Tutorial: Entrenamiento del primer modelo de Machine Learning (SDK v1, parte 2 de 3)
SE APLICA A:  Azure ML del SDK de Python v1
Azure ML del SDK de Python v1
En este tutorial se muestra cómo entrenar un modelo de Machine Learning en Azure Machine Learning. Este tutorial es parte 2 de una serie de tutoriales de dos partes.
En la parte 1: Ejecutar "Hola mundo" de la serie, aprendió a usar un script de control para ejecutar un trabajo en la nube.
En este tutorial, realizará el siguiente paso mediante el envío de un script que entrena un modelo de Machine Learning. Este ejemplo le ayuda a comprender cómo Azure Machine Learning facilita el comportamiento coherente entre la depuración local y las ejecuciones remotas.
En este tutorial, hizo lo siguiente:
- Cree un script de entrenamiento.
- Usar Conda para definir un entorno de Azure Machine Learning.
- Crear un script de control.
- Comprender las clases de Azure Machine Learning (
Environment,Run,Metrics). - Enviar y ejecutar el script de entrenamiento.
- Ver la salida del código en la nube.
- Registrar métricas en Azure Machine Learning.
- Ver las métricas en la nube.
Requisitos previos
- Finalización de la parte 1 de la serie.
Creación de scripts de entrenamiento
En primer lugar, defina la arquitectura de red neuronal en el archivo model.py. Todo el código de entrenamiento entra en el subdirectorio src, incluido model.py.
El código de entrenamiento se toma de este ejemplo de introducción de PyTorch. Los conceptos de Azure Machine Learning se aplican a cualquier código de aprendizaje automático, no solo PyTorch.
Cree el archivo model.py en la subcarpeta src. Copie este código en el archivo:
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return xEn la barra de herramientas, seleccione Guardar para guardar el archivo. Si lo desea, cierre la pestaña.
A continuación, defina el script de entrenamiento, también en la subcarpeta src. Este script descarga el conjunto de datos de CIFAR10 mediante las API
torchvision.datasetde PyTorch, configura la red que se define en model.py y lo entrena en dos tiempos mediante el SGD estándar y la pérdida de entropía cruzada.Cree un script train.py en la subcarpeta src:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root="../data", train=True, download=True, transform=torchvision.transforms.ToTensor(), ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 print(f"epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}") running_loss = 0.0 print("Finished Training")Ya tiene la siguiente estructura de carpetas:
Prueba local
Seleccione Save and run script in terminal (Guardar y ejecutar script en el terminal) para ejecutar el script train.py directamente en la instancia de proceso.
Cuando se haya completado el script, seleccione Actualizar las carpetas de archivos. Verá la nueva carpeta de datos denominada get-started/data Expanda esta carpeta para ver los datos descargados.
Crear un entorno de Python
Azure Machine Learning proporciona el concepto de un entorno para representar un entorno de Python reproducible y con control de versiones para ejecutar experimentos. Es fácil crear un entorno desde un entorno de PIP o Conda local.
En primer lugar, cree un archivo con las dependencias del paquete.
Cree un nuevo archivo en la carpeta get-started denominado
pytorch-env.yml:name: pytorch-env channels: - defaults - pytorch dependencies: - python=3.7 - pytorch - torchvisionEn la barra de herramientas, seleccione Guardar para guardar el archivo. Si lo desea, cierre la pestaña.
Creación del script de control
La diferencia entre el siguiente script de control y el que usó para enviar "Hola mundo" es que agrega un par de líneas adicionales para establecer el entorno.
Cree un archivo de Python en la carpeta get-started denominado run-pytorch.py:
# run-pytorch.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
if __name__ == "__main__":
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-train')
config = ScriptRunConfig(source_directory='./src',
script='train.py',
compute_target='cpu-cluster')
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
Sugerencia
Si usó un nombre diferente al crear el clúster de proceso, asegúrese de ajustar también el nombre en el código compute_target='cpu-cluster'.
Comprensión de los cambios de código
env = ...
Hace referencia al archivo de dependencia que creó anteriormente.
config.run_config.environment = env
Agrega el entorno a ScriptRunConfig.
Envío de la ejecución a Azure Machine Learning
Seleccione Save and run script in terminal (Guardar y ejecutar script en terminal) para ejecutar el script run-pytorch.py.
Verá un vínculo en la ventana de terminal que se abre. Seleccione el vínculo para ver el trabajo.
Nota
Es posible que vea algunas advertencias que empiezan por Error al cargar azureml_run_type_providers... . Puede ignorarlas. Use el vínculo de la parte inferior de estas advertencias para ver la salida.
Visualización de la salida
- En la página que se abre, verá el estado del trabajo. La primera vez que ejecute este script, Azure Machine Learning compila una nueva imagen de Docker desde el entorno de PyTorch. Todo el trabajo puede tardar unos 10 minutos en completarse. Esta imagen se reutilizará en trabajos futuros, lo que hará que se ejecuten mucho más rápido.
- Puede ver los registros de compilación de Docker en Estudio de Azure Machine Learning. para ver los registros de compilación:
- Seleccione la pestaña Outputs + logs (Resultados y registros).
- Seleccione la carpeta azureml-logs.
- Select 20_image_build_log.txt.
- Cuando el estado del trabajo sea Completado, seleccione Salida y registros.
- Seleccione user_logs, y a continuación, std_log.txt para ver la salida del trabajo.
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../data/cifar-10-python.tar.gz
Extracting ../data/cifar-10-python.tar.gz to ../data
epoch=1, batch= 2000: loss 2.19
epoch=1, batch= 4000: loss 1.82
epoch=1, batch= 6000: loss 1.66
...
epoch=2, batch= 8000: loss 1.51
epoch=2, batch=10000: loss 1.49
epoch=2, batch=12000: loss 1.46
Finished Training
Si ve un error Your total snapshot size exceeds the limit, la carpeta data se encuentra en el valor source_directory usado en ScriptRunConfig.
Seleccione ... al final de la carpeta y, después, seleccione Mover para mover data a la carpeta get-started.
Registro de métricas de entrenamiento
Ahora que tiene un entrenamiento del modelo en Azure Machine Learning, empiece a realizar un seguimiento de algunas métricas de rendimiento.
El script de entrenamiento actual imprime las métricas en el terminal. Azure Machine Learning proporciona un mecanismo para registrar métricas con más funcionalidad. Al agregar algunas líneas de código, puede ver las métricas en Studio y comparar las métricas entre varios trabajos.
Modifique train.py para incluir el registro
Modifique el script de train.py para incluir dos líneas de código más:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run # ADDITIONAL CODE: get run from the current context run = Run.get_context() # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor() ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 # ADDITIONAL CODE: log loss metric to AML run.log('loss', loss) print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')Guarde este archivo y cierre la pestaña si lo desea.
Comprensión de las dos líneas de código adicionales
En train.py, puede acceder al objeto de ejecución desde dentro del propio script de entrenamiento mediante el método Run.get_context() y usarlo para registrar métricas:
# ADDITIONAL CODE: get run from the current context
run = Run.get_context()
...
# ADDITIONAL CODE: log loss metric to AML
run.log('loss', loss)
Las métricas de Azure Machine Learning están:
- Organizadas por experimento y ejecución para que sea fácil realizar un seguimiento de las métricas y compararlas.
- Equipadas con una interfaz de usuario para que pueda visualizar el rendimiento del entrenamiento en Studio.
- Diseñadas para escalar, con el fin de mantener estas ventajas incluso cuando se ejecutan cientos de experimentos.
Actualización del archivo de entorno de Conda
El script de train.py ha tomado una dependencia nueva en azureml.core. Actualice pytorch-env.yml para reflejar este cambio:
name: pytorch-env
channels:
- defaults
- pytorch
dependencies:
- python=3.7
- pytorch
- torchvision
- pip
- pip:
- azureml-sdk
Asegúrese de guardar este archivo antes de enviar la ejecución.
Envío de la ejecución a Azure Machine Learning
Seleccione la pestaña del script run-pytorch.py, y a continuación, seleccione Guardar y ejecutar script en terminal para volver a ejecutar el script de run-pytorch.py. Asegúrese de guardar los cambios en pytorch-env.yml primero.
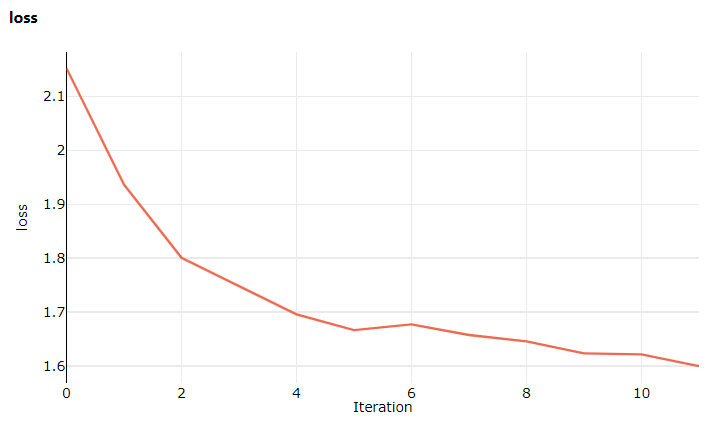
Esta vez, cuando visite Estudio de Azure Machine Learning, vaya a la pestaña Métricas, donde ya puede ver actualizaciones directas sobre la pérdida de entrenamiento del modelo. El entrenamiento puede tardar entre 1 y 2 minutos en comenzar.
Limpieza de recursos
Si tiene previsto continuar con otro tutorial o para iniciar sus propios trabajos de entrenamiento, vaya a Recursos relacionados.
Detención de una instancia de proceso
Si no va a utilizar ahora la instancia de proceso, deténgala:
- En Studio, a la izquierda, seleccione Proceso.
- En las pestañas superiores, seleccione Instancia de proceso.
- Seleccione la instancia de proceso en la lista.
- En la barra de herramientas superior, seleccione Detener.
Eliminación de todos los recursos
Importante
Los recursos que creó pueden usarse como requisitos previos para otros tutoriales y artículos de procedimientos de Azure Machine Learning.
Si no va a usar ninguno de los recursos que ha creado, elimínelos para no incurrir en cargos:
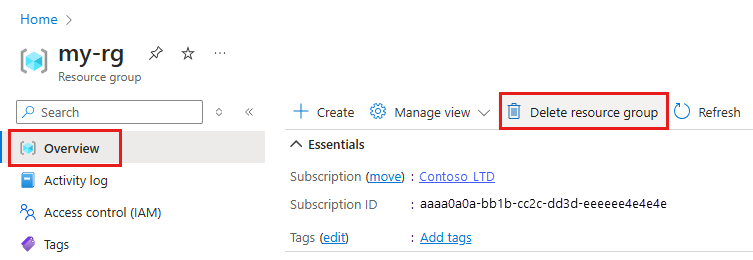
En Azure Portal, en el cuadro de búsqueda, escriba Grupos de recursos y selecciónelo en los resultados.
En la lista, seleccione el grupo de recursos que creó.
En la página Información general, seleccione Eliminar grupo de recursos.
Escriba el nombre del grupo de recursos. A continuación, seleccione Eliminar.
También puede mantener el grupo de recursos pero eliminar una sola área de trabajo. Muestre las propiedades del área de trabajo y seleccione Eliminar.
Recursos relacionados
En esta sesión, ha actualizado de un script básico "Hola mundo" a un script de entrenamiento más realista que requería que se ejecutara un entorno de Python específico. Ha visto cómo usar entornos mantenidos de Azure Machine Learning. Por último, vio cómo en algunas líneas de código puede registrar métricas en Azure Machine Learning.
Hay otras maneras de crear entornos de Azure Machine Learning, como desde un archivo requirements.txt de PIP o desde un entorno de Conda local existente.