Tutorial: Desarrollo de modelos en una estación de trabajo en la nube
Aprenda a desarrollar un script de entrenamiento con un cuaderno en una estación de trabajo en la nube de Azure Machine Learning. En este tutorial se describen los conceptos básicos que necesita para empezar a trabajar:
- Configure la estación de trabajo en la nube. La estación de trabajo en la nube cuenta con tecnología de una instancia de proceso de Azure Machine Learning, que está preconfigurada con entornos que podrá usar para satisfacer las distintas necesidades del proceso de desarrollo de modelos.
- Use entornos de desarrollo basados en la nube.
- Use MLflow para realizar un seguimiento de las métricas del modelo, todo desde un solo cuaderno.
Requisitos previos
Para usar Azure Machine Learning, necesita un área de trabajo. Si no tiene una, complete Crear recursos necesarios para empezar para crear un área de trabajo y obtener más información sobre su uso.
Importante
Si su área de trabajo de Azure Machine Learning está configurada con una red virtual administrada, es posible que deba agregar reglas de salida para permitir el acceso a los repositorios públicos de paquetes de Python. Para más información, consulte: Escenario: acceso a paquetes de aprendizaje automático públicos.
Inicio del proceso
La sección Proceso del área de trabajo le permite crear recursos de proceso. Una instancia de proceso es una estación de trabajo basada en la nube totalmente administrada por Azure Machine Learning. En esta serie de tutoriales se usa una instancia de proceso. También puede usarse para ejecutar su propio código y para desarrollar y probar modelos.
- Inicie sesión en Azure Machine Learning Studio.
- Seleccione el área de trabajo si aún no está abierta.
- En el panel de navegación izquierdo, seleccione Proceso.
- Si no tiene una instancia de proceso, verá la opción Nueva en medio de la pantalla. Seleccione Nueva y rellene el formulario. Puede usar todos los valores predeterminados.
- Si tiene una instancia de proceso, selecciónela en la lista. Si se detiene, seleccione Iniciar.
Abra Visual Studio Code (VS Code)
Una vez que tenga una instancia de proceso en ejecución, puede acceder a ella de varias maneras. En este tutorial se muestra el uso de la instancia de proceso de VS Code. VS Code proporciona un entorno de desarrollo integrado (IDE) completo con la eficacia de los recursos de Azure Machine Learning.
En la lista de instancias de proceso, seleccione VS Code (Web) o VS Code (Escritorio) para la instancia de proceso que desea usar. Si elige VS Code (Escritorio), es posible que vea un elemento emergente en el que se pregunta si desea abrir la aplicación.

Esta instancia de VS Code está asociada a la instancia de proceso y al sistema de archivos del área de trabajo. Incluso si lo abre en el escritorio, los archivos que ve son archivos en el área de trabajo.
Configuración de un nuevo entorno para la creación de prototipos (opcional)
Para que el script se ejecute, debe trabajar en un entorno configurado con las dependencias y bibliotecas que espera el código. En esta sección encontrará información para crear un entorno adaptado al código. Para crear el nuevo kernel de Jupyter al que se conecta el cuaderno, tendrá que usar un archivo YAML que defina las dependencias.
Cargar un archivo.
Los archivos que cargue se almacenarán en un recurso compartido de archivos de Azure, y estos archivos se montarán en cada instancia de proceso y se compartirán en el área de trabajo.
Descargue este archivo del entorno Conda, workstation_env.yml, a su equipo con el botón Descargar archivo sin formato en la parte superior derecha.
Arrastre el archivo del equipo a la ventana de VS Code. El archivo se carga en el área de trabajo.
Mueva el archivo a la carpeta con su nombre de usuario.
Seleccione este archivo para obtener una vista previa y vea qué dependencias especifica. El contenido aparece de esta forma:
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlibCree un kernel.
A continuación, use el terminal para crear un nuevo kernel de Jupyter, basado en el archivo workstation_env.yml.
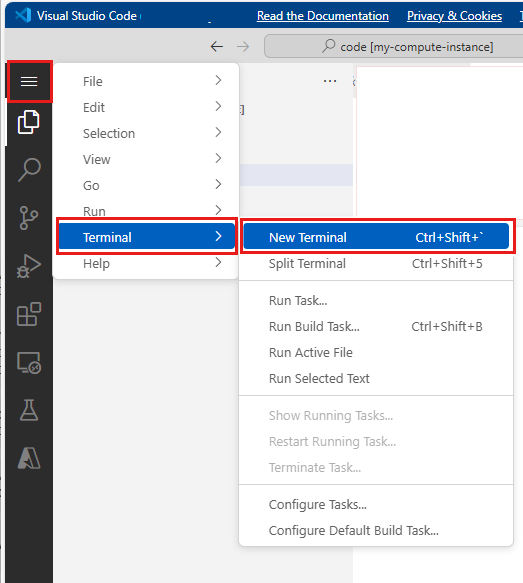
En la barra de menús superior, seleccione Terminal > Nuevo terminal.
Consulte los entornos de Conda actuales. El entorno activo se marca con un *.
conda env listcda la carpeta donde cargó el archivo workstation_env.yml. Por ejemplo, si lo cargó en la carpeta de usuario:cd Users/myusernameAsegúrese de que workstation_env.yml está en esta carpeta.
lsCree el entorno en función del archivo Conda proporcionado. Recuerde que este entorno tarda unos minutos en crearse.
conda env create -f workstation_env.ymlActive el nuevo entorno.
conda activate workstation_envNota:
Si ve un CommandNotFoundError, siga las instrucciones para ejecutar
conda init bash, cierre el terminal y abra uno nuevo. A continuación, reintente el comandoconda activate workstation_env.Compruebe que el entorno correcto está activo; para ello, busque el entorno marcado con *.
conda env listCree un nuevo kernel de Jupyter basado en el entorno activo.
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"Cierre ventana de terminal.
Ya tiene un nuevo kernel. A continuación, abra un cuaderno y use este kernel.
Creación de un cuaderno
- En la barra de menús superior, seleccione Archivo > Nuevo archivo.
- Asigne un nombre al nuevo archivo develop-tutorial.ipynb (o escriba el nombre que quiera). Asegúrese de usar la extensión .ipynb.
Establecer kernel
- En la parte superior derecha, seleccione Seleccionar kernel.
- Seleccione Instancia de proceso de Azure ML (computeinstance-name).
- Seleccione el kernel que creó, Tutorial Workstation Env. Si no lo ve, seleccione la herramienta Actualizar en la parte superior derecha.
Desarrollo de un script de entrenamiento
En esta sección, desarrollará un script de entrenamiento de Python capaz de predecir pagos predeterminados de la tarjeta de crédito mediante los conjuntos de datos de prueba y entrenamiento preparados del conjunto de datos de UCI.
Este código usa sklearn para el entrenamiento y MLflow para registrar las métricas.
Comience con el código que importa los paquetes y las bibliotecas que usará en el script de entrenamiento.
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_splitA continuación, cargue y procese los datos de este experimento. En este tutorial, tendrá que leer los datos de un archivo en Internet.
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )Prepare los datos para el entrenamiento:
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.valuesAgregue código para iniciar el registro automático con
MLflow, de modo que pueda realizar un seguimiento de las métricas y los resultados. Gracias a la naturaleza iterativa del desarrollo de modelos,MLflowle permite registrar los parámetros y los resultados del modelo. Consulte esas ejecuciones para comparar y comprender cómo funciona el modelo. Los registros también proporcionan contexto que podrá usar cuando esté listo para pasar de la fase de desarrollo a la fase de entrenamiento de los flujos de trabajo en la instancia de Azure Machine Learning.# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()Entrene un modelo.
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()Nota:
Puede ignorar las advertencias de mlflow. Seguirá obteniendo todos los resultados de los que necesite un seguimiento.
Iteración
Ahora que tiene los resultados del modelo, es posible que quiera cambiar algo e intentarlo de nuevo. Por ejemplo, tal vez quiera probar una técnica de clasificador diferente:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()Nota:
Puede ignorar las advertencias de mlflow. Seguirá obteniendo todos los resultados de los que necesite un seguimiento.
Examen de los resultados
Ahora que ha probado dos modelos diferentes, use los resultados cuyo seguimiento realiza MLFfow para decidir qué modelo es mejor. Puede consultar métricas como la precisión u otros indicadores importantes para sus escenarios. Puede profundizar en estos resultados con más detalle si examina los trabajos que creó MLflow.
Vuelva al área de trabajo en el Estudio de Azure Machine Learning.
En el panel de navegación izquierdo, seleccione Trabajos.
Seleccione el vínculo del tutorial Desarrollo en la nube.
Se muestran dos trabajos diferentes, uno para cada uno de los modelos que haya probado. Estos nombres se generan automáticamente. Cuando mantenga el puntero sobre un nombre, use la herramienta de lápiz que aparece junto al nombre si quiere cambiarlo.
Seleccione el vínculo del primer trabajo. El nombre aparece en la parte superior. También puede cambiar el nombre aquí, con la herramienta del lápiz.
En la página se muestran detalles del trabajo, como propiedades, salidas, etiquetas y parámetros. En Etiquetas, verá el elemento estimator_name, que describe el tipo de modelo.
Seleccione la pestaña Métricas para ver las métricas que registró
MLflow. (Puede esperar que los resultados sean diferentes, ya que tiene un conjunto de entrenamiento diferente).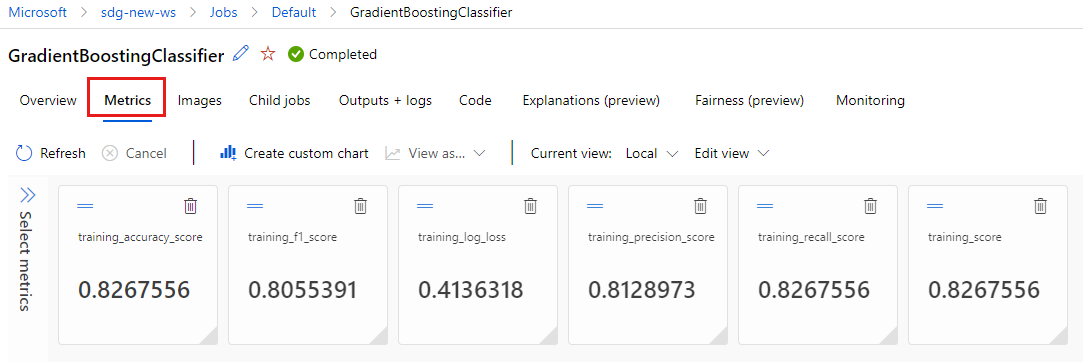
Seleccione la pestaña Imágenes para ver las imágenes que generó
MLflow.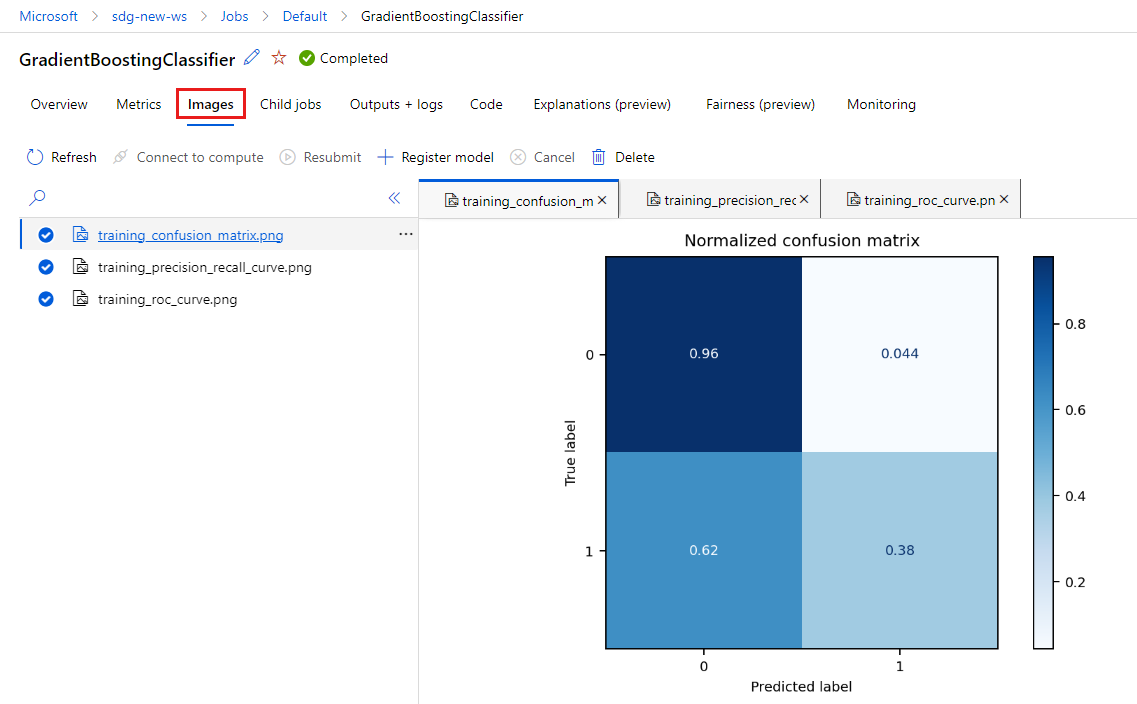
Vuelva y revise las métricas e imágenes del otro modelo.
Creación de un script de Python
A continuación, cree un script de Python desde el cuaderno para el entrenamiento del modelo.
En la ventana de VS Code, haga clic con el botón derecho en el nombre de archivo del cuaderno y seleccione Importar cuaderno a script.
Use el menú Archivo > Guardar para guardar este nuevo archivo de script. Llámelo train.py.
Examine este archivo y elimine el código que no quiera tener en el script de entrenamiento. Por ejemplo, mantenga el código del modelo que quiera usar y elimine el código del modelo que no quiera.
- Asegúrese de mantener el código que inicia el registro automático (
mlflow.sklearn.autolog()). - Al ejecutar el script de Python de forma interactiva (como está haciendo aquí), puede mantener la línea que define el nombre del experimento (
mlflow.set_experiment("Develop on cloud tutorial")). O bien, puede asignarle un nombre diferente para verlo como una entrada diferente en la sección Trabajos. Aún así, al preparar el script de un trabajo de entrenamiento, esa línea no se aplica y se debe omitir: la definición del trabajo incluye el nombre del experimento. - Al entrenar un único modelo, las líneas para iniciar y finalizar una ejecución (
mlflow.start_run()ymlflow.end_run()) tampoco son necesarias (ya que no tendrán ningún efecto), pero se pueden dejar tal cual, si quiere.
- Asegúrese de mantener el código que inicia el registro automático (
Cuando haya terminado con las modificaciones, guarde el archivo.
Ya tiene un script de Python que podrá usar para entrenar el modelo que prefiera.
Ejecute el script de Python.
Por ahora, ejecutará este código en la instancia de proceso, que es el entorno de desarrollo de Azure Machine Learning. En el Tutorial: Entrenamiento de un modelo se muestra cómo ejecutar un script de entrenamiento de forma más escalable en recursos de proceso más eficaces.
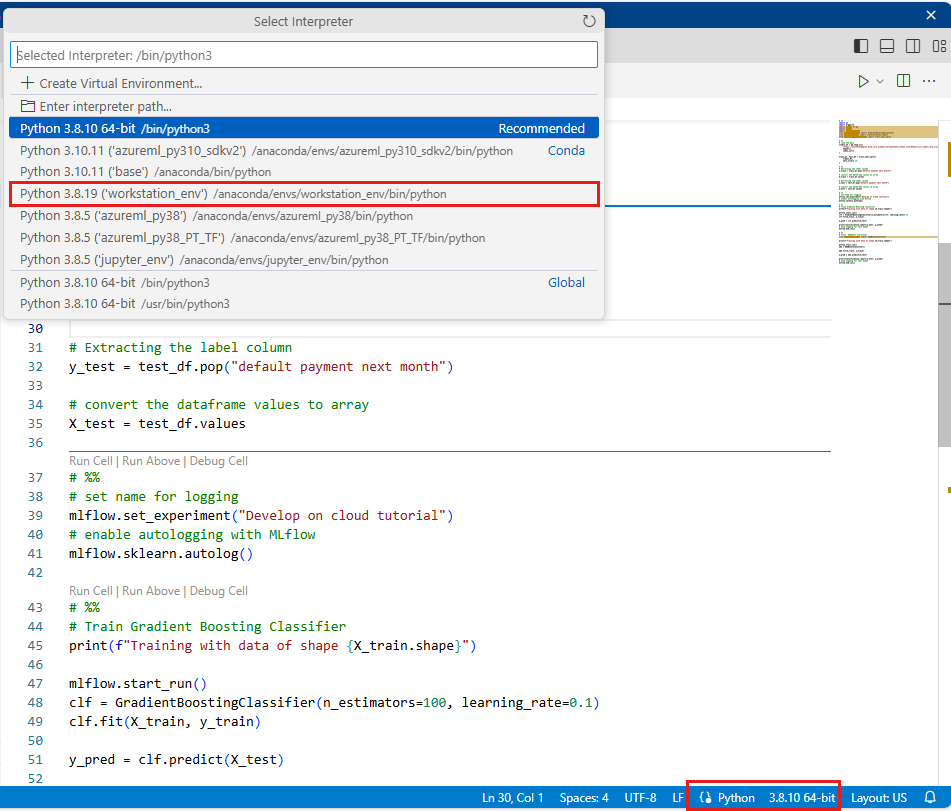
Seleccione el entorno que creó anteriormente en este tutorial como versión de Python (workstations_env). En la esquina inferior derecha del cuaderno, verá el nombre del entorno. Selecciónelo y, a continuación, seleccione el entorno en el medio de la pantalla.
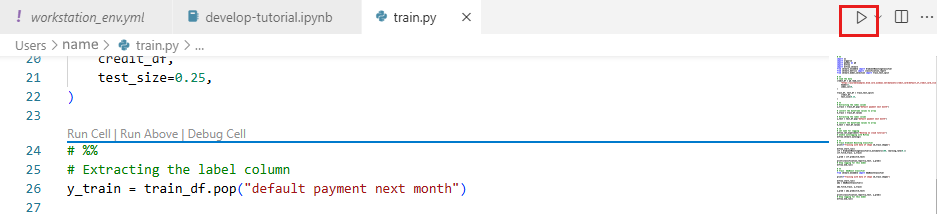
Ahora ejecute el script de Python. Use la herramienta Ejecutar archivo de Python en la parte superior derecha.
Nota:
Puede ignorar las advertencias de mlflow. Seguirá recibiendo todas las métricas e imágenes del registro automático.
Examen de los resultados del script
Vuelva a Trabajos en el área de trabajo del Estudio de Azure Machine Learning para ver los resultados del script de entrenamiento. Tenga en cuenta que los datos de entrenamiento cambian con cada división, por lo que los resultados también serán diferentes entre ejecuciones.
Limpieza de recursos
Si quiere continuar con otros tutoriales, ve a Pasos siguientes.
Detención de una instancia de proceso
Si no va a utilizar ahora la instancia de proceso, deténgala:
- En el estudio, en el área de navegación de la izquierda, seleccione Proceso.
- En las pestañas superiores, seleccione Instancia de proceso.
- Seleccione la instancia de proceso en la lista.
- En la barra de herramientas superior, seleccione Detener.
Eliminación de todos los recursos
Importante
Los recursos que creó pueden usarse como requisitos previos para otros tutoriales y artículos de procedimientos de Azure Machine Learning.
Si no va a usar ninguno de los recursos que ha creado, elimínelos para no incurrir en cargos:
En Azure Portal, en el cuadro de búsqueda, escriba Grupos de recursos y selecciónelo en los resultados.
En la lista, seleccione el grupo de recursos que creó.
En la página Información general, seleccione Eliminar grupo de recursos.
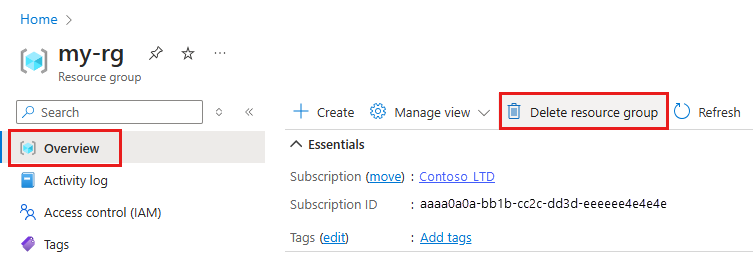
Escriba el nombre del grupo de recursos. A continuación, seleccione Eliminar.
Pasos siguientes
Más información sobre:
- De los artefactos a los modelos en MLflow
- Uso de GIT con Azure Machine Learning
- Ejecución de cuadernos de Jupyter Notebook en el área de trabajo
- Trabajo con un terminal de instancia de proceso en el área de trabajo
- Administración de sesiones de cuaderno y de terminal
En este tutorial se han mostrado los primeros pasos para crear un modelo y crear prototipos en la misma máquina donde reside el código. En el caso del entrenamiento de producción, puede aprender a usar ese script de entrenamiento en recursos de proceso remotos más eficaces: