Teoría del algoritmo de búsqueda de Grover
En este artículo encontrará una explicación teórica detallada de los principios matemáticos que hacen que el algoritmo de Grover funcione.
Para obtener una implementación práctica del algoritmo de Grover para resolver problemas matemáticos, consulte Implementación del algoritmo de búsqueda de Grover.
Instrucción del problema
El algoritmo de Grover acelera la solución a búsquedas de datos no estructuradas (o problema de búsqueda), ejecutando la búsqueda en menos pasos que cualquier algoritmo clásico. Cualquier tarea de búsqueda se puede expresar con una función $f(x)$ abstracta que acepta elementos de búsqueda $x$. Si el elemento $x$ es una solución para la tarea de búsqueda, $f(x)=1$. Si el elemento $x$ no es una solución, $f(x)=0$. El problema de búsqueda consiste en buscar cualquier elemento $x_0$, de forma que $f(x_0)=1$.
Cualquier problema que le permita comprobar si un valor determinado $x$ es una solución válida (una " Sí o ningún problema") se puede formular en términos del problema de búsqueda. Estos son algunos ejemplos:
- Problema de satisfiabilidad booleana: dado un conjunto de valores booleanos, ¿el conjunto satisface una fórmula booleana determinada?
- Problema de vendedores de viajes: ¿Cuál es el bucle más corto posible que conecta todas las ciudades?
- Problema de búsqueda de base de datos: ¿contiene una tabla de base de datos el registro $x$?
- Problema de factorización de enteros: ¿Es el número $N$ divisible por el número $x$?
La tarea que pretende resolver el algoritmo de Grover puede expresarse de la siguiente manera: dada una función clásica $f(x):\{0,1\}^n \rightarrow\{0,1\}$, donde $n$ es el tamaño de los bits del espacio de búsqueda, encontrar una entrada $x_0$ para la que $f(x_0)=1$. La complejidad del algoritmo se mide por el número de usos de la función $f(x)$. De forma clásica, en el peor de los casos, tenemos que evaluar $f(x)$ un total de $N-1$ veces, donde $N=2^n$, probando todas las posibilidades. Después de $N-1$ elementos, debe ser el último elemento. El algoritmo cuántico de Grover puede resolver este problema mucho más rápido, con una velocidad cuadrática. La velocidad cuadrática implica que solo se requieren $\sqrt{N}$ evaluaciones, en comparación con $N$.
Esquema del algoritmo
Supongamos que hay $N=2^n$ elementos aptos para la tarea de búsqueda y los indexamos asignando a cada elemento un entero de $0$ a $N-1$. Además, supongamos que hay $M$ entradas válidas diferentes, lo que significa que hay $M$ entradas para las que $f(x)=1$. Los pasos del algoritmo son los siguientes:
- Comience con un registro de $n$ cúbits iniciado en el estado $\ket{0}$.
- Prepare el registro en una superposición uniforme aplicando $H$ a cada cúbit del registro: $$|\text{register}\rangle=\frac{1}{\sqrt{N}}\sum_{x=0}^{N-1}|x\rangle$$
- Aplica las siguientes operaciones al registro $N_{\text{optimal}}$ veces:
- El oráculo de fase $O_f$ que aplica un desplazamiento de fase condicional de $-1$ para los elementos de la solución.
- Aplique $H$ a cada cúbit del registro.
- Un desplazamiento de fase condicional de $-1$ a cada estado de base computacional excepto $\ket{0}$. Esto se puede representar mediante la operación unitaria $-O_0$, del mismo modo que $O_0$ representa el desplazamiento de la fase condicional a $\ket{0}$ solamente.
- Aplique $H$ a cada cúbit del registro.
- Mida el registro para obtener el índice de un elemento que es una solución con una probabilidad muy alta.
- Comprueba si se trata de una solución válida. Si no es así, vuelve a empezar.
$N_{\text{optimal}}=\left\lfloor \frac{\pi}{{4}\sqrt{\frac{N}{M}}-\frac{{1}{{2}\right\rfloor$ es el número óptimo de iteraciones que maximiza la probabilidad de obtener el elemento correcto midiendo el registro.
Nota:
La aplicación conjunta de los pasos 3.b, 3.c y 3.d se conoce normalmente como operador de difusión de Grover.
La operación unitaria general aplicada al registro es:
$$(-H^{\otimes n}O_0H^{\otimes n}O_f)^{N_{\text{optimal}}}H^{\otimes n}$$
Seguimiento del estado del registro paso a paso
Para ilustrar el proceso, vamos a seguir las transformaciones matemáticas del estado del registro para un caso simple en el que solo tenemos dos cúbits y el elemento válido es $\ket{01}.$
El registro se inicia en el estado.
$\ket{\text{register}}=\ket{{00}$
Después de aplicar $H$ a cada cúbit, el estado del registro se transforma en:
$\ket{\text{register}}=\frac{{1}{\sqrt{4}}\sum_{i \in \lbrace 0,1 \rbrace}^2\ket{i}=\frac12(\ket{00}+\ket{01}+\ket{{10}+\ket{11})$
A continuación, se aplica el oráculo de fase para obtener:
$\ket{\text{register}}=\frac12(\ket{{00}-\ket{{01}+\ket{{10}+\ket{{11})$
A continuación, $H$ actúa de nuevo en cada cúbit para dar:
$\ket{\text{register}}=\frac12(\ket{{00}+\ket{{01}-\ket{{10}+\ket{{11})$
Ahora, el cambio de fase condicional se aplica en cada estado, excepto $\ket{00}$:
$\ket{\text{register}}=\frac12(\ket{{00}-\ket{{01}+\ket{{10}-\ket{{11})$
Por último, la primera iteración de Grover finaliza aplicando $H$ de nuevo para obtener:
$\ket{\text{register}}=\ket{{01}$
Siguiendo los pasos anteriores, el elemento válido se encuentra en una sola iteración. Como verá más adelante, esto se debe a que para N=4 y un solo elemento válido, el número óptimo de veces es $N_{\text{óptimo}}=1$.
Explicación geométrica
Para ver por qué funciona el algoritmo de Grover, vamos a estudiar el algoritmo desde una perspectiva geométrica. Suponiendo que hay $M$ soluciones válidas, la superposición de todos los estados cuánticos que no son una solución al problema de búsqueda:
$$\ket{\text{bad}}=\frac{{1}{\sqrt{N-M}}\sum_{x:f(x)=0}\ket{x}$$
La superposición de todos los estados que son una solución del problema de búsqueda:
$$\ket{\text{good}}=\frac{{1}{\sqrt{M}}\sum_{x:f(x)=1}\ket{x}$$
Puesto que good y bad son conjuntos mutuamente excluyentes, porque un elemento no puede ser válido y no válido, los estados son ortogonales. Ambos estados forman la base ortogonal de un plano en el espacio vectorial. Podemos usar este plano para visualizar el algoritmo.
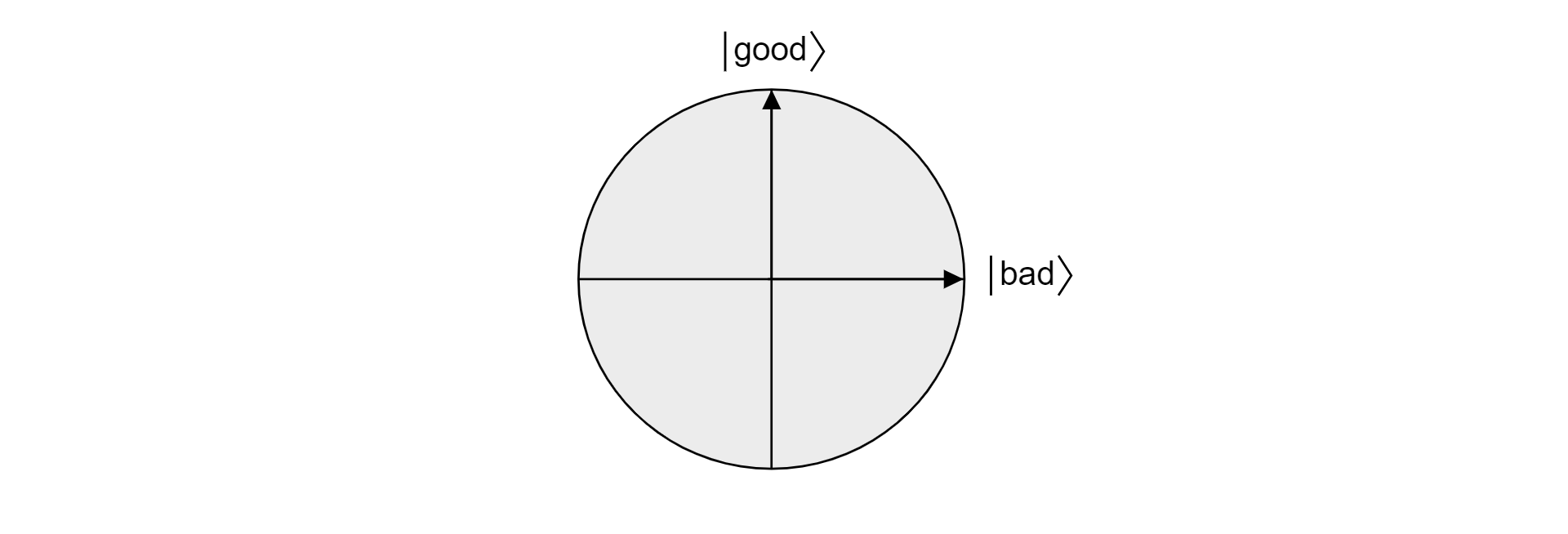
Ahora, supongamos que $\ket{\psi}$ es un estado arbitrario que reside en el plano abarcado por $\ket{\text{good}}$ y $\ket{\text{bad}}$. Cualquier estado que se encuentra en ese plano se puede expresar como:
$$\ket{\psi}=\alpha\ket{\text{good}} + \beta\ket{\text{bad}}$$
donde $\alpha$ y $\beta$ son números reales. Ahora, vamos a presentar el operador de reflexión $R_{\ket{\psi}}$, donde $\ket{\psi}$ es cualquier estado de cúbit que se encuentra en el plano. El operador se define como:
$$R_{\ket{\psi}}=2\ket{\psi}\bra{\psi}-\mathcal{I}$$
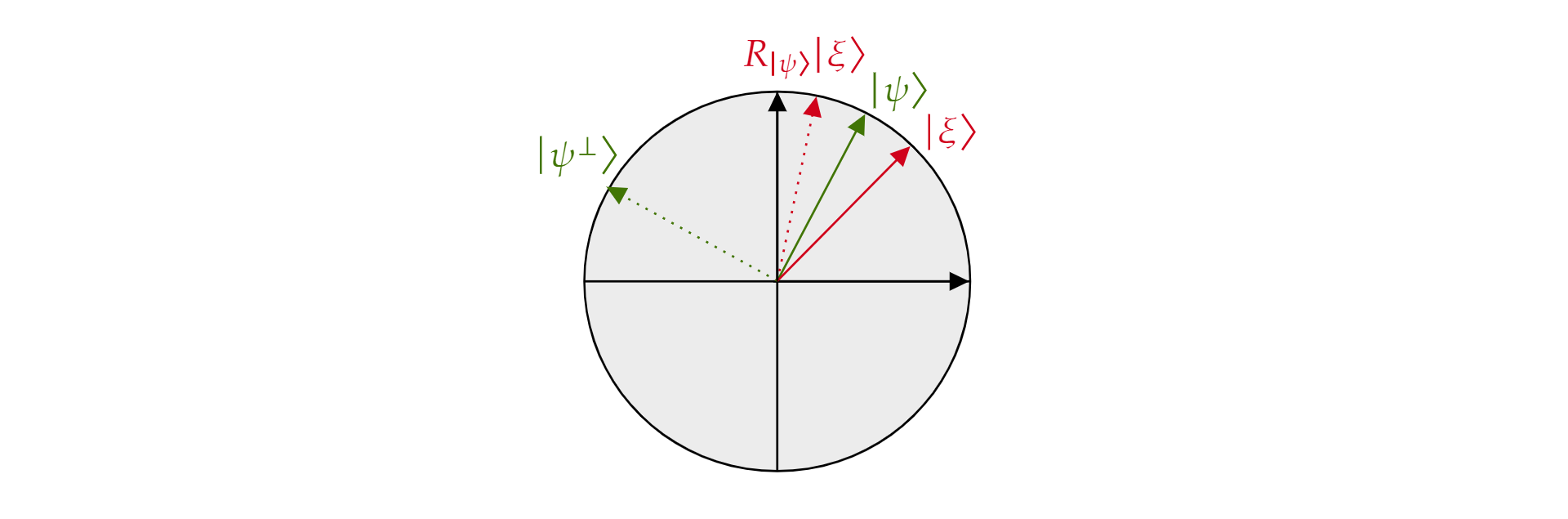
Se denomina operador de reflexión sobre $\ket{\psi}$ porque se puede interpretar geométricamente como reflexión sobre la dirección de $\ket{\psi}$. Para verlo, tome la base ortogonal del plano formado por $\ket{\psi}$ y su complemento ortogonal $\ket{\psi^{\perp}}$. Cualquier estado $\ket{\xi}$ del plano se puede descomponer de esta forma:
$$\ket{\xi}=\mu \ket{\psi} + \nu {\ket{\psi^{\perp}}}$$
Si se aplica el operador $R_{\ket{\psi}}$ a $\ket{\xi}$:
$$R_{\ket{\psi}}\ket{\xi}=\mu \ket{\psi} - \nu {\ket{\psi^{\perp}}}$$
El operador $R_{\ket{\psi}}$ invierte el componente ortogonal en $\ket{\psi}$, pero deja el componente $\ket{\psi}$ sin cambios. Por lo tanto, $R_{\ket{\psi}}$ es una reflexión sobre $\ket{\psi}$.
El algoritmo de Grover, después de la primera aplicación de $H$ a cada cúbit, empieza con una superposición uniforme de todos los estados. Esto se puede escribir como:
$$\ket{\text{all}}=\sqrt{\frac{M}{N}}\ket{\text{good}} + \sqrt{\frac{N-M}{N}}\ket{\text{bad}}$$
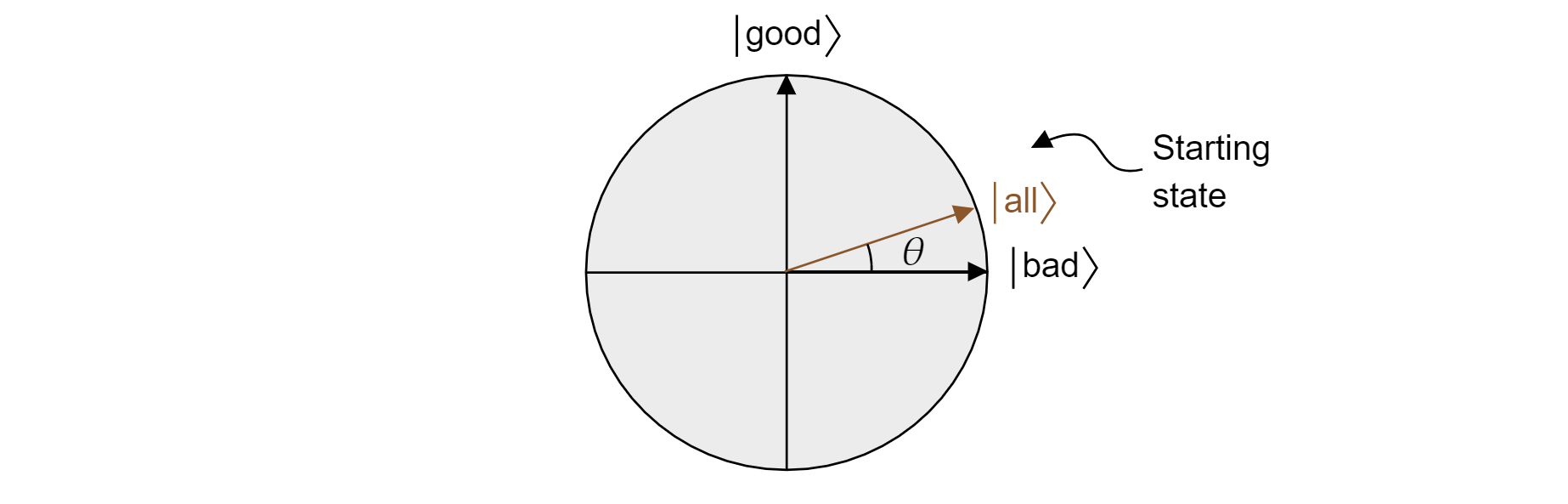
Y, por tanto, el estado reside en el plano. Tenga en cuenta que la probabilidad de obtener un resultado correcto cuando la medición de la superposición igual es simplemente $|\bra{\text{buena}}\ket{\text{all}}|^2=M/N$, que es lo que se esperaría de una estimación aleatoria.
El oráculo $O_f$ agrega una fase negativa a cualquier solución al problema de búsqueda. Por lo tanto, se puede escribir como una reflexión sobre el eje $\ket{\text{bad}}$:
$O_f = R_{\ket{\text{bad}}}= 2\ket{\text{bad}}\bra{\text{bad}} - \mathbb{I}$
Análogamente, el desplazamiento de fase condicional $O_0$ es simplemente una reflexión invertida sobre el estado $\ket{0}$:
$O_{0}= R_{\ket{0}}= -2\ket{{0}\bra{{0} + \mathbb{I}$
Sabiendo este hecho, es fácil comprobar que la operación de difusión de Grover $-H^{\otimes n} O_{0} H^{\otimes n}$ también es una reflexión sobre el estado $\ket{all}$. Simplemente haga lo siguiente:
$-H^{\otimes n} O_{{0} H^{\otimes n}=2H^{\otimes n}\ket{0}\bra{{0}H^{\otimes n} -H^{\otimes n}\mathbb{I}H^{\otimes n}= 2\ket{\text{all}}\bra{\text{all}} - \mathbb{I}= R_{\ket{\text{all}}}$
Se ha demostrado que cada iteración del algoritmo de Grover es una composición de dos reflejos $R_{\ket{\text{bad}}}$ y $R_{\ket{\text{all}}}$.
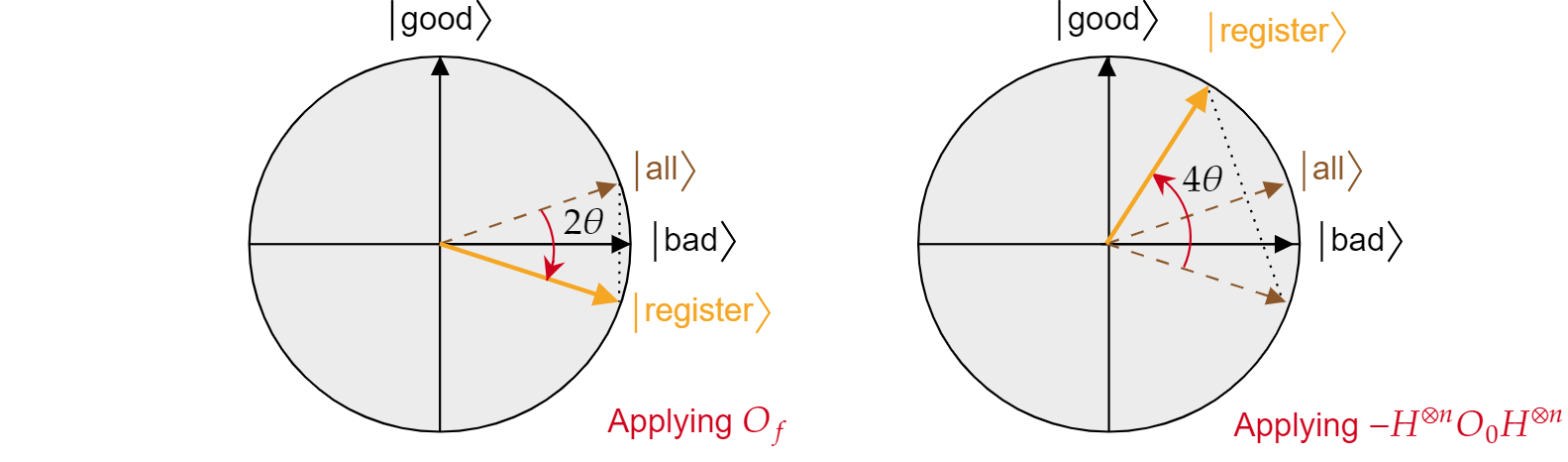
El efecto combinado de cada iteración de Grover es una rotación en sentido contrario a las agujas del reloj de un ángulo $2\theta$. Afortunadamente, el ángulo $\theta$ es fácil de encontrar. Dado que $\theta$ es simplemente el ángulo entre $\ket{\text{all}}$ y $\ket{\text{bad}}$, podemos usar el producto escalar para encontrar el ángulo. Se sabe que $\cos{\theta}=\braket{\text{all}|\text{bad}}$, por lo que necesitamos calcular $\braket{\text{all}|\text{bad}}$. A partir de la descomposición de $\ket{\text{all}}$ en términos de $\ket{\text{bad}}$ y $\ket{\text{good}}$, se obtiene los siguiente:
$$\theta = \arccos{\left(\braket{\text{all}|\text{bad}}\right)}= \arccos{\left(\sqrt{\frac{N-M}{N}}\right)}$$
El ángulo entre el estado del registro y el $\ket{\text{buen}}$ estado disminuye con cada iteración, lo que da lugar a una mayor probabilidad de medir un resultado válido. Para calcular esta probabilidad, solo tiene que calcular $|\braket{\text{el buen}|\text{registro}}|^2$. El ángulo entre $\ket{\text{good}}$ y $\ket{\text{register}}$ se indica como $\gamma (k)$, donde $k$ es el recuento de iteraciones:
$\gamma = \frac{\pi}{2}-\theta -2k\theta =\frac{\pi}{{2} -(2k + 1) \theta $
Por lo tanto, la probabilidad de éxito es:
$$P(\text{success}) = \cos^2(\gamma(k)) = \sin^2\left[(2k +1)\arccos \left( \sqrt{\frac{N-M}{N}}\right)\right]$$
Número óptimo de iteraciones
Como la probabilidad de éxito se puede escribir como una función del número de iteraciones, podemos encontrar el número óptimo de iteraciones $N_{\text{optimal}}$ al calcular el entero positivo más pequeño que (aproximadamente) maximiza la función de probabilidad de éxito.
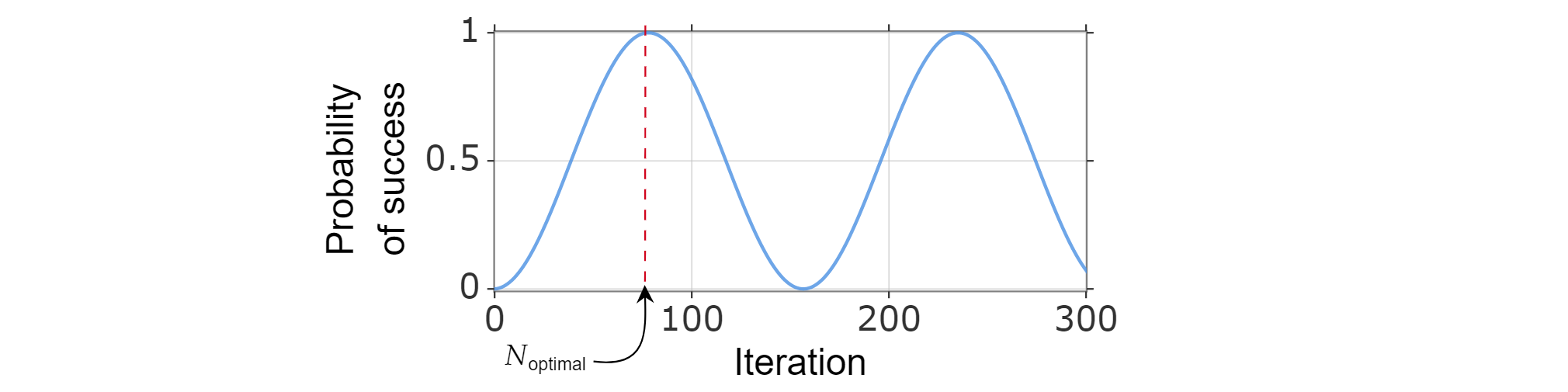
Se sabe que $\sin^2{x}$ alcanza su primer máximo para $x=\frac{\pi}{2}$, por lo que:
$\frac{\pi}{{2}=(2k_{\text{optimal}} +1)\arccos \left( \sqrt{\frac{N-M}{N}}\right)$
Este es el resultado:
$$k_{\text{optimal}}=\frac{\pi}{4\arccos\left(\sqrt{1-M/N}\right)}-1/2 =\frac{\pi}{{4}\sqrt{\frac{N}{M}}-\frac{1}{2}-O\left(\sqrt\frac{M}{N}\right)$$
Donde en el último paso, $\arccos \sqrt{1-x}=\sqrt{x} + O(x^{3/2})$.
Por lo tanto, puede elegir $N_{\text{optimal}}=\left\lfloor \frac{\pi}{{4}\sqrt{\frac{N}{M}}-\frac{{1}{{2}\right\rfloor$.
Análisis de complejidad
En el análisis anterior, necesitamos $O\left(\sqrt{\frac{N}{M}}\right)$ consultas del oráculo $O_f$ para encontrar un elemento válido. Sin embargo, ¿se puede implementar el algoritmo de forma eficaz en términos de complejidad de tiempo? $O_0$ se basa en la computación de operaciones booleanas en $n$ bits y se sabe que se puede implementar mediante $O(n)$ puertas. También hay dos capas de $n$ puertas Hadamard. Por lo tanto, ambos componentes solo requieren $O(n)$ puertas por iteración. Como $N=2^n$, se deduce que $O(n)=O(log(N))$. Por lo tanto, si necesitamos $O\left(\sqrt{\frac{N}{M}}\right)$ iteraciones y $O(log(N))$ puertas por iteración, la complejidad de tiempo total (sin tener en cuenta la implementación del oráculo) es $O\left(\sqrt{\frac{N}{M}}log(N)\right)$.
La complejidad general del algoritmo depende en última instancia de la complejidad de la implementación del O_f$ de oracle$. Si una evaluación de funciones es mucho más complicada en un equipo cuántico que en una clásica, el tiempo de ejecución del algoritmo general será más largo en el caso cuántico, aunque técnicamente use menos consultas.
Referencias
Si desea seguir aprendiendo sobre el algoritmo de Grover, puede comprobar cualquiera de los siguientes orígenes:
- Documento original de Lov K. Grover
- Sección de algoritmos de búsqueda cuántica de Nielsen, M. A. &erio; Chuang, I. L. (2010). Quantum Computation and Quantum Information (Computación cuántica e información cuántica).
- Algoritmo de Grover en Arxiv.org