Tutorial 1: Desarrollo y registro de un conjunto de características con el almacén de características gestionado
Esta serie de tutoriales muestra cómo las características integran a la perfección todas las fases del ciclo de vida del aprendizaje automático: creación de prototipos, entrenamiento y operacionalización.
Puede usar el almacén de características administradas de Azure Machine Learning para descubrir, crear y operacionalizar características. El ciclo de vida del aprendizaje automático incluye la fase de creación de prototipos, en la que puede experimentar con varias características. También implica la fase de puesta en funcionamiento, en la que se implementan los modelos y los pasos de inferencia buscan datos de características. Las características sirven como tejido de conexión en el ciclo de vida del aprendizaje automático. Para obtener más información sobre los conceptos básicos del almacén de características gestionado, vea ¿Qué es el almacén de características gestionado? y Comprender las entidades de nivel superior en el almacén de características gestionado.
En este tutorial se describe cómo crear una especificación de conjunto de características con transformaciones personalizadas. Después, se usa ese conjunto de características para generar datos de entrenamiento, habilitar la materialización y realizar un reposición. La materialización calcula los valores de las características de una ventana de características determinada y, después, los almacena en un almacén de materialización. Después, todas las consultas de características pueden usar los valores del almacén de materialización.
Sin materialización, una consulta de conjunto de características aplica las transformaciones al origen sobre la marcha para conocer el proceso de las características antes de que devuelva los valores. Este proceso funciona bien para la fase de creación de prototipos. Pero para operaciones de entrenamiento e inferencia en entornos de producción, se recomienda materializar las características a fin de lograr una mayor confiabilidad y disponibilidad.
Este tutorial es la primera parte de la serie de tutoriales sobre el almacén de características gestionado. Aquí, aprenderá a:
- Creación de un nuevo recurso de almacén de características mínimo
- Desarrollo y prueba local de un conjunto de características con funcionalidad de transformación de características
- Registro de una entidad de almacén de características con el almacén de características
- Registro del conjunto de características que ha desarrollado con el almacén de características
- Genere un DataFrame de entrenamiento de ejemplo mediante las características que ha creado.
- Habilite la materialización sin conexión en los conjuntos de características y reponga los datos de las características.
Esta serie de tutoriales tiene dos pistas:
- La pista solo del SDK usa SDK de Python. Elija esta pista para el desarrollo y la implementación puramente basados en Python.
- El SDK y la pista de la CLI usan el SDK de Python solo para el desarrollo y las pruebas del conjunto de características, y usa la CLI para las operaciones CRUD (creación, lectura, actualización y eliminación). Esta pista es útil en escenarios de integración continua y entrega continua (CI/CD) o GitOps, donde se prefiere la CLI o YAML.
Requisitos previos
Antes de continuar con este tutorial, asegúrese de cumplir estos requisitos previos:
Un área de trabajo de Azure Machine Learning. Para obtener más información sobre la creación de áreas de trabajo, vea Inicio rápido: Crear recursos de área de trabajo .
En la cuenta de usuario, el rol Propietario del grupo de recursos donde se crea el almacén de características.
Si elige usar un nuevo grupo de recursos para este tutorial, puede eliminar fácilmente todos los recursos eliminando el grupo de recursos.
Preparar el entorno del notebook
En este tutorial, se usa el cuaderno de Spark de Azure Machine Learning para el desarrollo.
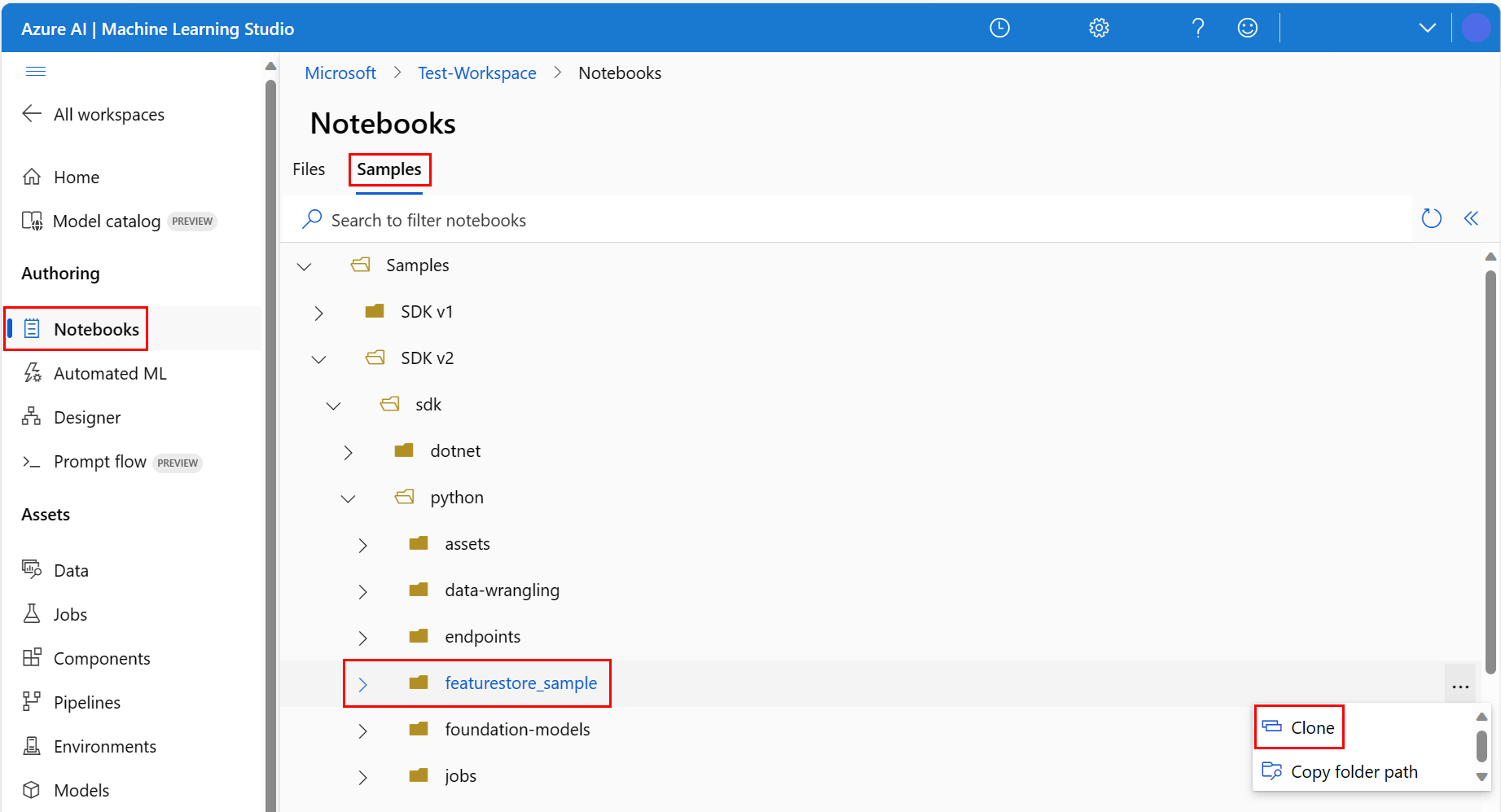
En el entorno de Azure Machine Learning studio, seleccione Notebooks en el panel izquierdo y, a continuación, seleccione la pestaña Samples.
Vaya al directorio featurestore_sample (seleccioneSamples> SDK v2 >sdk >python>featurestore_sample ) y, a continuación, seleccione Clonar.
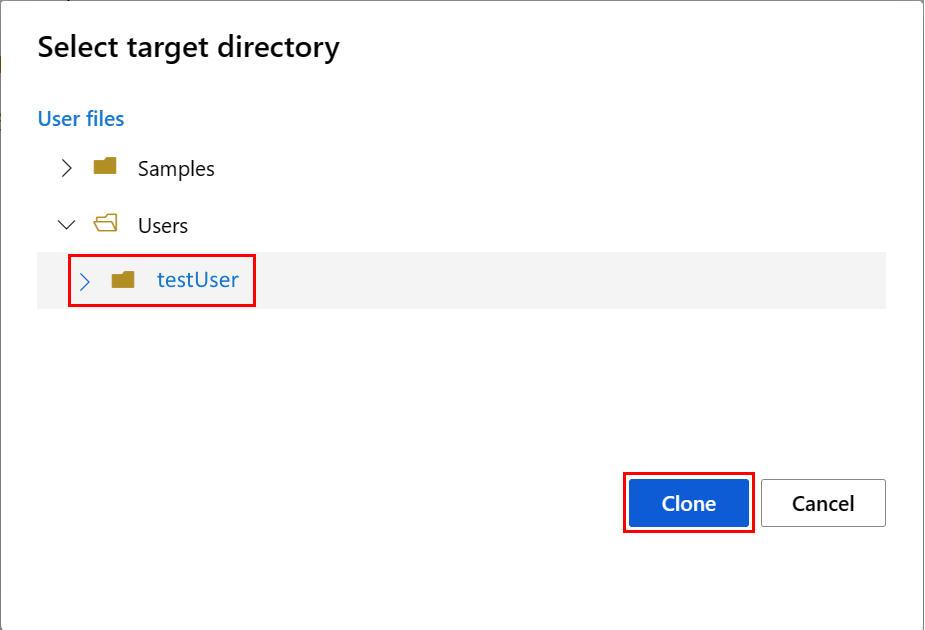
El panel Seleccionar directorio de destino se abre a continuación. Seleccione el directorio Usuarios, después el nombre de usuarioy, por último, seleccione Clonar.
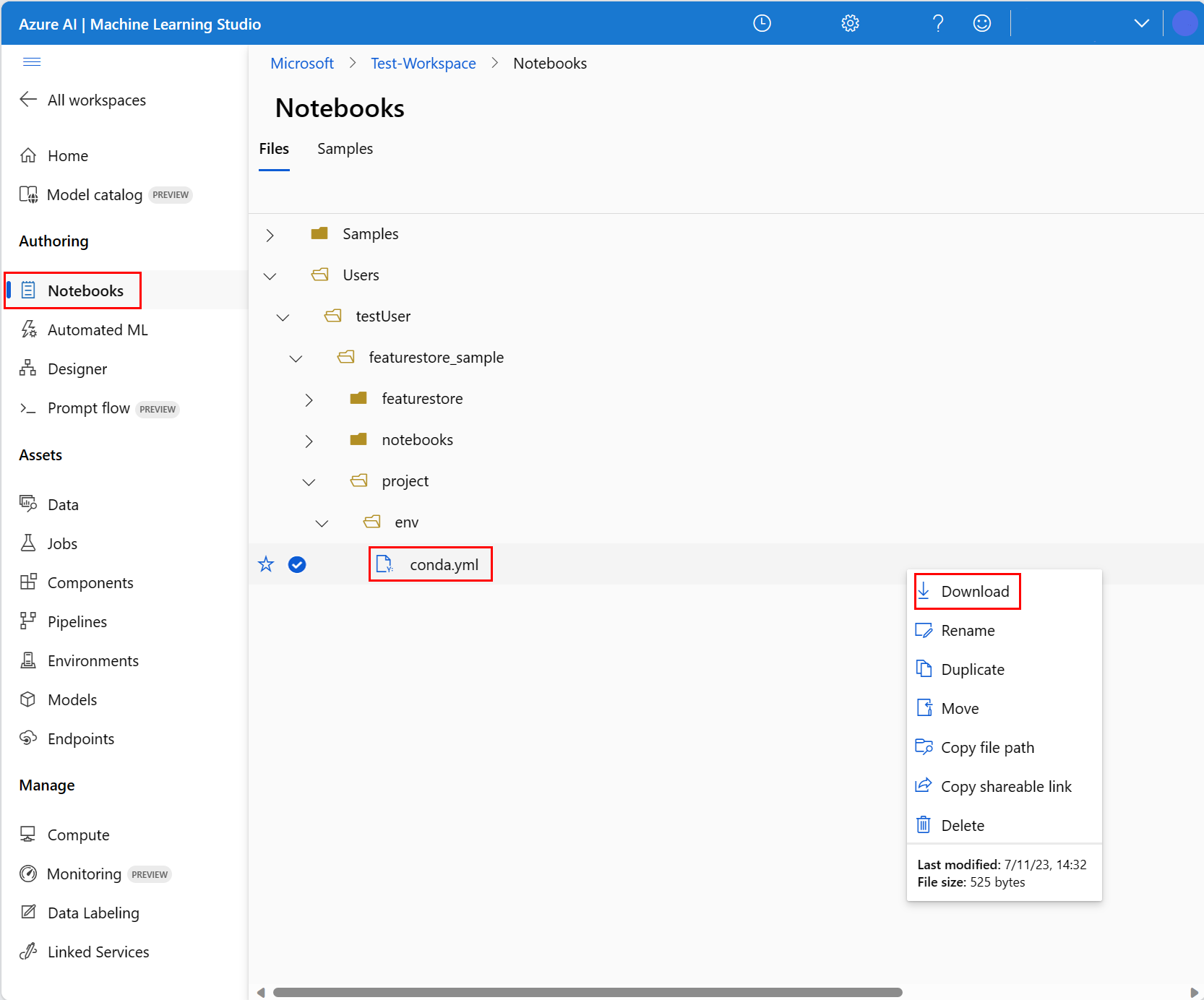
Para configurar el entorno del notebook, debe cargar el archivo conda.yml:
- Seleccione Notebooks en el panel izquierdo y, a continuación, seleccione la pestaña Archivos.
- Vaya al directorio env (seleccione Usuarios>el_nombre_de_usuario>featurestore_sample>project>env) y, después, seleccione el archivo conda.yml.
- Seleccione Descargar.
- Seleccione Serverless Spark Compute en el menú desplegable Compute de la navegación superior. Esta operación podría tardar uno o dos minutos. Espere a que la barra de estado de la parte superior muestre la opción Configurar sesión.
- Seleccione Configurar sesión en el panel de navegación superior.
- Lista de paquetes de Python.
- Seleccione Cargar archivos de Conda.
- Seleccione el archivo
conda.ymlque ha descargado en el dispositivo local. - (Opcional) Aumente el tiempo de espera de la sesión (tiempo de inactividad en minutos) para reducir el tiempo de arranque del clúster spark sin servidor.
En el entorno de Azure Machine Learning, abra el notebook y, a continuación, seleccioneConfigurar sesión .
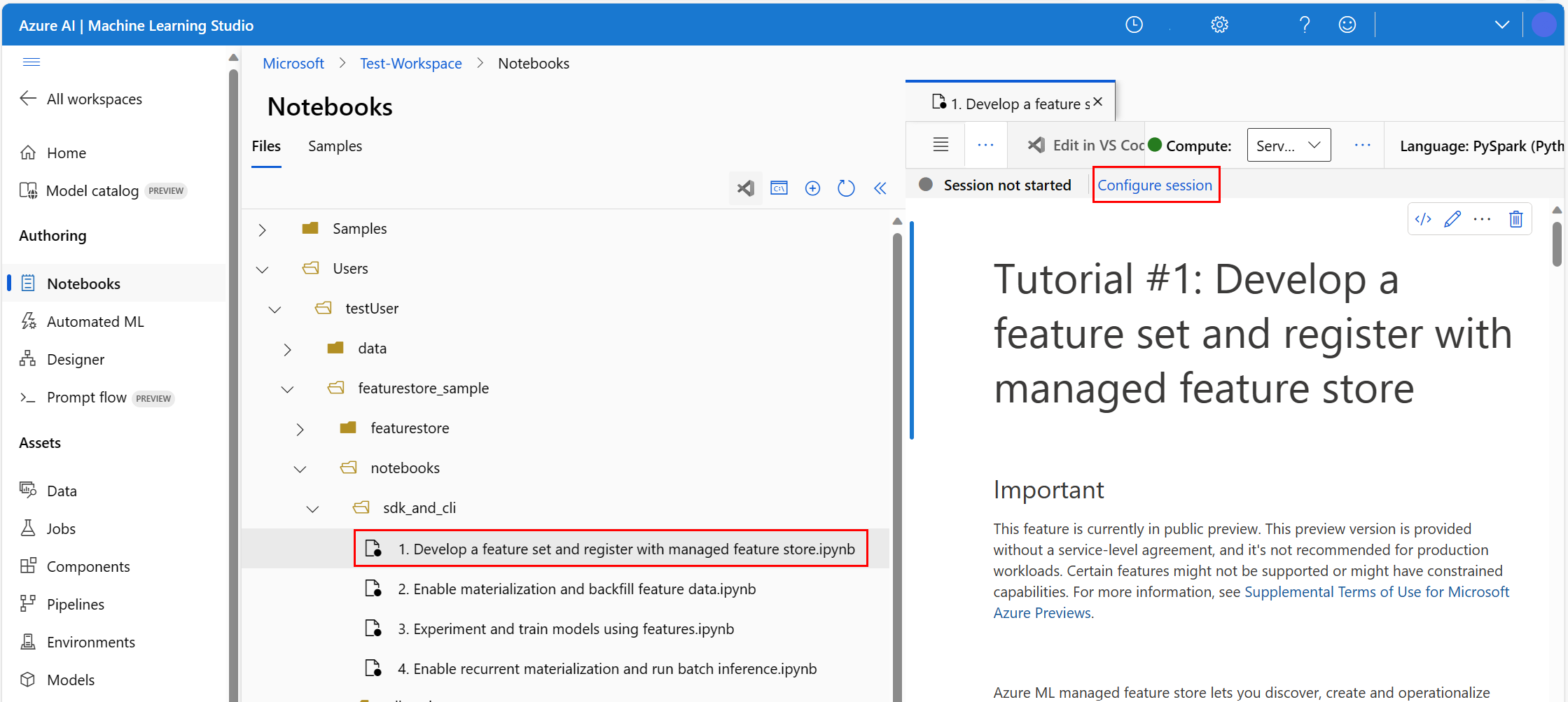
En el panel Configurar sesión, seleccione Paquetes de Python.
Cargue el archivo de Conda:
- En la pestaña Paquetes de Python, seleccione Cargar archivo de Conda.
- Vaya al directorio que hospeda el archivo de Conda.
- Seleccione conda.yml y, a continuación, seleccione Abrir.
Seleccione Aplicar.






Iniciar la sesión de Spark
# Run this cell to start the spark session (any code block will start the session ). This can take around 10 mins.
print("start spark session")Configuración del directorio raíz para los ejemplos
import os
# Please update <your_user_alias> below (or any custom directory you uploaded the samples to).
# You can find the name from the directory structure in the left navigation panel.
root_dir = "./Users/<your_user_alias>/featurestore_sample"
if os.path.isdir(root_dir):
print("The folder exists.")
else:
print("The folder does not exist. Please create or fix the path")Configuración de la CLI
No aplicable.
Nota:
Se usa un almacén de características para reutilizar características en todos los proyectos. Usará un área de trabajo del proyecto (un área de trabajo de Azure Machine Learning) para entrenar modelos y la inferencia, aprovechando las características de los almacenes de características. Muchas áreas de trabajo de proyecto pueden compartir y reutilizar el mismo almacén de características.
En este tutorial, se usan dos SDK:
SDK CRUD del almacén de características
Use el mismo
MLClient(nombre del paqueteazure-ai-ml) SDK que usa con el área de trabajo de Azure Machine Learning. El almacén de características se implementa como un tipo de área de trabajo. Como resultado, este SDK se usa para las operaciones CRUD para el almacén de características, el conjunto de características y la entidad del almacén de características.SDK principal del almacén de características
Este SDK (
azureml-featurestore) es para el desarrollo y consumo del conjunto de características. Los pasos posteriores de este tutorial describen estas operaciones:- Desarrolle una especificación de conjunto de características.
- Recuperar datos de características.
- Enumera u obtiene un conjunto de características registrado.
- Generar y resolver especificaciones de recuperación de características.
- Generación de datos de entrenamiento e inferencia mediante combinaciones a un momento dado
Para este tutorial no se necesita la instalación explícita de esos SDK, porque las instrucciones anteriores de conda.yml cubren este paso.
Creación de un almacén de características mínimas
Establezca parámetros de almacén de características, incluidos el nombre, la ubicación y otros valores.
# We use the subscription, resource group, region of this active project workspace. # You can optionally replace them to create the resources in a different subsciprtion/resource group, or use existing resources. import os featurestore_name = "<FEATURESTORE_NAME>" featurestore_location = "eastus" featurestore_subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"] featurestore_resource_group_name = os.environ["AZUREML_ARM_RESOURCEGROUP"]Creación del almacén de características
from azure.ai.ml import MLClient from azure.ai.ml.entities import ( FeatureStore, FeatureStoreEntity, FeatureSet, ) from azure.ai.ml.identity import AzureMLOnBehalfOfCredential ml_client = MLClient( AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, ) fs = FeatureStore(name=featurestore_name, location=featurestore_location) # wait for feature store creation fs_poller = ml_client.feature_stores.begin_create(fs) print(fs_poller.result())Inicialice un cliente del SDK principal del almacén de características para Azure Machine Learning.
Como se explicó anteriormente en este tutorial, el cliente del SDK básico del almacén de características se usa para desarrollar y consumir características.
# feature store client from azureml.featurestore import FeatureStoreClient from azure.ai.ml.identity import AzureMLOnBehalfOfCredential featurestore = FeatureStoreClient( credential=AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, name=featurestore_name, )Conceda el rol "Científico de datos de Azure Machine Learning" en el almacén de características a su identidad de usuario. Obtenga el valor del id. de objeto de Microsoft Entra de Azure Portal como se describe en Búsqueda del id. de objeto de usuario.
Asigne el rol Científico de datos de AzureML a la identidad de usuario para que pueda crear recursos en el área de trabajo del almacén de características. Es posible que los permisos necesiten algún tiempo para propagarse.
Para más información sobre el control de acceso, vea Administración del control de acceso para el almacén de características gestionado.
your_aad_objectid = "<USER_AAD_OBJECTID>" !az role assignment create --role "AzureML Data Scientist" --assignee-object-id $your_aad_objectid --assignee-principal-type User --scope $feature_store_arm_id
Prototipo y desarrollo de un conjunto de características
En estos pasos, creará un conjunto de características denominado transactions que tiene características graduales basadas en agregados de ventana:
Explore los datos de
transactionsorigen.Este cuaderno usa datos de ejemplo hospedados en un contenedor de blobs accesible públicamente. Se puede leer en Spark solo mediante un controlador
wasbs. Al crear conjuntos de características con sus propios datos de origen, hospédelos en una cuenta de Azure Data Lake Storage Gen2 y use un controladorabfssen la ruta de acceso de datos.# remove the "." in the roor directory path as we need to generate absolute path to read from spark transactions_source_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet" transactions_src_df = spark.read.parquet(transactions_source_data_path) display(transactions_src_df.head(5)) # Note: display(training_df.head(5)) displays the timestamp column in a different format. You can can call transactions_src_df.show() to see correctly formatted valueDesarrollo del conjunto de características de forma local
Una especificación de conjunto de características es una definición de conjunto de características independiente que se puede desarrollar y probar localmente. Aquí, se crean estas características de agregado de ventana móvil:
transactions three-day counttransactions amount three-day sumtransactions amount three-day avgtransactions seven-day counttransactions amount seven-day sumtransactions amount seven-day avg
Revise el archivo de código de transformación de características: featurestore/featuresets/transactions/transformation_code/transaction_transform.py. Observe la agregación móvil definida para las características. Se trata de un transformador de Spark.
Para más información sobre el conjunto de características y las transformaciones, vea ¿Qué es almacén de características gestionado?.
from azureml.featurestore import create_feature_set_spec from azureml.featurestore.contracts import ( DateTimeOffset, TransformationCode, Column, ColumnType, SourceType, TimestampColumn, ) from azureml.featurestore.feature_source import ParquetFeatureSource transactions_featureset_code_path = ( root_dir + "/featurestore/featuresets/transactions/transformation_code" ) transactions_featureset_spec = create_feature_set_spec( source=ParquetFeatureSource( path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet", timestamp_column=TimestampColumn(name="timestamp"), source_delay=DateTimeOffset(days=0, hours=0, minutes=20), ), feature_transformation=TransformationCode( path=transactions_featureset_code_path, transformer_class="transaction_transform.TransactionFeatureTransformer", ), index_columns=[Column(name="accountID", type=ColumnType.string)], source_lookback=DateTimeOffset(days=7, hours=0, minutes=0), temporal_join_lookback=DateTimeOffset(days=1, hours=0, minutes=0), infer_schema=True, )Exportar como una especificación de conjunto de características
Para registrar la especificación de conjunto de características con el almacén de características, debe guardar la especificación de conjunto de características en un formato específico.
Revise la especificación del conjunto de características generado
transactions. Abra este archivo desde el árbol de archivos para ver la especificación: featurestore/featuresets/accounts/spec/FeaturesetSpec.yaml.La especificación contiene estos elementos:
source: Una referencia a un recurso de almacenamiento. En este caso, es un archivo Parquet en un recurso de almacenamiento de blobs.features: Lista de características y sus tipos de datos. Si proporciona código de transformación, el código debe devolver un elemento DataFrame que se asigne a las características y los tipos de datos.index_columns: Claves de combinación necesarias para acceder a los valores del conjunto de características
Para obtener más información sobre la especificación, vea Descripción de las entidades de nivel superior en el almacén de características gestionado y el esquema YAML del conjunto de características de la CLI (v2).
Conservar la especificación del conjunto de características ofrece otra ventaja: la especificación del conjunto de características puede controlarse en origen.
import os # Create a new folder to dump the feature set specification. transactions_featureset_spec_folder = ( root_dir + "/featurestore/featuresets/transactions/spec" ) # Check if the folder exists, create one if it does not exist. if not os.path.exists(transactions_featureset_spec_folder): os.makedirs(transactions_featureset_spec_folder) transactions_featureset_spec.dump(transactions_featureset_spec_folder, overwrite=True)
Registro de la entidad del almacén de características
Como procedimiento recomendado, las entidades ayudan a aplicar el uso de la misma definición de clave de combinación entre conjuntos de características que usan las mismas entidades lógicas. Algunos ejemplos de entidades incluyen cuentas y clientes. Normalmente, las entidades se crean una vez y luego se reutilizan en distintos conjuntos de características. Para más información, vea Descripción de las entidades de nivel superior en almacén de características gestionado.
Inicializar el cliente CRUD del almacén de características
Como se explicó anteriormente en este tutorial,
MLClientse usa para crear, leer, actualizar y eliminar un recurso de almacén de características. El ejemplo de celda de código de cuaderno que se muestra aquí busca el almacén de características que se creó en un paso anterior. Aquí, no puede reutilizar el mismoml_clientvalor que usó anteriormente en este tutorial, porque tiene un alcance en el nivel del grupo de recursos. El alcance adecuado es un requisito previo para la creación del almacén de características.En este ejemplo de código, el cliente tiene como ámbito el nivel de almacén de características.
# MLClient for feature store. fs_client = MLClient( AzureMLOnBehalfOfCredential(), featurestore_subscription_id, featurestore_resource_group_name, featurestore_name, )Registro de la entidad
accountcon el almacén de característicasCree una
accountentidad que tenga la clave de combinaciónaccountIDde tipostring.from azure.ai.ml.entities import DataColumn, DataColumnType account_entity_config = FeatureStoreEntity( name="account", version="1", index_columns=[DataColumn(name="accountID", type=DataColumnType.STRING)], stage="Development", description="This entity represents user account index key accountID.", tags={"data_typ": "nonPII"}, ) poller = fs_client.feature_store_entities.begin_create_or_update(account_entity_config) print(poller.result())
Registro del conjunto de características de transacciones con el almacén de características
Use este código para registrar un recurso de conjunto de características con el almacén de características. Después, puede reutilizar ese recurso y compartirlo fácilmente. El registro de un recurso de conjunto de características ofrece funcionalidades administradas, incluido el control de versiones y la materialización. En los pasos posteriores de esta serie de tutoriales se tratan las funcionalidades administradas.
from azure.ai.ml.entities import FeatureSetSpecification
transaction_fset_config = FeatureSet(
name="transactions",
version="1",
description="7-day and 3-day rolling aggregation of transactions featureset",
entities=[f"azureml:account:1"],
stage="Development",
specification=FeatureSetSpecification(path=transactions_featureset_spec_folder),
tags={"data_type": "nonPII"},
)
poller = fs_client.feature_sets.begin_create_or_update(transaction_fset_config)
print(poller.result())Exploración de la interfaz de usuario del almacén de características
La creación y las actualizaciones de recursos del almacén de características solo se pueden realizar a través del SDK y la CLI. Puede usar la interfaz de usuario para buscar o explorar el almacén de características:
- Abra la página de aterrizaje global de Azure Machine Learning.
- Seleccione Almacenes de características en el panel izquierdo.
- En esta lista de almacenes de características accesibles, seleccione el almacén de características que creó anteriormente en este tutorial.
Concesión de acceso al rol lector de datos de blobs de almacenamiento a la cuenta de usuario en el almacén sin conexión
Se debe asignar el rol Lector de datos de blobs de almacenamiento a la cuenta de usuario en el almacén sin conexión. Esto garantiza que la cuenta de usuario pueda leer los datos de características materializados desde el almacén de materialización sin conexión.
Obtenga el valor del id. de objeto de Microsoft Entra de Azure Portal como se describe en Búsqueda del id. de objeto de usuario.
Obtenga información sobre el almacén de materialización sin conexión de la página Información general del almacén de características en la interfaz de usuario del almacén de características. Puede encontrar los valores del identificador de suscripción de la cuenta de almacenamiento, el nombre del grupo de recursos de la cuenta de almacenamiento y el nombre de la cuenta de almacenamiento para el almacén de materialización sin conexión en la tarjeta Almacén de materialización sin conexión.
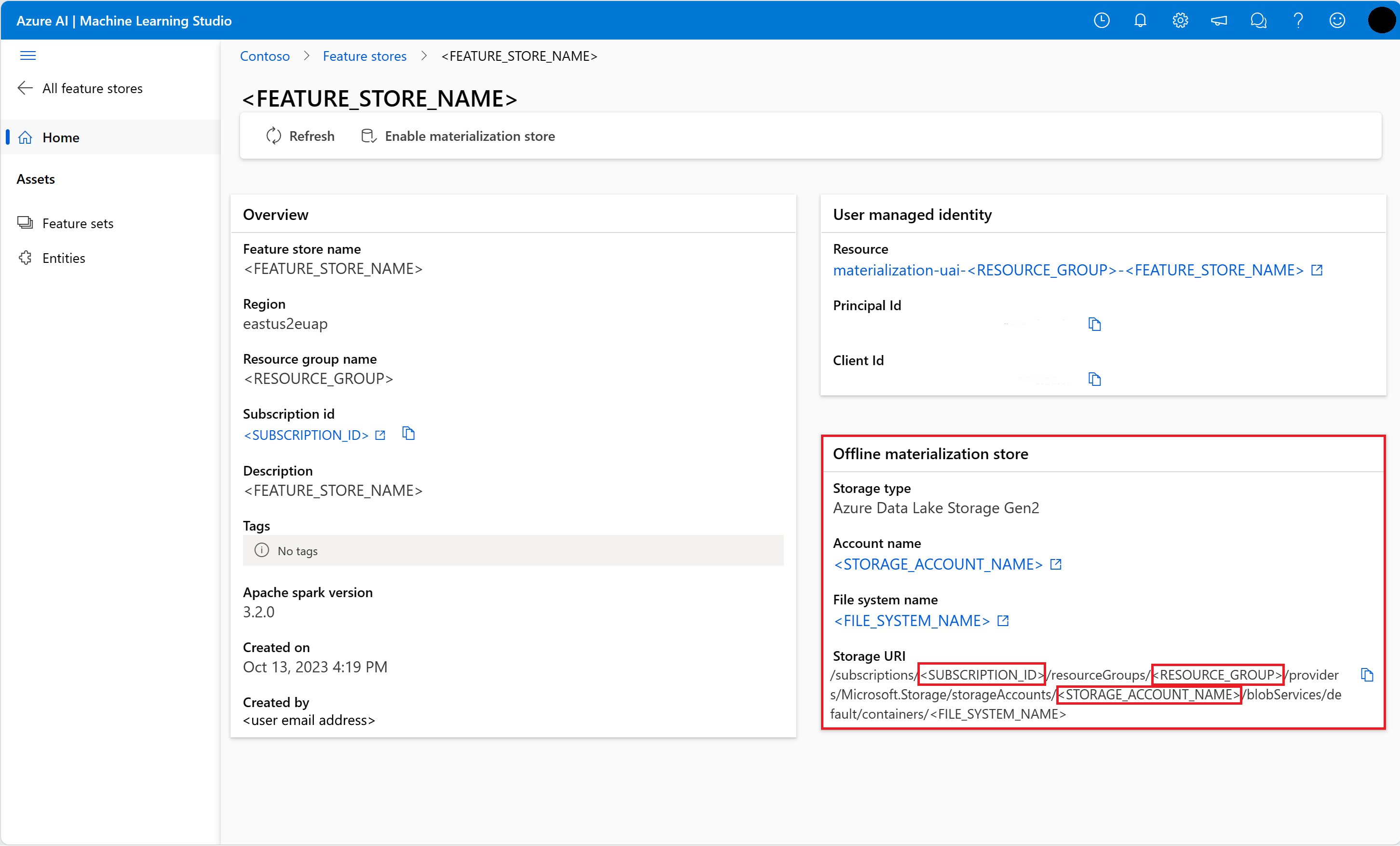
Para más información sobre el control de acceso, vea Administración del control de acceso para el almacén de características gestionado.
Ejecute esta celda de código para la asignación de roles. Es posible que los permisos necesiten algún tiempo para propagarse.
# This utility function is created for ease of use in the docs tutorials. It uses standard azure API's. # You can optionally inspect it `featurestore/setup/setup_storage_uai.py`. import sys sys.path.insert(0, root_dir + "/featurestore/setup") from setup_storage_uai import grant_user_aad_storage_data_reader_role your_aad_objectid = "<USER_AAD_OBJECTID>" storage_subscription_id = "<SUBSCRIPTION_ID>" storage_resource_group_name = "<RESOURCE_GROUP>" storage_account_name = "<STORAGE_ACCOUNT_NAME>" grant_user_aad_storage_data_reader_role( AzureMLOnBehalfOfCredential(), your_aad_objectid, storage_subscription_id, storage_resource_group_name, storage_account_name, )

Generación de un DataFrame de datos de entrenamiento mediante el conjunto de características registrado
Carga de los datos de observación.
Los datos de observación generalmente involucran los datos principales que se usan para el entrenamiento y la inferencia. Estos datos se combinan con los datos de características para crear el recurso de datos de entrenamiento completo.
Los datos de observación son datos capturados durante el propio evento. Aquí, tiene los datos de transacción principales, que incluyen el id. de transacción, el id. de cuenta y el importe de transacción. Dado que lo usamos para el entrenamiento, también tiene la variable destino (is_fraud) adjunta.
observation_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/observation_data/train/*.parquet" observation_data_df = spark.read.parquet(observation_data_path) obs_data_timestamp_column = "timestamp" display(observation_data_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueObtención del conjunto de características registrado y enumeración de sus características
# Look up the featureset by providing a name and a version. transactions_featureset = featurestore.feature_sets.get("transactions", "1") # List its features. transactions_featureset.features# Print sample values. display(transactions_featureset.to_spark_dataframe().head(5))Seleccione las características que pasarán a formar parte de los datos de entrenamiento. A continuación, use el SDK del almacén de características para generar los datos de entrenamiento por sí mismo.
from azureml.featurestore import get_offline_features # You can select features in pythonic way. features = [ transactions_featureset.get_feature("transaction_amount_7d_sum"), transactions_featureset.get_feature("transaction_amount_7d_avg"), ] # You can also specify features in string form: featureset:version:feature. more_features = [ f"transactions:1:transaction_3d_count", f"transactions:1:transaction_amount_3d_avg", ] more_features = featurestore.resolve_feature_uri(more_features) features.extend(more_features) # Generate training dataframe by using feature data and observation data. training_df = get_offline_features( features=features, observation_data=observation_data_df, timestamp_column=obs_data_timestamp_column, ) # Ignore the message that says feature set is not materialized (materialization is optional). We will enable materialization in the subsequent part of the tutorial. display(training_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueUna combinación a un momento dado anexa las características a los datos de entrenamiento.
Habilitación de la materialización sin conexión en el conjunto de características de transactions
Una vez que se habilita la materialización del conjunto de características, puede realizar una reposición. También puede programar trabajos de materialización recurrentes. Para obtener más información, consulte el tercer tutorial de la serie.
Establezca spark.sql.shuffle.partitions en el archivo yaml según el tamaño de los datos de características
La configuración de Spark spark.sql.shuffle.partitions es un parámetro OPCIONAL que puede afectar al número de archivos de Parquet generados (por día) cuando el conjunto de características se materializa en el almacén sin conexión. El valor predeterminado para este parámetro es 200. Como procedimiento recomendado, evite la generación de muchos archivos de Parquet pequeños. Si la recuperación de características sin conexión se ralentiza después de la materialización del conjunto de características, vaya a la carpeta correspondiente en el almacén sin conexión para comprobar si el problema implica demasiados archivos de Parquet pequeños (por día) y ajuste el valor de este parámetro en consecuencia.
Nota:
Los datos de ejemplo usados en este cuaderno son pequeños. Por tanto, este parámetro se establece en 1 en el archivo featureset_asset_offline_enabled.yaml.
from azure.ai.ml.entities import (
MaterializationSettings,
MaterializationComputeResource,
)
transactions_fset_config = fs_client._featuresets.get(name="transactions", version="1")
transactions_fset_config.materialization_settings = MaterializationSettings(
offline_enabled=True,
resource=MaterializationComputeResource(instance_type="standard_e8s_v3"),
spark_configuration={
"spark.driver.cores": 4,
"spark.driver.memory": "36g",
"spark.executor.cores": 4,
"spark.executor.memory": "36g",
"spark.executor.instances": 2,
"spark.sql.shuffle.partitions": 1,
},
schedule=None,
)
fs_poller = fs_client.feature_sets.begin_create_or_update(transactions_fset_config)
print(fs_poller.result())También puede guardar el recurso de conjunto de características como un recurso YAML.
## uncomment to run
transactions_fset_config.dump(
root_dir
+ "/featurestore/featuresets/transactions/featureset_asset_offline_enabled.yaml"
)Reposición de datos para el conjunto de características de transactions
Como se ha explicado antes, la materialización implica el cálculo de los valores de características de una ventana de características y el almacenamiento de esos valores en un almacén de materialización. La materialización de características aumenta la confiabilidad y la disponibilidad de los valores calculados. Todas las consultas de características ahora usan los valores del almacén de materialización. En este paso se realiza una reposición única para una ventana de características de 18 meses.
Nota:
Es posible que tenga que determinar un valor de ventana de datos de reposición. La ventana debe coincidir con la ventana de los datos de entrenamiento. Por ejemplo, a fin de usar 18 meses de datos para el entrenamiento, debe recuperar características de 18 meses. Esto significa que debería hacer la reposición para una ventana de 18 meses.
Esta celda de código materializa los datos por estado actual Ninguno o Incompleto para la ventana de características definida.
from datetime import datetime
from azure.ai.ml.entities import DataAvailabilityStatus
st = datetime(2022, 1, 1, 0, 0, 0, 0)
et = datetime(2023, 6, 30, 0, 0, 0, 0)
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version="1",
feature_window_start_time=st,
feature_window_end_time=et,
data_status=[DataAvailabilityStatus.NONE],
)
print(poller.result().job_ids)# Get the job URL, and stream the job logs.
fs_client.jobs.stream(poller.result().job_ids[0])Sugerencia
- La columna
timestampdebe seguir el formatoyyyy-MM-ddTHH:mm:ss.fffZ. - La granularidad de
feature_window_start_timeyfeature_window_end_timese limita a segundos. Se omitirán los milisegundos proporcionados en el objetodatetime. - Solo se enviará un trabajo de materialización si los datos de la ventana de características coinciden con el valor
data_statusdefinido al enviar el trabajo de reposición.
Imprima datos de ejemplo del conjunto de características. La información de salida muestra que los datos se recuperaron del almacén de materialización. El método get_offline_features() recuperó los datos de entrenamiento e inferencia. También usa el almacén de materialización de manera predeterminada.
# Look up the feature set by providing a name and a version and display few records.
transactions_featureset = featurestore.feature_sets.get("transactions", "1")
display(transactions_featureset.to_spark_dataframe().head(5))Exploración más detallada de la materialización de características sin conexión
Puede explorar el estado de materialización de características de un conjunto de características en la interfaz de usuario Trabajos de materialización.
Abra la página de aterrizaje global de Azure Machine Learning.
Seleccione Almacenes de características en el panel izquierdo.
En esta lista de almacenes de características accesibles, seleccione el almacén de características para el que ha realizado la reposición.
Seleccione la pestaña Trabajos de materialización.
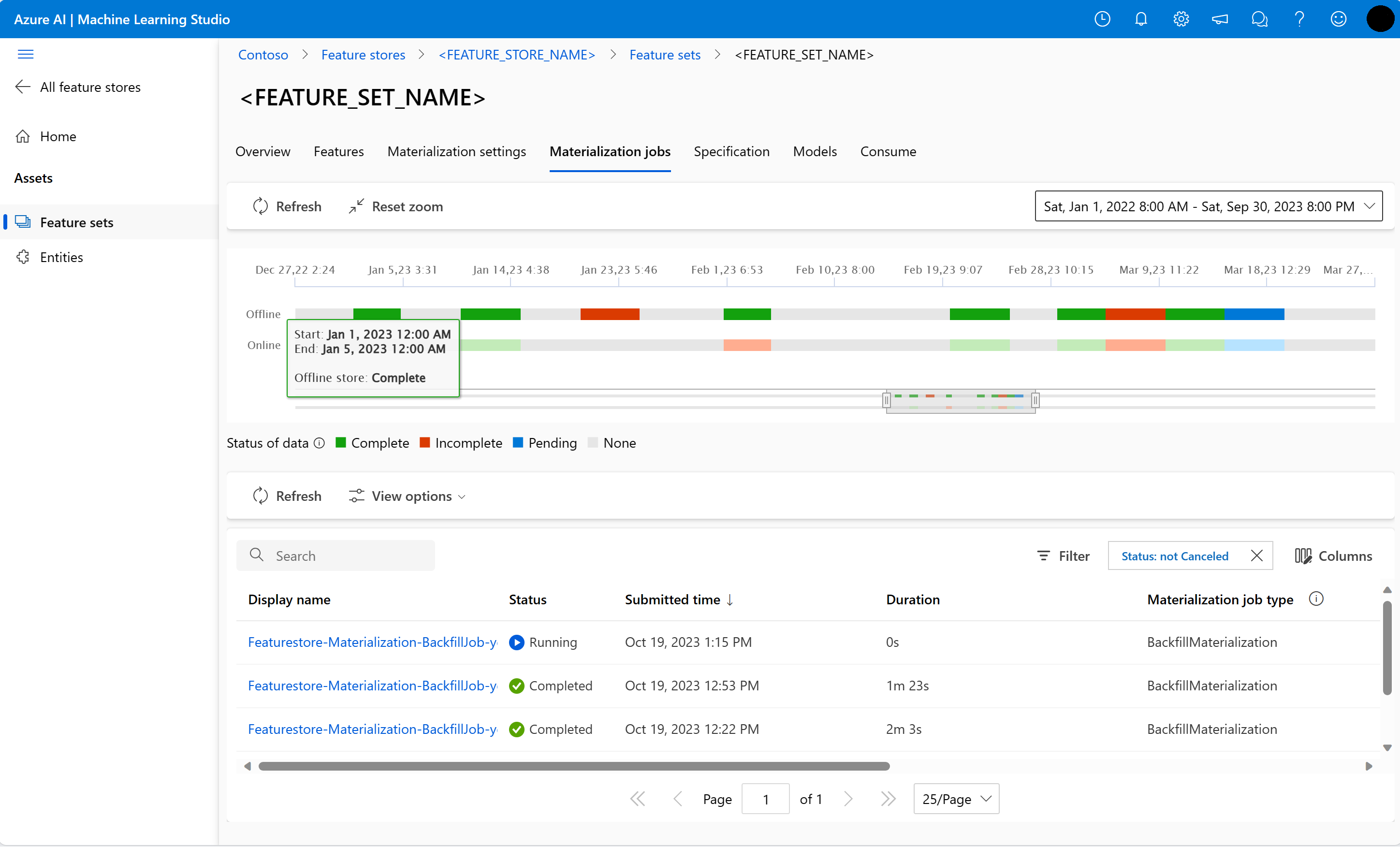

El estado de materialización de datos puede ser
- Completo (verde)
- Incompleto (rojo)
- Pendiente (azul)
- Ninguno (gris)
Un intervalo de datos representa una parte contigua de los datos con el mismo estado de materialización de datos. Por ejemplo, la instantánea anterior tiene 16 intervalos de datos en el almacén de materialización sin conexión.
Los datos pueden tener un máximo de 2000 intervalos de datos. Si los datos contienen más de 2000 intervalos de datos, cree una versión del conjunto de características.
Puede proporcionar una lista de más de un estado de datos (por ejemplo,
["None", "Incomplete"]) en un único trabajo de reposición.Durante la reposición, se envía un nuevo trabajo de materialización para cada intervalo de datos que coincida con la ventana de características definida.
Si un trabajo de materialización está pendiente, o bien se ejecuta para un intervalo de datos que todavía no se ha repuesto, no se envía un trabajo nuevo para ese intervalo de datos.
Puede reintentar un trabajo de materialización con errores.
Nota:
Para obtener el id. de trabajo de un trabajo de materialización con errores:
- Vaya a la interfaz de usuario Trabajos de materialización del conjunto de características.
- Seleccione el Nombre para mostrar de un trabajo específico con Estado de Error.
- Busque el id. de trabajo en la propiedad Nombre que se encuentra en la página Información general del trabajo. Comienza con
Featurestore-Materialization-.
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version=version,
job_id="<JOB_ID_OF_FAILED_MATERIALIZATION_JOB>",
)
print(poller.result().job_ids)
Actualización del almacén de materialización sin conexión
- Si un almacén de materialización sin conexión se debe actualizar en el nivel de almacén de características, todos los conjuntos de características del almacén de características deben tener deshabilitada la materialización sin conexión.
- Si la materialización sin conexión está deshabilitada en un conjunto de características, se restablece el estado de materialización de los datos ya materializados en el almacén de materialización sin conexión. El restablecimiento hace que los datos ya materializados no se puedan usar. Debe volver a enviar los trabajos de materialización después de habilitar la materialización sin conexión.
En este tutorial se han creado los datos de entrenamiento con características del almacén de características, se ha habilitado la materialización en el almacén de características sin conexión y se ha realizado un reposición. A continuación, ejecutará el entrenamiento del modelo con estas características.
Limpieza
En el quinto tutorial de la serie se describe cómo eliminar los recursos.
Pasos siguientes
- Vea al siguiente tutorial de la serie: Modelos de entrenamiento y experimentos mediante características.
- Obtenga información sobre losconceptos de almacén de características y las entidades de nivel superior en el almacén de características gestionado.
- Obtenga información sobre la identidad y el control de acceso para el almacén de características gestionado.
- Consulte la guía de solución de problemas del almacén de características gestionado.
- Consulte la referencia de YAML.