Creación de conjuntos de datos de Azure Machine Learning en Azure Open Datasets
En este artículo, aprenderá a incorporar datos de enriquecimiento mantenidos en sus experimentos de aprendizaje automático locales o remotos con conjuntos de datos de Azure Machine Learning y Azure Open Datasets.
Con un conjunto de datos de Azure Machine Learning, creará una referencia a la ubicación del origen de datos, junto con una copia de sus metadatos. Dado que los conjuntos de datos se evalúan de forma diferida y los datos permanecen en su ubicación existente, usted:
- No se arriesgará de forma no intencionada cambiando sus orígenes de datos originales.
- No generar ningún costo de almacenamiento adicional.
- Mejorará las velocidades de rendimiento del flujo de trabajo de ML.
Para obtener más información sobre dónde encajan los conjuntos de datos en el flujo de trabajo general de acceso a datos de Azure Machine Learning, visite el artículo Datos de acceso seguro.
Azure Open Datasets son conjuntos de datos públicos mantenidos que agregan características de escenarios específicos con el fin de enriquecer sus soluciones predictivas y mejorar la precisión de esas soluciones. Visite el recurso del catálogo de Open Datasets para encontrar los datos de dominio público que pueden ayudarle a entrenar modelos de aprendizaje automático, por ejemplo:
- Salud y genómica
- Mano de obra y economía
- Población y seguridad
- Conjuntos de datos complementarios y comunes
- Transporte
Open Datasets se hospeda en la nube en Microsoft Azure. Tanto el SDK de Python de Azure Machine Learning como Estudio de Azure Machine Learning lo incluyen.
Requisitos previos
Necesita:
Suscripción a Azure. Si no tiene una, cree una cuenta gratuita antes de empezar. Pruebe la versión gratuita o de pago de Azure Machine Learning.
El SDK de Azure Machine Learning para Python instalado, que incluye el paquete
azureml-datasets.- Cree una instancia de proceso de Azure Machine Learning, un entorno de desarrollo completamente configurado y administrado que incluya cuadernos integrados y el SDK ya instalado.
OR
- Trabaje en su propio entorno de Python e instale el SDK con estas instrucciones.
Nota:
Algunas clases Dataset tienen dependencias del paquete azureml dataprep. Este paquete solo es compatible con Python de 64 bits. Para los usuarios de Linux, estas clases solo se admiten en las siguientes distribuciones de Linux:
- Debian (8, 9)
- Fedora (27, 28)
- Red Hat Enterprise Linux (7, 8)
- Ubuntu (14.04, 16.04, 18.04)
Creación de conjuntos de datos con el SDK
Para crear conjuntos de datos de Azure Machine Learning mediante clases de Azure Open Datasets en el SDK de Python, asegúrese de instalar el paquete con pip install azureml-opendatasets. En el SDK, la clase de cada conjunto de datos discreto representa esa clase y algunas clases están disponibles como un tipo de datos FileDataset de Azure Machine Learning, un tipo de datos TabularDataset de Azure Machine Learning o ambos. Vea la documentación de referencia para obtener una lista completa de clases opendatasets.
Puede recuperar determinadas clases opendatasets como recursos TabularDataset o FileDataset. Después, puede manipular o descargar los archivos directamente. Otras clases solo pueden recuperar el conjunto de datos con el uso de las funciones get_tabular_dataset() o get_file_dataset() de la clase Dataset en el SDK de Python.
Este código muestra que la clase opendatasets de MNIST puede devolver TabularDataset o FileDataset:
from azureml.core import Dataset
from azureml.opendatasets import MNIST
# MNIST class can return either TabularDataset or FileDataset
tabular_dataset = MNIST.get_tabular_dataset()
file_dataset = MNIST.get_file_dataset()
En este ejemplo, la clase opendatasets de Diabetes solo está disponible como TabularDataset. Esto requiere el uso de get_tabular_dataset().
from azureml.opendatasets import Diabetes
from azureml.core import Dataset
# Diabetes class can return ONLY TabularDataset and must be called from the static function
diabetes_tabular = Diabetes.get_tabular_dataset()
Registro de conjuntos de datos
Registre un conjunto de datos de Azure Machine Learning con el área de trabajo, con el fin de que pueda compartir el conjunto de datos con otros usuarios y reutilizarlo en varios experimentos en el área de trabajo. Cuando se registra un conjunto de datos de Azure Machine Learning creado desde Open Datasets, los datos no se descargan inmediatamente, pero se tendrá acceso a ellos más adelante (durante el entrenamiento, por ejemplo) cuando se soliciten desde una ubicación de almacenamiento central.
Para registrar sus conjuntos de datos con un área de trabajo, use el método register().
titanic_ds = titanic_ds.register(workspace=workspace,
name='titanic_ds',
description='titanic training data')
Creación de conjuntos de datos con Studio
También puede crear conjuntos de datos de Azure Machine Learning desde Azure Open Datasets con Estudio de Azure Machine Learning. Esta interfaz web consolidada incluye herramientas de aprendizaje automático para realizar escenarios de ciencia de datos para los profesionales de ciencia de datos con conocimientos de todos los niveles.
Nota:
Los conjuntos de datos creados mediante Azure Machine Learning Studio se registran automáticamente en el área de trabajo.
En el área de trabajo, seleccione Datos en el panel de navegación izquierdo. En la pestaña Recursos de datos, seleccione Crear, como se muestra en este recorte de pantalla:

En la pantalla siguiente, agregue un nombre y una descripción opcional para el nuevo recurso de datos. Después, seleccione Tabular en la lista desplegable Tipo, como se muestra en este recorte de pantalla:

En la pantalla siguiente, seleccione Desde Azure Open Datasets y, después, seleccione Siguiente, como se muestra en este recorte de pantalla:

En la pantalla siguiente, seleccione un conjunto de datos disponible de Azure Open Datasets. En este recorte de pantalla, hemos seleccionado el conjunto de datos Datos de seguridad de San Francisco:
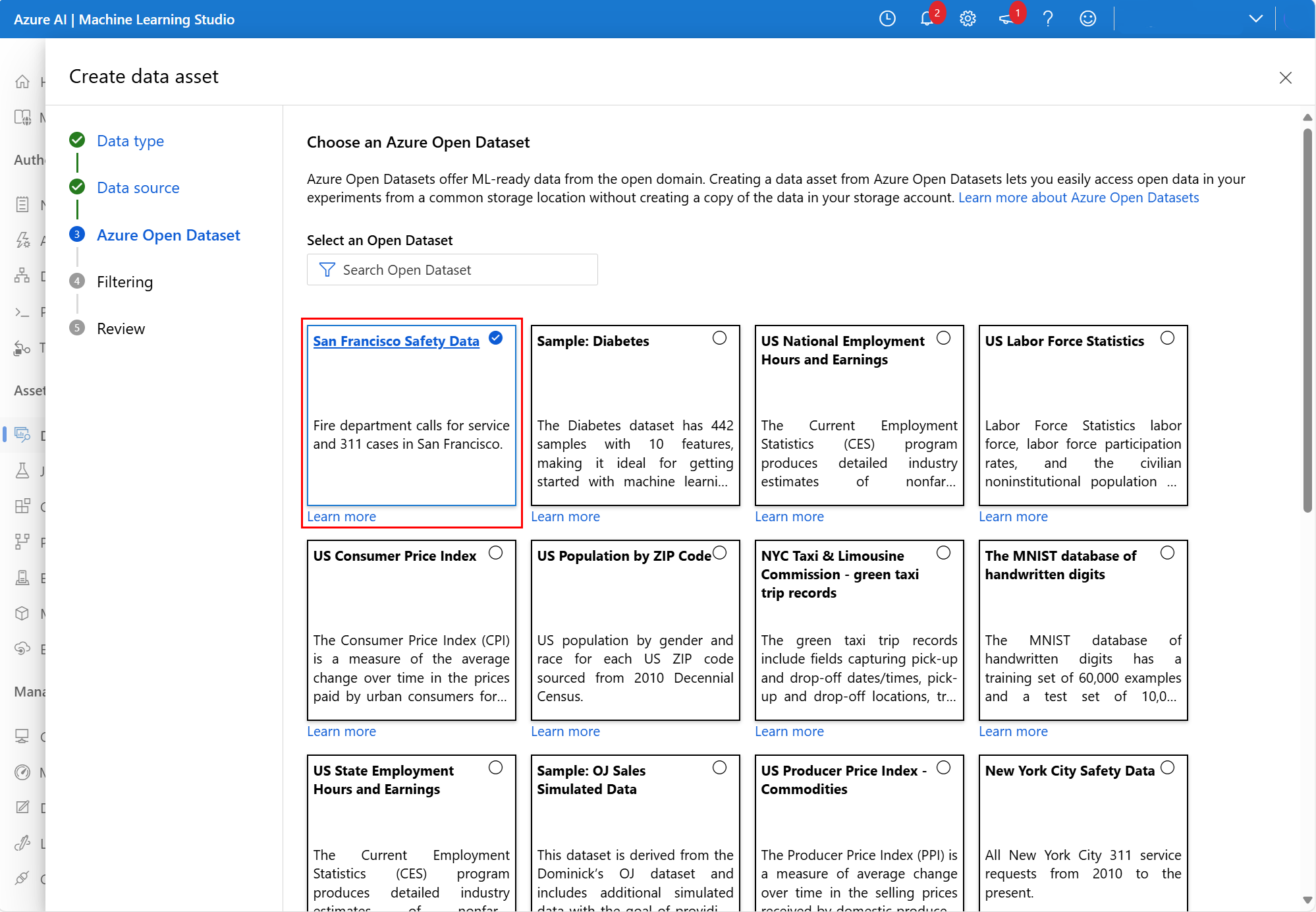
Desplácese hacia abajo si es necesario y seleccione Siguiente, como se muestra en este recorte de pantalla:
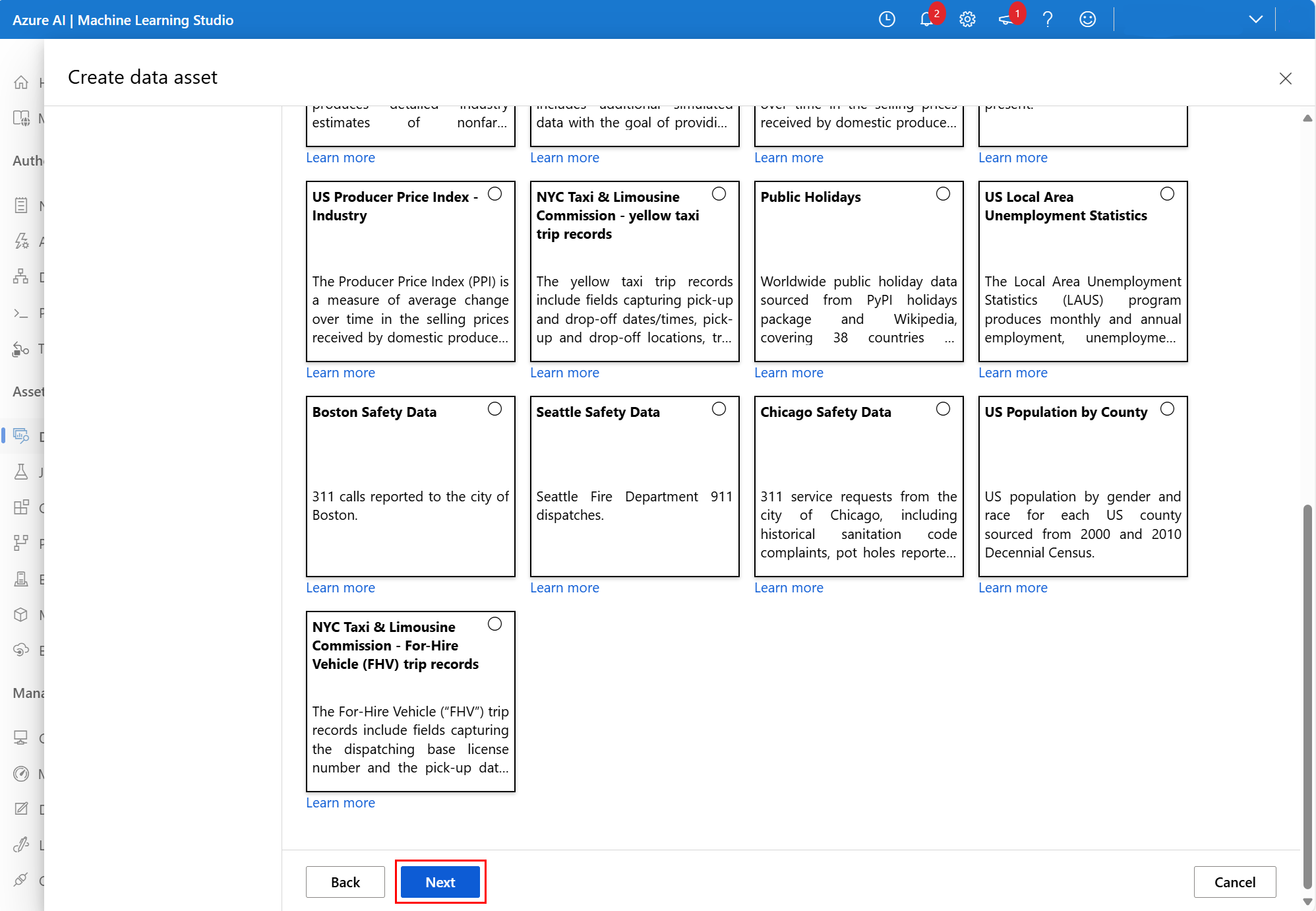
Opcionalmente, filtre los datos con los filtros disponibles, adecuados para el conjunto de datos elegido. Para el conjunto de datos Datos de seguridad de San Francisco, establecemos el intervalo de fechas filtrado entre una fecha de inicio el 1 de julio de 2024 y el 17 de julio de 2024. Seleccione Siguiente, como se muestra en este recorte de pantalla:

En la siguiente pantalla, revise la configuración del nuevo recurso de datos y realice los cambios necesarios. Cuando le parezca bien, seleccione Crear como se muestra en este recorte de pantalla:
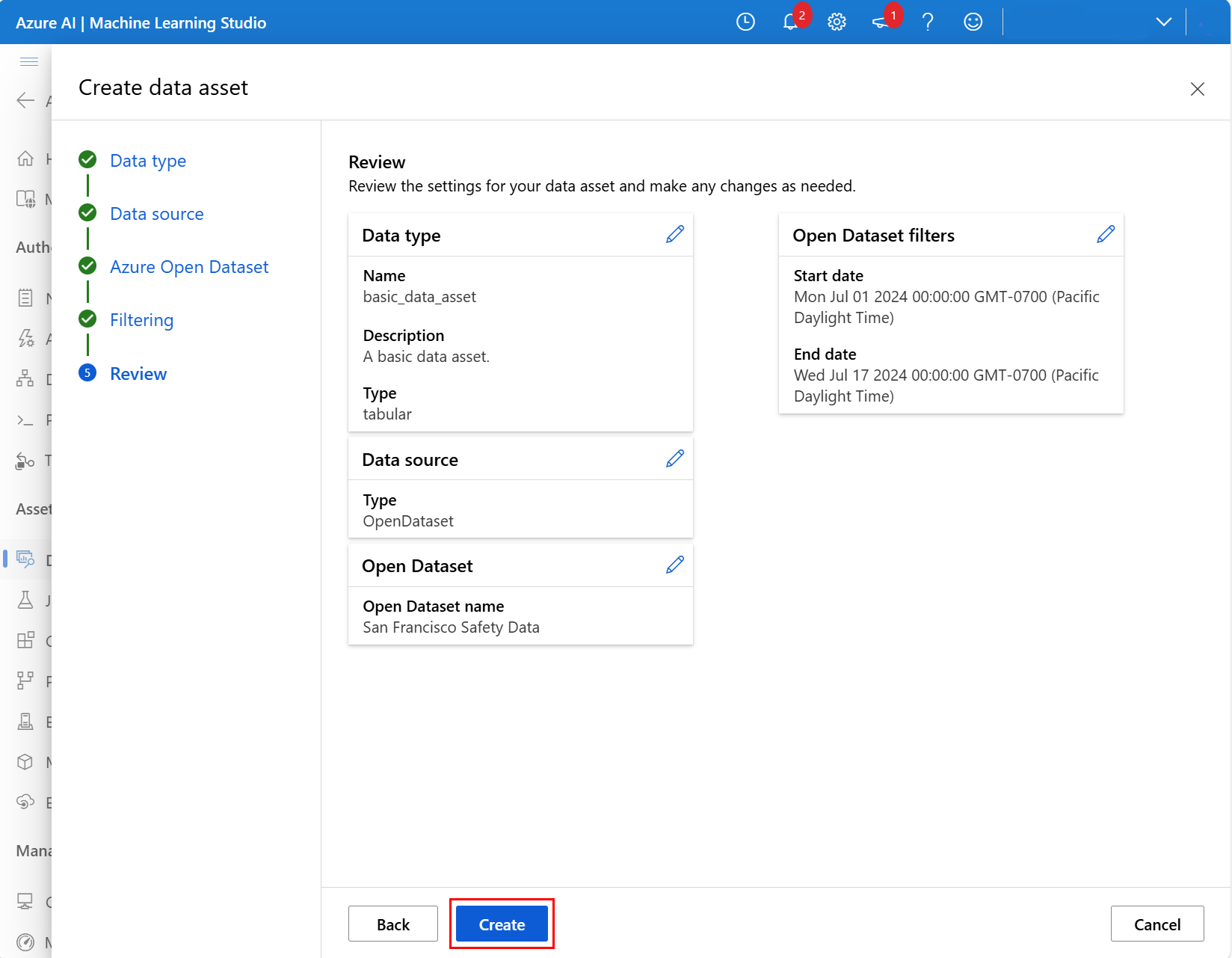
Para obtener más información sobre las descripciones de campo y los intervalos de fechas para el conjunto de datos Datos de seguridad de San Francisco, visite el recurso Datos de seguridad de San Francisco. Para obtener más información sobre otros conjuntos de datos, visite el recurso del catálogo de Azure Open Datasets.







El conjunto de valores ahora está disponible en su área de trabajo, en Conjunto de datos. Puede usarlo de la misma manera que otros conjuntos de datos que ha creado.
Acceso a los conjuntos de datos de los experimentos
Use sus conjuntos de datos en los experimentos de aprendizaje automático para entrenar modelos de aprendizaje automático. Para más información, consulte Más información sobre cómo entrenar con conjuntos de datos.
Cuadernos de ejemplo
Puede encontrar ejemplos y demostraciones de la funcionalidad de Open Datasets en estos cuadernos de ejemplo.