Introducción a la continuidad empresarial con Azure Database for PostgreSQL: servidor flexible
SE APLICA A:  Azure Database for PostgreSQL con servidor flexible
Azure Database for PostgreSQL con servidor flexible
En el servidor flexible de Azure Database for PostgreSQL, la continuidad empresarial hace referencia a los mecanismos, directivas y procedimientos que permiten a la empresa seguir funcionando en caso de interrupciones, especialmente en lo que respecta a su infraestructura informática. En la mayoría de los casos, el servidor flexible de Azure Database for PostgreSQL controlará los eventos de interrupción que puedan ocurrir en el entorno en la nube y permitirá que se sigan ejecutando las aplicaciones y los procesos empresariales. No obstante, hay algunos eventos que no se pueden controlar automáticamente, por ejemplo:
- El usuario elimina o actualiza accidentalmente una fila de una tabla.
- Los terremotos provocan una interrupción de energía que puede deshabilitar temporalmente una zona de disponibilidad o una región.
- Se necesita una revisión de bases de datos para corregir un error o un problema de seguridad.
El servidor flexible de Azure Database for PostgreSQL proporciona características que protegen los datos y mitigan el tiempo de inactividad para las bases de datos fundamentales durante eventos de tiempo de inactividad planeados y no planeados. Según la infraestructura de Azure que ofrece una sólida resistencia y disponibilidad, un servidor flexible de Azure Database for PostgreSQL tiene características de continuidad empresarial que proporcionan otra protección ante errores, se ocupan de los requisitos de tiempo de recuperación y reducen el riesgo de pérdida de datos. Al diseñar las aplicaciones, debe tener en cuenta la tolerancia al tiempo de inactividad —el objetivo de tiempo de recuperación (RTO) y el riesgo de pérdida de datos—y el objetivo de punto de recuperación (RPO). Por ejemplo, su base de datos empresarial esencial tiene unos requisitos de tiempo de actividad más estrictos que una base de datos de prueba.
La tabla siguiente ilustra las características que ofrece el servidor flexible de Azure Database for PostgreSQL.
| Característica | Descripción | Consideraciones |
|---|---|---|
| Copias de seguridad automáticas | El servidor flexible de Azure Database for PostgreSQL realiza automáticamente copias de seguridad diarias de los archivos de su base de datos y hace copias de seguridad continuas de los registros de transacciones. Las copias de seguridad se pueden conservar desde 7 hasta 35 días. Es posible restaurar el servidor de bases de datos a un momento dado dentro del período de retención de la copia de seguridad. El RTO depende del tamaño de los datos que se van a restaurar más el tiempo necesario para realizar la recuperación del registro. Puede tardar desde unos minutos hasta 12 horas. Para obtener más información, vea Conceptos: copia de seguridad y restauración. | Los datos de copia de seguridad permanecen en la región. |
| Alta disponibilidad con redundancia de zona | El servidor flexible de Azure Database for PostgreSQL se puede implementar con configuración de alta disponibilidad (HA) redundante de zona. De este modo, los servidores principal y en espera se implementarán en dos zonas de disponibilidad diferentes dentro de una región. Esta configuración de alta disponibilidad protege sus bases de datos frente a errores de nivel de zona y además ayuda a reducir el tiempo de inactividad de la aplicación durante eventos de tiempo de inactividad planeados y no planeados. Los datos del servidor principal se replican de modo sincrónico en la réplica en espera. En caso de que se produzca una interrupción en el servidor principal, el servidor se conmuta por error automáticamente a la réplica en espera. Se espera que el RTO en la mayoría de los casos dure menos de 120 s. Se espera que el RPO sea cero (sin pérdida de datos). Para más información, consulte [Conceptos: alta disponibilidad]/azure/reliability/reliability-postgresql-flexible-server. | Compatible con los niveles de proceso de uso general y optimizado para memoria. Está disponible únicamente en regiones con varias zonas. |
| Alta disponibilidad en la misma zona | El servidor flexible de Azure Database for PostgreSQL se puede implementar con configuración de alta disponibilidad (HA) con redundancia de zona. De este modo, los servidores principal y en espera se implementarán en dos zonas de disponibilidad diferentes dentro de una región. Esta configuración de alta disponibilidad protege sus bases de datos frente a errores de nivel de zona y además ayuda a reducir el tiempo de inactividad de la aplicación durante eventos de tiempo de inactividad planeados y no planeados. Los datos del servidor principal se replican de modo sincrónico en la réplica en espera. En caso de que se produzca una interrupción en el servidor principal, el servidor se conmuta por error automáticamente a la réplica en espera. Se espera que el RTO en la mayoría de los casos dure menos de 120 s. Se espera que el RPO sea cero (sin pérdida de datos). Para más información, consulte [Conceptos: alta disponibilidad]/azure/reliability/reliability-postgresql-flexible-server. | Compatible con los niveles de proceso de uso general y optimizado para memoria. |
| Discos administrados premium | Los archivos de la base de datos se guardan en un almacenamiento premium administrado de alta disponibilidad y muy duradero. Esto proporciona redundancia de datos con tres copias de réplicas almacenadas en una zona de disponibilidad con capacidades automáticas de recuperación de datos. Para obtener más información, consulte la documentación de Managed Disks. | Datos almacenados en una zona de disponibilidad. |
| Copia de seguridad con redundancia de zona | Las copias de seguridad del servidor flexible de Azure Database for PostgreSQL se almacenan de forma automática y segura en un almacenamiento con redundancia de zona de una región si esta admite zonas de disponibilidad. Durante un error de nivel de zona en el que se ha aprovisionado el servidor, y si el servidor no está configurado con redundancia de zona, puede restaurar sin problemas la base de datos con el punto de restauración más reciente en otra zona. Para obtener más información, consulte Conceptos: copias de seguridad y restauración. | Aplicable únicamente a regiones con varias zonas disponibles. |
| Copia de seguridad con redundancia geográfica | Las copias de seguridad del servidor flexible de Azure Database for PostgreSQL se copian en una región remota. Esto es de ayuda con la situación de recuperación ante desastres en caso de que la región del servidor principal esté fuera de servicio. | Esta característica está habilitada actualmente en las regiones seleccionadas. Se tarda un RTO más largo y un RPO mayor en función del tamaño de los datos que se restaurarán y la cantidad de recuperación que se realizará. |
| Réplica de lectura | Las réplicas de lectura entre regiones se pueden implementar para proteger las bases de datos frente a errores de nivel de región. Las réplicas de lectura se actualizan de manera asincrónica mediante la tecnología de replicación física de PostgreSQL y pueden generar retrasos en la principal. Para obtener más información, vea Conceptos: réplicas de lectura. | Compatible con los niveles de proceso de uso general y optimizado para memoria. |
En la tabla siguiente se comparan el RTO y el RPO en un escenario de carga de trabajo típica:
| Funcionalidad | Flexible | Uso general | Memoria optimizada |
|---|---|---|---|
| Restauración a un momento dado a partir de una copia de seguridad | Cualquier punto de restauración dentro del período de retención RTO: varía RPO < 5 minutos |
Cualquier punto de restauración dentro del período de retención RTO: varía RPO < 5 minutos |
Cualquier punto de restauración dentro del período de retención RTO: varía RPO < 5 minutos |
| Restauración geográfica de las copias de seguridad con replicación geográfica | RTO: varía RPO < 1 hora |
RTO: varía RPO < 1 hora |
RTO: varía RPO < 1 hora |
| Réplicas de lectura | RTO: minutos* RPO < 5 minutos* |
RTO: minutos* RPO < 5 minutos* |
RTO: minutos* RPO < 5 minutos* |
* El RTO y el RPO pueden ser muy superiores en algunos casos, en función de varios factores, como la latencia entre sitios, la cantidad de datos que se transmitirá y, sobre todo, la carga de trabajo de escritura de la base de datos principal.
Eventos de tiempo de inactividad planeados
A continuación puede ver algunos escenarios de mantenimiento planeado. Normalmente, estos eventos incurren en pocos minutos de tiempo de inactividad y sin pérdida de datos.
| Escenario | Process |
|---|---|
| Escalado de proceso (iniciado por el usuario) | Durante la operación de escalado de proceso, se permite que se completen los puntos de comprobación activos, se purgan las conexiones de cliente, se cancelan las transacciones no confirmadas, se retira el almacenamiento y, a continuación, se apaga el servidor. Se aprovisiona una nueva instancia de servidor flexible de Azure Database for PostgreSQL con el mismo nombre de servidor de base de datos con la configuración de proceso escalado. Después, el almacenamiento se conecta al nuevo servidor y se inicia la base de datos, que, de ser necesario, realiza una recuperación antes de aceptar conexiones de cliente. |
| Escalado vertical del almacenamiento (iniciado por el usuario) | Cuando se inicia una operación de escalado vertical del almacenamiento, se permite que se completen los puntos de comprobación activos, se purgan las conexiones de cliente y se cancelan las transacciones no confirmadas. Después, se apaga el servidor. El almacenamiento se escala al tamaño deseado y, a continuación, se conecta al nuevo servidor. Si es necesario, se realiza una recuperación antes de aceptar conexiones de clientes. Tenga en cuenta que no se admite la reducción vertical para el tamaño del almacenamiento. |
| Nueva implementación de software (iniciada por Azure) | La implementación de nuevas características o las correcciones de errores se producen automáticamente como parte del mantenimiento planeado del servicio, y es posible programar cuándo se realizan estas actividades. Para obtener más información, consulte su portal. |
| Actualizaciones de versiones secundarias (iniciadas por Azure) | Azure Database for PostgreSQL revisa automáticamente los servidores de bases de datos según la versión secundaria determinada por Azure. Se produce como parte del mantenimiento planeado del servicio. El servidor de base de datos se reinicia automáticamente con la nueva versión secundaria. Para obtener más información, vea la documentación. También puede comprobar su portal. |
Cuando la instancia del servidor flexible de Azure Database for PostgreSQL se configura con alta disponibilidad, el servicio realiza las operaciones de escalado y mantenimiento en el servidor en espera en primer lugar. Para más información, consulte [Conceptos: alta disponibilidad]/azure/reliability/reliability-postgresql-flexible-server.
Mitigación del tiempo de inactividad no planeado
Se pueden producir tiempos de inactividad no planeados como resultado de interrupciones imprevistas, incluidos errores subyacentes de hardware, problemas de red y errores de software. Si el servidor de bases de datos configurado con una alta disponibilidad deja de funcionar de forma inesperada, la réplica en espera se activa y los clientes pueden reanudar sus operaciones. Si no se ha configurado con alta disponibilidad (HA), si se produce un error en el intento de reinicio, se aprovisiona automáticamente un nuevo servidor de base de datos. Aunque no es posible evitar un tiempo de inactividad no planeado, el servidor flexible de Azure Database for PostgreSQL lo reduce gracias a las operaciones de recuperación automáticas sin necesidad de intervención humana.
Aunque siempre estamos esforzándonos por proporcionar alta disponibilidad, hay ocasiones en las que el servidor flexible de Azure Database for PostgreSQL sufre una interrupción, lo que hace que la base de datos deje de estar disponible y, por tanto, afecta a la aplicación. Cuando la supervisión del servicio detecta problemas que provocan errores de conectividad generalizados, averías o problemas de rendimiento, el servicio declara automáticamente una interrupción para mantener al usuario informado.
Interrupción del servicio
En caso de interrupción del servidor flexible de Azure Database for PostgreSQL, puede consultar más detalles relacionados con la interrupción en los siguientes lugares:
- Banner de Azure Portal: Si se detecta que afecta a su suscripción, verá una alerta de interrupción en Problema de servicio en las Notificaciones de Azure Portal.
- Ayuda + soporte técnico o Soporte + solución de problemas: Al crear una incidencia de soporte técnico en Ayuda y soporte técnico o en Soporte y solución de problemas, verá información sobre los problemas que afectan a los recursos. Seleccione Ver los detalles de la interrupción para obtener más información y un resumen del alcance. También aparecerá una alerta en la página Nueva solicitud de soporte técnico.
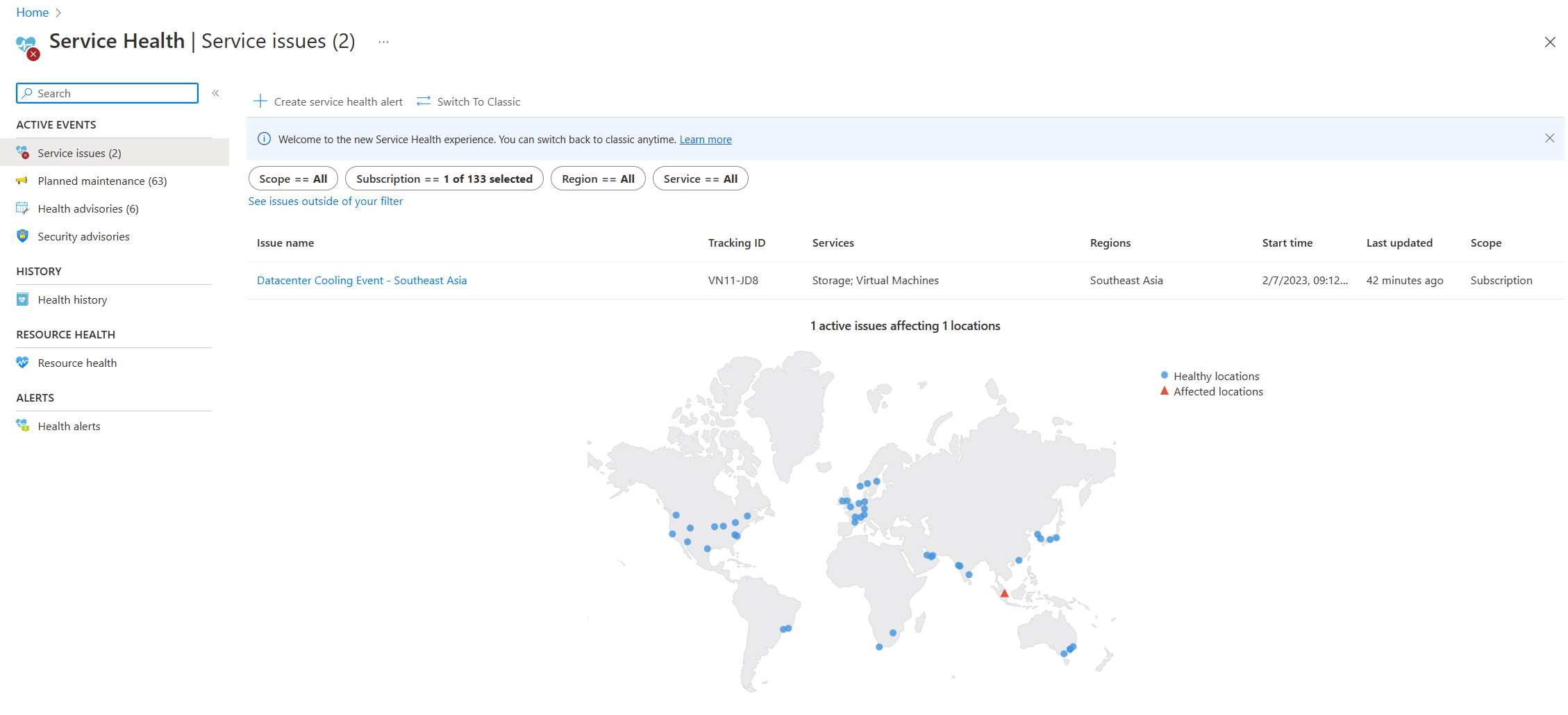
- Ayuda del servicio: La página Estado del servicio en Azure Portal contiene información sobre el estado global del centro de datos de Azure. Busque "estado del servicio" en la barra de búsqueda de Azure Portal y, a continuación, vea Problemas de servicio en la categoría Eventos activos. También puede ver el estado de un recurso concreto en la página Estado de los recursos del recurso en cuestión, en el menú Ayuda. Aquí se muestra una captura de pantalla de ejemplo de la página Estado del servicio con información sobre un problema de servicio activo en el sudeste asiático.
- Notificación por correo electrónico: Si ha configurado alertas, recibirá una notificación por correo electrónico cuando una interrupción del servicio afecte a su suscripción y recurso. Los correos electrónicos proceden de "azure-noreply@microsoft.com". El cuerpo del correo electrónico comienza con "La alerta del registro de actividad... se activó por un problema de servicio para la suscripción de Azure...". Para obtener más información sobre las alertas de estado de servicios, vea Recepción de alertas del registro de actividad en notificaciones de servicio de Azure mediante Azure Portal.
Importante
Como su nombre implica, los espacios de tablas temporales de PostgreSQL se usan para objetos temporales, así como para otras operaciones internas de base de datos, como la ordenación. Por lo tanto, no se recomienda crear objetos de esquema de usuario en el espacio de tablas temporal, ya que no garantizamos la durabilidad de estos objetos después de reiniciar el servidor, conmutaciones por error de alta disponibilidad, etc.
Tiempo de inactividad no planeado: escenarios de error y recuperación de servicio
A continuación puede ver algunos escenarios de error no planeados y el proceso de recuperación.
| Escenario | Proceso de recuperación [Servidores configurados sin alta disponibilidad con redundancia de zona] |
Proceso de recuperación [Servidores configurados con alta disponibilidad con redundancia de zona] |
|---|---|---|
| Error de servidor de bases de datos | Si el servidor de base de datos está inactivo, Azure intentará reiniciar el servidor de bases de datos. Si se produce un error, el servidor de bases de datos se reiniciará en otro nodo físico. El tiempo de recuperación (RTO) depende de varios factores, por ejemplo, la actividad en el momento del error, como una transacción de gran tamaño, y el volumen de recuperación que se va a realizar durante el proceso de inicio del servidor de bases de datos. Las aplicaciones que usan bases de datos de PostgreSQL se deben crear de forma que detecten y reintenten conexiones eliminadas y transacciones erróneas. |
Si se detecta un error del servidor de bases de datos, se activa el servidor en espera, lo que reduce el tiempo de inactividad. Para más información, consulte [página de conceptos de alta disponibilidad]/azure/reliability/reliability-postgresql-flexible-server. Se espera que el RTO dure entre 60 y 120 s, sin pérdida de datos. |
| Error de almacenamiento | Los problemas relacionados con el almacenamiento, como un error de disco o un daño de bloque físico, no afectarán a las aplicaciones. Puesto que los datos se almacenan en tres copias, el almacenamiento sobreviviente proporciona la copia de los datos. El bloque de datos dañado se repara automáticamente y se crea una copia de los datos de manera automática. | En el caso de los errores poco frecuentes y no recuperables, como aquellos en los que no se puede acceder a todo el almacenamiento, el servidor flexible de Azure Database for PostgreSQL se conmuta por error a la réplica en espera para reducir el tiempo de inactividad. Para más información, consulte [página de conceptos de alta disponibilidad]/azure/reliability/reliability-postgresql-flexible-server. |
| Errores de usuario o lógicos | Para recuperarse de los errores de usuario, como las tablas eliminadas accidentalmente o los datos actualizados incorrectamente, debe realizar una recuperación a un momento dado (PITR). Al realizar la operación de restauración, especifica el punto de restauración personalizado, que es el momento justo antes de que se produjera el error. Si quiere restaurar únicamente un subconjunto de bases de datos o tablas específicas en lugar de todas las bases de datos del servidor de bases de datos, puede restaurar el servidor de base de datos en una nueva instancia, exportar las tablas a través de pg_dump y, a continuación, usar pg_restore para restaurar esas tablas en la base de datos. |
Estos errores de usuario no están protegidos mediante la alta disponibilidad, ya que todos los cambios se replican también de forma sincrónica en la réplica en espera. Tiene que realizar una restauración a un momento dado para recuperarse de estos errores. |
| Error de zona de disponibilidad | Para recuperarse de un error de nivel de zona, puede realizar una recuperación a un momento dado mediante la copia de seguridad y elegir un punto de restauración personalizado del último momento para restaurar los datos más recientes. Una nueva instancia de servidor flexible de Azure Database for PostgreSQL se implementa en otra zona no afectada. El tiempo necesario para la restauración depende de la copia de seguridad anterior y del volumen de registros de transacciones que se van a recuperar. | El servidor flexible de Azure Database for PostgreSQL se conmuta por error automáticamente al servidor en espera en un plazo entre 60 y 120 segundos sin pérdida de datos. Para más información, consulte [página de conceptos de alta disponibilidad]/azure/reliability/reliability-postgresql-flexible-server. |
| Error de región | Si el servidor está configurado con copia de seguridad con redundancia geográfica, puede realizar la restauración geográfica en la región emparejada. Se aprovisionará un nuevo servidor y se recuperará en los últimos datos disponibles que se copiaron en esta región. También puede usar réplicas de lectura entre regiones. En caso de error de la región, puede realizar una operación de recuperación ante desastres promoviendo la réplica de lectura para que sea un servidor independiente de lectura y escritura. Se espera que el objetivo de punto de recuperación sea de hasta 5 minutos (posible pérdida de datos), excepto en el caso de un error regional grave cuando el RPO puede estar cerca del retraso de replicación en el momento del error. |
Mismo proceso. |
Configure su base de datos tras la recuperación de un error regional
- Si está utilizando la recuperación geográfica o la réplica geográfica para recuperarse de una interrupción, debe asegurarse de que la conectividad con el nuevo servidor esté configurada correctamente para que se pueda reanudar el funcionamiento normal de la aplicación. Puede seguir las Tareas posteriores a la restauración.
- Si ha configurado previamente una configuración de diagnóstico en el servidor original, asegúrese de hacer lo mismo en el servidor de destino si es necesario, como se explica en Configurar y acceder a registros en Azure Database for PostgreSQL - Servidor flexible.
- Para configurar las alertas de telemetría, debe asegurarse de que la configuración de las reglas de alerta existentes se actualiza para asignarse al nuevo servidor. Para más información sobre reglas de alerta, consulte Utilizar el Azure Portal para configurar alertas sobre métricas para Azure Database for PostgreSQL - Servidor flexible.
Importante
Puede restaurar los servidores eliminados. Si quiere eliminar el servidor, puede seguir nuestra guía Restaurar una base de datos de Azure anulada - Azure Database for PostgreSQL: servidor flexible para recuperarla. Use el bloqueo de recursos de Azure para evitar la eliminación accidental del servidor.