de almacenamiento nativos de Azure, excepto Azure NetApp Files. Sin embargo, se recomienda usar Premium Storage debido a acuerdos de nivel de servicio superiores en cuanto a rendimiento e IOPS.
- El servidor de clústeres de conmutación por error de Windows con SMB en Azure NetApp Files se admite en Azure NetApp Files. En este escenario también se admiten los recursos compartidos de SMB hospedados en los servicios de Azure Premium Files. No se admite Azure Standard Files
- El servidor de clústeres de conmutación por error de Windows con un disco compartido de Windows basado en SIOS
Datakeeperse puede implementar en todos los tipos de almacenamiento nativos de Azure, excepto Azure NetApp Files. Sin embargo, se recomienda usar Premium Storage debido a acuerdos de nivel de servicio superiores en cuanto a rendimiento e IOPS. - Se admite SUSE o Red Hat Pacemaker con recursos compartidos de NFS en Azure NetApp Files.
- Se admite SUSE o Red Hat Pacemaker con recursos compartidos de NFS en Azure Premium Files con LRS o ZRS. No se admite Azure Standard Files
- SUSE Pacemaker con una configuración de
drdbentre dos máquinas virtuales es compatible con los tipos de almacenamiento nativos de Azure, excepto Azure NetApp Files. Sin embargo, se recomienda usar uno de los servicios de primera entidad con Azure Premium Files o Azure NetApp Files. - Red Hat Pacemaker con
glusterfspara proporcionar un recurso compartido de archivos de NFS es compatible con los tipos de almacenamiento nativos de Azure, excepto Azure NetApp Files. Sin embargo, se recomienda usar uno de los servicios de primera entidad con Azure Premium Files o Azure NetApp Files.
Importante
Microsoft Azure Marketplace ofrece una variedad de dispositivos de software que proporcionan soluciones de almacenamiento sobre el almacenamiento nativo de Azure. Estos dispositivos de software de almacenamiento se pueden usar para crear también recursos compartidos de archivos de NFS o SMB que, teóricamente, podrían usarse en los servicios centrales de SAP en clúster de conmutación por error. Microsoft no admite directamente estas soluciones para la carga de trabajo de SAP. Si decide usar una solución de este tipo para crear el recurso compartido de archivos de NFS o SMB, la compatibilidad con la configuración del servicio central de SAP debe proporcionarla el software de terceros que posee el software en el dispositivo de software de almacenamiento.
Clústeres de conmutación por error de servicios centrales de SAP con varios SID
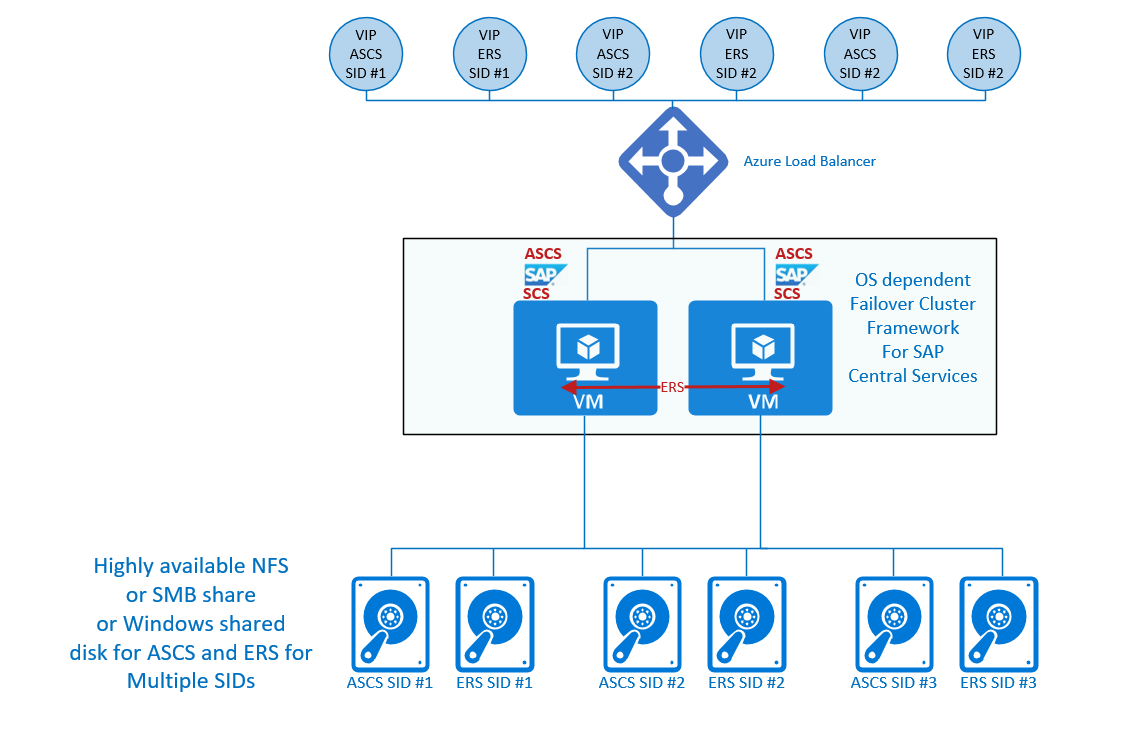
Para reducir el número de máquinas virtuales que se necesitan en entornos SAP de gran tamaño, SAP permite ejecutar instancias de SAP Central Services de varios sistemas SAP diferentes en la configuración del clúster de conmutación por error. Imagine casos en los que tenga 30 o más sistemas de producción de NetWeaver o S/4HANA. Sin la agrupación en clústeres de varios SID, estas configuraciones requerirían 60 o más máquinas virtuales en 30 o más configuraciones de clúster de conmutación por error de Windows o Pacemaker. La implementación de varios servicios centrales de SAP en dos nodos en una configuración de clúster de conmutación por error puede reducir considerablemente el número de máquinas virtuales. Sin embargo, la implementación de varias instancias de servicios centrales de SAP en una sola configuración de clúster de dos nodos también tiene algunas desventajas. Los problemas relacionados con una sola máquina virtual en la configuración del clúster ocurren en varios sistemas SAP. El mantenimiento en el sistema operativo invitado que se ejecuta en la configuración del clúster requiere más coordinación, ya que se ven afectados varios sistemas SAP de producción. Herramientas como SAP LaMa no admiten la agrupación en clústeres de varios SID en el proceso de clonación del sistema.
En Azure, se admite una configuración de clúster de varios SID para el sistema operativo Windows con ENSA1 y ENSA2. La recomendación es no combinar la antigua arquitectura del servicio de replicación en cola (ENSA1) con la nueva arquitectura (ENSA2) en un clúster de varios SID. Los detalles sobre esta arquitectura se documentan en los artículos siguientes:
- Alta disponibilidad con varios identificadores de seguridad de instancia de ASCS/SCS de SAP para los clústeres de conmutación por error de Windows Server y el disco compartido en Azure
- Alta disponibilidad con varios identificadores de seguridad de instancia SAP ASCS/SCS para los clústeres de conmutación por error de Windows Server y los recursos compartidos de archivos en Azure
Para SUSE, también se admite un clúster de varios SID basado en Pacemaker. Hasta ahora, la configuración es compatible con:
- Un máximo de cinco instancias de ASCS/SCS de SAP
- La arquitectura de ICE del antiguo servidor de replicación en cola (ENSA1)
- Configuraciones de clúster de Pacemaker de dos nodos
La configuración se documenta en Alta disponibilidad para SAP NetWeaver en máquinas virtuales de Azure en SUSE Linux Enterprise Server para SAP Applications: guía de varios SID.
Un clúster de varios SID con el servidor de replicación en cola tiene esquemáticamente un aspecto como el siguiente:
Escenarios de escalabilidad horizontal de SAP HANA
Los escenarios de escalado horizontal de SAP HANA se admiten para un subconjunto de máquinas virtuales de Azure con certificación de HANA, tal como se muestra en el directorio de hardware de SAP HANA. Todas las máquinas virtuales marcadas con "Sí" en la columna "Agrupación en clústeres" se pueden usar para el escalado horizontal de OLAP o S/4HANA. Las configuraciones sin modo de espera se admiten con los tipos Azure Storage siguientes:
- Azure Premium Storage v1, que incluye el acelerador de escritura de Azure para el volumen /hana/log
- Azure Premium Storage v2
- Disco Ultra
- Azure NetApp Files
Las configuraciones de escalado horizontal de SAP HANA para OLAP o S/4HANA con nodos en espera se admiten exclusivamente con NFS compartido hospedado en Azure NetApp Files.
Para obtener más información sobre las configuraciones de almacenamiento exactas con o sin nodo en espera, consulte los artículos:
- Configuraciones de almacenamiento de máquinas virtuales de Azure en SAP HANA
- Implementación de un sistema de escalabilidad horizontal de SAP HANA con nodo en espera en VM de Azure mediante Azure NetApp Files en SUSE Linux Enterprise Server
- Implementación de un sistema de escalabilidad horizontal de SAP HANA con nodo en espera en VM de Azure mediante Azure NetApp Files en Red Hat Enterprise Linux
- Nota de soporte técnico de SAP 2080991
Escenario de recuperación ante desastres
Se admiten diferentes escenarios de recuperación ante desastres. Definimos las arquitecturas de desastres como aquellas arquitecturas que deberían compensar la región de Azure completa que se queda desconectada. Esto significa que necesitamos que el destino de recuperación ante desastres sea una región de Azure diferente para ejecutar el entorno de SAP. Separamos métodos y configuraciones en nivel de DBMS y nivel que no es de DBMS.
Nivel de DBMS
En el nivel de DBMS, se admiten las configuraciones que usan mecanismos de replicación nativa de DBMS, como Always On, Oracle Data Guard, DB2 HADR, SAP ASE Always-On o la replicación del sistema de HANA. Es obligatorio que la secuencia de replicación en estos casos sea asincrónica, en lugar de sincrónica como en los típicos escenarios de alta disponibilidad que se implementan dentro de una única región de Azure. Se describe un ejemplo habitual de una configuración de recuperación ante desastres de DBMS compatible en el artículo Disponibilidad de SAP HANA entre regiones de Azure. En el segundo gráfico de esa sección se describe un escenario con HANA como ejemplo. Las bases de datos principales compatibles con las aplicaciones de SAP se pueden implementar en este tipo de escenario.
Se admite el uso de una máquina virtual más pequeña como instancia de destino en la región de recuperación ante desastres, ya que la máquina virtual no experimenta todo el tráfico de la carga de trabajo. Al hacerlo, tenga en cuenta las siguientes consideraciones:
- Los tipos de máquina virtual más pequeños no permiten muchos discos conectados a máquinas virtuales más pequeñas.
- Las máquinas virtuales más pequeñas tienen menos rendimiento de red y almacenamiento.
- Cambiar el tamaño de las familias de máquinas virtuales puede suponer un problema cuando se recopilan las diferentes máquinas virtuales en un conjunto de disponibilidad de Azure o cuando el cambio de tamaño se produce entre la familia de la serie M y la familia de máquinas virtuales Mv2.
- Consumo de CPU y memoria para que la instancia de base de datos pueda recibir el flujo de cambios con un retraso mínimo y suficientes recursos de CPU y memoria para aplicar estos cambios con un retraso mínimo a los datos.
Puede encontrar más detalles sobre las limitaciones de diferentes tamaños de máquina virtual en la página de tamaños de máquina virtual.
Otro método admitido para implementar un destino de recuperación ante desastres es tener una segunda instancia de DBMS instalada en una máquina virtual que ejecute una instancia de DBMS que no sea de producción de una instancia de SAP que no sea de producción. Esto puede ser un poco más complicado, ya que es necesario averiguar qué memoria, recursos de CPU, ancho de banda de red y ancho de banda de almacenamiento son necesarios para las instancias de destino concretas que deberían funcionar como instancia principal en el escenario de recuperación ante desastres. Especialmente en HANA, se recomienda encarecidamente que configure la instancia que funciona como destino de recuperación ante desastres en un host compartido, de modo que los datos no se carguen previamente en la instancia de destino de recuperación ante desastres.
Nota
No se ha probado el uso de Azure Site Recovery para las implementaciones de DBMS en la carga de trabajo de SAP. Como resultado, no se admite para el nivel de DBMS de los sistemas SAP en este momento. No se admiten otros métodos de replicación de Microsoft y SAP que no aparecen en la lista. El uso de software de terceros para replicar el nivel de DBMS de sistemas SAP entre diferentes regiones de Azure debe ser compatible con el proveedor del software y no se admitirá a través de los canales de soporte técnico de Microsoft y SAP.
Nivel que no es de DBMS
Para la capa de la aplicación de SAP y los eventuales recursos compartidos de archivos o ubicaciones de almacenamiento necesarios, los clientes utilizan los dos escenarios principales:
- Los destinos de recuperación ante desastres de la segunda región de Azure no se usan para fines de producción o de no producción. En este escenario, las máquinas virtuales que funcionan como destino de recuperación ante desastres no se implementan idealmente, y la imagen y los cambios en las imágenes del nivel de aplicación de SAP de producción se replican en la región de recuperación ante desastres. Una funcionalidad que puede realizar esta tarea es Azure Site Recovery. Azure Site Recovery admite un escenario de replicación de Azure a Azure como este.
- Los destinos de recuperación ante desastres son máquinas virtuales que en realidad están en uso por sistemas que no son de producción. Todo el panorama de SAP se distribuye entre dos regiones diferentes de Azure con sistemas de producción normalmente en una región y sistemas que no son de producción en otra región. En muchas implementaciones de clientes, este tiene un sistema que no es de producción pero es equivalente a él. El cliente tiene instaladas las instancias de la aplicación de producción previamente en los sistemas que no son de producción. En caso de una conmutación por error, se apagarían las instancias que no son de producción, los nombres virtuales de las máquinas virtuales de producción se moverían a las máquinas virtuales que no son de producción (después de asignar nuevas direcciones IP en DNS) y se iniciarían las instancias de producción preinstaladas.
Clústeres de servicios centrales de SAP
Los clústeres de servicios centrales de SAP que usan discos compartidos (Windows), recursos compartidos de archivos de SMB (Windows) o recursos compartidos de archivos de NFS son un poco más difíciles de replicar. En el lado de Windows, la replicación de almacenamiento de Windows es una posible solución. En Linux, rsync es una solución viable. También la replicación entre regiones de Azure NetApp Files es una solución viable.
Escenario no admitido
Hay una lista de escenarios que no se admiten para la carga de trabajo de SAP en arquitecturas de Azure. No admitido significa que SAP y Microsoft no admiten estas configuraciones y necesitan pasarlas a eventuales terceros participantes que proporcionen software para establecer este tipo de arquitecturas. Dos de las categorías son:
- Dispositivos de software de almacenamiento: existen varios dispositivos de almacenamiento de software en el mercado. Algunos de los proveedores ofrecen documentación propia sobre cómo usar estos dispositivos de software de almacenamiento en Azure en relación con el software de SAP. El proveedor de los dispositivos de software de almacenamiento debe proporcionar compatibilidad para las configuraciones o implementaciones que afecten a estos dispositivo de software de almacenamiento. Este hecho también se manifiesta en la nota de soporte de SAP 2015553
- Marcos de alta disponibilidad: Solo los clústeres de conmutación por error de Windows Server y Pacemaker son marcos de alta disponibilidad admitidos para la carga de trabajo de SAP en Azure. Como se mencionó anteriormente, Microsoft describe y documenta la solución de SIOS
Datakeeper. No obstante, los componentes de SIOSDatakeeperdeben ser compatibles con SIOS como proveedor que proporciona esos componentes. SAP también enumera otros marcos de alta disponibilidad certificados en varias notas de SAP. Algunos de ellos también están certificados por el proveedor de terceros de Azure. No obstante, el proveedor del producto debe proporcionar soporte técnico para las configuraciones que usan estos productos. Los distintos proveedores tienen una integración diferente en los procesos de compatibilidad de SAP. Debe aclarar qué proceso de soporte técnico funciona mejor para el proveedor en particular antes de decidirse a usar el producto con las configuraciones de SAP implementadas en Azure. - Los clústeres de discos compartidos, en los que residen los archivos de base de datos en los discos compartidos, no son compatibles, excepto para maxDB. Para todas las demás bases de datos, la solución admitida es tener ubicaciones de almacenamiento independientes en lugar de un recurso compartido de archivos de SMB o NFS o un disco compartido para configurar escenarios de alta disponibilidad.
Otros escenarios no compatibles son, por ejemplo, los siguientes:
- Escenarios de implementación que introducen una mayor latencia de red entre el nivel de aplicación de SAP y el nivel de DBMS de SAP, como en NetWeaver, S/4 HANA y, por ejemplo,
Hybris. Esto incluye:- Implementación de uno de los niveles locales, mientras el otro nivel se implementa en Azure
- Implementación de la capa de aplicación de SAP de un sistema en una región de Azure diferente a la del nivel de DBMS.
- Implementación de un nivel en centros de datos que se encuentran en la misma ubicación que Azure y el otro nivel en Azure, excepto en los casos en los que un servicio nativo de Azure proporciona este tipo de patrón de arquitectura.
- Implementación de aplicaciones virtuales de red entre el nivel de aplicación de SAP y el nivel de DBMS.
- Uso del almacenamiento que se hospeda en centros de información que se encuentran en la misma ubicación que el centro de datos de Azure para el nivel de DBMS de SAP o el directorio de transporte global de SAP.
- Implementación de dos niveles con dos proveedores de nube diferentes. Por ejemplo, la implementación del nivel de DBMS en la infraestructura de la nube de Oracle y el nivel de aplicación en Azure.
- Configuraciones de clúster de Pacemaker de HANA de varias instancias
- Configuraciones de clúster de Windows con discos compartidos a través de SOFS o SMB en ANF para las bases de datos de SAP compatibles con Windows. En su lugar, se recomienda el uso de la replicación nativa de alta disponibilidad de las bases de datos concretas y el uso de pilas de almacenamiento independientes.
- Implementación de bases de datos de SAP que se admiten en Linux con archivos de base de datos que se encuentran en recursos compartidos de archivos de NFS sobre ANF, excepto SAP HANA, Oracle en Oracle Linux y Db2 en Suse y Red Hat.
- Implementación de DBMS de Oracle en cualquier otro sistema operativo invitado además de Windows y Oracle Linux. Consulte también la nota de soporte técnico de SAP 2039619.
Escenarios que no hemos probado y, por lo tanto, con los que no tenemos experiencia; por ejemplo:
- Azure Site Recovery replicando máquinas virtuales de nivel de DBMS. Por lo tanto, se recomienda utilizar la funcionalidad de replicación asincrónica nativa de la base de datos para una posible configuración de recuperación ante desastres.
Pasos siguientes
Consulte los pasos siguientes en Implementación y planeamiento de Azure Virtual Machines para SAP NetWeaver.