Tutorial: Diseñador (entrenamiento de un modelo de regresión sin código)
Entrene un modelo de regresión lineal que prediga los precios de los automóviles mediante el diseñador de Azure Machine Learning. Este tutorial es la primera de una serie de dos partes.
En este tutorial se usa el diseñador de Azure Machine Learning. Para obtener más información, consulte ¿Qué es el diseñador de Azure Machine Learning?
Nota:
El diseñador admite dos tipos de componentes: componentes precompilados clásicos (v1) y componentes personalizados (v2). Estos dos tipos de componentes NO son compatibles.
Los componentes precompilados clásicos proporcionan componentes precompilados principalmente para el procesamiento de datos y las tareas tradicionales de aprendizaje automático, como la regresión y la clasificación. Este tipo de componentes se sigue admitiendo, pero no se agregará ningún componente nuevo.
Los componentes personalizados le permiten ajustar su propio código como componente. Admite el uso compartido de componentes entre áreas de trabajo y la creación fluida entre las interfaces de Studio, CLI v2 y SDK v2.
Para los proyectos nuevos, le recomendamos que utilice el componente personalizado, que es compatible con AzureML V2, y seguirá recibiendo nuevas actualizaciones.
Este artículo se aplica a los componentes precompilados clásicos y no es compatible con CLI v2 y SDK v2.
En la primera parte del tutorial, aprenderá a:
- Crear una canalización.
- Importar datos.
- Preparar los datos.
- Entrenar un modelo de Machine Learning.
- Evaluar un modelo de Machine Learning.
En la segunda parte del tutorial se implementa el modelo como punto de conexión de inferencia en tiempo real para predecir el precio de cualquier automóvil en función de las especificaciones técnicas que envíe.
Nota
Está disponible una versión completa de este tutorial como una canalización de ejemplo.
Para encontrarla, vaya al diseñador del área de trabajo. En la sección Nueva canalización, seleccione Sample 1 - Regression: Automobile Price Prediction (Basic) (Ejemplo 1 - Regresión: predicción del precio de automóviles [básica])
Importante
Si no ve los elementos gráficos que se mencionan en este documento, como los botones en Studio o en el diseñador, es posible que no tenga el nivel de permisos adecuado para el área de trabajo. Póngase en contacto con el administrador de suscripciones de Azure para verificar que se le ha concedido el nivel de acceso correcto. Para obtener más información, consulte Administración de usuarios y roles.
Creación de una canalización
Las canalizaciones de Azure Machine Learning organizan varios pasos de aprendizaje automático y procesamiento de datos en un único recurso. Las canalizaciones permiten organizar, administrar y reutilizar flujos de trabajo de aprendizaje automático complejos entre proyectos y usuarios.
Para crear una canalización de Azure Machine Learning, necesita un área de trabajo de Azure Machine Learning. En esta sección aprenderá a crear estos dos recursos.
Crear un área de trabajo
Para usar el diseñador, necesita un área de trabajo de Azure Machine Learning. El área de trabajo es el recurso de nivel superior de Azure Machine Learning y proporciona un lugar centralizado para trabajar con todos los artefactos que crea con Azure Machine Learning. Para más información sobre la creación de un área de trabajo, consulte Creación de recursos para el área de trabajo.
Nota
Si el área de trabajo utiliza una red virtual, hay pasos de configuración adicionales que debe realizar para usar el diseñador. Para más información, consulte el artículo sobre el uso de Azure Machine Learning Studio en una red virtual de Azure.
Creación de la canalización
Nota:
El diseñador admite dos tipos de componentes: componentes precompilados clásicos y componentes personalizados. Estos dos tipos de componentes no son compatibles.
Los componentes precompilados clásicos proporcionan componentes precompilados principalmente para el procesamiento de datos y las tareas tradicionales de aprendizaje automático, como la regresión y la clasificación. Este tipo de componentes se sigue admitiendo, pero no se agregará ningún componente nuevo.
Los componentes personalizados permiten proporcionar su propio código como componente. Admiten el uso compartido entre áreas de trabajo y la creación fluida entre Estudio, la CLI y las interfaces del SDK.
Este artículo se aplica a los componentes precompilados clásicos.
Inicie sesión en ml.azure.com y seleccione el área de trabajo con la que quiere trabajar.
Seleccione Diseñador ->Precompilado clásico
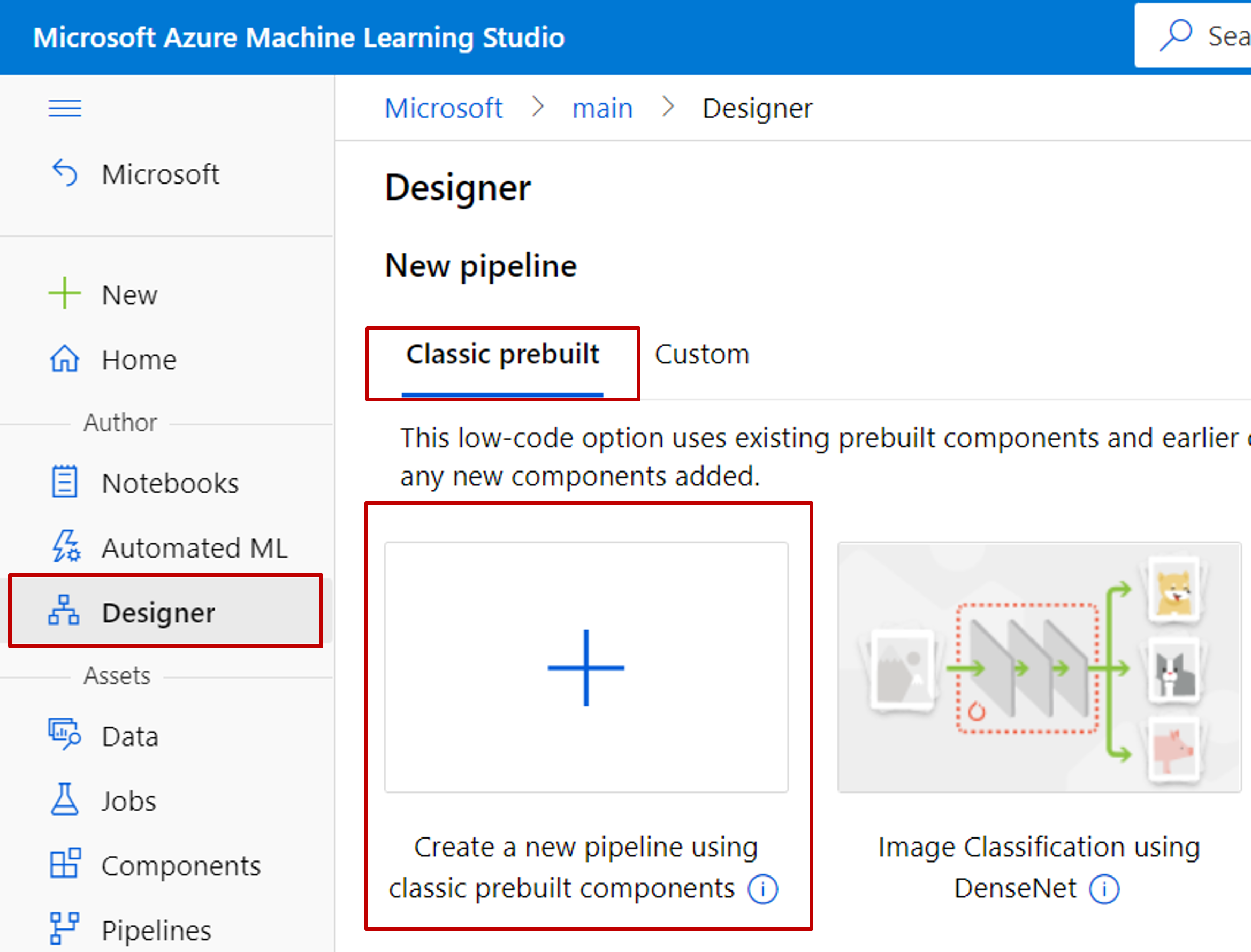
Seleccione: Crear una canalización nueva mediante componentes precompilados clásicos.
Haga clic en el icono de lápiz situado junto al nombre del borrador de canalización generado automáticamente y cámbielo a Predicción de precios de automóviles. No es necesario que el nombre sea único.
Importar datos
Se incluyen varios conjuntos de datos de ejemplo en el diseñador para que experimente con ellos. En este tutorial, use Automobile price data (Raw) .
A la izquierda del lienzo de la canalización, hay una paleta de conjuntos de datos y componentes. Seleccione Componente ->Datos de ejemplo.
Seleccione el conjunto de datos Automobile price data (Raw) y arrástrelo al lienzo.
Visualización de los datos
Puede visualizar los datos para comprender el conjunto de datos que va a usar.
Haga clic con el botón derecho en Datos de precio del automóvil (sin procesar) y seleccione Vista previa de los datos.
Seleccione las diferentes columnas de la ventana de datos para ver información sobre cada una.
Cada fila representa un automóvil y las variables asociadas a cada uno aparecen como columnas. Hay 205 filas y 26 columnas en este conjunto de datos.
Preparación de los datos
Los conjuntos de datos suelen necesitar algún procesamiento previo antes del análisis. Puede que, al inspeccionar el conjunto de datos, haya observado que faltan algunos valores. Estos valores que faltan se deben limpiar, para que el modelo pueda analizar los datos de manera adecuada.
Quitar una columna
Al entrenar un modelo, hay que hacer algo con los datos que faltan. En este conjunto de datos, faltan muchos valores en la columna normalized-losses, por lo que excluiremos toda esa columna del modelo.
En la paleta de conjuntos de datos y componentes a la izquierda del lienzo, haga clic en Componente y busque el componente Select Columns in Dataset.
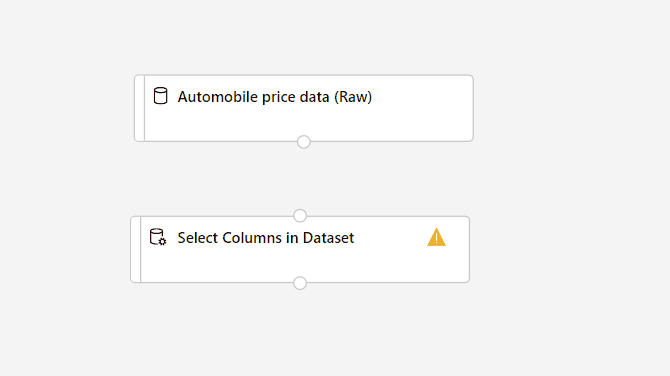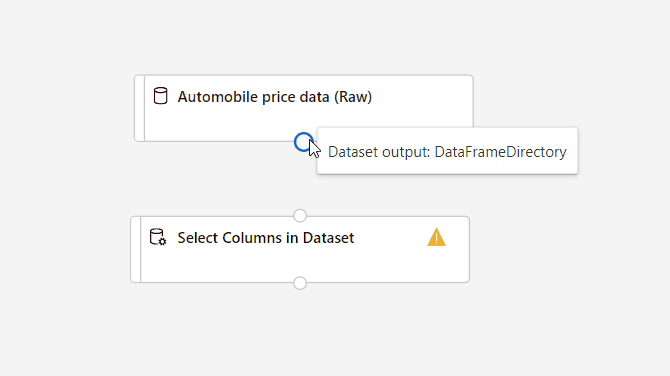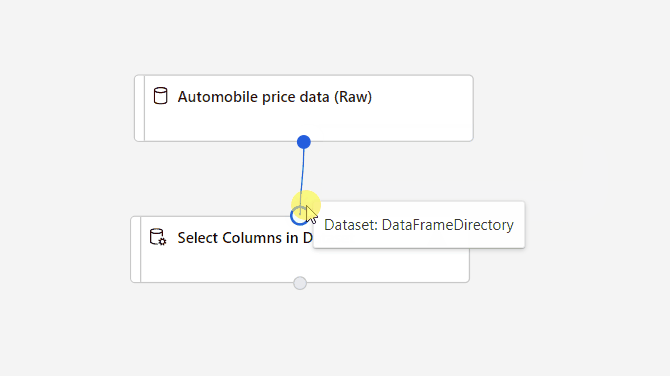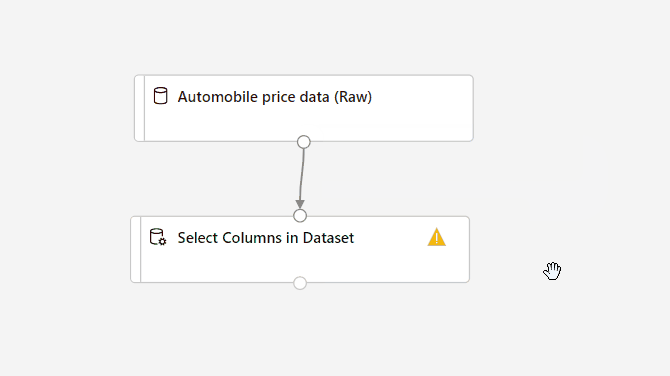
Arrastre el componente Select Columns in Dataset (Seleccionar columnas del conjunto de datos) al lienzo. Coloque el componente debajo del componente de conjunto de datos.
Conecte el conjunto de datos Automobile price data (Raw) al componente Select Columns in Dataset (Seleccionar columnas del conjunto de datos). Arrastre desde el puerto de salida del conjunto de datos, que es el círculo pequeño situado en la parte inferior del conjunto de datos en el lienzo, hasta el puerto de entrada de Select Columns in Dataset (Seleccionar columnas del conjunto de datos), que es el círculo pequeño de la parte superior del componente.
Sugerencia
Puede crear un flujo de datos mediante la canalización si conecta el puerto de salida de un componente al puerto de entrada de otro.
Seleccione el componente Select Columns in Dataset (Seleccionar columnas del conjunto de datos).
Haga clic en el icono de flecha en Configuración a la derecha del lienzo para abrir el panel de detalles del componente. Como alternativa, puede hacer doble clic en el componente Select Columns in Dataset para abrir el panel de detalles.
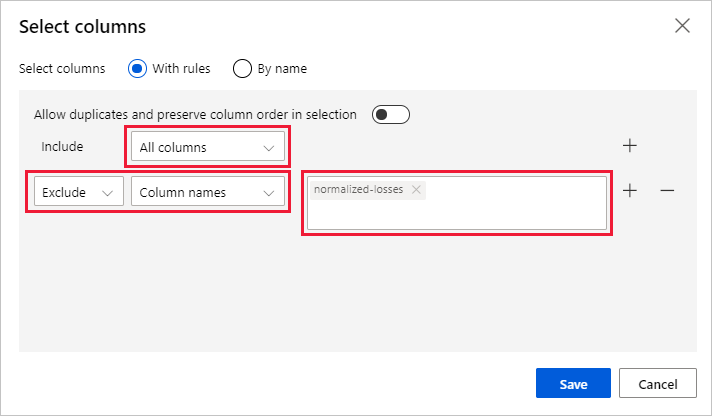
Seleccione Editar columna a la derecha del panel.
Expanda la lista desplegable Nombres de columna situada junto a Incluir y seleccione Todas las columnas.
Seleccione el signo + para agregar una nueva regla.
En los menús desplegables, seleccione Excluir y Nombres de columna.
Escriba normalized-losses en el cuadro de texto.
En la esquina inferior derecha, seleccione Save (Guardar) para cerrar el selector de columnas.
En el panel de detalles del componente Select Columns in Dataset, expanda Node info.
Seleccione el cuadro de texto Comment y escriba Excluir pérdidas normalizadas.
Los comentarios aparecerán en el gráfico para ayudarle a organizar la canalización.
Limpiar datos que faltan
Después de quitar la columna normalized-losses, aún faltan valores en el conjunto de datos. Puede eliminar el resto de los datos que faltan mediante el componente Clean Missing Data (Limpiar datos que faltan).
Sugerencia
Un requisito previo para usar la mayoría de los componentes del diseñador es limpiar los valores que faltan.
En la paleta de conjuntos de datos y componentes a la izquierda del lienzo, haga clic en Componente y busque el componente Clean Missing Data.
Arrastre el componente Clean Missing Data (Limpiar datos que faltan) al lienzo de la canalización. Conéctelo al componente Select Columns in Dataset (Seleccionar columnas del conjunto de datos).
Seleccione el componente Clean Missing Data (Limpiar datos que faltan).
Haga clic en el icono de flecha en Configuración a la derecha del lienzo para abrir el panel de detalles del componente. Como alternativa, puede hacer doble clic en el componente Clean Missing Data para abrir el panel de detalles.
Seleccione Editar columna a la derecha del panel.
En la ventana Columns to be cleaned (Columnas que se limpian) que aparece, expanda el menú desplegable situado junto a Include (Incluir). Seleccione All columns (Todas las columnas).
Seleccione Guardar.
En el panel de detalles del componente Clean Missing Data, en Cleaning mode, seleccione Quitar Remove entire row.
En el panel de detalles del componente Clean Missing Data, expanda Node info.
Seleccione el cuadro de texto Comment y escriba Quitar filas que les falta valor.
La canalización debe parecerse a esta:
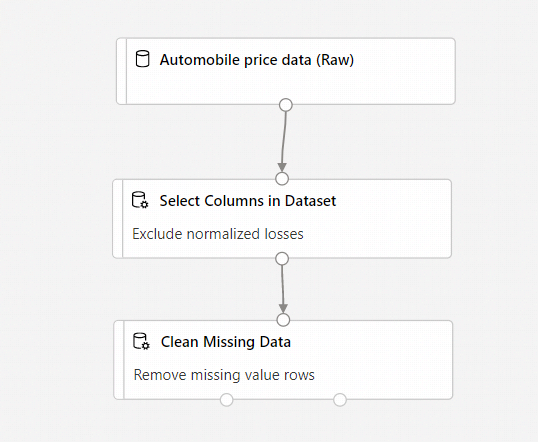
Entrenar un modelo de Machine Learning
Ahora que los componentes están listos para procesar los datos, puede configurar los componentes de entrenamiento.
Como lo que se desea es predecir un precio, que es un número, se puede usar un algoritmo de regresión. En este ejemplo, va a usar un modelo de regresión lineal.
División de los datos
La división de los datos es una tarea común en el aprendizaje automático. Dividirá los datos en dos conjuntos independientes. Un conjunto de datos sirve para entrenar el modelo y el otro para comprobar su funcionamiento.
En la paleta de conjuntos de datos y componentes a la izquierda del lienzo, haga clic en Componente y busque el componente Split Data.
Arrastre el componente Split Data (Dividir datos) al lienzo de la canalización.
Conecte al puerto izquierdo del componente Clean Missing Data(Limpiar datos que faltan) al componente Split Data (Dividir datos).
Importante
Asegúrese de que el puerto de salida izquierdo de Clean Missing Data se conecta a Split Data. El puerto izquierdo contiene los datos limpios. El puerto derecho contiene los datos descartados.
Seleccione el componente Split Data (Dividir datos).
Haga clic en el icono de flecha en Configuración a la derecha del lienzo para abrir el panel de detalles del componente. Como alternativa, puede hacer doble clic en el componente Split Data para abrir el panel de detalles.
En el panel de detalles de Split Data, establezca Fraction of rows in the first output dataset en 0,7.
De este modo divide los datos: el 70 % para entrenar el modelo y el 30 % para probarlo. Al conjunto de datos del 70 % se podrá acceder a través del puerto de salida de la izquierda. Los datos restantes están disponibles a través del puerto de salida derecho.
En el panel de detalles de Split Data, expanda Node info.
Seleccione el cuadro de texto Comment y escriba Dividir el conjunto de datos en conjunto de entrenamiento (0,7) y conjunto de pruebas (0,3).
Entrenamiento del modelo
Para entrenar el modelo, proporciónele un conjunto de datos que incluya el precio. El algoritmo construye un modelo que explica la relación entre las características y el precio presentado por los datos de entrenamiento.
En la paleta de conjuntos de datos y componentes a la izquierda del lienzo, haga clic en Componente y busque el componente Linear Regression.
Arrastre el componente Linear Regression al lienzo de la canalización.
En la paleta de conjuntos de datos y componentes a la izquierda del lienzo, haga clic en Componente y busque el componente Train Model.
Arrastre el componente Train Model al lienzo de la canalización.
Conecte la salida del componente Linear Regression (Regresión lineal) a la entrada izquierda del componente Train Model (Entrenar modelo).
Conecte la salida de datos de entrenamiento (puerto izquierdo) del componente Dividir datos a la entrada derecha del componente Entrenar modelo.
Importante
Asegúrese de que el puerto de salida izquierdo de Split Data se conecta a Train Model. El puerto izquierdo contiene el conjunto de entrenamiento. El puerto derecho contiene el conjunto de prueba.

Seleccione el componente Entrenar modelo.
Haga clic en el icono de flecha en Configuración a la derecha del lienzo para abrir el panel de detalles del componente. Como alternativa, puede hacer doble clic en el componente Train Model para abrir el panel de detalles.
Seleccione Editar columna a la derecha del panel.
En la ventana Columna de etiqueta que aparece, expanda el menú desplegable y seleccione Nombres de columna.
En el cuadro de texto, escriba precio para especificar el valor que el modelo va a predecir.
Importante
Asegúrese de escribir exactamente el nombre de la columna. No use mayúsculas para el precio.
La canalización debe ser parecida a esta:
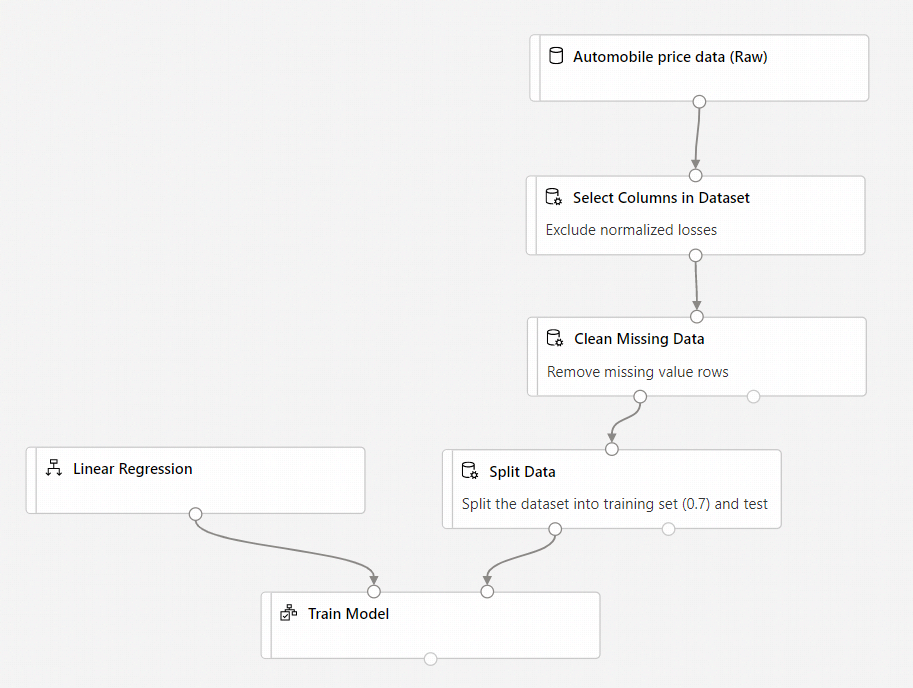
Incorporación del componente Score Model (Puntuar modelo)
Después de entrenar el modelo con el 70 % de los datos, puede usarlo para puntuar el otro 30 % y ver si el modelo funciona correctamente.
En la paleta de conjuntos de datos y componentes a la izquierda del lienzo, haga clic en Componente y busque el componente Score Model.
Arrastre el componente Score Model al lienzo de la canalización.
Conecte la salida del componente Train Model (Entrenar modelo) al puerto de entrada izquierdo de Score Model (Entrenar modelo). Conecte la salida de los datos de prueba (puerto derecho) del componente Split Data (Dividir datos) al puerto de entrada correcto de Score Model (Puntuar modelo).
Incorporación del componente Evaluate Model (Evaluar modelo)
Use el componente Evaluate Model (Evaluar modelo) para evaluar la puntuación que dio el modelo al conjunto de datos de prueba.
En la paleta de conjuntos de datos y componentes a la izquierda del lienzo, haga clic en Componente y busque el componente Evaluate Model.
Arrastre el componente Evaluate Model al lienzo de la canalización.
Conecte la salida del componente Score Model (Puntuar modelo) a la entrada izquierda de Evaluate Model (Evaluar modelo).
La canalización final debe parecerse a esta:
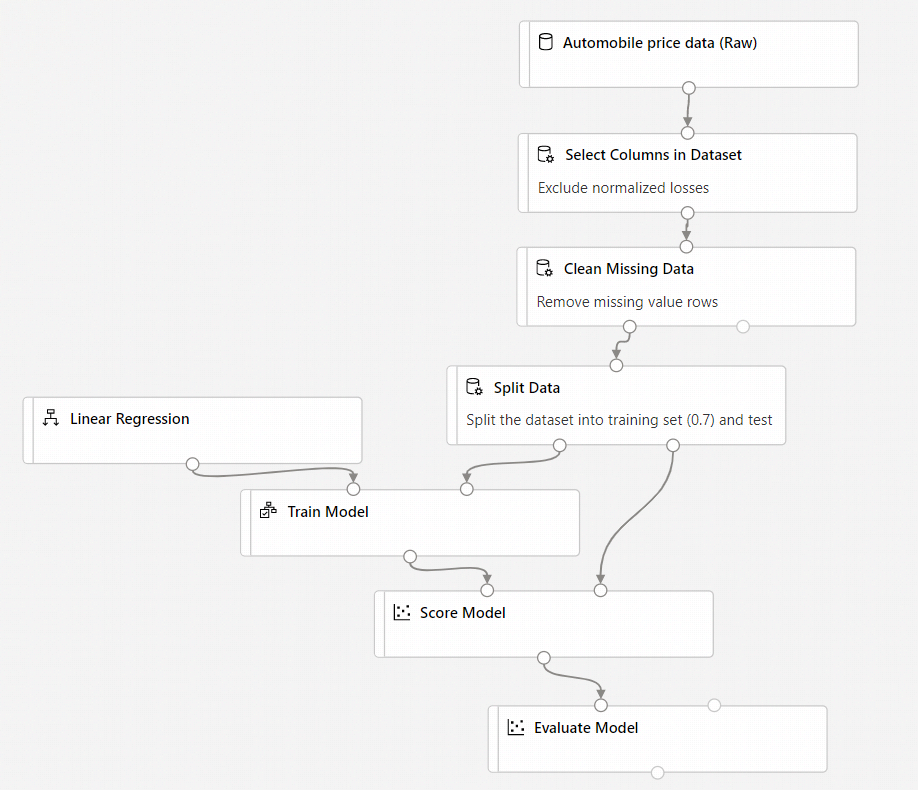
Envío de la canalización
Seleccione Configurar y enviar en la esquina superior derecha para enviar la canalización.

A continuación, verá un asistente paso a paso, siga el asistente para enviar el trabajo de canalización.
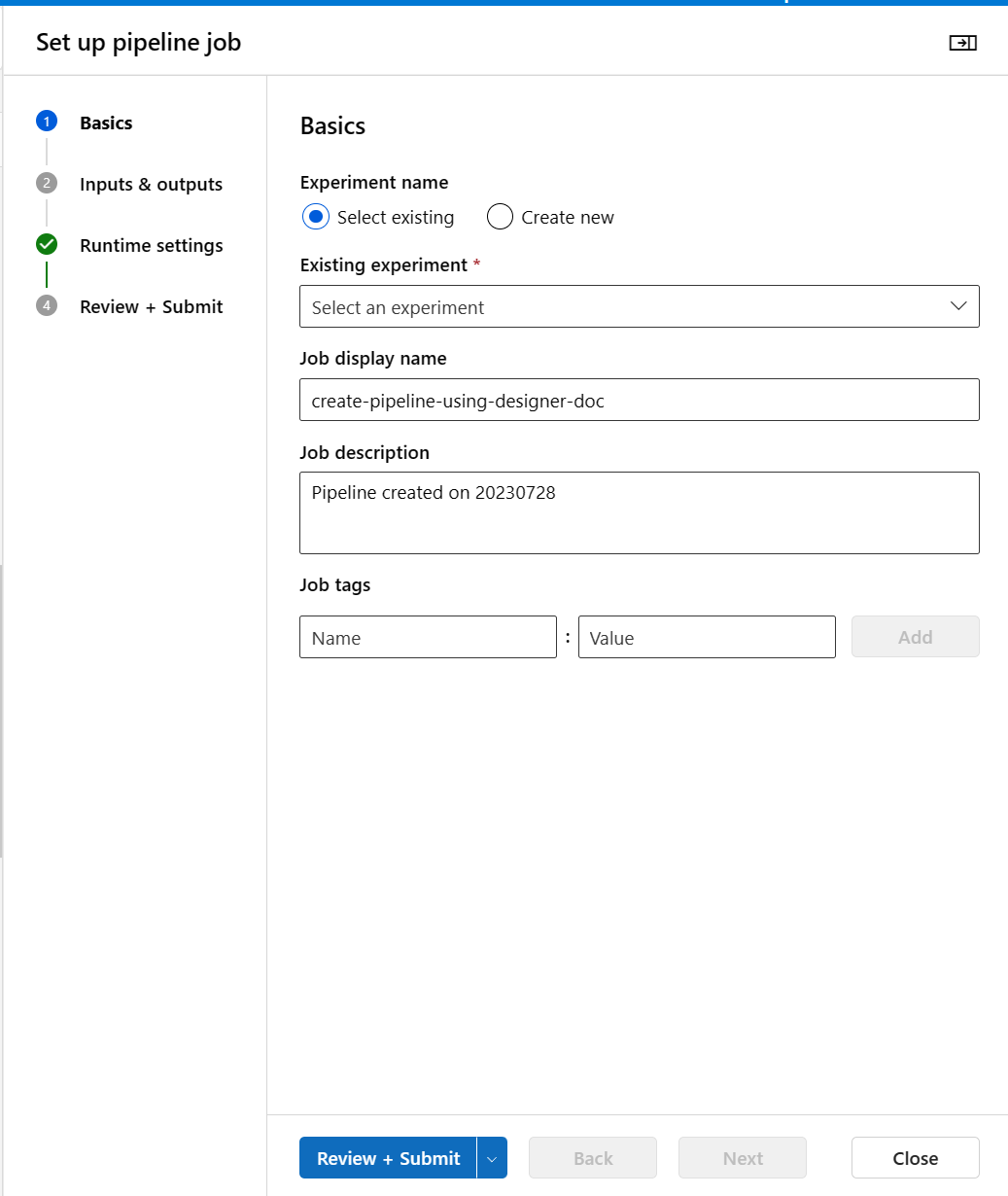

En el paso Aspectos básicos, puede configurar el experimento, el nombre para mostrar el trabajo, la descripción del trabajo, etc.
En el paso Entradas y salidas, puede asignar valor a las entradas o salidas que se promueven al nivel de canalización. En este ejemplo, estará vacío porque no hemos promocionado ninguna entrada o salida al nivel de canalización.
En Configuración del entorno de ejecución, puede configurar el almacén de datos predeterminado y el proceso predeterminado en la canalización. Es el almacén de datos o proceso predeterminado para todos los componentes de la canalización. Sin embargo, si establece un proceso o almacén de datos diferente para un componente explícitamente, el sistema respeta la configuración de nivel de componente. De lo contrario, usa el valor predeterminado.
El paso Revisar y enviar es el último paso para revisar toda la configuración antes de enviar. El asistente recordará la última configuración si alguna vez envía la canalización.
Después de enviar el trabajo de canalización, habrá un mensaje en la parte superior con un vínculo al detalle del trabajo. Puede seleccionar este vínculo para revisar los detalles del trabajo.

Visualización de etiquetas con puntuación
En la página de detalles del trabajo, puede comprobar el estado del trabajo de canalización, los resultados y los registros.

Una vez finalizado el trabajo, puede ver los resultados de la ejecución de canalización. En primer lugar, examine las predicciones generadas por el modelo de regresión.
Haga clic con el botón derecho en el componente Puntuar modelo y seleccione Vista previa de los datos>Conjunto de datos puntuado para ver el resultado.
Aquí puede ver los precios previstos y los precios reales de los datos de prueba.
Evaluación de modelos
Use Evaluate Model (Evaluar modelo) para ver el rendimiento del modelo entrenado en el conjunto de datos de prueba.
- Haga clic con el botón derecho en el componente Evaluar modelo y seleccione Vista previa de los datos>Resultados de la evaluación para ver el resultado.
Se muestran las siguientes estadísticas de su modelo:
- Desviación media (MAE) : la media de errores absolutos. Un error es la diferencia entre el valor previsto y el valor real.
- Error cuadrático medio (RMSE) : la raíz cuadrada de la media de errores al cuadrado de las predicciones realizadas sobre el conjunto de datos de prueba.
- Error absoluto relativo: la media de errores absolutos en relación con la diferencia absoluta entre los valores reales y la media de todos los valores reales.
- Error al cuadrado relativo: la media de errores al cuadrado en relación con la diferencia al cuadrado entre los valores reales y la media de todos los valores reales.
- Coeficiente de determinación: conocido también como valor R cuadrado, es una métrica estadística que indica en qué medida se ajusta un modelo a los datos.
Para cada una de las estadísticas de errores, cuanto menor sea el valor, mejor. Un valor inferior indica que las predicciones están más próximas a los valores reales. En el coeficiente de determinación, cuanto más próximo es su valor a uno (1,0), mejores son las predicciones.
Limpieza de recursos
Omita esta sección si desea continuar con la parte 2 del tutorial sobre la implementación de modelos.
Importante
Los recursos que creó pueden usarse como requisitos previos de otros tutoriales y artículos de procedimientos de Azure Machine Learning.
Eliminar todo el contenido
Si no va a usar nada de lo que ha creado, elimine el grupo de recursos completo para que no le genere gastos.
En Azure Portal, seleccione Grupos de recursos en la parte izquierda de la ventana.
En la lista, seleccione el grupo de recursos que creó.
Seleccione Eliminar grupo de recursos.
Al eliminar el grupo de recursos también se eliminan todos los recursos que creó en el diseñador.
Eliminación de recursos individuales
En diseñador donde creó el experimento, elimine recursos individuales; para ello, selecciónelos y, luego, haga clic en el botón Eliminar.
El destino de proceso que ha creado aquí se escala automáticamente a cero nodos cuando no se usa. Esta acción se lleva a cabo para minimizar los cargos. Si quiere eliminar el destino de proceso, siga estos pasos:
Puede anular el registro de los conjuntos de datos del área de trabajo seleccionando cada conjunto de datos y Anular el registro.
Para eliminar un conjunto de datos, vaya a la cuenta de almacenamiento mediante Azure Portal o el Explorador de Azure Storage y elimine manualmente esos recursos.
Pasos siguientes
En la segunda parte, aprenderá a implementar el modelo como un punto de conexión en tiempo real.