Solución de problemas e identificación de consultas de ejecución lenta en Azure Database for PostgreSQL: servidor flexible
SE APLICA A:  Azure Database for PostgreSQL con servidor flexible
Azure Database for PostgreSQL con servidor flexible
En este artículo se describe cómo identificar y diagnosticar la causa principal de las consultas de ejecución lenta.
En este artículo, aprenderá lo siguiente:
- Cómo identificar las consultas de ejecución lenta.
- Cómo identificar un procedimiento de ejecución lenta junto a la misma. Identificar una consulta lenta entre una lista de consultas que pertenecen al mismo procedimiento almacenado de ejecución lenta.
Requisitos previos
Habilite las guías de solución de problemas siguiendo los pasos descritos en Usar guías de solución de problemas.
Configure la extensión
auto_explainagregando en la lista de permitidos y cargando la extensión.Una vez configurada la extensión
auto_explain, cambie los siguientes parámetros de servidor, que controlan el comportamiento de la extensión:- De
auto_explain.log_analyzeaON. - De
auto_explain.log_buffersaON. auto_explain.log_min_durationsegún lo que sea razonable en su escenario.- De
auto_explain.log_timingaON. - De
auto_explain.log_verboseaON.
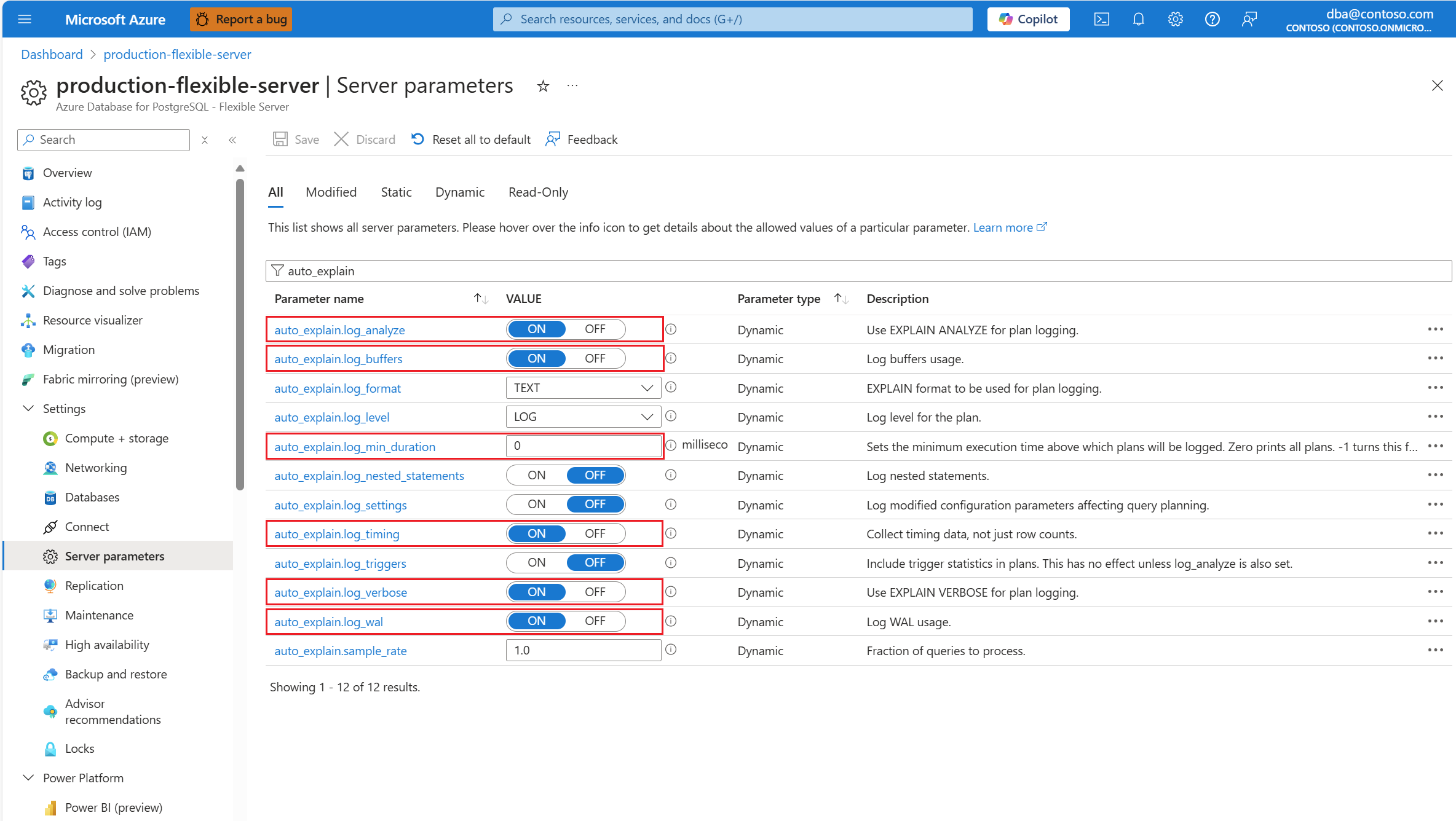
- De

Nota:
Si establece auto_explain.log_min_duration en 0, la extensión comienza a registrar todas las consultas que se ejecutan en el servidor. Esto puede afectar al rendimiento de la base de datos. Se deben realizar las diligencias adecuadas para llegar a un valor que se considera lento en el servidor. Por ejemplo, si todas las consultas se completan en menos de 30 segundos y eso es aceptable para la aplicación, se recomienda actualizar el parámetro a 30000 milisegundos. Esto registraría cualquier consulta que tarde más de 30 segundos en completarse.
Identificar consultas lentas
Con las guías de solución de problemas y la extensión auto_explain, se describe el escenario con la ayuda de un ejemplo.
Tenemos un escenario en el que el uso de CPU aumenta al 90 % y queremos determinar la causa del pico. Para depurar el escenario, siga estos pasos:
En cuanto se le avise de un escenario de CPU, en el menú de recursos de la instancia afectada del servidor flexible de Azure Database for PostgreSQL, en la sección Supervisión, seleccione Guías de solución de problemas.
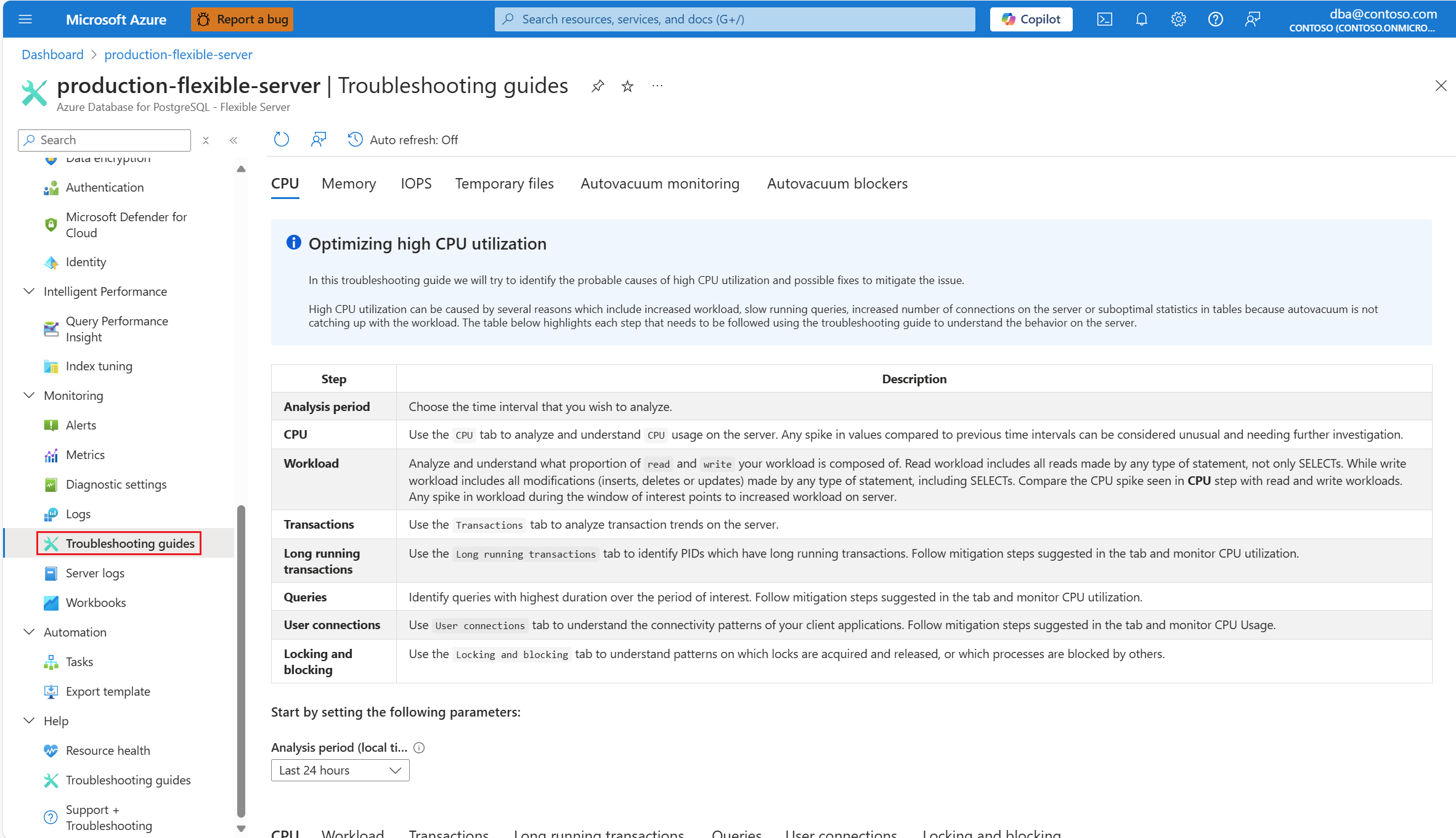
Seleccione la pestaña CPU. Se abre la guía de solución de problemas Optimizar uso elevado de la CPU.
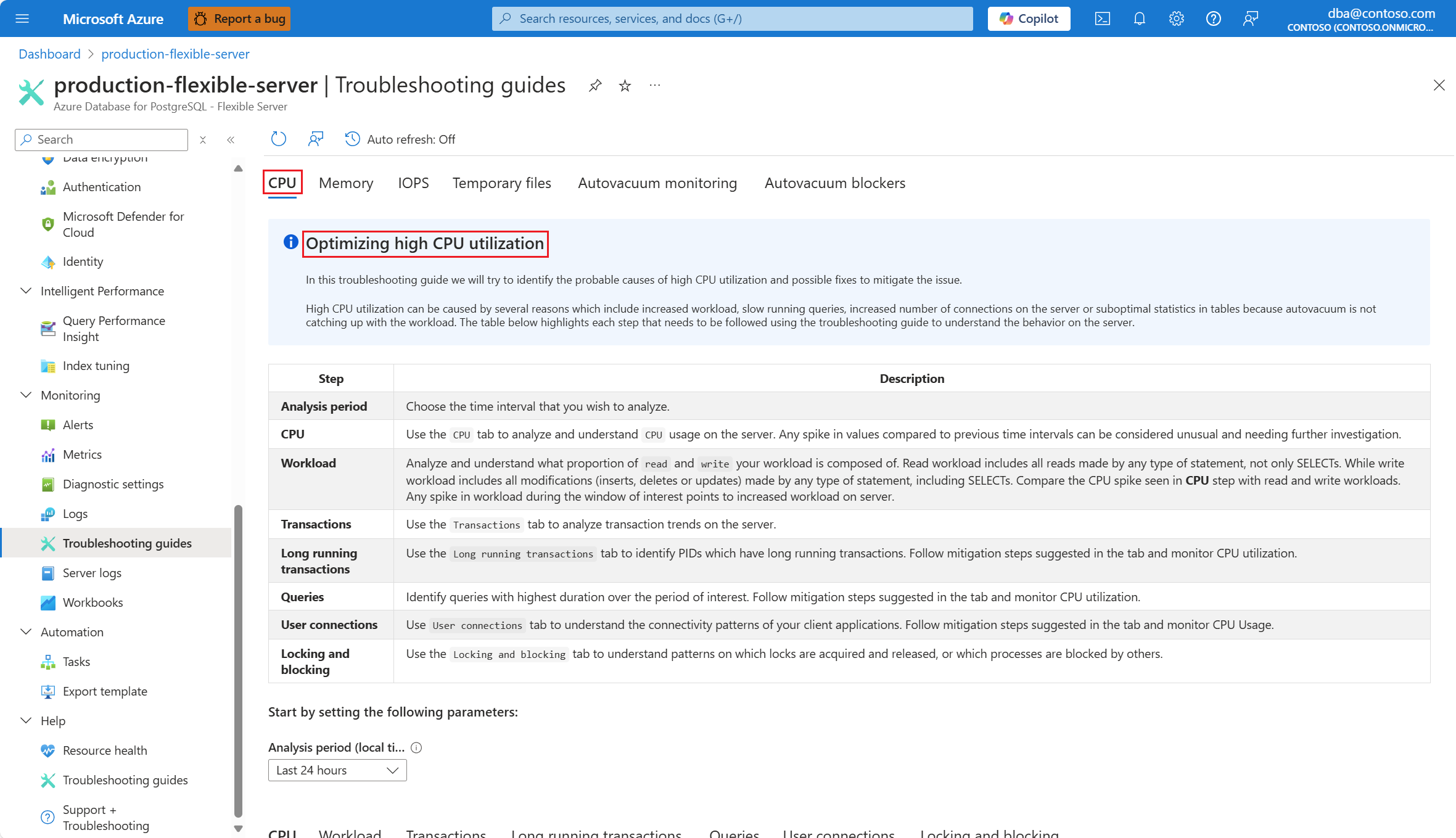
En la lista desplegable Período de análisis (hora local), seleccione el intervalo de tiempo en el que desea centrar el análisis.
Seleccione la pestaña Consultas. Muestra los detalles de todas las consultas que se ejecutaron en el intervalo donde se ha visto el 90 % de uso de CPU. Observando la instantánea, parece que la consulta con el tiempo de ejecución promedio más lento durante el intervalo de tiempo era de aproximadamente 2,6 minutos y la consulta se ejecutó 22 veces durante el intervalo. Es probable que esa consulta sea la causa de los picos de uso de CPU.
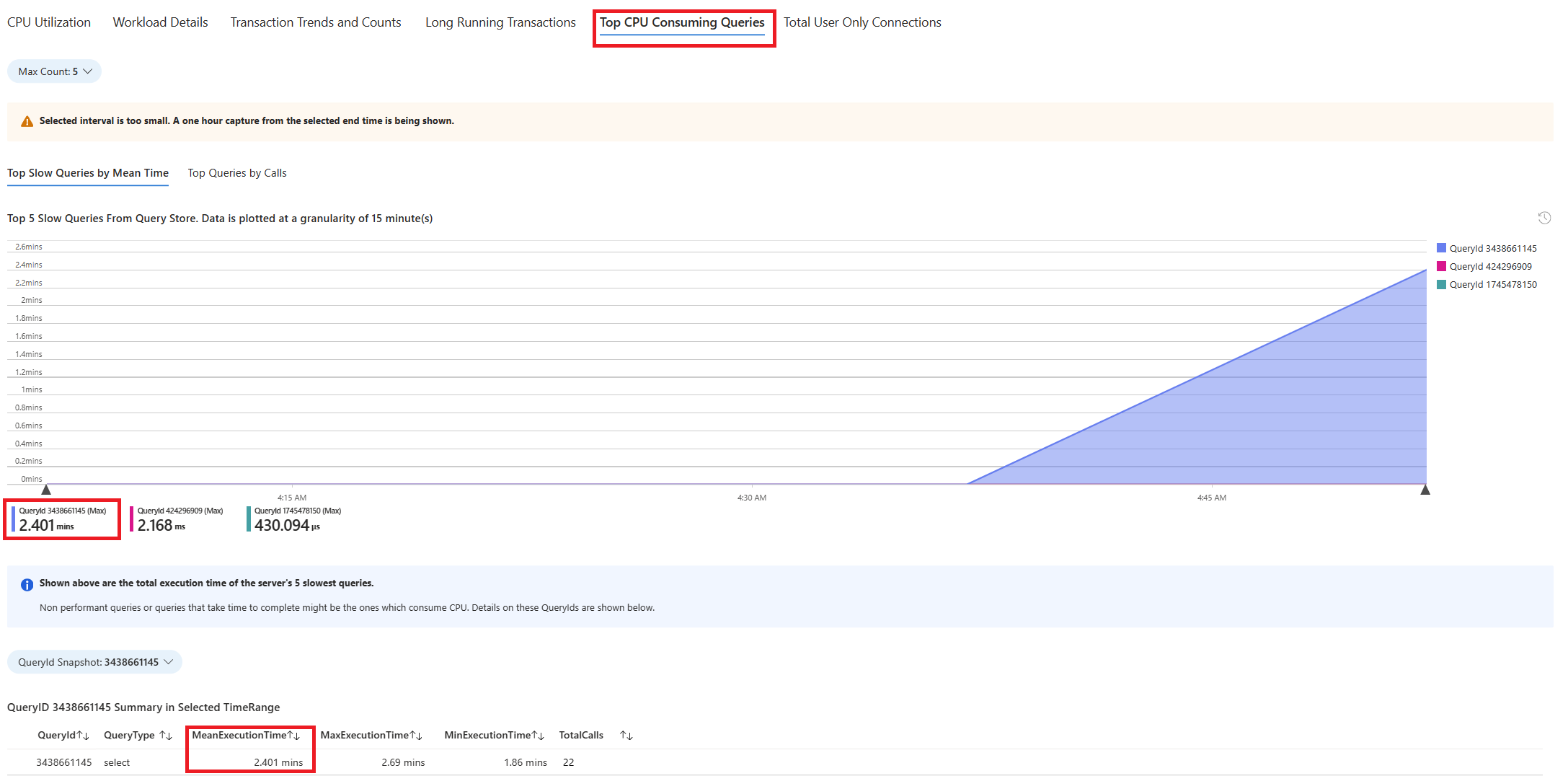
Para recuperar el texto de consulta real, conéctese a la base de datos
azure_sysy ejecute la consulta siguiente.




psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- En el ejemplo considerado, la consulta lenta fue:
SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id, c_id
ORDER BY c_w_id;
Para comprender qué plan de explicación exacto se generó, use los registros de servidor flexible de Azure Database for PostgreSQL. Cada vez que la consulta complete la ejecución durante ese período de tiempo, la extensión
auto_explaindebe escribir una entrada en los registros. En el menú de recursos, en la sección Supervisión, seleccione Registros.
Seleccione el intervalo de tiempo en el que se encontró el 90 % de uso de CPU.
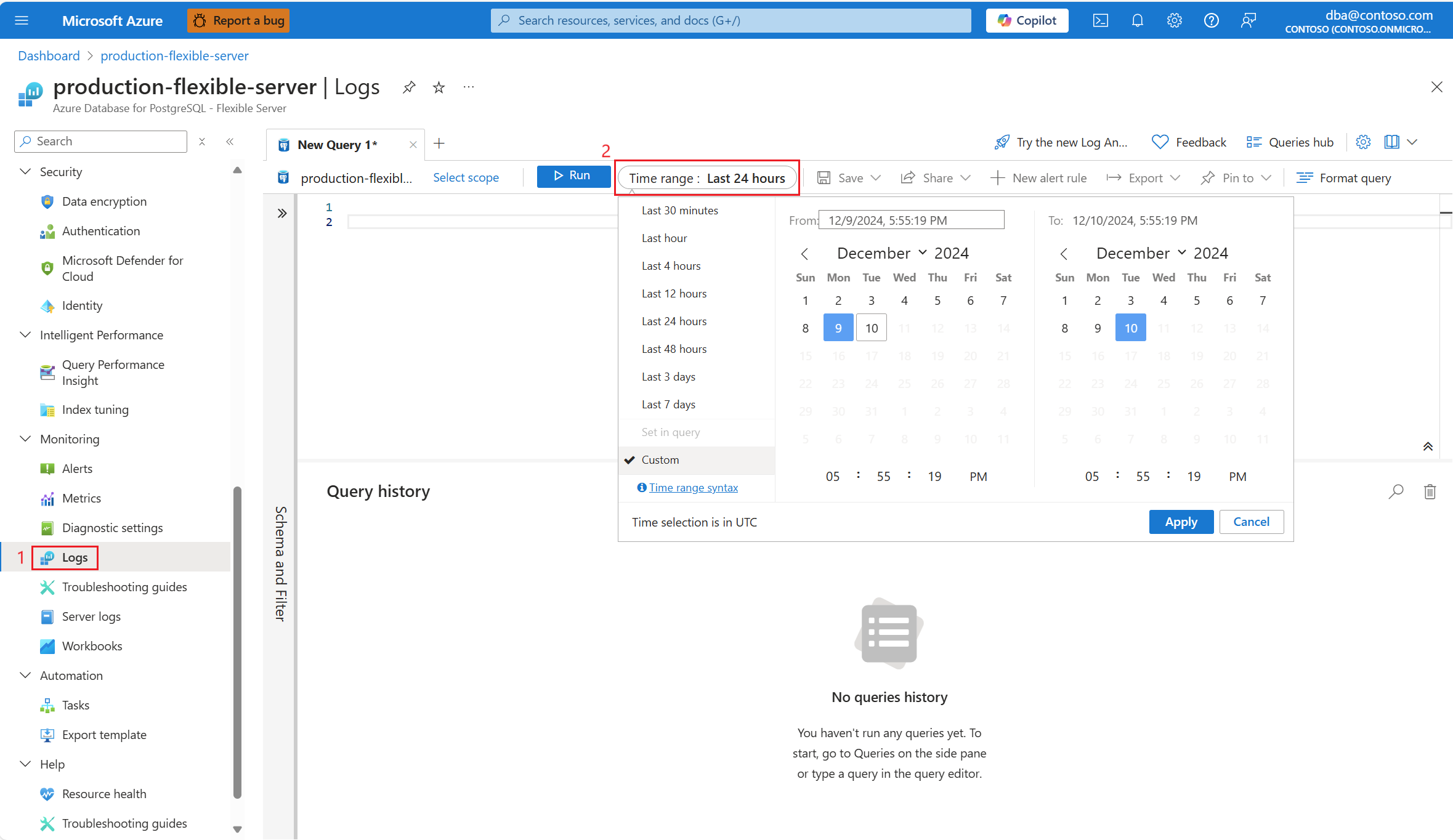
Ejecute la consulta siguiente para recuperar la salida de EXPLAIN ANALYZE para la consulta identificada.

AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
La columna de mensaje almacena el plan de ejecución como se muestra en esta salida:
2024-11-10 19:56:46 UTC-6525a8e7.2e3d-LOG: duration: 150692.864 ms plan:
Query Text: SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id,c_id
order by c_w_id;
GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=70930.833..129231.950 rows=10000000 loops=1)
Output: c_id, sum(c_balance), c_w_id
Group Key: customer.c_w_id, customer.c_id
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=70930.821..81898.430 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
Sort Key: customer.c_w_id, customer.c_id
Sort Method: external merge Disk: 225104kB
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.021..22997.697 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
La consulta se ejecutó durante aproximadamente 2,5 minutos, como se muestra en la guía de solución de problemas. El valor duration de 150692.864 ms de la salida del plan de ejecución capturada lo confirma. Use la salida de EXPLAIN ANALYZE para solucionar problemas y optimizar la consulta.
Nota:
Tenga en cuenta que la consulta se ejecutó 22 veces durante el intervalo, y los registros mostrados contienen una de esas entradas capturadas durante el intervalo.
Identificación de una consulta de ejecución lenta en un procedimiento almacenado
Con las guías de solución de problemas y extensión auto_explain instalada, explicamos el escenario con la ayuda de un ejemplo.
Tenemos un escenario en el que el uso de CPU aumenta al 90 % y queremos determinar la causa del pico. Para depurar el escenario, siga estos pasos:
En cuanto se le avise de un escenario de CPU, en el menú de recursos de la instancia afectada del servidor flexible de Azure Database for PostgreSQL, en la sección Supervisión, seleccione Guías de solución de problemas.
Seleccione la pestaña CPU. Se abre la guía de solución de problemas Optimizar uso elevado de la CPU.
En la lista desplegable Período de análisis (hora local), seleccione el intervalo de tiempo en el que desea centrar el análisis.
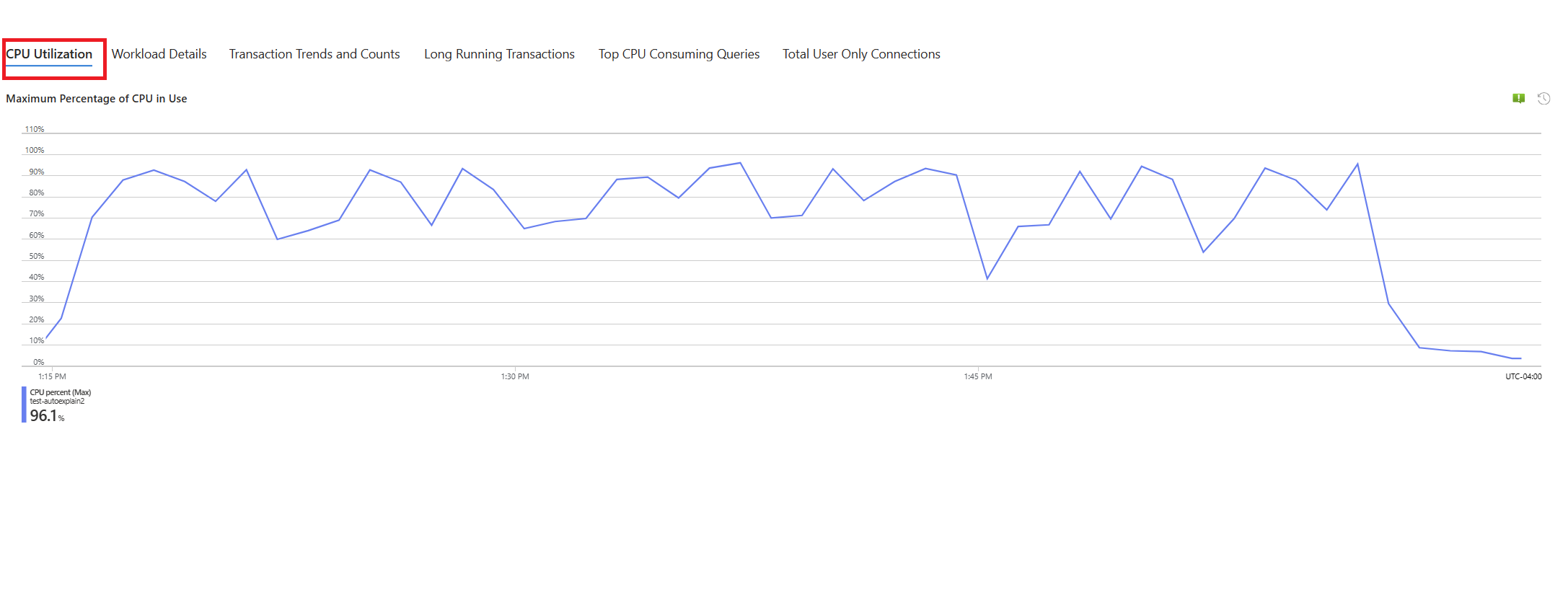
Seleccione la pestaña Consultas. Muestra los detalles de todas las consultas que se ejecutaron en el intervalo donde se ha visto el 90 % de uso de CPU. Observando la instantánea, parece que la consulta con el tiempo de ejecución promedio más lento durante el intervalo de tiempo era de aproximadamente 2,6 minutos y la consulta se ejecutó 22 veces durante el intervalo. Es probable que esa consulta sea la causa de los picos de uso de CPU.
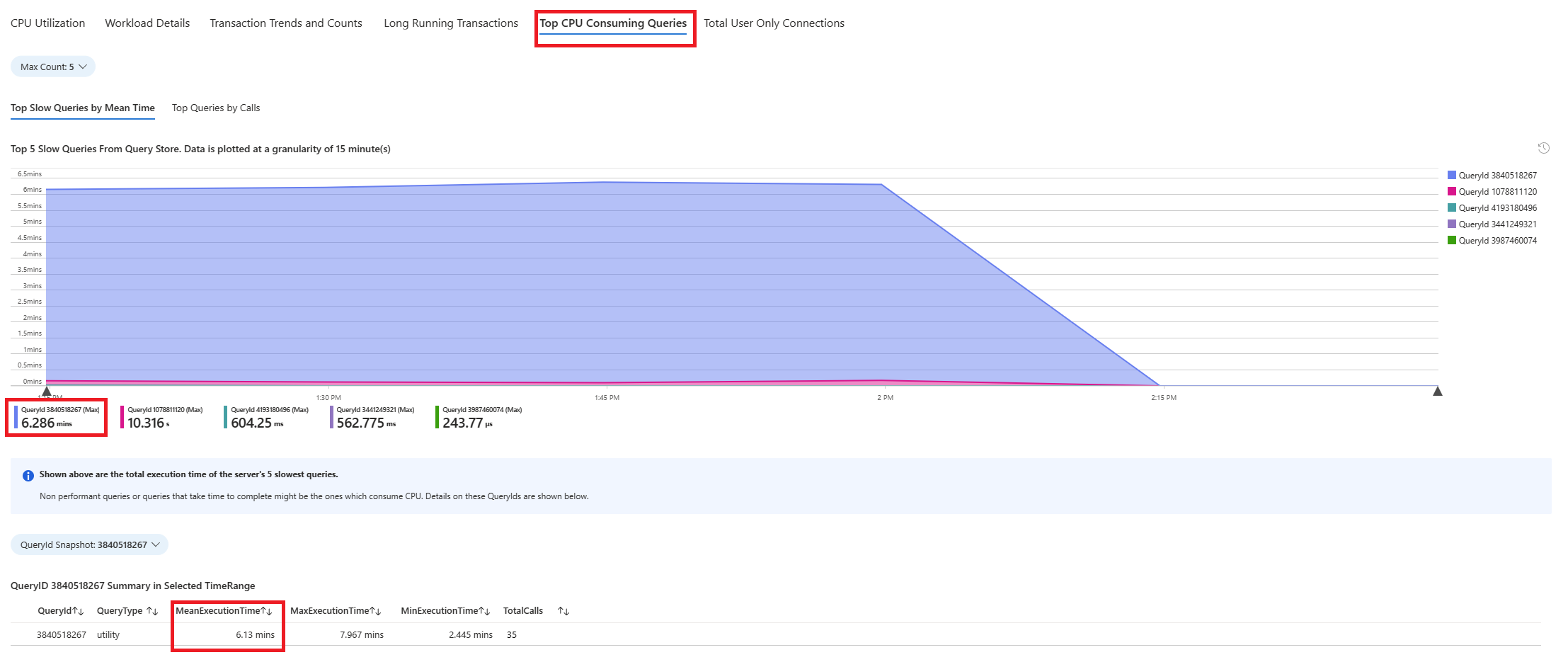
Conéctese a la base de datos azure_sys y ejecute la consulta para recuperar el texto de consulta real con el siguiente script.


psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- En el ejemplo considerado, la consulta lenta fue un procedimiento almacenado:
call autoexplain_test ();
- Para comprender qué plan de explicación exacto se generó, use los registros de servidor flexible de Azure Database for PostgreSQL. Cada vez que la consulta complete la ejecución durante ese período de tiempo, la extensión
auto_explaindebe escribir una entrada en los registros. En el menú de recursos, en la sección Supervisión, seleccione Registros. A continuación, en Intervalo de tiempo:, seleccione la ventana de tiempo en la que desea centrar el análisis.

- Ejecute la consulta siguiente para recuperar la salida de análisis de explicación de la consulta identificada.
AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
El procedimiento tiene varias consultas, que se resaltan a continuación. La salida del análisis de explicación de cada consulta que se usa en el procedimiento almacenado se registra para analizar más y solucionar problemas. El tiempo de ejecución de las consultas registradas se puede usar para identificar las consultas más lentas que forman parte del procedimiento almacenado.
2024-11-10 17:52:45 UTC-6526d7f0.7f67-LOG: duration: 38459.176 ms plan:
Query Text: insert into customer_balance SELECT c_id, SUM(c_balance) AS total_balance FROM customer GROUP BY c_w_id,c_id order by c_w_id
Insert on public.customer_balance (cost=1906820.83..2231820.83 rows=0 width=0) (actual time=38459.173..38459.174 rows=0 loops=1)Buffers: shared hit=10108203 read=454055 dirtied=54058, temp read=77521 written=77701 WAL: records=10000000 fpi=1 bytes=640002197
-> Subquery Scan on "*SELECT*" (cost=1906820.83..2231820.83 rows=10000000 width=36) (actual time=20415.738..29514.742 rows=10000000 loops=1)
Output: "*SELECT*".c_id, "*SELECT*".total_balance Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=20415.737..28574.266 rows=10000000 loops=1)
Output: customer.c_id, sum(customer.c_balance), customer.c_w_id Group Key: customer.c_w_id, customer.c_id Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=20415.723..22023.515 rows=10000000 loops=1)
Output: customer.c_id, customer.c_w_id, customer.c_balance Sort Key: customer.c_w_id, customer.c_id Sort Method: external merge Disk: 225104kB Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.310..15061.471 rows=10000000 loops=1) Output: customer.c_id, customer.c_w_id, customer.c_balance Buffers: shared hit=1 read=400000
2024-11-10 17:52:07 UTC-6526d7f0.7f67-LOG: duration: 61939.529 ms plan:
Query Text: delete from customer_balance
Delete on public.customer_balance (cost=0.00..799173.51 rows=0 width=0) (actual time=61939.525..61939.526 rows=0 loops=1) Buffers: shared hit=50027707 read=620942 dirtied=295462 written=71785 WAL: records=50026565 fpi=34 bytes=2711252160
-> Seq Scan on public.customer_balance (cost=0.00..799173.51 rows=15052451 width=6) (actual time=3185.519..35234.061 rows=50000000 loops=1)
Output: ctid Buffers: shared hit=27707 read=620942 dirtied=26565 written=71785 WAL: records=26565 fpi=34 bytes=11252160
2024-11-10 17:51:05 UTC-6526d7f0.7f67-LOG: duration: 10387.322 ms plan:
Query Text: select max(c_id) from customer
Finalize Aggregate (cost=180185.84..180185.85 rows=1 width=4) (actual time=10387.220..10387.319 rows=1 loops=1) Output: max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Gather (cost=180185.63..180185.84 rows=2 width=4) (actual time=10387.214..10387.314 rows=1 loops=1)
Output: (PARTIAL max(c_id)) Workers Planned: 2 Workers Launched: 0 Buffers: shared hit=37148 read=1204 written=69
-> Partial Aggregate (cost=179185.63..179185.64 rows=1 width=4) (actual time=10387.012..10387.013 rows=1 loops=1) Output: PARTIAL max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Parallel Index Only Scan using customer_i1 on public.customer (cost=0.43..168768.96 rows=4166667 width=4) (actual time=0.446..7676.356 rows=10000000 loops=1)
Output: c_w_id, c_d_id, c_id Heap Fetches: 24 Buffers: shared hit=37148 read=1204 written=69
Nota:
Para fines de demostración, se muestra la salida EXPLAIN ANALYZE de solo algunas consultas usadas en el procedimiento. La idea es que se pueda recopilar la salida EXPLAIN ANALYZE de todas las consultas de los registros e identificar la más lenta de esas y tratar de ajustarlas.
Contenido relacionado
- Solución de problemas de consumo elevado de CPU en Azure Database for PostgreSQL: servidor flexible.
- Solución de problemas de uso elevado de IOPS en Azure Database for PostgreSQL: servidor flexible.
- Solución de problemas de uso elevado de memoria en Azure Database for PostgreSQL: servidor flexible.
- Parámetros del servidor en Azure Database for PostgreSQL: servidor flexible.
- Ajuste del vaciado automático en Azure Database for PostgreSQL: servidor flexible.